translation
Japanese translation of this article (by courtesy of Makato Saito @promisedhill) can be found here.
Introduction
This is our experience with employing Neo4j graph databases and GraphQL query language in our latest project. It's been under active development for the past ~ 3 months. The technology stack we use for this project:
- Neo4j : Graph database for persistence layer
- GraphQL: query language to provide backend API
- Vue.js : For front end development
The Project
A new project to build an Instagram marketing platform came as an extension to our existing miel AI fashion platform. We have been collecting information on Instagramers who signed up for our existing platform, it seems only natural to extend that for a more comprehensive platform that could benefit marketers who want to promote their brand/products and monitor social penetration.
For the discussion purpose we limit the focus on one aspect of our platform. Among other things, one feature we want was for a customer to be able to create campaigns, sign-up Instagrammers to it and evaluate the performance of the campaign.
Technology Selection
We have been contemplating on using GraphQL and reading all the hype about Neo4j how wonderful it is to use graph databases. When the new project comes up which matches a perfect use case of these technologies we wanted to try it out.
Social networks help us identify the direct and indirect relationships between people, groups, and the things with which they interact, allowing users to rate, review, and discover each other and the things they care about. By understanding who interacts with whom, how people are connected, and what representatives within a group are likely to do or choose based on the aggregate behavior of the group, we generate tremendous insight into the unseen forces that influence individual behaviors.
The social networks are already graphs, so using Neo4j to create the data model directly matches the domain model, and helps you better understand our data, and avoid needless work. using Neo4j can improve the quality and speed, reducing the time to create data modeling.
GraphQL seems a natural fit for a data-model which will be represented with a graph database. Modeling the underlying data-model in GraphQL transfers the control of consuming data to front-end apps that can query the data it wants from the persistent layer. GraphQL type system ensures the validity of the queries and saves a lot of development effort reducing the communication overhead between back-end and front-end teams.
Data Modeling
One of the hypes about the Neo4j was data-modeling i.e. how easy and intuitive it is to build a data model. In our experience it turned out to be true indeed. It was much easier to bring the mental image that we draw on a whiteboard during discussions to a Neo4j model. No normalization, primary/foreign keys, just circles and arrows.
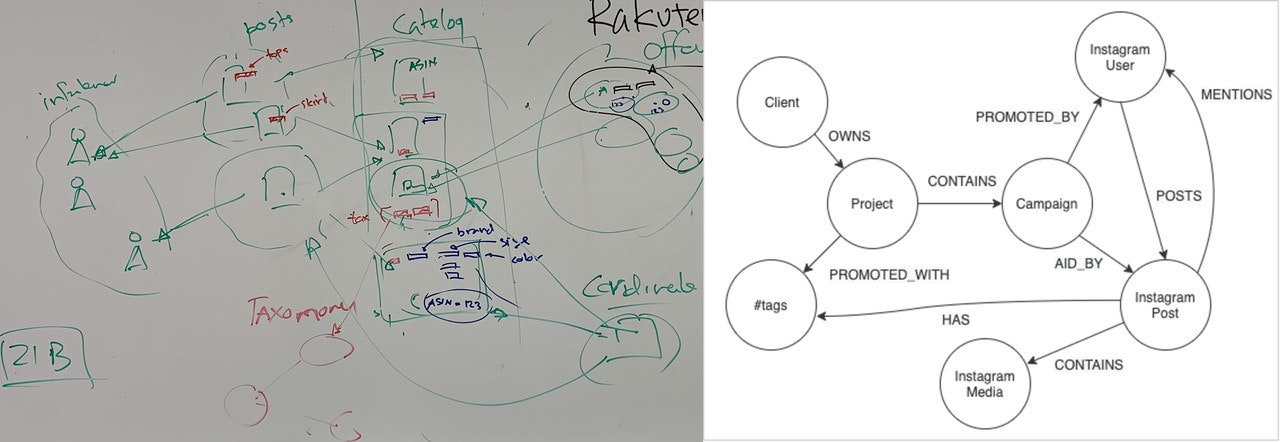
Neo4j/Neomodel
For modeling we used Neomodel, an Object Graph Mapper(OGM) for Neo4j. Neomodel hides all the complexity of the Neo4j Cypher query language which is intimidating at the beginning and in the back-end team we love python, thus we couldn’t think of a better way to get the project moving while we are learning the ropes with Neo4j/Cypher. In Neomodel the objects and their relationships for our Client and Projects looks like below.
class Client(StructuredNode):
uid = UniqueIdProperty()
name = StringProperty(required=True)
# relationships
instagram = RelationshipTo(InstaUser, 'HAS', cardinality=ZeroOrMore)
projects = RelationshipTo('Project', 'OWNS', cardinality=ZeroOrMore)
class Project(StructuredNode):
uid = UniqueIdProperty()
name = StringProperty(required=True)
# relationships
hashtags = RelationshipTo(Hashtag, 'MONITOR', cardinality=ZeroOrMore)
campaigns = RelationshipTo('Campaign', 'PROMOTE', cardinality=ZeroOrMore)
The relationships like “each client can have multiple projects”, “each projects can have multiple campaigns”, "project is promoted through multiple hashtags" are enforced by cardinality rules ZeroOrMore.
Campaign run by clients can have specific hash-tags which are promoted by Instagrammers signed up for the campaign. Campaign is getting visibility in multiple ways, getting tagged, client’s Instagram account gets mentioned, hashtag promoted etc. We modeled it as relationship AID which contains the type of the information on the relationship itself.
class AidRel(StructuredRel):
AID_TYPE = {'M': 'mention', 'T': 'tagged', 'H': 'hashtag', 'O': 'manual'}
type = StringProperty(choices=AID_TYPE)
name = StringProperty()
class Campaign(StructuredNode):
uid = UniqueIdProperty()
name = StringProperty()
start = DateTimeProperty()
end = DateTimeProperty()
url = StringProperty()
# relationships
posts = RelationshipTo(InstaPost, 'AID', cardinality=ZeroOrMore, model=AidRel)
entry_users = RelationshipTo(InstaUser, 'ENTRY', cardinality=ZeroOrMore)
aid_users = RelationshipTo(InstaUser, 'PROMOTE_BY', cardinality=ZeroOrMore)
[Note: Models of InstaUser InstaPost are removed for brevity]
GraphQL with Ariadne
We choose Ariadne GraphQL library to implement the API. It's schema-first approach makes us first model our API in GraphQL query language and then bind the data resolvers to the schema definitions.
Schema
GraphQL APIs enforces types on every API method. It makes API much more robust and consuming the API less error-prone. IDEs like GraphQL playground can read the API schema and validate the query even before it is sent, making developing against a GraphQL API a very pleasant experience for front-end developers.
Design goal of the GraphQL API is to represent the underlying data model and elevate the relationships of different types without much regard for how it will be used by the consumer. We end up mapping 1-to-1 GraphQL types for our data model's nodes types.
type Client {
uid : ID
name: String
user: User
instagram: InstaUser
projects: [Project]
}
type Project {
uid: ID
name: String
hashtags: [Hashtag]
campaigns: [Campaign]
}
In order to capture relationship data (ie. data placed on edges instead of nodes) we created new types like AidRelInstaPost to aggregate relationships data (AidRel) with corresponding node data (InstaPost).
type Campaign {
uid: ID
name: String
start: DateTime
end: DateTime
url: String
posts: [InstaPost]
aid_users: [InstaUser]
aid_rel_posts: [AidRelInstaPost]
}
type AidRelInstaPost {
aid: AidRel # edge data
post: InstaPost # node data
}
Resolvers
GraphQL provides any elegant and flexible way to query the fields of a type through a mechanism called resolvers. For most of the scalar fields (like ID, String Int etc.) we didn't have to provide resolvers at all, since Ariadne provides very natural way of mapping Neomodel data-objects' field names to corresponding type GraphQL type's fields names. For array fields we end up with below 90% of the time.
@campaign.field("posts")
def reslove_campaign_posts(campaign, *_):
return campaign.posts.all()
For hybrid-types which contain both edge and node information we had to resort to Neo4j Cypher query language to obtain information and construct the data.
@campaign.field("aid_rel_posts")
def reslove_campaign_aid_rel_post(campaign, *_):
query = f"""
MATCH (c:Campaign)-[a:AID]->(p:InstaPost)
WHERE c.uid = '{campaign.uid}'
RETURN a, p
"""
results, _ = db.cypher_query(query)
# Create AidRelInstaPost objects
res = [{'aid': AidRel.inflate(r[0]),
'post': InstaPost.inflate(r[1])} for r in results]
return res
Once we represented our data model in GraphQL querying any data related to projects could be done with a simple getProjects query.
type Query {
getProjects(project: ProjectQueryInput): [Project]
}
input ProjectQueryInput {
# project by uid
uid: ID
# project query by client.uid or .name and project.name
client_uid: ID
client_name: String
project_name: String
}
We also had a lot of flexibility with graphQL’s optional fields which let our QueryInput fields to come up with different criteria to query. For example above we were able to query projects by uid or client_id,project_name pair or even client_name,project_name. However one drawback of this was it pushed query validation down to the query resolvers.
Querying data
Data representing a client's campaign looks like below in Neo4j database.
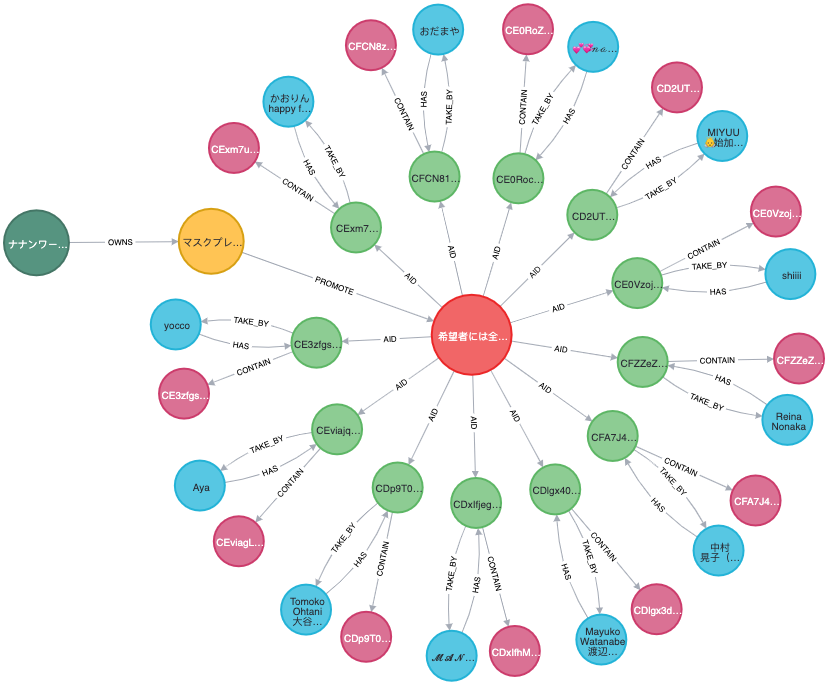
rgb(86,148,128) - Client
rgb(247,195,82) - Project
rgb(235,101,102) - Campaign
rgb(141,204,147) - InstaPost
rgb(218,113,148) - InstaMedia
rgb(89,199,227) - InstaUser
The query getProjects can request required fields. from any of the objects belonging to these nodes. For example, the query to populate the project report is like below.
{
getProjects(project: {
# all projects or criteria
}) {
# Project attributes
uid
name
hashtags {
tag_id
name
}
campaigns { # Campaign attributes
uid
name
start
end
url
posts { # Post attributes
post_id
shortcode
media(first: 1) { # media selection: only first one
display_url
media_id
shortcode
}
}
entry_users { # entry user attributes
ig_id
username
}
}
}
}
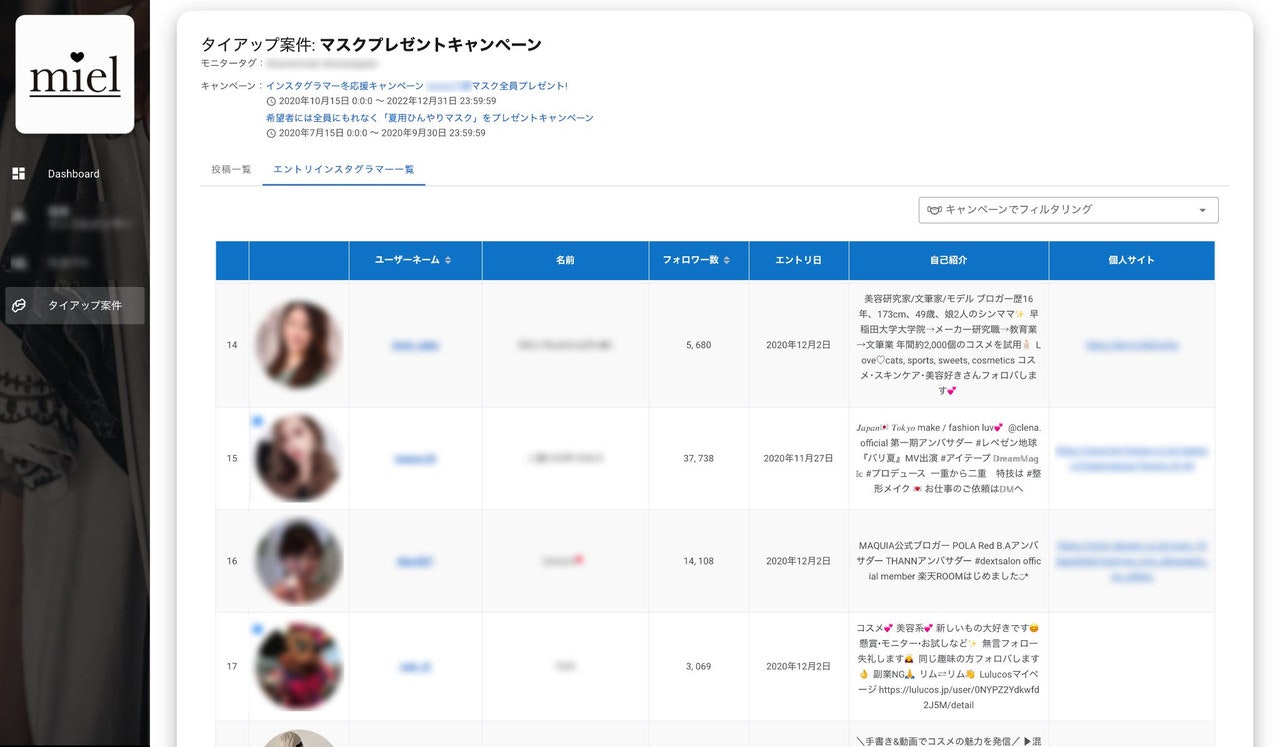
Front end can choose to retrieve any data element and resolvers get executed only for the requested elements. Below image shows above query being served in the GraphQL Playground. Tools like this help query composition for front end developers a breeze. The auto-completion, error handling expedite the development process and can handle changes to API specification with less communication overhead.
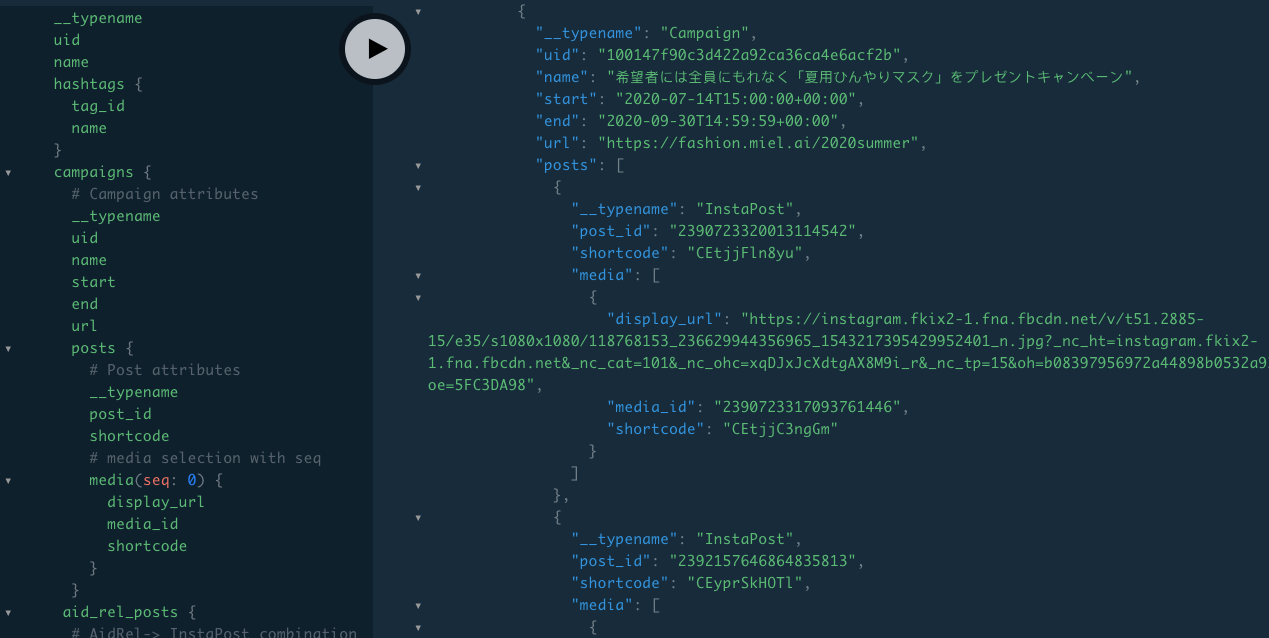
The front end rendering of the data from the query to present the client report of the campaign looks like this.
Conclusions
Use of the Neo4j and GraphQL in the new project has been a pleasant experience so far. With evolving project requirements we were able to extend our schema and add new entities and relationships to the data model without major refactoring. Neomodel was indispensable in clearly describing our entity relationships and early stages of building queries, even though we had to resort to Cypher query language later on to have better control. Since the GraphQL API is a reflection of our data model it too got extended with new functionalities without breaking the API. Even some breaking API refactoring could be effectively communicated to the front-end with GraphQL schema documentation, query validation and at times, surprisingly useful suggestions to use the correct field names when typographical mistakes were made.
It has been only a couple of months since we started using this stack. There is a lot to explore, we are confident that this technology stack continues to deliver our project expectations. It is also worth mentioning the GRANstack which is more aligned with javascript developer communities.