強化学習のバリエーションを増やすために、ChainerでやってみるDeep Q Learning - 立ち上げ編 - QiitaのエージェントをDQNからAction Value Actor-Critic型のPolicy Gradientに差し替えてみることにしました。

Actor Criticのイメージ図:6.6 Actor-Critic Methods
ちなみにChainerは使ってないですからねー 気を付けてくださいねー
Deep Learningでもないですよー
結論からいうといい感じのV(s)やπを設計できていないようで、
まっすぐ行って壁にぶつかり続けてしまう始末。
⇒ 若干の正規化で動き回るようにはなりました。
価値関数が線形では難しいのか、赤リンゴを追うようにはならず。
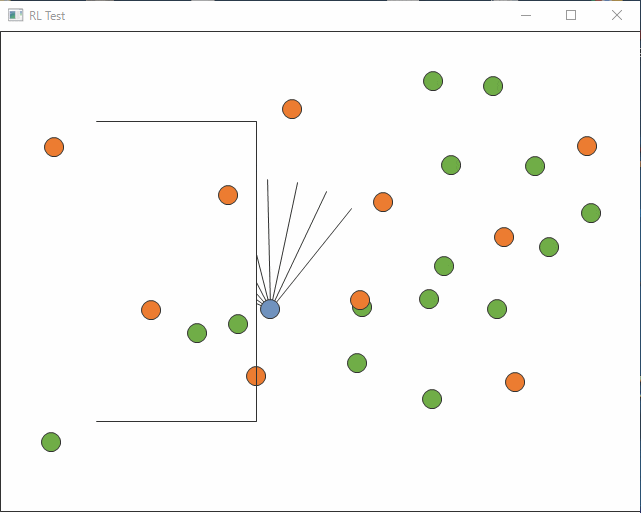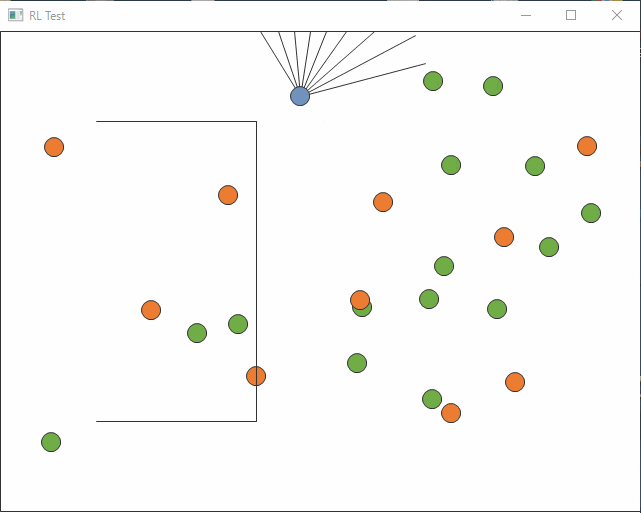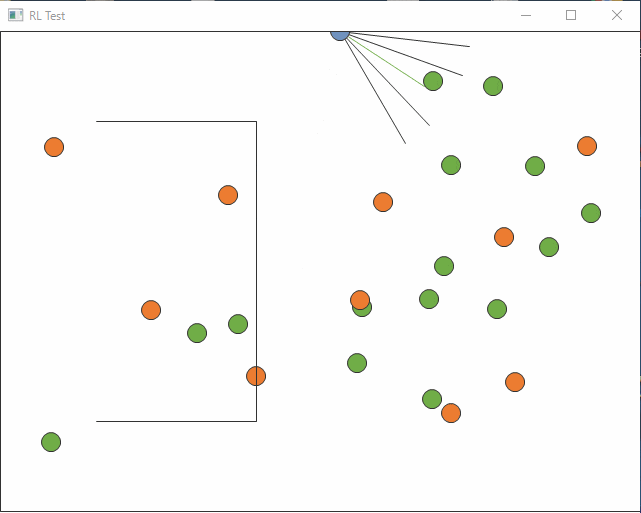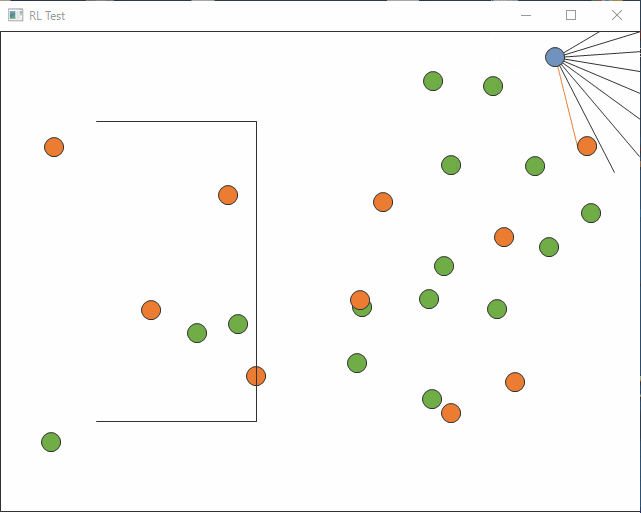
最近いろいろやりっぱなしがたまっていますが、やったところまでの記録です。
価値関数 V(s)
sは[赤リンゴまでの目測距離x9, 毒リンゴまでの目測距離x9,壁までの目測距離x9] x 2 Step分とし、線形アーキテクチャにおける更新処理(TD法)の考えで、価値関数を線形とし
V(s) = w \cdot s / dim(s)
def Value(self, state):
return np.sum(self.w.reshape(1,-1) * state)/STATE_DIM
self.w = np.random.rand(1, STATE_DIM)
self.w += self.alpha * TDErr * state
確率的政策関数π
Actor-Criticを連続行動空間へ拡張するには?を参考に正規分布で設定。
def get_action(self, state):
mu = np.sum(self.theta* state, axis=1)/STATE_DIM
x = [np.random.normal(mu[0], 1/(1+np.exp(-self.sigma[0]))),
np.random.normal(mu[1], 1/(1+np.exp(-self.sigma[1])))]
return x
def update_model(self, r, state, a):
TDErr = max(
min((r + self.gamma * self.Value(state) - self.Value(self.prevState)),
0.9),
-0.9)
mu = np.sum(self.theta* state, axis=1)/STATE_DIM
mu[0] = max(min(mu[0], 0.9), -0.9)
mu[1] = max(min(mu[1], 0.9), -0.9)
mud = np.array([a[0] - mu[0],
a[1] - mu[1]]).reshape(2, -1)
print TDErr,mu, a, mud,r
self.theta += self.alpha * TDErr * np.multiply(mud, state)/STATE_DIM
tmp = self.sigma + self.alpha * TDErr * (mud**2 - self.sigma**2)
tmp[0] = min(max(tmp[0], -10.0), 10.0)
tmp[1] = min(max(tmp[1], -10.0), 10.0)
self.sigma = tmp
# Actor Critic Model
self.theta = np.random.rand(2, STATE_DIM)
self.sigma = np.array([[1.0],[1.0]])#np.random.rand(2, 1)
self.w = np.random.rand(1, STATE_DIM)
このほか
環境条件などは基本的にChainerでやってみるDeep Q Learning - 立ち上げ編 - Qiitaと同等
モータ動作には回転制限をかけています
# Action Step
action[0] = max(min(action[0], 1.0), -1.0)
action[1] = max(min(action[1], 1.0), -1.0)
self.A.speed = (action[0] + action[1])/2.0 * 5.0
tmp = max(min((action[0] - action[1])/ 2.0 / 5.0, 2.0), -2.0)
self.A.dir_Angle += math.atan(tmp)
self.A.dir_Angle = ( self.A.dir_Angle + np.pi) % (2 * np.pi ) - np.pi
所感
出力リミッタをかける場合はTDerrorの計算時に少し怪しいことになりがちだと思います。
雑な議論で正確性に欠けますが、一般に制御では出力が不連続に切り替わるところでいろいろ面倒なことが起きがちですが、デジタルPIDなんかでは速度型PIDで実装することで、この辺を回避できることもあります(c.f. アンチワインドアップ)
参考資料
ソース
# -*- coding: utf-8 -*-
import wx
import wx.lib
import wx.lib.plot as plot
import math
import random as rnd
import numpy as np
import copy
# import pickle
# Steps looking back
STATE_NUM = 2
# State
STATE_NUM = 2
NUM_EYES = 9
STATE_DIM = NUM_EYES * 3 * 2
class SState(object):
def __init__(self):
self.seq = np.ones((STATE_NUM, NUM_EYES*3), dtype=np.float32)
def push_s(self, state):
self.seq[1:STATE_NUM] = self.seq[0:STATE_NUM-1]
self.seq[0] = state
def fill_s(self, state):
for i in range(0, STATE_NUM):
self.seq[i] = state
class Walls(object):
def __init__(self, x0, y0, x1, y1):
self.xList = [x0, x1]
self.yList = [y0, y1]
self.P_color = wx.Colour(50,50,50)
def addPoint(self, x, y):
self.xList.append(x)
self.yList.append(y)
def Draw(self,dc):
dc.SetPen(wx.Pen(self.P_color))
for i in range(0, len(self.xList)-1):
dc.DrawLine(self.xList[i], self.yList[i], self.xList[i+1],self.yList[i+1])
def IntersectLine(self, p0, v0, i):
dp = [p0[0] - self.xList[i], p0[1] - self.yList[i]]
v1 = [self.xList[i+1] - self.xList[i], self.yList[i+1] - self.yList[i]]
denom = float(v1[1]*v0[0] - v1[0]*v0[1])
if denom == 0.0:
return [False, 1.0]
ua = (v1[0] * dp[1] - v1[1] * dp[0])/denom
ub = (v0[0]*dp[1] - v0[1] * dp[0])/denom
if 0 < ua and ua< 1.0 and 0 < ub and ub < 1.0:
return [True, ua]
return [False, 1.0]
def IntersectLines(self, p0, v0):
tmpt = 1.0
tmpf = False
for i in range(0, len(self.xList)-1):
f,t = self.IntersectLine( p0, v0, i)
if f:
tmpt = min(tmpt, t)
tmpf = True
return [tmpf, tmpt]
class Ball(object):
def __init__(self, x, y, color, property = 0):
self.pos_x = x
self.pos_y = y
self.rad = 10
self.property = property
self.B_color = color
self.P_color = wx.Colour(50,50,50)
def Draw(self, dc):
dc.SetPen(wx.Pen(self.P_color))
dc.SetBrush(wx.Brush(self.B_color))
dc.DrawCircle(self.pos_x, self.pos_y, self.rad)
def SetPos(self, x, y):
self.pos_x = x
self.pos_y = y
def IntersectBall(self, p0, v0):
# StackOverflow:Circle line-segment collision detection algorithm?
# http://goo.gl/dk0yO1
o = [-self.pos_x + p0[0], -self.pos_y + p0[1]]
a = v0[0] ** 2 + v0[1] **2
b = 2 * (o[0]*v0[0]+o[1]*v0[1])
c = o[0] ** 2 + o[1] **2 - self.rad ** 2
discriminant = float(b * b - 4 * a * c)
if discriminant < 0:
return [False, 1.0]
discriminant = discriminant ** 0.5
t1 = (- b - discriminant)/(2*a)
t2 = (- b + discriminant)/(2*a)
if t1 >= 0 and t1 <= 1.0:
return [True, t1]
if t2 >= 0 and t2 <= 1.0:
return [True, t2]
return [False, 1.0]
class EYE(object):
def __init__(self, i):
self.OffSetAngle = - math.pi/3 + i * math.pi*2/3/NUM_EYES
self.SightDistance = 0
self.obj = -1
self.FOV = 130.0
self.resetSightDistance()
def resetSightDistance(self):
self.SightDistance = self.FOV
self.obj = -1
class Agent(Ball):
def __init__(self, panel, x, y, alpha = 0.5):
super(Agent, self).__init__(
x, y, wx.Colour(112,146,190)
)
self.dir_Angle = math.pi/4
self.speed = 5
self.pos_x_max, self.pos_y_max = panel.GetSize()
self.pos_y_max = 480
self.eyes = [ EYE(i) for i in range(0, NUM_EYES)]
self.prevActions = np.array([])
# Actor Critic Model
self.theta = np.random.rand(2, STATE_DIM)
self.sigma = np.array([[0.2],[0.2]])#np.random.rand(2, 1)
self.w = np.random.rand(1, STATE_DIM)
self.alpha = alpha
self.gamma = 0.95
self.State = SState()
self.prevState = np.ones((1,STATE_DIM))
def UpdateState(self):
s = np.ones((1, NUM_EYES * 3),dtype=np.float32)
for i in range(0, NUM_EYES):
if self.eyes[i].obj != -1:
s[0, i * 3 + self.eyes[i].obj] = self.eyes[i].SightDistance / self.eyes[i].FOV
self.State.push_s(s)
def Draw(self, dc):
dc.SetPen(wx.Pen(self.P_color))
dc.SetBrush(wx.Brush(self.B_color))
for e in self.eyes:
if e.obj == 1:
dc.SetPen(wx.Pen(wx.Colour(112,173,71)))
elif e.obj == 2:
dc.SetPen(wx.Pen(wx.Colour(237,125,49)))
else:
dc.SetPen(wx.Pen(self.P_color))
dc.DrawLine(self.pos_x, self.pos_y,
self.pos_x + e.SightDistance*math.cos(self.dir_Angle + e.OffSetAngle),
self.pos_y - e.SightDistance*math.sin(self.dir_Angle + e.OffSetAngle))
super(Agent, self).Draw(dc)
def get_action(self, state):
mu = np.sum(self.theta* state, axis=1)/STATE_DIM
x = [np.random.normal(mu[0], 1/(1+np.exp(-self.sigma[0]))),
np.random.normal(mu[1], 1/(1+np.exp(-self.sigma[1])))]
return x
def reduce_alpha(self):
self.alpha -= 1.0/2000
self.alpha = max(0.02, self.alpha)
def Value(self, state):
return np.sum(self.w.reshape(1,-1) * state)/STATE_DIM
def update_model(self, r, state, a):
TDErr = max(
min((r + self.gamma * self.Value(state) - self.Value(self.prevState)),
0.9),
-0.9)
mu = np.sum(self.theta* state, axis=1)/STATE_DIM
mu[0] = max(min(mu[0], 0.9), -0.9)
mu[1] = max(min(mu[1], 0.9), -0.9)
mud = np.array([a[0] - mu[0],
a[1] - mu[1]]).reshape(2, -1)
print TDErr,mu, a, mud,r
self.theta += self.alpha * TDErr * np.multiply(mud, state)/STATE_DIM
tmp = self.sigma + self.alpha * TDErr * (mud**2 - self.sigma**2)
tmp[0] = min(max(tmp[0], -10.0), 10.0)
tmp[1] = min(max(tmp[1], -10.0), 10.0)
self.sigma = tmp
self.w += self.alpha * TDErr * state
def Move(self, WallsList):
flag = False
dp = [ self.speed * math.cos(self.dir_Angle),
-self.speed * math.sin(self.dir_Angle)]
for w in WallsList:
if w.IntersectLines([self.pos_x, self.pos_y], dp)[0]:
dp = [0.0, 0.0]
flag = True
self.pos_x += dp[0]
self.pos_y += dp[1]
self.pos_x = max(0, min(self.pos_x, self.pos_x_max))
self.pos_y = max(0, min(self.pos_y, self.pos_y_max))
return flag
def HitBall(self, b):
if ((b.pos_x - self.pos_x)**2+(b.pos_y - self.pos_y)**2)**0.5 < (self.rad + b.rad):
return True
return False
class World(wx.Frame):
def __init__(self, parent=None, id=-1, title=None):
wx.Frame.__init__(self, parent, id, title)
self.panel = wx.Panel(self, size=(640, 640))
self.panel.SetBackgroundColour('WHITE')
self.Fit()
self.A = Agent(self.panel, 350, 150 )
self.greenB = [Ball(rnd.randint(40, 600),rnd.randint(40, 440),
wx.Colour(112,173,71), property = 1) for i in range(0, 15)]
self.redB = [Ball(rnd.randint(40, 600),rnd.randint(40, 440),
wx.Colour(237,125,49), property = 2) for i in range(0, 10)]
# OutrBox
self.Box = Walls(640, 480, 0, 480)
self.Box.addPoint(0,0)
self.Box.addPoint(640,0)
self.Box.addPoint(640,480)
# Wall in the world
self.WallA = Walls(96, 90, 256, 90)
self.WallA.addPoint(256, 390)
self.WallA.addPoint(96,390)
self.Bind(wx.EVT_CLOSE, self.CloseWindow)
self.cdc = wx.ClientDC(self.panel)
w, h = self.panel.GetSize()
self.bmp = wx.EmptyBitmap(w,h)
self.timer = wx.Timer(self)
self.Bind(wx.EVT_TIMER, self.OnTimer)
self.timer.Start(20)
# Plot
# https://www.daniweb.com/programming/software-development/code/216913/using-wxpython-for-plotting
#self.plotter = plot.PlotCanvas(self, pos=(0,480),size=(400,240))
#self.plotter.SetEnableZoom(True)
#self.plotter.SetEnableLegend(True)
#self.plotter.SetFontSizeLegend(20)
def CloseWindow(self, event):
# self.timer.Stop()
wx.Exit()
def OnTimer(self, event):
# Update States
self.A.UpdateState()
state = self.A.State.seq.reshape(1,-1)
action = self.A.get_action(state)
# Action Step
action[0] = max(min(action[0], 1.0), -1.0)
action[1] = max(min(action[1], 1.0), -1.0)
self.A.speed = (action[0] + action[1])/2.0 * 5.0
tmp = max(min((action[0] - action[1])/ 2.0 / 5.0, 10.0), -10.0)
self.A.dir_Angle += math.atan(tmp)
self.A.dir_Angle = ( self.A.dir_Angle + np.pi) % (2 * np.pi ) - np.pi
flag = self.A.Move([self.Box,self.WallA])
digestion_reward = 0.0
for g in self.greenB:
if self.A.HitBall(g):
g.SetPos(rnd.randint(40, 600),rnd.randint(40, 440))
digestion_reward -= 6.0
for r in self.redB:
if self.A.HitBall(r):
r.SetPos(rnd.randint(40, 600),rnd.randint(40, 440))
digestion_reward += 5.0
# Reward
proximity_reward = 0.0
for e in self.A.eyes:
proximity_reward += float(e.SightDistance)/e.FOV if e.obj == 0 else 1.0
proximity_reward /= NUM_EYES
proximity_reward = min(1.0, proximity_reward*2)
forward_reward = 0.0
#if(tmp == 0.0 and proximity_reward > 0.75):
# forward_reward = 0.1 * proximity_reward
if flag:
wall_punish = -10.0
else:
wall_punish = 0.0
reward = proximity_reward + forward_reward + digestion_reward + wall_punish
reward /= 10.0
# Learning Step
self.A.update_model(reward, state, action)
self.A.prevState = state.copy()
self.A.reduce_alpha()
# Graphics Update
for e in self.A.eyes:
e.resetSightDistance()
p = [self.A.pos_x, self.A.pos_y]
s = math.sin(self.A.dir_Angle + e.OffSetAngle)
c = math.cos(self.A.dir_Angle + e.OffSetAngle)
for g in self.greenB:
f, t = g.IntersectBall(p, [e.SightDistance * c, - e.SightDistance * s])
if f:
e.SightDistance *= t
e.obj = g.property
for r in self.redB:
f, t = r.IntersectBall(p, [e.SightDistance * c, - e.SightDistance * s])
if f:
e.SightDistance *= t
e.obj = r.property
for w in [self.Box, self.WallA]:
f, t = w.IntersectLines(p, [e.SightDistance * c, - e.SightDistance * s])
if f:
e.SightDistance *= t
e.obj = 0
self.bdc = wx.BufferedDC(self.cdc, self.bmp)
self.gcdc = wx.GCDC(self.bdc)
self.gcdc.Clear()
self.gcdc.SetPen(wx.Pen('white'))
self.gcdc.SetBrush(wx.Brush('white'))
self.gcdc.DrawRectangle(0,0,640,640)
self.A.Draw(self.gcdc)
for g in self.greenB:
g.Draw(self.gcdc)
for r in self.redB:
r.Draw(self.gcdc)
self.Box.Draw(self.gcdc)
self.WallA.Draw(self.gcdc)
#line = plot.PolyLine(ext.extract(), colour='blue', width=1, legend=filename)
#graph = plot.PlotGraphics([line], 'Wave', 't', 'f(t)')
#self.plotter.Draw(graph, xAxis=(0,len(ext.wav)), yAxis=(ext.wav.minvalue, ext.wav.maxvalue))
if __name__ == '__main__':
app = wx.PySimpleApp()
w = World(title='RL Test')
w.Center()
w.Show()
app.MainLoop()