BigQuery Advent Calendar 2020の10日目の記事です。
この記事では、BigQueryを分析者に試験的に使ってもらった際に色々もらった質問とその解決策についてまとめてみました。
そして、その結果として**「BigQueryのUsabilityが高いことに気づけた」**というのが本記事のストーリーになります。
自身が運用側かつBigQueryに多少知識があったがために気づけなかった**「分析者目線での初めてのBigQuery」におけるTips**を質問と解決策を通してお伝えできればと思います。
(※あくまでも自身が提供した環境におけるTipsという点をご了承ください)
はじめに
簡単に自己紹介
学生の頃はデータ分析をかじっていましたが、入社したら社内向け分析プラットフォームを提供している部隊に入隊してました。
(入隊直後は自身が置かれた環境を受け入れるのに時間がかかりました)
入隊後はAWSから勉強し、現在はGCPをメインに担当中です。まだ若手といわれる年次です。
そんなある日・・
天の声「Synapse以外のDWHも試してみるか」
啓示を授かってしまった自分が現在社内向け分析プラットフォームにお試しでBigQueryの導入を担当しています。
試験的に提供した環境
分析者に提供した環境を簡単にまとめると、
- インターネット接続なし(ブラウザでBigQueryは利用できない)
- 分析用Linuxサーバー(SSHでサーバーに入ってもらってガチャガチャ分析してもらう)
- bqコマンドおよびPythonによるアクセスのマニュアル
になります。とにかくすぐに触ってもらう!を重視したのでかなり最低限の用意しかしませんでした。
その分、「あれどうなの?」「これどーしたらいいの?」のと質問が飛んできて気づきが多かったです。
実際に質問された「分析者目線での初めてのBigQuery」
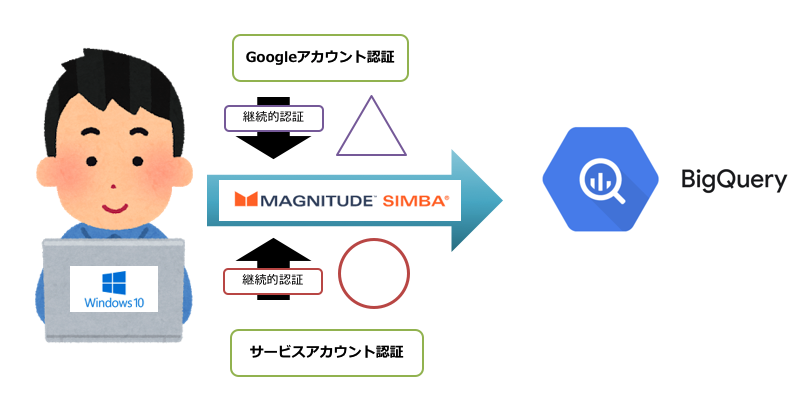
Q. 「WindowsからBigQuery使える?」
分析者によっては、SQLエディターを使ってwindowsから触りたいという声が多かったです。
ブラウザからアクセスできない環境というのもあり、比較的近いSQLエディターを介した分析の方が効率が良いとのことでした。
A. JDBC/ODBCドライバーで利用可能
これはGoogle公式のドライバが提供されているので、それをセットアップして対応しました。
SQLエディターによるかもしれませんが、ODBCのセットアップは難しくなくスムーズに導入できました。
BigQuery の Magnitude Simba ドライバ

Q. 「認証が数時間ごとに切れるんだけど?」
分析者にはGoogleアカウントを発行し、ドライバーのセットアップ時に認証をしてもらっていました。
ただ、自分の勉強不足だったのですがGoogleアカウントでGoogleAPIsを利用するにはOAuth認証が必要で、この認証は定期的にアクセストークが期限切れになり再認証が必要なるものでした。
分析途中に通ってたクエリが急にエラーがでると言われた時は焦りました(笑)
A. サービスアカウントでのセットアップなら定期的な認証いらず
そこでもう一つの認証方法であるサービスアカウントの認証に切り替えました。
こちらでセットアップすると分析者は継続的にBigQueryを利用することができるようになりました。
Q. 「クエリでテーブル一覧みたいなメタデータって見れない?」
最初はLinux環境でbqコマンドが使えれば良いと思っていましたが、上記のようにWindows環境でSQLエディターを介した作業がメインであるとクエリでメタデータを見れると嬉しいというのは確かにと思いました。
運用してる際はbqコマンドをメインで使っているので、こういったクエリで完結したいという分析者の思いに気づけたのは大きかったです。
A. INFORMATION_SCHEMAが便利
BigQueryで提供されている様々なメタデータを閲覧できるINFORMATION_SCHEMAが今回のケースで役立ちました。
データセットごとのメタデータの取得可能になっているビューであるため、余計な権限構成などを考えず分析者が利用できるというのが運用としてはありがたかったです。
こちらの記事が一通りINFORMATION_SCHEMAについてまとめてあるのでとても参考になりました。
BigQuery の INFORMATION_SCHEMA からどんな情報が取得できるのか、全ての VIEW を確認してみた
※上記掲載の一覧を貼らせていただきます。
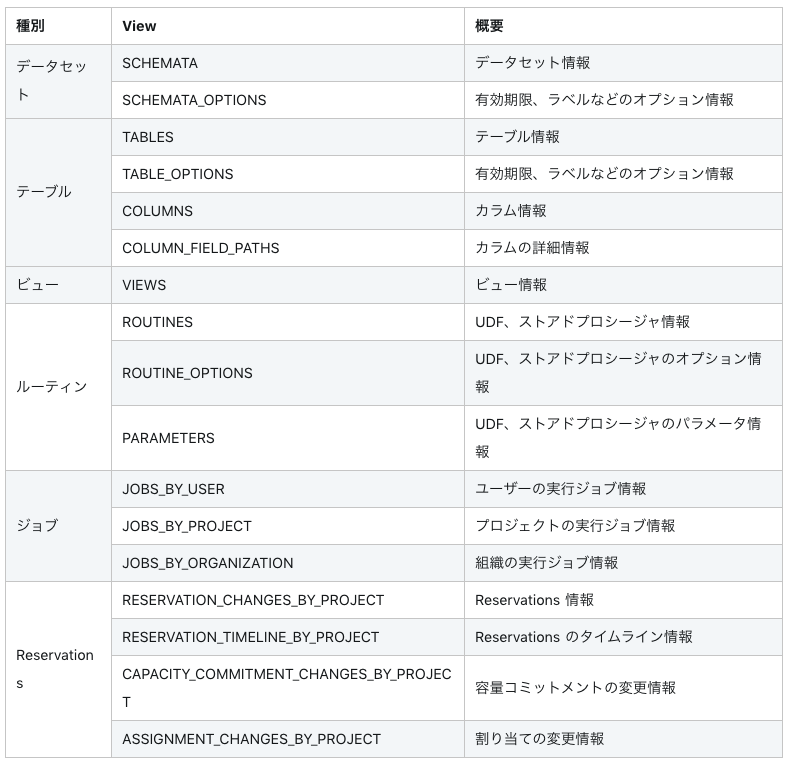
この中でも自分が発行したクエリ状況を確認できる INFORMATION_SCHEMA.JOBS_BY_USER は使い勝手よいという声が多かったです。
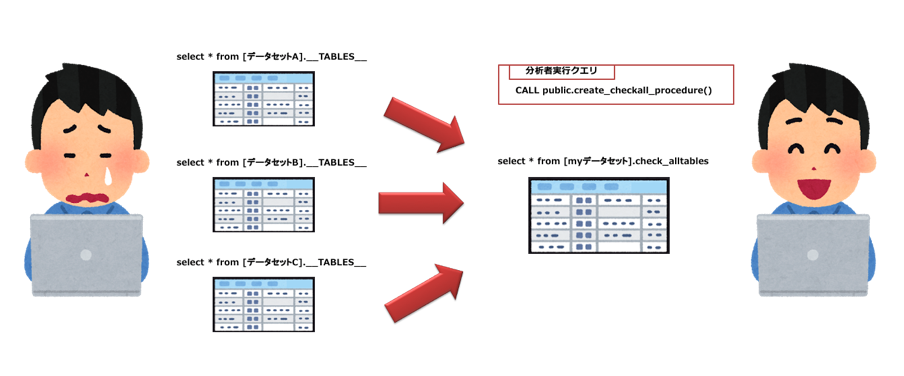
Q. 「データセット毎じゃなく全テーブルを一括で確認できない?」
最初は上記にもある通り、[データセット名].INFORMATION_SCHEMA.TABLESや**[データセット名]._TABLES _**でデータセットごとに見れれば問題ないのでは?と思っていたのですが、分析者としてはクエリするたびにデータセット名を変更したり、似たようなクエリをエディターに貯めておくのは効率がよ良くないとのことでした。
これも自身では気づけなかった点でした。ユーザーからのフィードバックは非常にありがたい。
A. ストアドプロシージャで提供
SQL力がなくなかなかいい方法を見つけられなかったのですが、下記の記事でまさに取得したいBigQueryScriptsがあったのでこちらをプロシージャとして提供しました。
BigQueryのテーブルの情報を一撃(?)で取ってみる。
中身はほぼ記事のもので、分析者が共有で利用できるデータセットにPROCEDUREを作成しておきました。
分析者はCALL [PROCEDURE名]を実行するだけ、分析者が閲覧できるテーブル一覧のテーブルを作成することができました。
CREATE PROCEDURE ステートメント
頭を悩ませていたので、記事の筆者さんに本当に感謝です。
Q. 「ビューにクエリするとエラーがでるんだけど?」
分析者が閲覧できる権限を持っているデータセットのビューにクエリするとエラーがでるとのことでした。
ただ、すべてのビューでエラーがでるわけではなく同じデータセットのビューでもクエリできるものもありました。
「・・・どうゆことや??」
これは完全に勉強不足だったのですが、ビューの導出元への閲覧権限の有無がポイントでした。
A. 承認済みビューの適用
原因調査の結果、
- クエリできるビュー:導出元の全てのデータセットには分析者の権限が付与されている
- クエリできないビュー:導出元データセットには分析者の権限が付与されていないものが含まれている
考えて見れば当たり前ですが、BigQueryでは閲覧権限のあるデータセットに存在するビューでも導出元にその分析者の閲覧権限がなければエラーになります。
そこで、承認済みビューという機能が提供されています。
承認済みのビューの作成
この機能で導出元に分析者の閲覧権限がなくてもビュー自体に閲覧権限があればクエリすることが可能になります。例えば、分析者に公開したくないテーブルと結合したビューのみを公開したいときなどに便利だったりします。

Q. 「スキャン量を減らす方法ある?」
分析者の方によっては処理時間の短縮化として、スキャン量を減らすようなクエリ最適化をやってくれています。
もちろん、必要なカラムのみを絞ってクエリするというのは大前提ですがそれ以外で何かないかといった問い合わせでした。
A. パーティション分割/クラスタ化テーブルの適用
パーティション分割テーブルは、よく知られているパーティショニングが日付や整数値の範囲などで適用されます。また、クラスタ化テーブルは指定したカラムで関連データが同じ場所に配置されます。これらを適用することで設定したカラムで条件を指定したときに必要なデータのみをスキャンできるようになります。
そうすることで、スキャン量を抑えることができパフォーマンスの向上やコスト低減を実現することができます。
下記記事の一部で紹介されています。
BigQuery におけるコスト最適化の ベスト プラクティス
※上記掲載の図を貼らせていただきます。
◆ dateカラムでパーティション分割テーブルを適用した場合
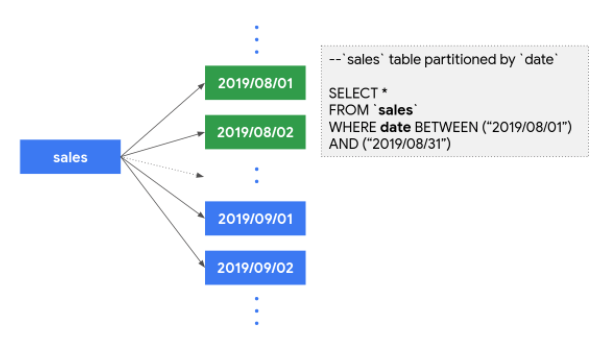
◆ 加えて特定のカラムでクラスタ化テーブルを適用した場合
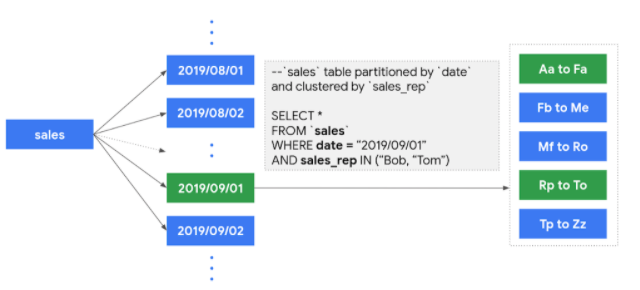
クエリではselect * from [データセット名].INFORMATION_SCHEMA.COLUMNSによってはis_partitioning_column,clustering_ordinal_positionというカラムで確認することができます。
bq query --nouse_legacy_sql --format=prettyjson 'select * from data_dwh.INFORMATION_SCHEMA.COLUMNS where table_name = "table1"'
[
{
"clustering_ordinal_position": null,
"column_name": "time_x",
"data_type": "TIMESTAMP",
"generation_expression": null,
"is_generated": "NEVER",
"is_hidden": "NO",
"is_nullable": "YES",
"is_partitioning_column": "YES",
"is_stored": null,
"is_system_defined": "NO",
"is_updatable": null,
"ordinal_position": "1",
"table_name": "table1",
"table_schema": "data_dwh"
},
{
"clustering_ordinal_position": "1",
"column_name": "keyid",
"data_type": "INT64",
"generation_expression": null,
"is_generated": "NEVER",
"is_hidden": "NO",
"is_nullable": "YES",
"is_partitioning_column": "NO",
"is_stored": null,
"is_system_defined": "NO",
"is_updatable": null,
"ordinal_position": "2",
"table_name": "table1",
"table_schema": "data_dwh"
},
・・・
]
少し前まではクラスタ化テーブルの適用はパーティション分割テーブルの適用が前提でしたが、2020年のアップデートで単独で利用が可能になったようです。
BigQueryの2020年アップデートを(だいたい)全部振り返る
クラスタ化テーブルが単独で利用可能になった(従来はパーティション分割との併用が必須だった)
Q. 「--nouse_legacy_sqlって省略できない?」
これは自身でも感じていたことですが、bqコマンドでStandardSQLを利用する際に --nouse_legacy_sql や --user_legacy_sql=false をつけて面倒だなぁと思っていました。
デフォルトのbqコマンドの設定が変えられれば楽なのに・・・
A. .bigqueryrcでデフォルト設定をカスタマイズ
ありましたね。これまた調べ不足でした。~/.bigqueryrcというファイルを編集することでbqコマンドのデフォルト設定を変更することができます。
コマンドライン フラグのデフォルト値の設定
今回の質問に関しては下記のように記述することでデフォルトでStandardSQLを利用可能になりました。
[query]
--use_legacy_sql=false
[load]
--destination_kms_key=projects/myproject/locations/mylocation/keyRings/myRing/cryptoKeys/myKey
まとめ
BigQueryを分析者に触ってもらった際の質問と解決策をまとめてみました。
BigQueryをよくご存知の方には当たり前の内容になっているかもしれませんが、BigQueryの運用を検討している方や運用始めの方の役に立つと嬉しいです。
分析者目線のフィードバックによって「そーいうところが気になるのか!」といった気づきが多く、もっと快適な分析環境を提供することへのモチベーションになりました。本当に感謝です。
また、質問された内容について調べると大抵のことはBigQueryにあらかじめ備わっているというのも大きな気づきで、BigQueryのUsabilityの高さを実感できました。
筆者「神様、BigQuery良さそうですぜ〜」

以上、初めてのAdventCalender参加で緊張しましたが楽しく書けてよかったです。
ありがとうございました。