強化学習といえばDeep Q learningみたいなのりで、DQNがもてはやされていますが、AlphaGoとかロボットの機械学習では数年前くらいからActor-Criticに移行してきているように見えます。
その一方でパワーポイントに飼い慣らされた漫画お脳には論文なんて読んでも面白みがない感じの毎日なのに、一方に解説が出てくる気配が感じられません。ということで、鳩山イニシアチブが如く、恥を忍んで今の理解をざっくり紙芝居にします。
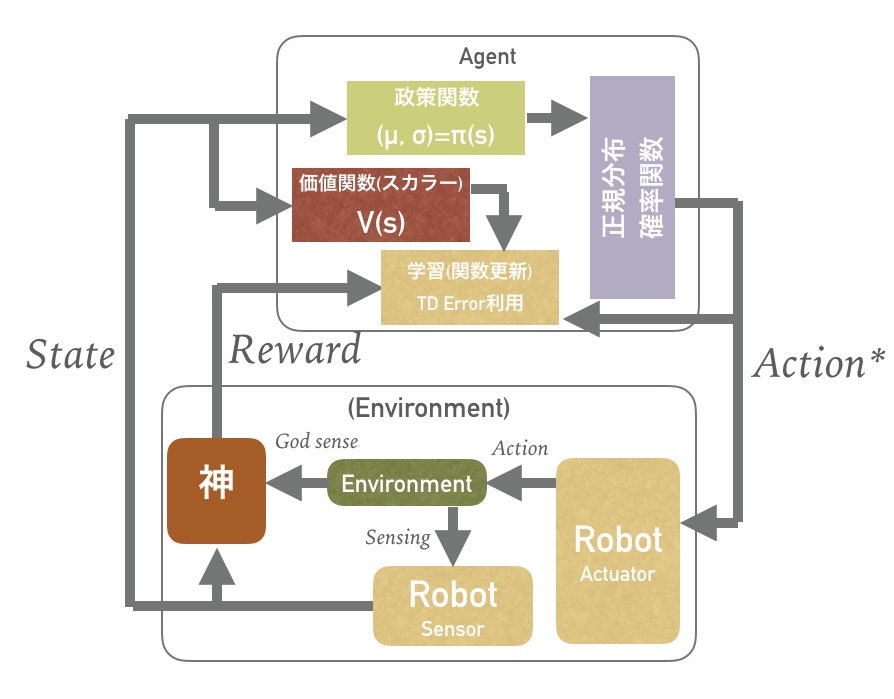
復習
強化学習
だいたい世の強化学習ってこんな絵で始まります。
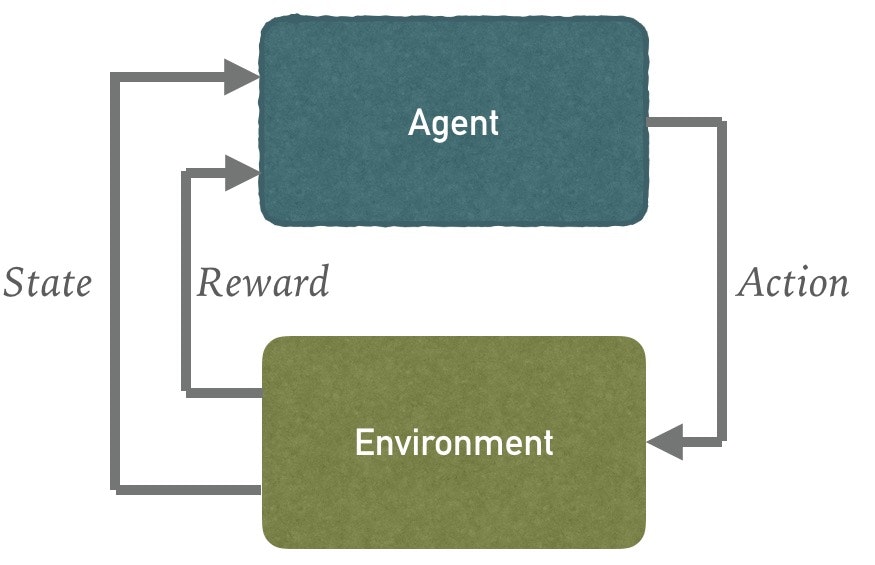
これをロボット制御に使う場合は実際の出力は、動作指令値であって出力ではなく、こんな感じ。
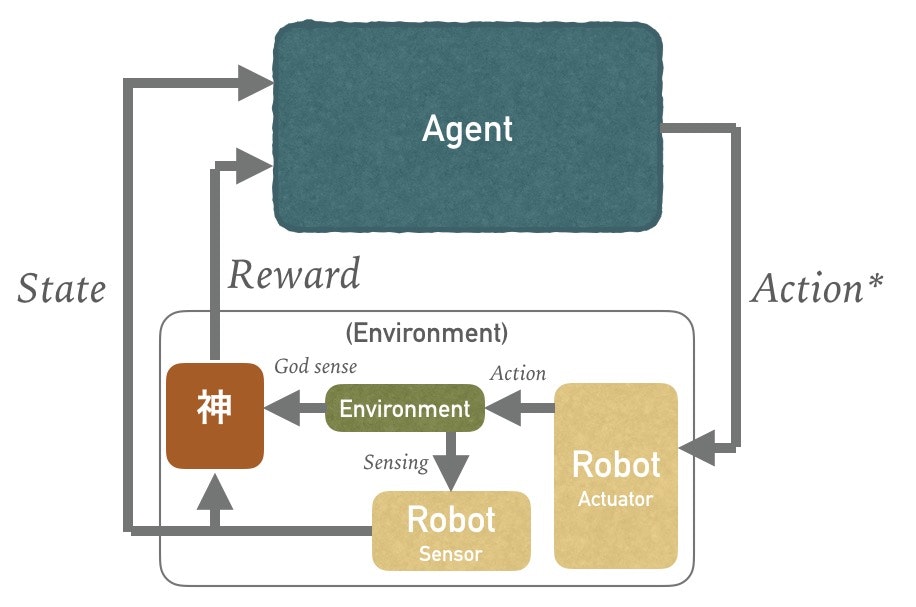
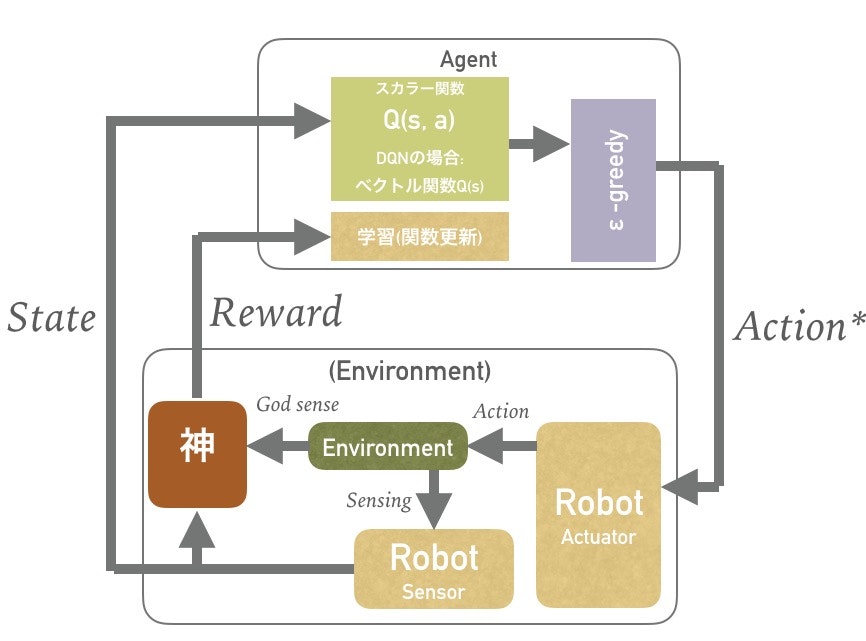
神の設計というか、リワードの設計がいろいろ面倒で、OpenAIとかdeep mindとかからの共同論文にも言及ありましたね。
ここでAgentが獲得を目指すのはQ値で評価される値で長期的にみて報酬rの合計値が最大化される値でしたね。
Q = r_0 + \gamma \cdot r_1 + \gamma ^2 \cdot r_2 + \cdots
Deep Q network
強化学習でq学習を使うことにして、更にq関数をディープなニューラルネットワークで近似することにすると、
関数はこんな感じでした。上が伝統的q関数をそのままニューラルネットワークにしたので、ニューラルネットで表現するのに不便なので下がdeep q networkではセオリーなq関数。
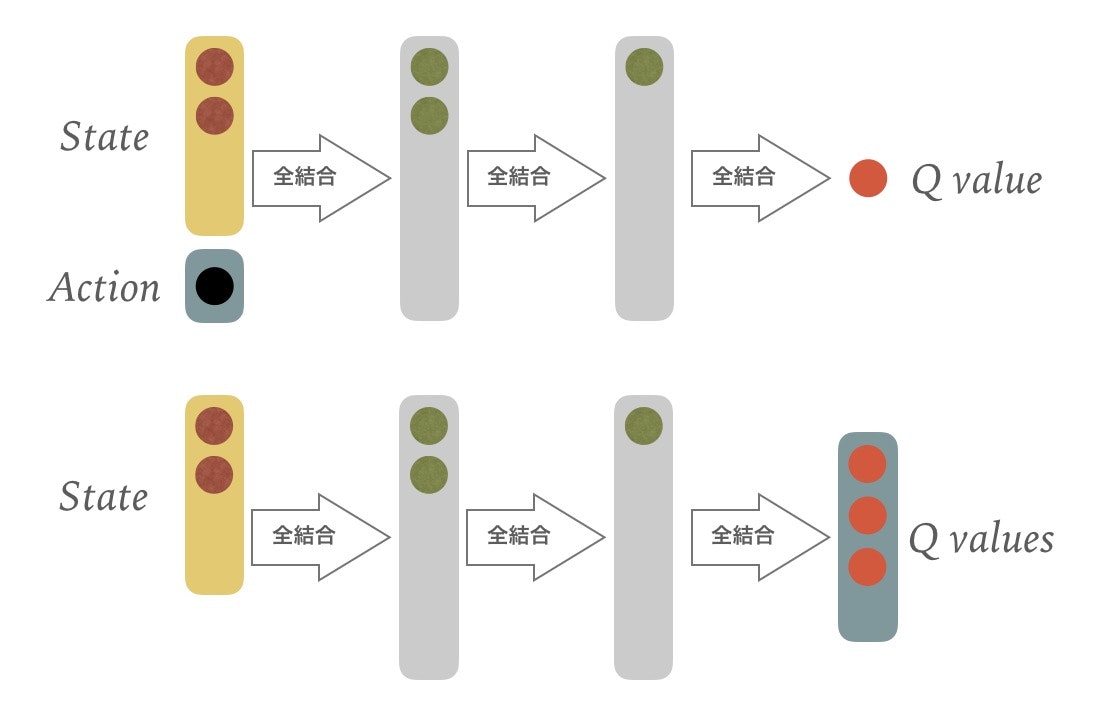
その時々の状態(state)に対してQ値の最大が期待される行動をとっていくようにします。学習の過程でQ値を予測する関数をどんどん正確にしていき、行動を最適化します。
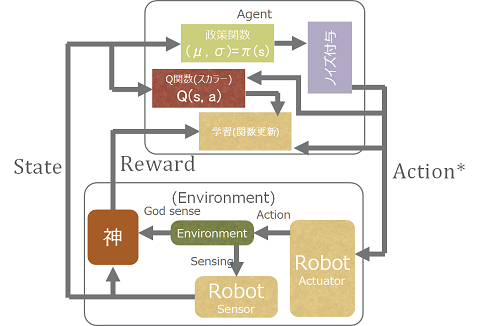
Actor-critic DDPG (Deep Deterministic Policy Gradient)
Q関数を求めるところと状態に応じた行動を決定する部分を分けたのがActor-Criticという強化学習方法で、調べれば調べるほど色んなタイプがあることがわかります(いや、本当に迷子になりました)
古典的なTD学習では、
Q(s,a) = V(s) + A(s,a)
という表現に置き換えてやると、
A(s,a) \approx r + \gamma V(s_{t+1}) -V(s_t) = TDError
であることから、q関数のところを価値関数vと政策関数πに置き換えて、
としてしまっているんだって!
これらの価値関数を線形関数で近似したのがAction value Actor-Critic型Policy Gradientによる連続値動作の強化学習です。
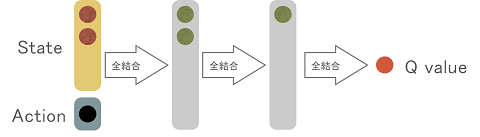
さて、DDPGでは、これを改めてQ関数で表現し、それをNNで表現する…というのがだいたいの骨子です。
ここでQ値関数を
政策関数を
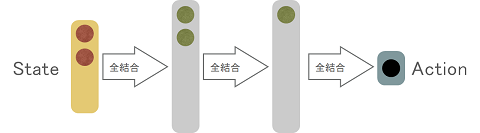
にして、かつ関数がディープなニューラルネットワークなのがDDPGという感じ。
実装
いつものChainerでやってみるDeep Q Learning - 立ち上げ編 - Qiitaで試験。一度作ると使いまわせていいですね。
Q関数
エージェントは左右輪のアクションを取るので、ステート数+2のネットワーク。
Q関数は教師信号
y = R + \gamma \cdot Q(s', \pi(s'))
をターゲットに学習する
class Q(Chain):
def __init__(self, state_dim = STATE_DIM):
super(Q, self).__init__(
l1=F.Linear(state_dim + 2, 20),
l2=F.Linear(20, 20),
v_value=F.Linear(20, 1)
)
def __call__(self, x, t):
return F.mean_squared_error(self.predict(x, train=True), t)
def predict(self, x, train = False):
h1 = F.leaky_relu(self.l1(x))
h2 = F.leaky_relu(self.l2(h1))
y = self.v_value(h2)
return y
政策関数
政策関数については,Chainerではロス関数というより勾配を直接定義して学習を進める必要がある様子。
\frac{\partial Loss_\pi}{\partial \theta} = \frac{\partial Q}{\partial a} \frac{\partial \pi}{\partial \theta}
これについては、
\frac{\partial Loss_\pi}{\partial \theta} = \frac{\partial Q(s,\pi(s;\theta))}{\partial \theta}
とも表せることからQとπをまとめて定義しちゃう方がいいかなとも思ったのですが、学習フェーズでノイズを負荷したaの処置がよくわからなかったので別個に定義しました。
class PolicyNetwork(Chain):
def __init__(self, state_dim = STATE_DIM):
super(PolicyNetwork, self).__init__(
l1=F.Linear(state_dim, 20),
p_value=F.Linear(20, 2)
)
def __call__(self, x, t):
return F.mean_squared_error(self.predict(x, train=True), t)
def predict(self, x, train = False):
h1 = F.leaky_relu(self.l1(x))
y = self.p_value(h1)
return y
学習
学習のところはDQNと同様にexperience replayです。
ポリシーの学習については、これでいいのかなと思いつつ、
\frac{\partial Q}{\partial a}
を放り込んでます!
def update_model(self, r, state, a):
print a, r
if len(self.eMem)<self.batch_num:
return
memsize = self.eMem.shape[0]
batch_index = np.random.permutation(memsize)[:self.batch_num]
batch = np.array(self.eMem[batch_index], dtype=np.float32).reshape(self.batch_num, -1)
p_seq = batch[:, 0:STATE_DIM]
r = batch[:, STATE_DIM]
a = batch[:, STATE_DIM:STATE_DIM+2]
new_seq= batch[:,(STATE_DIM+2):(STATE_DIM*2+2)]
x = Variable( np.hstack((p_seq,a)).astype(np.float32))
na = self.modelP.predict(Variable(new_seq)).data
tmpQ = self.modelQ.predict(Variable(np.hstack((new_seq,na)))).data.copy()
targetsQ = r.reshape((self.batch_num,-1)) + self.gamma * tmpQ
t = Variable(np.array(targetsQ, dtype=np.float32).reshape((self.batch_num,-1)))
# Q関数更新
self.modelQ.zerograds()
loss=self.modelQ(x ,t)
self.loss = loss.data
loss.backward()
self.optimizerQ.update()
# Policy更新
s = Variable(p_seq)
self.modelP.zerograds()
y = self.modelP.predict(s)
y.grad = x.grad[:,-2:]
y.backward()
self.optimizerP.update()
結果
下記実行していただいて目で見ていただくのがいいと思います。
リワードの微調整をしてやると挙動が結構変わります。
一度スピンを始めると中々抜け出せないのでそういう時は再起動してやってください。
考え方の違うところがあったら教えてください。添削していただける下心で公開してます!
環境はこちら
- Python 2.7
- Chainer 1.7.2
- numpy 1.11.0
- wxPython
ソース
汚いっすが貼っておきますね。そろそろwxPythonじゃなくてkivyにしようかな。
# -*- coding: utf-8 -*-
import wx
import wx.lib
import wx.lib.plot as plot
import math
import random as rnd
from chainer import cuda, optimizers, FunctionSet, Variable, Chain
import chainer.functions as F
import numpy as np
import copy
# import pickle
np.random.seed(1023)
# Steps looking back
STATE_NUM = 2
# State
STATE_NUM = 2
NUM_EYES = 9
STATE_DIM = NUM_EYES * 3 * 2
class SState(object):
def __init__(self):
self.seq = np.ones((STATE_NUM, NUM_EYES*3), dtype=np.float32)
def push_s(self, state):
self.seq[1:STATE_NUM] = self.seq[0:STATE_NUM-1]
self.seq[0] = state
def fill_s(self, state):
for i in range(0, STATE_NUM):
self.seq[i] = state
class Q(Chain):
def __init__(self, state_dim = STATE_DIM):
super(Q, self).__init__(
l1=F.Linear(state_dim + 2, 20),
l2=F.Linear(20, 20),
v_value=F.Linear(20, 1)
)
def __call__(self, x, t):
return F.mean_squared_error(self.predict(x, train=True), t)
def predict(self, x, train = False):
h1 = F.leaky_relu(self.l1(x))
h2 = F.leaky_relu(self.l2(h1))
y = self.v_value(h2)
return y
class PolicyNetwork(Chain):
def __init__(self, state_dim = STATE_DIM):
super(PolicyNetwork, self).__init__(
l1=F.Linear(state_dim, 20),
l2=F.Linear(20, 20),
p_value=F.Linear(20, 2)
)
def __call__(self, x, t):
return F.mean_squared_error(self.predict(x, train=True), t)
def predict(self, x, train = False):
h1 = F.leaky_relu(self.l1(x))
h2 = F.leaky_relu(self.l2(h1))
y = self.p_value(h1)
return y
class Walls(object):
def __init__(self, x0, y0, x1, y1):
self.xList = [x0, x1]
self.yList = [y0, y1]
self.P_color = wx.Colour(50,50,50)
def addPoint(self, x, y):
self.xList.append(x)
self.yList.append(y)
def Draw(self,dc):
dc.SetPen(wx.Pen(self.P_color))
for i in range(0, len(self.xList)-1):
dc.DrawLine(self.xList[i], self.yList[i], self.xList[i+1],self.yList[i+1])
def IntersectLine(self, p0, v0, i):
dp = [p0[0] - self.xList[i], p0[1] - self.yList[i]]
v1 = [self.xList[i+1] - self.xList[i], self.yList[i+1] - self.yList[i]]
denom = float(v1[1]*v0[0] - v1[0]*v0[1])
if denom == 0.0:
return [False, 1.0]
ua = (v1[0] * dp[1] - v1[1] * dp[0])/denom
ub = (v0[0]*dp[1] - v0[1] * dp[0])/denom
if 0 < ua and ua< 1.0 and 0 < ub and ub < 1.0:
return [True, ua]
return [False, 1.0]
def IntersectLines(self, p0, v0):
tmpt = 1.0
tmpf = False
for i in range(0, len(self.xList)-1):
f,t = self.IntersectLine( p0, v0, i)
if f:
tmpt = min(tmpt, t)
tmpf = True
return [tmpf, tmpt]
class Ball(object):
def __init__(self, x, y, color, property = 0):
self.pos_x = x
self.pos_y = y
self.rad = 10
self.property = property
self.B_color = color
self.P_color = wx.Colour(50,50,50)
def Draw(self, dc):
dc.SetPen(wx.Pen(self.P_color))
dc.SetBrush(wx.Brush(self.B_color))
dc.DrawCircle(self.pos_x, self.pos_y, self.rad)
def SetPos(self, x, y):
self.pos_x = x
self.pos_y = y
def IntersectBall(self, p0, v0):
# StackOverflow:Circle line-segment collision detection algorithm?
# http://goo.gl/dk0yO1
o = [-self.pos_x + p0[0], -self.pos_y + p0[1]]
a = v0[0] ** 2 + v0[1] **2
b = 2 * (o[0]*v0[0]+o[1]*v0[1])
c = o[0] ** 2 + o[1] **2 - self.rad ** 2
discriminant = float(b * b - 4 * a * c)
if discriminant < 0:
return [False, 1.0]
discriminant = discriminant ** 0.5
t1 = (- b - discriminant)/(2*a)
t2 = (- b + discriminant)/(2*a)
if t1 >= 0 and t1 <= 1.0:
return [True, t1]
if t2 >= 0 and t2 <= 1.0:
return [True, t2]
return [False, 1.0]
class EYE(object):
def __init__(self, i):
self.OffSetAngle = - math.pi/3 + i * math.pi*2/3/NUM_EYES
self.SightDistance = 0
self.obj = -1
self.FOV = 130.0
self.resetSightDistance()
def resetSightDistance(self):
self.SightDistance = self.FOV
self.obj = -1
class Agent(Ball):
def __init__(self, panel, x, y, alpha = 1.8):
super(Agent, self).__init__(
x, y, wx.Colour(112,146,190)
)
self.dir_Angle = math.pi/4
self.speed = 5
self.pos_x_max, self.pos_y_max = panel.GetSize()
self.pos_y_max = 480
self.eyes = [ EYE(i) for i in range(0, NUM_EYES)]
self.prevActions = np.zeros_like([])
# Actor Critic Model
self.theta = np.random.rand(2, STATE_DIM)
self.sigma = np.array([[0.2],[0.2]])#np.random.rand(2, 1)
self.w = np.random.rand(1, STATE_DIM)
# self.model
self.modelQ = Q()
self.optimizerQ = optimizers.Adam()
self.optimizerQ.setup(self.modelQ)
self.modelP = PolicyNetwork()
self.optimizerP = optimizers.Adam()
self.optimizerP.setup(self.modelP)
# experience Memory
self.eMem = np.array([],dtype = np.float32)
self.memPos = 0
self.memSize = 30000
self.batch_num = 30
self.loss = 0.0
self.alpha = alpha
self.gamma = 0.95
self.State = SState()
self.prevState = np.ones((1,STATE_DIM))
def UpdateState(self):
s = np.ones((1, NUM_EYES * 3),dtype=np.float32)
for i in range(0, NUM_EYES):
if self.eyes[i].obj != -1:
s[0, i * 3 + self.eyes[i].obj] = self.eyes[i].SightDistance / self.eyes[i].FOV
self.State.push_s(s)
def Draw(self, dc):
dc.SetPen(wx.Pen(self.P_color))
dc.SetBrush(wx.Brush(self.B_color))
for e in self.eyes:
if e.obj == 1:
dc.SetPen(wx.Pen(wx.Colour(112,173,71)))
elif e.obj == 2:
dc.SetPen(wx.Pen(wx.Colour(237,125,49)))
else:
dc.SetPen(wx.Pen(self.P_color))
dc.DrawLine(self.pos_x, self.pos_y,
self.pos_x + e.SightDistance*math.cos(self.dir_Angle + e.OffSetAngle),
self.pos_y - e.SightDistance*math.sin(self.dir_Angle + e.OffSetAngle))
super(Agent, self).Draw(dc)
def get_action(self, state):
x = Variable(state.reshape((1, -1)).astype(np.float32))
y = self.modelP.predict(x)
tmp = [max(min(y.data[0][0],0.9),-0.9),
max(min(y.data[0][1],0.9),-0.9)]
x = [tmp[0]+np.random.normal(0., self.alpha),
tmp[1]+np.random.normal(0., self.alpha)]
return x
def reduce_alpha(self):
self.alpha -= 1.0/2000
self.alpha = max(0.02, self.alpha)
def Value(self, state):
x = Variable(state.reshape((1, -1)).astype(np.float32))
return self.modelQ.predict(x).data[0]
def update_model(self, r, state, a):
print a, r
if len(self.eMem)<self.batch_num:
return
memsize = self.eMem.shape[0]
batch_index = np.random.permutation(memsize)[:self.batch_num]
batch = np.array(self.eMem[batch_index], dtype=np.float32).reshape(self.batch_num, -1)
p_seq = batch[:, 0:STATE_DIM]
r = batch[:, STATE_DIM]
a = batch[:, STATE_DIM:STATE_DIM+2]
new_seq= batch[:,(STATE_DIM+2):(STATE_DIM*2+2)]
x = Variable( np.hstack((p_seq,a)).astype(np.float32))
na = self.modelP.predict(Variable(new_seq)).data
tmpQ = self.modelQ.predict(Variable(np.hstack((new_seq,na)))).data.copy()
targetsQ = r.reshape((self.batch_num,-1)) + self.gamma * tmpQ
t = Variable(np.array(targetsQ, dtype=np.float32).reshape((self.batch_num,-1)))
# Q関数更新
self.modelQ.zerograds()
loss=self.modelQ(x ,t)
self.loss = loss.data
loss.backward()
self.optimizerQ.update()
# Policy更新
s = Variable(p_seq)
self.modelP.zerograds()
y = self.modelP.predict(s)
y.grad = x.grad[:,-2:]
y.backward()
self.optimizerP.update()
def experience(self,x):
if self.eMem.shape[0] > self.memSize:
self.eMem[int(self.memPos%self.memSize)] = x
self.memPos+=1
elif self.eMem.shape[0] == 0:
self.eMem = x
else:
self.eMem = np.vstack( (self.eMem, x) )
def Move(self, WallsList):
flag = False
dp = [ self.speed * math.cos(self.dir_Angle),
-self.speed * math.sin(self.dir_Angle)]
for w in WallsList:
if w.IntersectLines([self.pos_x, self.pos_y], dp)[0]:
dp = [0.0, 0.0]
flag = True
self.pos_x += dp[0]
self.pos_y += dp[1]
self.pos_x = max(0, min(self.pos_x, self.pos_x_max))
self.pos_y = max(0, min(self.pos_y, self.pos_y_max))
reward = (dp[0]**2+dp[1]**2)**0.5
return flag, reward
def HitBall(self, b):
if ((b.pos_x - self.pos_x)**2+(b.pos_y - self.pos_y)**2)**0.5 < (self.rad + b.rad):
return True
return False
class World(wx.Frame):
def __init__(self, parent=None, id=-1, title=None):
wx.Frame.__init__(self, parent, id, title)
self.panel = wx.Panel(self, size=(640, 640))
self.panel.SetBackgroundColour('WHITE')
self.Fit()
self.A = Agent(self.panel, 350, 150 )
self.greenB = [Ball(rnd.randint(40, 600),rnd.randint(40, 440),
wx.Colour(112,173,71), property = 1) for i in range(0, 15)]
self.redB = [Ball(rnd.randint(40, 600),rnd.randint(40, 440),
wx.Colour(237,125,49), property = 2) for i in range(0, 10)]
# OutrBox
self.Box = Walls(640, 480, 0, 480)
self.Box.addPoint(0,0)
self.Box.addPoint(640,0)
self.Box.addPoint(640,480)
# Wall in the world
#self.WallA = Walls(96, 90, 256, 90)
#self.WallA.addPoint(256, 390)
#self.WallA.addPoint(96,390)
self.Bind(wx.EVT_CLOSE, self.CloseWindow)
self.cdc = wx.ClientDC(self.panel)
w, h = self.panel.GetSize()
self.bmp = wx.EmptyBitmap(w,h)
self.timer = wx.Timer(self)
self.Bind(wx.EVT_TIMER, self.OnTimer)
self.timer.Start(20)
# Plot
# https://www.daniweb.com/programming/software-development/code/216913/using-wxpython-for-plotting
#self.plotter = plot.PlotCanvas(self, pos=(0,480),size=(400,240))
#self.plotter.SetEnableZoom(True)
#self.plotter.SetEnableLegend(True)
#self.plotter.SetFontSizeLegend(20)
def CloseWindow(self, event):
# self.timer.Stop()
wx.Exit()
def OnTimer(self, event):
# Update States
self.A.UpdateState()
state = self.A.State.seq.reshape(1,-1)
action = self.A.get_action(state)
# Action Step
action[0] = max(min(action[0], 1.0), -1.0)
action[1] = max(min(action[1], 1.0), -1.0)
self.A.speed = (action[0] + action[1])/2.0 * 5.0
tmp = math.atan(max(min((action[0] - action[1])/ 2.0 / 2.5, 2.0), -2.0))
self.A.dir_Angle += tmp
self.A.dir_Angle = ( self.A.dir_Angle + np.pi) % (2 * np.pi ) - np.pi
flag,rrr = self.A.Move([self.Box])
digestion_reward = 0.0
for g in self.greenB:
if self.A.HitBall(g):
g.SetPos(rnd.randint(40, 600),rnd.randint(40, 440))
digestion_reward -= 6.0
for r in self.redB:
if self.A.HitBall(r):
r.SetPos(rnd.randint(40, 600),rnd.randint(40, 440))
digestion_reward += 5.0
# Reward
proximity_reward = 0.0
for e in self.A.eyes:
proximity_reward += float(e.SightDistance)/e.FOV if e.obj == 0 else 1.0
proximity_reward /= NUM_EYES
proximity_reward = min(1.0, proximity_reward*2)
forward_reward = 0.0
if(self.A.speed > 2.0 and proximity_reward > 0.75):
forward_reward = 0.1
elif(self.A.speed < 1.0):
foward_reward = -0.2
if (self.A.speed > 0.0 and tmp > -np.pi/8 and tmp < np.pi/8):
forward_reward += 0.1
if flag:
wall_punish = -1.0
else:
wall_punish = 0.0
reward = proximity_reward + forward_reward + digestion_reward + wall_punish+rrr/2.0
print ("reward:%.2f %.2f %.2f %.2f")%(proximity_reward,forward_reward
,digestion_reward, wall_punish+rrr/2.0)
# Learning Step
self.A.experience(np.hstack([
self.A.prevState,
np.array([reward]).reshape(1,-1),
np.array([action]).reshape(1,-1),
state
]))
self.A.update_model(reward, state, action)
self.A.prevState = state.copy()
self.A.reduce_alpha()
# Graphics Update
for e in self.A.eyes:
e.resetSightDistance()
p = [self.A.pos_x, self.A.pos_y]
s = math.sin(self.A.dir_Angle + e.OffSetAngle)
c = math.cos(self.A.dir_Angle + e.OffSetAngle)
for g in self.greenB:
f, t = g.IntersectBall(p, [e.SightDistance * c, - e.SightDistance * s])
if f:
e.SightDistance *= t
e.obj = g.property
for r in self.redB:
f, t = r.IntersectBall(p, [e.SightDistance * c, - e.SightDistance * s])
if f:
e.SightDistance *= t
e.obj = r.property
for w in [self.Box]:
f, t = w.IntersectLines(p, [e.SightDistance * c, - e.SightDistance * s])
if f:
e.SightDistance *= t
e.obj = 0
self.bdc = wx.BufferedDC(self.cdc, self.bmp)
self.gcdc = wx.GCDC(self.bdc)
self.gcdc.Clear()
self.gcdc.SetPen(wx.Pen('white'))
self.gcdc.SetBrush(wx.Brush('white'))
self.gcdc.DrawRectangle(0,0,640,640)
self.A.Draw(self.gcdc)
for g in self.greenB:
g.Draw(self.gcdc)
for r in self.redB:
r.Draw(self.gcdc)
self.Box.Draw(self.gcdc)
#self.WallA.Draw(self.gcdc)
#line = plot.PolyLine(ext.extract(), colour='blue', width=1, legend=filename)
#graph = plot.PlotGraphics([line], 'Wave', 't', 'f(t)')
#self.plotter.Draw(graph, xAxis=(0,len(ext.wav)), yAxis=(ext.wav.minvalue, ext.wav.maxvalue))
if __name__ == '__main__':
app = wx.PySimpleApp()
w = World(title='RL Test')
w.Center()
w.Show()
app.MainLoop()
参考