最初に
Neo4jとGraphQLを会社のプロジェクトで採用し、新しいプロダクトを開発しています。
今回はNeo4jとGraphQLを使った所感や事例などを共有したいと思います。
技術スタック:
- Neo4j : 永続用のグラフデータベース
- GraphQL: バックエンド API を提供するためのクエリ言語
- Vue.js : フロントエンド
プロジェクトについて
現在私達が取り組んでいるプロジェクトは、ファッションAIプラットフォーム mielの延長線の内容で、インスタグラムを代表とするSNSの投稿やソーシャルグラフを取得して分析を行い、ブランドや製品の影響力などを調査・評価をするプラットフォームの構築です。
今回の記事では、分析したいSNSアカウント(特にインスタグラム)やキャンペーンを登録し、キャンペーンのパフォーマンスを評価できるようにする機能に関して書きたいと思います。
GraphQL/Neo4Jを選んだ理由
私たちは、GraphQLを使うことを考えていて、Neo4jについての宣伝記事を読んで、グラフデータベースを使うことがどれほど素晴らしいかを考えていました。これらの技術の完璧なユースケースにマッチする新しいプロジェクトが出てきたとき、私たちはそれを試してみたいと思いました。
ソーシャルネットワークは、人やグループ、そしてそれらが相互に作用するものの間の直接的・間接的な関係を特定するのに役立ち、ユーザーはお互いに評価したり、レビューしたり、気になるものを発見したりすることができるようになります。誰が誰と交流しているのか、人々はどのようにつながっているのか、グループ内の代表者がグループの集合的な行動に基づいてどのような行動や選択をする可能性が高いのかを理解することで、個人の行動に影響を与える目に見えない力についての大きな洞察を得ることができます。
ソーシャルネットワークはすでにグラフ化されているので、Neo4jを使ってデータモデルを作成することで、ドメインモデルと直接一致し、データをよりよく理解することができ、無駄な作業を避けることができます。
GraphQLは、グラフデータベースで表現されるデータモデルに自然にフィットするように思われます。基礎となるデータモデルをGraphQLでモデリングすることで、データを消費するコントロールをフロントエンドアプリに転送し、永続層から必要なデータをクエリすることができます。GraphQL型のシステムは、クエリの妥当性を保証し、バックエンドとフロントエンドの間の通信オーバーヘッドを削減する開発努力を大幅に節約します。
Data Model
Neo4jについての売り文句の一つは、データモデリング、つまりデータモデルの構築がいかに簡単で直感的にできるかということでした。私たちの経験では、実際にその通りであることがわかりました。議論の間にホワイトボードに描くようなイメージをNeo4jモデルに持ってくることは、はるかに簡単でした。正規化、主キー/外部キーはなく、円と矢印だけです。
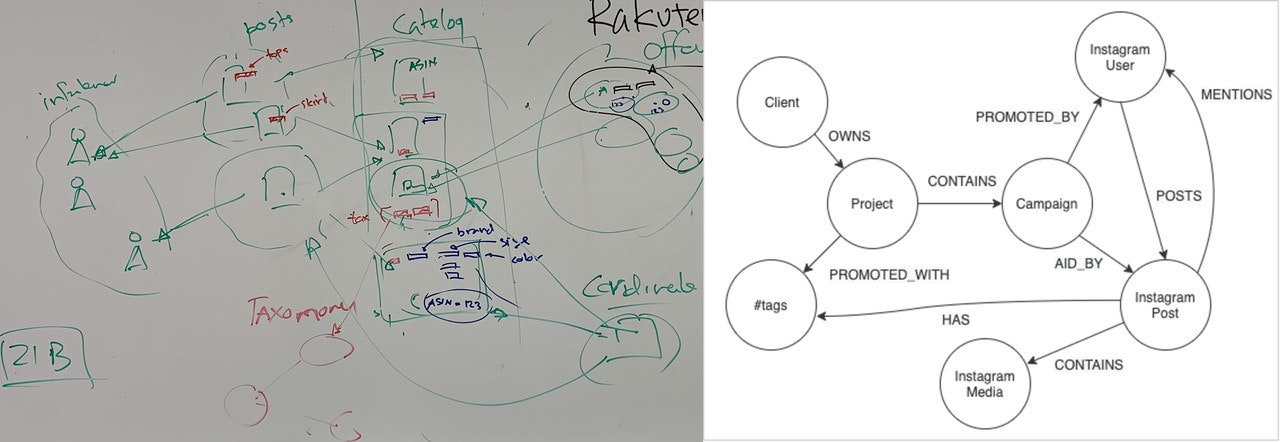
Neo4j/Neomodel
モデリングには、Neo4j用のオブジェクトグラフマッパー(OGM)であるNeomodelを使用しました。NeomodelはNeo4jのCypherクエリ言語の複雑さをすべて隠していますが、それは最初は威圧的で、バックエンドのチームでは私たちはPythonが大好きです。Neomodelでは、クライアントとプロジェクト`のためのオブジェクトとその関係は以下のようになります。
class Client(StructuredNode):
uid = UniqueIdProperty()
name = StringProperty(required=True)
# relationships
instagram = RelationshipTo(InstaUser, 'HAS', cardinality=ZeroOrMore)
projects = RelationshipTo('Project', 'OWNS', cardinality=ZeroOrMore)
class Project(StructuredNode):
uid = UniqueIdProperty()
name = StringProperty(required=True)
# relationships
hashtags = RelationshipTo(Hashtag, 'PROMOTED_WITH', cardinality=ZeroOrMore)
campaigns = RelationshipTo('Campaign', 'CONTAINS', cardinality=ZeroOrMore)
各クライアントは複数のプロジェクトを持つことができる」「各プロジェクトは複数のキャンペーンを持つことができる」「プロジェクトは複数のハッシュタグでプロモーションされる」といった関係性は、カーディナリティルール ZeroOrMoreによって強制される。
クライアントが運営するキャンペーンは、特定のハッシュタグを持つことができ、そのハッシュタグはキャンペーンに登録したインスタグラマーによってプロモーションされます。キャンペーンは、タグ付けされたり、クライアントのInstagramアカウントが言及されたり、ハッシュタグがプロモーションされたりと、複数の方法で可視性を得ています。我々はそれをリレーションシップAIDとしてモデル化しました。
class AidRel(StructuredRel):
AID_TYPE = {'M': 'mention', 'T': 'tagged', 'H': 'hashtag', 'O': 'manual'}
type = StringProperty(choices=AID_TYPE)
name = StringProperty()
class Campaign(StructuredNode):
uid = UniqueIdProperty()
name = StringProperty()
start = DateTimeProperty()
end = DateTimeProperty()
url = StringProperty()
# relationships
posts = RelationshipTo(InstaPost, 'AID', cardinality=ZeroOrMore, model=AidRel)
entry_users = RelationshipTo(InstaUser, 'ENTRY', cardinality=ZeroOrMore)
aid_users = RelationshipTo(InstaUser, 'PROMOTE_BY', cardinality=ZeroOrMore)
注:InstaUser InstaPost のモデルは簡潔にするために図示していません
GraphQL と Ariadne
APIの実装にはAriadneのGraphQLライブラリを選択しました。これはスキーマファーストのアプローチで、まずAPIをGraphQLクエリ言語でモデル化してから、データリゾルバをスキーマ定義にバインドします。
スキーマ
GraphQL APIは、すべてのAPIエンティティに型を強制します。これにより、APIはより堅牢になり、APIの消費はエラーが発生しにくくなります。GraphQL playgroundのようなIDEは、APIスキーマを読み込んで、クエリがディスパッチされる前にクエリを検証することができるので、フロントエンド開発者にとって、GraphQL APIを使った開発は非常に快適な経験になります。
GraphQL APIの設計目標は、基礎となるデータモデルを表現し、消費者がどのように使用するかをあまり気にすることなく、異なるタイプの関係性を高めることです。最終的には、データモデルのノード型に1対1のGraphQL型をマッピングします。
type Client {
uid : ID
name: String
user: User
instagram: InstaUser
projects: [Project]
}
type Project {
uid: ID
name: String
hashtags: [Hashtag]
campaigns: [Campaign]
}
リレーションシップデータ(ノードの代わりにエッジに配置されたデータ)を取得するために、リレーションシップデータ(AidRel)と対応するノードデータ(InstaPost)を集約するために、AidRelInstaPostのような新しい型を作成しました。
type Campaign {
uid: ID
name: String
start: DateTime
end: DateTime
url: String
posts: [InstaPost]
aid_users: [InstaUser]
aid_rel_posts: [AidRelInstaPost]
}
type AidRelInstaPost {
aid: AidRel # edge data
post: InstaPost # node data
}
Resolvers
GraphQLは、reslolverと呼ばれるメカニズムを使って、型のフィールドを問い合わせるためのエレガントで柔軟な方法を提供しています。ほとんどのスカラフィールド(ID, String, Int など)については、リゾルバを用意する必要がありませんでした。なぜなら、Ariadne は Neomodel データオブジェクトのフィールド名と対応する GraphQL 型のフィールド名を自然にマッピングしてくれるからです。配列フィールドの場合、90%以下のような結果になることが多いです。
@campaign.field("posts")
def reslove_campaign_posts(campaign, *_):
return campaign.posts.all()
エッジとノードの両方の情報を含むハイブリッド型については、データを構築するための情報を得るためにNeo4j Cypher クエリ言語に頼らなければならなかった。
@campaign.field("aid_rel_posts")
def reslove_campaign_aid_rel_post(campaign, *_):
query = f"""
MATCH (c:Campaign)-[a:AID_BY]->(p:InstaPost)
WHERE c.uid = '{campaign.uid}'
RETURN a, p
"""
results, _ = db.cypher_query(query)
# Create AidRelInstaPost objects
res = [{'aid': AidRel.inflate(r[0]),
'post': InstaPost.inflate(r[1])} for r in results]
return res
データモデルをGraphQLで表現すると、プロジェクトに関連するあらゆるデータの問い合わせは、単純な getProjects クエリで行うことができます。
type Query {
getProjects(project: ProjectQueryInput): [Project]
}
input ProjectQueryInput {
# project by uid
uid: ID
# project query by client.uid or .name and project.name
client_uid: ID
client_name: String
project_name: String
}
また、グラフQLのオプションフィールドを使用することで、QueryInputフィールドに異なる条件でクエリを実行することができます。上の例では、uid や client_id, project_name のペア、あるいは client_name, project_name のペアでプロジェクトをクエリすることができました。しかし、この場合の欠点は、クエリの検証をクエリリゾルバに押し付けてしまうことでした。
データの問い合わせ
クライアントのキャンペーンを表すデータは、Neo4jデータベースでは以下のようになりますす。
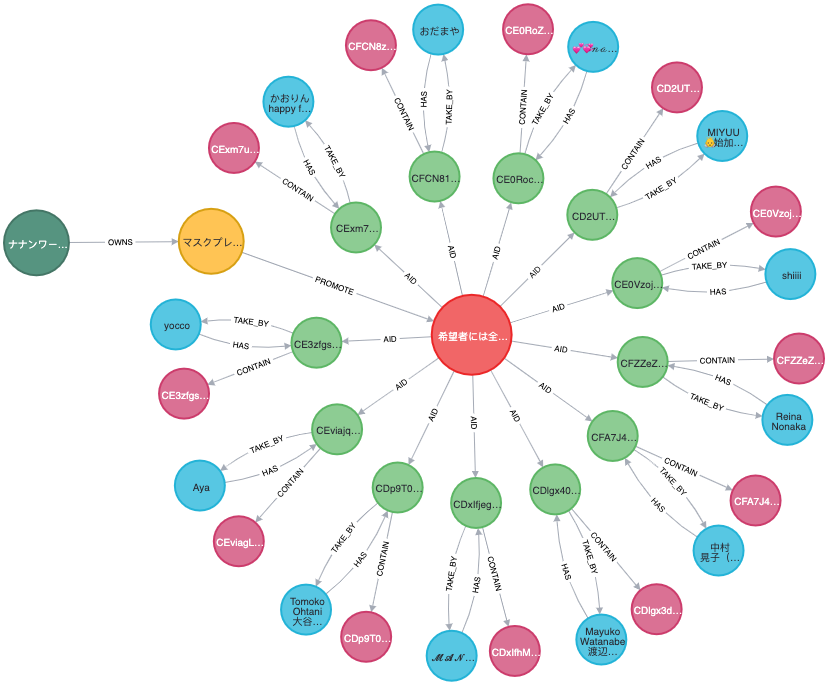
rgb(86,148,128) - Client
rgb(247,195,82) - Project
rgb(235,101,102) - Campaign
rgb(141,204,147) - InstaPost
rgb(218,113,148) - InstaMedia
rgb(89,199,227) - InstaUser
クエリ getProjects は、これらのノードに属するオブジェクトのいずれかから必要なフィールドを要求することができる。例えば、プロジェクトレポートを生成するクエリは以下のようになります。
{
getProjects(project: {
# all projects or criteria
}) {
# Project attributes
uid
name
hashtags {
tag_id
name
}
campaigns { # Campaign attributes
uid
name
start
end
url
posts { # Post attributes
post_id
shortcode
media(first: 1) { # media selection: only first one
display_url
media_id
shortcode
}
}
entry_users { # entry user attributes
ig_id
username
}
}
}
}
フロントエンドは任意のデータ要素を取得することができ、リゾルバは要求された要素に対してのみ実行されます。下の画像は、GraphQL Playgroundで提供されている上記のクエリを示しています。このようなツールは、フロントエンド開発者のためのクエリ構成を簡単にしてくれます。自動補完、エラー処理により開発プロセスを迅速化し、API仕様の変更にも少ない通信オーバーヘッドで対応することができます。
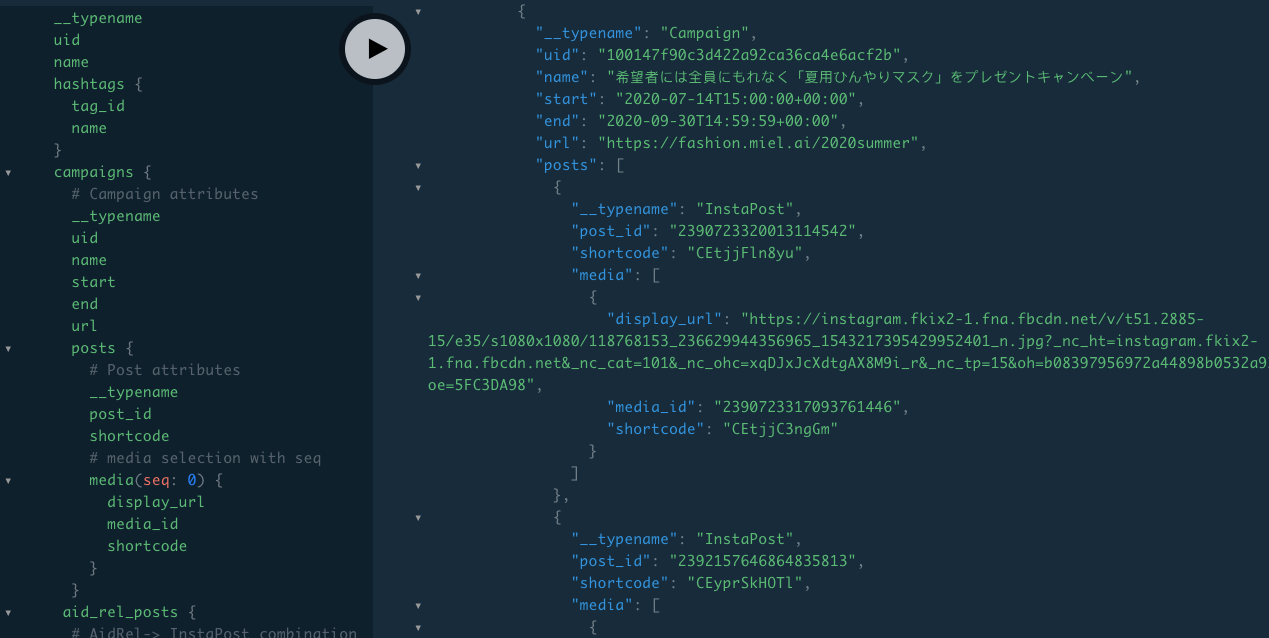
キャンペーンのクライアントレポートを提示するためのクエリからのデータのフロントエンドレンダリングは次のようになります。
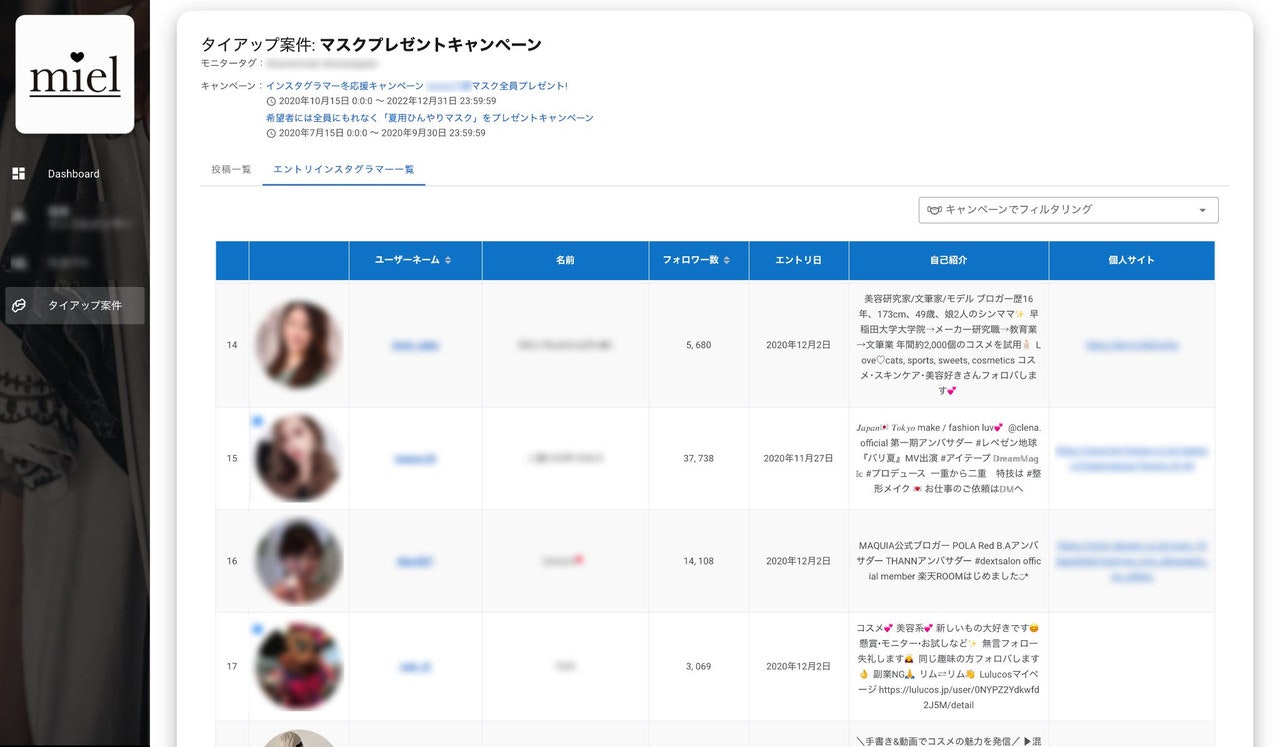
最後に
新しいプロジェクトでのNeo4jとGraphQLの使用は、これまでのところ楽しい経験でした。プロジェクトの要件の進化に伴い、スキーマを拡張し、大きなリファクタリングなしでデータモデルに新しいエンティティとリレーションシップを追加することができました。Neomodelは、エンティティの関係を明確に記述し、クエリを構築する初期段階では不可欠でしたが、後になってより良い制御をするためにクエリ言語のCypherに頼らざるを得なくなりました。GraphQLのAPIはデータモデルを反映したものなので、APIを壊すことなく新しい機能を追加することができました。APIのリファクタリングでさえも、GraphQLスキーマのドキュメント、クエリの検証、時として、タイプミスがあった場合に正しいフィールド名を使用するための驚くほど便利な提案など、効果的にフロントエンドに伝えることができました。
このスタックを使い始めてまだ数ヶ月しか経っていません。探求すべきことはたくさんありますが、この技術スタックが私たちのプロジェクトの期待に応え続けてくれると確信しています。また、GRANstackについても言及する価値があり、これはjavascriptの開発者コミュニティとより連携しています。