initはもはや昔のしくみで、OS起動・停止時の制御はsystemdが行う。initよりも並列度を高める設計思想なので、HWの進化ともあいまって最近のOS起動はとにかく速い。
操作には冪等性があるし、Pre/Postといったライフサイクルフックな仕組みもあるので、応用の幅は旧式のinitと比べるとかなり広がっている。独自にシェルを組まずとも、ユニットファイルと呼ばれる定義ファイルをsystemdに食わせてやるだけでよい。
やはりなによりも__統一されたインタフェースでサービスを操作可能__というのがいい。起動・停止はsystemctlコマンドだけで済む。
というわけで、systemdサービスユニットファイルの覚書。
変更履歴
- 2019-02-26: Type=forkingで複数子プロセス生成時にcgroup内のプロセスが終了した場合の挙動を追加
- 2019-02-26: journal.confの項目を追加
- 2019-03-11: KillModeの項目を追加
- 2019-07-03: 付録に意地悪テストパターンを追加
動作確認環境
- CentOS Linux release 7.6.1810 (Core)
- 3.10.0-957.5.1.el7.x86_64
ユニットファイル
"/etc/systemd/system"下に"unitname.service"で配置(その他"/usr/lib/systemd"や"/lib/systemd"といったディレクトリもあるが、どちらかというとシステム向け)。
主な記載内容は以下の3セクション。
Unitセクション
ユニットの説明や起動順序制御・依存関係パラメータを記載する。
通常はAfterやBeforeを設定するだけで足りる、とマニュアルには記載されている。ここの使い分けはBeforeで一元管理したいか、Afterで各ユニットで判断させるかという設計思想次第だろう。systemdからの制御という意味ではどちらを使おうが同じ結果が得られる。
Requiresは強い依存で、ユニット起動時に指定したユニットも共づれで起動し、依存先ユニット起動が失敗したら自ユニットも異常終了させる。
Wantsは弱い依存で、ユニット起動時に指定したユニットも共づれで起動する点は同じだが、依存先ユニット起動が失敗しても自ユニットはそのまま続行する。
Serviceセクション
ユニットの動作パラメータを記載する。
Type
実行コマンドとメインプロセスの関係をTypeで表す。
- simple: ExecStartのコマンドがそのままメインプロセス
- forking: ExecStartの子プロセスがメインプロセス
- oneshot: ExecStartが終了してもメインプロセスが残る・残らないに関係なくとにかく一度実行(メインプロセス自体がなくてもよい)さらにRemainAfterExit=yesにすることで、ExecStart終了後も
systemctl statusは正常(active Exited)になる。
Restart
旧inittabでのrespawnに相当するようなパラメータで、再起動条件を指定できる。
- always: 常に再実行
- on-abort: キャッチできないシグナルで終了したときに再実行
- on-watchdog: 監視時間切れで再実行
- on-abnormal: SIGHUP, SIGINT, SIGTERM or SIGPIPE以外のシグナルで終了したときに再実行
- on-failure: メインプロセスが正常終了コード以外で終了したときに再実行
- on-success: メインプロセスが正常終了コードで終了したときに再実行
Installセクション
ユニットを有効化(sytemctl enable)したときにどのターゲット(旧ランレベル)で実行させるかを指定する。
たとえばマルチユーザモード(旧ランレベル3)で有効にする場合、"/etc/systemd/system/multi-user.target"配下へユニットファイルへのシンボリックリンクが張られる。
ユニットファイルフォーマット
リストはスペース区切り。よく使いそうなもののみ記載する。
[Unit]
Description=説明文
After=指定したユニットリストの起動後に実行
Before=指定したユニットリストの前に実行
Requires=指定したユニットリストの起動成功後に実行(下位項目起動時に依存ユニットも共づれ起動し、上位ユニット失敗時は起動しない)
Wants=指定したユニットリストが起動失敗しても実行(下位項目起動時に依存ユニットも共づれ起動し、上位ユニット失敗時も起動する)
[Service]
Environment=環境変数リスト
EnvironmentFile=環境変数ファイル
Type=simple|forking|oneshot
ExecStart=起動コマンド
ExecStop=停止コマンド
ExecReload=再読み込みコマンド
Restart=always|on-abort|on-watchdog|on-abnormal|on-failure|on-success|no
RemainAfterExit=yes|no
PIDFile=メインプロセスのPIDファイルパス
User=ExecXXの実行ユーザ
SuccessExitStatus=(0以外に)メインプロセス正常終了とみなすEXITコードリスト
[Install]
Alias=サービス別名リスト
WantedBy=ターゲットリスト
Also=一緒にインストールされるユニットリスト
よく使うコマンド
unitファイルのインストール(読み込み)
$ systemctl daemon-reload
有効化・無効化
$ systemctl enable|disable unitname
状態表示
$ systemctl show unitname
Type=forking
Restart=no
PIDFile=/tmp/sleep.pid
NotifyAccess=none
RestartUSec=100ms
TimeoutStartUSec=1min 30s
TimeoutStopUSec=1min 30s
WatchdogUSec=0
~略~
依存関係表示
$ systemctl list-dependencies unitname
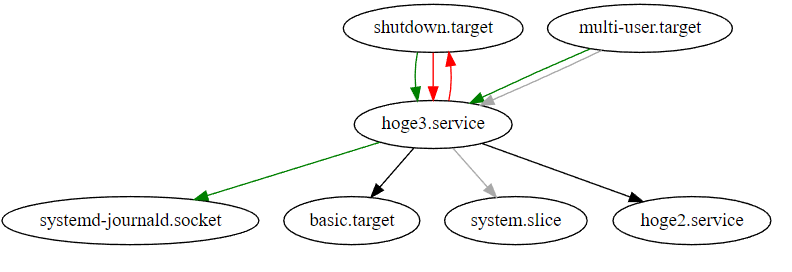
hoge1, hoge2, hoge3ユニットがあり、hoge3→hoge2→hoge1という風に依存している(Requires)場合の例。
$ systemctl list-dependencies hoge3
hoge3.service
● |-hoge2.service
● |-system.slice
● |-basic.target
"-a"を付与すると、hoge2からの依存も含められる。
$ systemctl list-dependencies hoge3 -a
hoge3.service
● |-hoge2.service
● | |-hoge1.service
逆に依存される側からたどるには、"--reverse"を付与する。
$ systemctl list-dependencies hoge1 --reverse -a
hoge1.service
● |-hoge2.service
● | |-hoge3.service
● | | |-multi-user.target
依存関係ではなく、前後関係を確認する(network → wasapp → ihsとなっている場合)。
$ systemctl list-dependencies --after ihs -a
ihs.service
● |-wasapp.service
● | |-network.service
起動シーケンスの確認
起動にかかった時間のサマリ(カーネル、initrd、ユーザ)
$ systemd-analyze time # 省略時
Startup finished in 331ms (kernel) + 3.827s (initrd) + 20.842s (userspace) = 25.002s
ユニット起動にかかった時間(現在activeなユニット)
$ systemd-analyze blame
15.916s kdump.service
7.849s hoge1.service
5.009s hoge3.service
5.009s hoge2.service
1.253s tuned.service
1.222s lvm2-monitor.service
システム起動時間のクリティカルパスをツリー表示(ユニット名は".service"省略不可)
$ systemd-analyze critical-chain unitname
The time after the unit is active or started is printed after the "@" character.
The time the unit takes to start is printed after the "+" character.
hoge3.service +5.009s
mqbasic.target @3.537s
mqsockets.target @3.537s
mqrpcbind.socket @3.537s
mqsysinit.target @3.537s
mqsystemd-update-utmp.service @3.531s +5ms
mqauditd.service @3.283s +247ms
mqsystemd-tmpfiles-setup.service @3.269s +9ms
mqrhel-import-state.service @3.235s +33ms
mqlocal-fs.target @3.235s
mqboot.mount @2.521s +713ms
mqlocal-fs-pre.target @2.520s
mqlvm2-monitor.service @1.298s +1.222s
mqlvm2-lvmetad.service @1.570s
mqlvm2-lvmetad.socket @1.282s
mq-.slice
出力にある通り、@はユニットがアクティブになった後の時間で、+はユニット起動自体にかかった時間。
起動シーケンスをSVG出力
$ systemd-analyze plot > systemd.sequence.svg
ブラウザ等で開けばこのようなクールな表示が得られる。
依存関係を出力
dotコマンド(GraphVizパッケージ)を使えばSVG出力にもできる。
$ systemd-analyze dot | dot -Tsvg > systemd.dependencies.svg`
全ユニット状態のダンプ
$ systemd-analyze dump
-> Unit swap.target:
Description: Swap
Instance: n/a
Unit Load State: loaded
Unit Active State: active
Inactive Exit Timestamp: Sat 2019-02-23 08:47:40 JST
Active Enter Timestamp: Sat 2019-02-23 08:47:40 JST
Active Exit Timestamp: Sat 2019-02-23 08:47:38 JST
Inactive Enter Timestamp: Sat 2019-02-23 08:47:38 JST
GC Check Good: yes
ユニットファイルのロードと検証
$ systemd-analyze verify /etc/systemd/system/hoge3.service
[/etc/systemd/system/hoge3.service:3] Unknown lvalue 'Raequires' in section 'Unit'
ログの確認
$ journalctl -xe # -x:拡張行表示 -e: 最終行から表示
$ journalctl -xe -S "2019-02-22 23:00:00" # --since=
$ journalctl -xe -S "2019-02-22 23:00:00" -U "2019-02-22 23:10:00" # --until=
$ journalctl -xe -u unitname
$ journalctl -f -u servicename # ライブ確認
$ journalctl --disk-usage
$ lsof -p $(pidof systemd-journald)
# →ディスク上のログファイルは確認できず
ログ設定
/etc/systemd/journal.confにログ設定を記載。Storage=autoがデフォルトで、man journald.confによれば"/var/log/journal"があればディスクへ、なければメモリ上に保持する("persistent"に設定するとディレクトリがなければ作る)。CentOS7では、実際には"/var/run/log/journal"があり、そこに出力されていた。
$ lsof /var/run/log/journal/ba824c1be03c41b4a67db39cc7fa89f7/system.journal
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd-j 1543 root mem REG 0,19 8388608 8152 /var/../run/log/journal/ba824c1be03c41b4a67db39cc7fa89f7/system.journal
systemd-j 1543 root 13u REG 0,19 8388608 8152 /var/../run/log/journal/ba824c1be03c41b4a67db39cc7fa89f7/system.journal
rsyslogd 3277 root mem REG 0,19 8388608 8152 /var/../run/log/journal/ba824c1be03c41b4a67db39cc7fa89f7/system.journal
rsyslogd 3277 root 5r REG 0,19 8388608 8152 /var/../run/log/journal/ba824c1be03c41b4a67db39cc7fa89f7/system.journal
その他
$ systemctl show-environment # systemdコンテクストでの環境変数表示
$ systemctl edit unitname # ユニットファイル編集と思いきや、"unitname.service.d"ディレクトリ作成しその下にファイル作成
動かしてみる
oneshot系(RemainAfterExit yes VS no)
このシェルをExecStartとするサービスユニットを作成し、RemainAfterExitの違いを確認する。
# !/usr/bin/bash
echo "$(hwclock) asdfasdfasdf this is ${1}"
sleep 5
exit 0
メインプロセスはない。ログにメッセージを書き込むだけ。あとで依存関係や順序設定をしたユニットの起動を確認しやすいよう、ハードウェアクロックをメッセージに含める(ブート時のシステムクロック同期でログの時刻が不正確になる)。
RemainAfterExit=yes
[Service]
ExecStart=/root/hoge.sh 1
Type=oneshot
RemainAfterExit=yes
$ systemctl daemon-reload
$ systemctl start hoge
$ systemctl status hoge
● hoge.service
Loaded: loaded (/etc/systemd/system/hoge.service; static; vendor preset: disabled)
Active: active (exited) since 土 2019-02-23 11:30:32 JST; 4s ago
Process: 30397 ExecStart=/root/hoge.sh 1 (code=exited, status=0/SUCCESS)
Main PID: 30397 (code=exited, status=0/SUCCESS)
2月 23 11:30:26 template systemd[1]: Starting hoge.service...
2月 23 11:30:27 template hoge.sh[30397]: 2019年02月23日 11時30分26秒 -0.741583 秒 asdfasdfasdf this is 1
2月 23 11:30:32 template systemd[1]: Started hoge.service.
activeになっている。再度systemctl start hogeを実行してもExecStartは動かない。一度systemctl stop hogeを実行すれば、再度起動できる。
RemainAfterExit=no
ユニットファイルのRemainAfterExit=noに変えて同じことを実行。
$ systemctl daemon-reload
$ systemctl start hoge
$ systemctl status hoge
● hoge.service
Loaded: loaded (/etc/systemd/system/hoge.service; static; vendor preset: disabled)
Active: inactive (dead)
2月 23 11:32:19 template systemd[1]: Starting hoge.service...
2月 23 11:32:20 template hoge.sh[30534]: 2019年02月23日 11時32分10秒 -0.665157 秒 asdfasdfasdf this is 1
2月 23 11:32:25 template systemd[1]: Started hoge.service.
今度はinactiveになる。再度systemctl start hogeを実行すると、ExecStartが動く。systemctl stop hogeを実行すると、何もせずにリターンコード0で終了する。
基本的にsystemctlによるサービスの操作は、冪等性があるようだ。
常駐プロセスがあるoneshot
プロセスが残る場合にどう見えるかの確認。
# !/usr/bin/bash
echo "$(hwclock) asdfasdfasdf this is ${1}"
sleep 1000 &
exit 0
[Service]
ExecStart=/root/hoge2.sh 4
Type=oneshot
RemainAfterExit=no
$ systemctl daemon-reload
$ systemctl start hogehoge
$ systemctl status hogehoge
● hogehoge.service
Loaded: loaded (/etc/systemd/system/hogehoge.service; static; vendor preset: disabled)
Active: inactive (dead)
sleepプロセスは残らない(terminateされる)。
RemainAfterExit=yesとすると、
● hogehoge.service
Loaded: loaded (/etc/systemd/system/hogehoge.service; static; vendor preset: disabled)
Active: active (exited) since 月 2019-02-25 19:22:53 JST; 3s ago
Process: 4923 ExecStart=/root/hoge2.sh 4 (code=exited, status=0/SUCCESS)
Main PID: 4923 (code=exited, status=0/SUCCESS)
CGroup: /system.slice/hogehoge.service
mq4925 sleep 1000
このようにsleepプロセスが残り、管理下に置かれる。sleepが終了しても特になにもしない(ExecStopは動かない)。
依存関係
同じoneshotのhogeサービスを複製してhoge1.service、hoge2.serviceとhoge3.serviceを作成する。
hoge3 wants hoge2、hoge2 wants hoge1としてみる。
[Service]
ExecStart=/root/hoge.sh 1
Type=oneshot
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
[Unit]
Wants=hoge1.service
[Service]
ExecStart=/root/hoge.sh 2
Type=oneshot
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
[Unit]
Wants=hoge2.service
[Service]
ExecStart=/root/hoge.sh 3
Type=oneshot
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
Wantsで依存するユニットを持つユニットを起動
hoge3を起動する。
$ systemctl daemon-reload
$ systemctl start hoge3
$ systemctl status hoge*
● hoge1.service
2月 23 11:41:03 template systemd[1]: Starting hoge1.service...
2月 23 11:41:08 template systemd[1]: Started hoge1.service.
● hoge2.service
2月 23 11:41:03 template systemd[1]: Starting hoge2.service...
2月 23 11:41:08 template systemd[1]: Started hoge2.service.
● hoge3.service
2月 23 11:41:03 template systemd[1]: Starting hoge3.service...
2月 23 11:41:08 template systemd[1]: Started hoge3.service.
順序関係を設定していないので、hoge1、hoge2、hoge3が同時に起動している。
__依存関係≠順序関係であることに注意__しなければならない。
Requiresで依存するユニットを持つユニットを起動
hoge2を"Wants"→"Requires"にし、hoge1を異常終了させる。
$ systemctl stop hoge*
$ systemctl daemon-reload
$ systemctl start hoge3
$ systemctl status hoge1 hoge2 hoge3
● hoge1.service
2月 23 12:23:57 template systemd[1]: hoge1.service failed.
● hoge2.service
Active: active (exited) since 土 2019-02-23 12:24:03 JST; 1s ago
2月 23 12:23:57 template systemd[1]: Starting hoge2.service...
2月 23 12:23:57 template systemd[1]: Dependency failed for hoge2.service.
2月 23 12:23:57 template systemd[1]: Job hoge2.service/start failed with ...'.
2月 23 12:23:58 template hoge.sh[5767]: 2019年02月23日 12時23分57秒 -0.74…s 2
● hoge3.service
2月 23 12:23:57 template systemd[1]: Starting hoge3.service...
2月 23 12:23:57 template hoge.sh[5765]: asdfasdfasdf this is 3
2月 23 12:24:02 template systemd[1]: Started hoge3.service.
hoge2 requires hoge1 なので、実行されないかと思いきや、activeになっている。しかも、途中で落とされている(asdfで始まるメッセージ出力なし)。
改めて、__依存関係≠順序関係__であり、かつ中途半端に実行される可能性があると認識する必要がある。
hoge3 wants hoge2なので、こちらは何事もなかったかのように実行されactiveになっている。
依存関係下でのrestart
再度普通に起動する状態で依存関係が、(hoge3 wants hoge2, hoge2 requires hoge1)のとき、再起動したらどうなるのかを確認する。
$ systemctl restart hoge1
$ systemctl status hoge[123] -l
● hoge3.service
2月 25 19:29:12 template systemd[1]: Started hoge3.service.
● hoge1.service
2月 25 20:15:40 template systemd[1]: Stopped hoge1.service.
2月 25 20:15:40 template systemd[1]: Stopping hoge1.service...
2月 25 20:15:40 template systemd[1]: Starting hoge1.service...
2月 25 20:15:40 template hoge.sh[7656]: 2019年02月25日 20時15分39秒 -0.012156 秒 asdfasdfasdf this is 1
2月 25 20:15:45 template systemd[1]: Started hoge1.service.
● hoge2.service
2月 25 20:15:40 template systemd[1]: Starting hoge2.service...
2月 25 20:15:40 template hoge.sh[7655]: hwclock: Cannot access the Hardware Clock via any known method.
2月 25 20:15:40 template hoge.sh[7655]: hwclock: Use the --debug option to see the details of our search for an access method.
2月 25 20:15:40 template hoge.sh[7655]: asdfasdfasdf this is 2
2月 25 20:15:45 template systemd[1]: Started hoge2.service.
というわけで、依存(Requires)先ユニットが再起動するときに、依存元も再起動する。
$ systemctl restart hoge2
$ systemctl status hoge[123] -l
● hoge3.service
2月 25 19:29:12 template systemd[1]: Started hoge3.service.
● hoge1.service
2月 25 20:15:45 template systemd[1]: Started hoge1.service.
● hoge2.service
2月 25 20:18:40 template systemd[1]: Stopped hoge2.service.
2月 25 20:18:40 template systemd[1]: Stopping hoge2.service...
2月 25 20:18:40 template systemd[1]: Starting hoge2.service...
2月 25 20:18:41 template hoge.sh[7817]: 2019年02月25日 20時18分40秒 -0.320656 秒 asdfasdfasdf this is 2
2月 25 20:18:46 template systemd[1]: Started hoge2.service.
依存(Wants)先ユニット再起動に、依存元はつられて再起動はしない。また、逆に依存先ユニットも再起動しない。
ということは、hoge3.serviceの再起動には誰も付き合わない、ということになる。
デーモン系(simple VS forking)
以下のsleepデーモンを使う。
# !/bin/sh
PID_FILE=/tmp/sleep.pid
SigHandle() {
echo "trapped $1 ($(kill -l $1))"
test $1 != 15 && rm -f ${PID_FILE}; kill -9 $pid
exit $1
}
trap 'SigHandle 1' 1
trap 'SigHandle 2' 2
trap 'SigHandle 3' 3
trap 'SigHandle 6' 6
trap 'SigHandle 15' 15
/usr/bin/sleep 1000000 &
pid=$!
echo $pid > ${PID_FILE}
wait $pid
まずは、以下のようなシンプルなユニットファイルを作成する。
[Service]
ExecStart=/tmp/sleep.sh
Type=forking
SuccessExitStatus=15
[Service]
ExecStart=/tmp/sleep.sh
Type=simple
SuccessExitStatus=15
sleepshはシェル自体がメインプロセスに、sleepはforkしたsleepがメインプロセスとなる。
simple
$ systemctl daemon-reload
$ systemctl start sleepsh
$ systemctl status sleepsh
● sleepsh.service
Loaded: loaded (/etc/systemd/system/sleepsh.service; static; vendor preset: disabled)
Active: active (running) since 土 2019-02-23 12:49:02 JST; 9s ago
Main PID: 7059 (sleep.sh)
CGroup: /system.slice/sleepsh.service
tq7059 /bin/sh /tmp/sleep.sh
mq7060 /usr/bin/sleep 1000000
2月 23 12:49:02 template systemd[1]: Started sleepsh.service.
停止してみる。
$ systemctl stop sleepsh
2月 23 12:50:40 template systemd[1]: Stopping sleepsh.service...
2月 23 12:50:40 template sleep.sh[7059]: trapped 15 (TERM)
2月 23 12:50:40 template sleep.sh[7059]: /tmp/sleep.sh: 7 行: kill: (7060)…ん
2月 23 12:50:40 template systemd[1]: Stopped sleepsh.service.
SIGTERMが送られた。
forking
$ systemctl start sleep
Job for sleep.service failed because a timeout was exceeded. See "systemctl status sleep.service" and "journalctl -xe" for details.
ExecStartがタイムアウトした。systemctl status sleepshで確認する。
2月 23 12:54:07 template systemd[1]: Starting sleep.service...
2月 23 12:55:37 template systemd[1]: sleep.service start operation timed ...g.
2月 23 12:55:37 template sleep.sh[7343]: trapped 15 (TERM)
2月 23 12:55:37 template sleep.sh[7343]: /tmp/sleep.sh: 7 行: kill: (7344)…
2月 23 12:55:37 template systemd[1]: Failed to start sleep.service.
2月 23 12:55:37 template systemd[1]: Unit sleep.service entered failed state.
2月 23 12:55:37 template systemd[1]: sleep.service failed.
タイムアウトしてSIGTERMが送られた。forkingを選択する以上、ExecStartは何らかの方法でsystemdに正常な状態になったことを伝える必要がある。
この辺は実際に使用するコマンドの仕様に合わせる必要がある。今回はメインプロセスが起動、つまりシェルがsleepを発行したらPIDファイルを作成してwaitせずにexit 0を返すのが素直な方法になる。
PID_FILE=/tmp/sleep.pid
/usr/bin/sleep 1000000 &
pid=$!
echo $pid > ${PID_FILE}
exit 0
[Service]
ExecStart=/tmp/sleep.sh
Type=forking
PIDFile=/tmp/sleep.pid
複数プロセスがforkしてできる場合
以下のケースを考える。
# !/usr/bin/bash
sleep 1000 &
sleep 1000 &
sleep 1000 &
exit 0
[Service]
ExecStart=/root/hoge1.sh
Type=forking
Restart=always
$ systemctl daemon-reload
$ systemctl start hoge
$ systemctl status hoge
CGroup: /system.slice/hoge.service
|-4917 sleep 1000
|-4918 sleep 1000
|-4919 sleep 1000
CGroup内のsleepプロセスを1つずつkillしてみると、全滅したときにRestartが発動する(二つまでは何もしない)。systemdからすればメインのPIDがわからないのだから当然ではある
メインのPIDを明示すれば動作が変わる。
# !/usr/bin/bash
sleep 1000 &
echo $! > /tmp/sleeppid.pid
sleep 1000 &
sleep 1000 &
exit 0
[Service]
ExecStart=/root/hoge1.sh
Type=forking
PIDFile=/tmp/sleeppid.pid
Restart=always
$ systemctl daemon-reload
$ systemctl start hoge
$ systemctl status hoge
Main PID: 5211 (sleep)
CGroup: /system.slice/hoge.service
|-5211 sleep 1000
|-5212 sleep 1000
|-5213 sleep 1000
この場合は、pidが5211のプロセスをkillすると、CGroup内の他のsleepにSIGTERMが送られ、指定されていればExecStopが実行されて、ExecStartされる。
その他留意事項
実は一番厄介というか不思議な動きをするのがExecStopだったりする。systemctl startで起動したメインプロセスをsystemdを介さずに終了させると、systemdはこれを検知し、ExecStopを実行する。もう止まっているのだからいいのでは?と思うが、何かクリーンアップ処理もしろということなのか、とにかくそういう仕様になっている。
systemdで管理するなら、systemdを介さずに起動・停止コマンドを直接実行することは避けておいたほうが無難。Restart設定も入れていたりすると、最悪は起動と停止の繰り返しに陥る可能性もある(systemctlで起動→起動済みのためExecStart異常終了→Restart発動しExecStart実行→異常終了のループ)。
KillMode(2019.03.11追記)
サービスの停止がうまくいかないような状況1で、確実にプロセスを停止する場合、以下のような制御パラメータが役に立つ。
KillMode: ExecStop実行後にSIGNALを送信する先(control-group, process, mixed, none)
KillSignal: KillModeで指定した対象に送信するシグナル
SendSIGHUP: KillSignal送信後にSIGHUPも送信する(デフォルトno)
SendSIGKILL: StopTimeoutSec後にSIGKILLも送信する(デフォルトyes)
以下のようなサービスで試してみる。
[Service]
Type=simple
ExecStart=/work/tmp/service1.sh
ExecStop=/work/tmp/stop.sh
PIDFile=/work/tmp/service1.sh.pid
KillMode=control-group
KillSignal=SIGTERM
# !/bin/sh
trap 'echo huh! SIGTERM means nothing to me!' 15
trap 'echo "oops! i shall exit now!"; exit 0' 1 3
echo $$ > $(dirname ${0})/$(basename ${0}).pid
while true; do
$(dirname ${0})/service2.sh
done
# !/bin/sh
trap 'echo huh!! SIGTERM means nothing to me!!' 15
trap 'echo "oops!! i shall exit now!!"; exit 0' 1 3
echo $$ > $(dirname ${0})/$(basename ${0}).pid
while true; do
sleep 10
done
# !/bin/sh
echo hah! nothing to do
service.serviceサービスが直接起動するのはservice1.shであり、service1.shはservice2.shを何度でも起動する。service2.shはsleep 10を何度でも実行する。
いずれもSIGTERMは無視し、SIGHUPかSIGQUITを受けると正常終了する。
$ systemctl daemon-reload
$ systemctl start service
$ systemctl stop service
$ systemctl status service
3月 11 22:03:37 sandbox systemd[1]: Stopping service.service...
3月 11 22:03:37 sandbox stop.sh[1212]: hah! nothing to do
3月 11 22:03:37 sandbox service1.sh[1190]: Terminated
3月 11 22:03:37 sandbox service1.sh[1190]: huh!! SIGTERM means nothing to me!!
3月 11 22:05:07 sandbox systemd[1]: service.service stop-sigterm timed out. Killing.
3月 11 22:05:07 sandbox systemd[1]: service.service: main process exited, code=killed, status=9/KILL
3月 11 22:05:07 sandbox systemd[1]: Stopped service.service.
3月 11 22:05:07 sandbox systemd[1]: Unit service.service entered failed state.
3月 11 22:05:07 sandbox systemd[1]: service.service failed.
22:03:37の何の役にも立たない停止コマンドの実行に続き、即座にSIGTERMがservice2.shに対して送信されるも、これを華麗にスルーしている。そしてTimeoutStopSec=90(デフォルト)秒後に全プロセスが強制終了(SendSIGKILL=yesがデフォルト)され、ステータスがfailedになっている(SuccessExitStatusは、Exitコード0, SIGHUP, SIGINT, SIGTERM, SIGPIPEがデフォルト)。
メインプロセスであるservice1.shにはSIGTERMが送られていない。
ところで、これらはSIGHUPまたはSIGQUITで正常終了する。そこでSendSIGHUP=yesにして同じことを実行する。
3月 11 22:14:57 sandbox stop.sh[1989]: hah! nothing to do
3月 11 22:14:57 sandbox service1.sh[1973]: Terminated
3月 11 22:14:57 sandbox service1.sh[1973]: oops!! i shall exit now!!
3月 11 22:14:57 sandbox service1.sh[1973]: oops! i shall exit now!
3月 11 22:14:57 sandbox systemd[1]: Stopped service.service.
きれいに停止した。KillSignal=SIGQUITとしても同様にservice2.shおよびservice1.shにシグナルが送信され、正常に停止する。
というわけで、デフォルトでは90秒たってもサービス(プロセス)が停止しなければ、SIGKILLにより葬られる。このあたりをどうするのがよいのかは、もちろん実際に起動するプロセスによりけりではある。特にヒープメモリをクリアしたいがためなら、合理的時間内に停止しなければSIGKILLで強制終了させるのがよいと考えられる。
なんにせよ、これらをシェルで実装しなくてもsystemdが面倒を見てくれるというのがうれしいところではある。
付録
参考情報
- systemd.service
- systemctl + WebSphere
man systemd.serviceman systemd-analyzeman systemd.kill- RHEL7マニュアル
unitファイル例
再起動等はちゃんと確認していない。
Apache系(forkするデーモン)
[Unit]
Description=IBM HTTP Server
After=wasapp.service
[Service]
Type=forking
ExecStart=/opt/IBM/HTTPServer/bin/apachectl start
ExecStop=/opt/IBM/HTTPServer/bin/apachectl graceful-stop
PIDFile=/opt/IBM/HTTPServer/logs/httpd.pid
Restart=on-failure
[Install]
WantedBy=multi-user.target
WebSphere Application Server(特殊な停止)
[Unit]
Description=IBM WebSphere Application Server apserver
After=network.target network.service
[Service]
Type=forking
ExecStart=/opt/IBM/WebSphere/AppServer/profiles/AppSrv01/bin/startServer.sh apserver
ExecStop=/opt/IBM/WebSphere/AppServer/profiles/AppSrv01/bin/stopServer.sh apserver
PIDFile=/opt/IBM/WebSphere/AppServer/profiles/AppSrv01/logs/apserver/apserver.pid
Restart=on-failure
User=wasuser
SuccessExitStatus=143 0
TimeoutStopSec=10min
TimeoutStartSec=0
[Install]
WantedBy=multi-user.target
WASの場合、stopServer.shからSOAPコネクタでメインプロセスと通信し、シャットダウンする。この時のメインプロセス(つまりjavaプロセス)のexitコードが143になる。この143は128+15で、つまり15=SIGTERMによって終了したことを意味する。
Advanced Bash-Scripting Guide: Appendix E. Exit Codes With Special Meanings
また、SuccessExitStatusに記載するのは、「0以外に正常とみなすEXITコード」なので、0を明記する必要はないのだが、書いても問題ないので並べて書いておくのがわかりやすい。
意地悪テスト
Type=forkingと相性の悪いExecStart
systemdの仕様上、メインプロセスを特定するということが重要ということは前述の通り(メインプロセスが終了するとExecStopが発動)。そこで、例えば以下のような処理をsystemdで制御しようとするとなかなか厳しいものがある。
# !/bin/bash
su - postgres -c '
sleep 1000 &
sleep 1000 &
'
メインプロセスは二個のsleepコマンドだとする。
[Service]
Type=forking
ExecStart=/work/startup.sh
$ systemctl damon-reload
$ systemctl start su_sleep
$ systemctl status su_sleep
● su_sleep.service
Loaded: loaded (/etc/systemd/system/su_sleep.service; static; vendor preset: disabled)
Active: inactive (dead)
ユニットファイルではメインプロセスに関する情報を明示していない。デフォルトでsystemdはメインプロセスを推測する(GuessMainPid=yes)から、この場合は、suコマンド自体をメインプロセスと認識する。suコマンドはメインプロセスであるはずのsleepを2個バックグラウンドで起動して戻ってくる。するとsystemdはメインコマンド終了と誤認してせっかく起動した名プロセスであるsleepもkillしてしまう。つまるところ何も残らない。
実際にこのようなトリッキーなスクリプトを書く人はいないと思われるかもしれないが、それなりのシェアを誇る製品の起動コマンドがこういう作りになっていたのにでくわした(PostgresqlとTomcatを製品専用ユーザで起動)。
こういうときは仕方がないのでType=oneshotかつRemainAfterExit=yesとしてとりあえず起動コマンド実行しました、で逃げるしかない。またはサービスユニットを分けられるのであればそうするべきだ。せっかくなのでサービスプロセスはすべてsystemdの管理下(cgroup)に置きたいところだ。
次にもう一つだけ、とても複雑な起動シーケンスを持ったものにも出くわした。
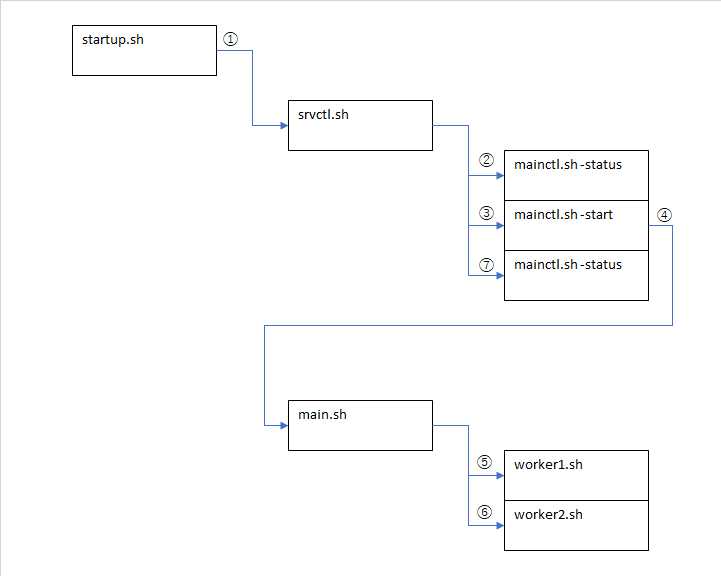
実線矢印がforkを表す。実際にはもっと複雑だったが、とにかくややこしい起動シーケンスになっている。
startup.shが起動コマンドで、そこから起動コントローラとなるsrvctl.shを呼出す(①)。srvctl.shはまず起動ステータスを確認し(②)、未起動ならメインプロセス起動コマンドであるmain.shを実行する(③④)。この④の呼出し処理は、setsidを使用してデーモンモードでなされる。そこから実際の作業プロセスであるworker[12].shを呼出す。
さらに、何らかの仕組みですべてのワーカープロセスが起動したことをコントローラが検知し、再度ステータス確認を実行する(⑦)。そしてその結果が正常ならば、起動コマンドおよび起動コントローラ自体がリターンする。つまり、最後に残るプロセスは、main.sh、worker1.sh、worker2.shになるというもの。
これを簡単にシミュレートしてみる。
# !/bin/bash
$(dirname $0)/srvctl.sh
# !/bin/bash
# pre-check
$(dirname $0)/mainctl.sh check1
# run
$(dirname $0)/mainctl.sh run
# post-check
$(dirname $0)/mainctl.sh check2
# !/bin/bash -xv
case $1 in
check1) exit 0;;
run) setsid $(dirname $0)/main.sh >/dev/null 1>&2 </dev/null & ;;
check2) exit 0;;
esac
while true; do
test -f $(dirname $0)/done.flg && exit 0
done
# !/bin/bash -xv
sleep 1000 &
sleep 1000 &
touch $(dirname $0)/done.flg
trap '/bin/rm -f $(dirname $0)/done.flg && exit 0' 1 2 3 15
while true; do
sleep 6
done
[Service]
Type=forking
ExecStart=/work/a/startup.sh
$ systemctl daemon-reload
$ systemctl start complex
$ systemctl status complex
● complex.service
Loaded: loaded (/etc/systemd/system/complex.service; static; vendor preset: disabled)
Active: active (running) since 水 2019-07-03 20:27:14 JST; 9s ago
Process: 7270 ExecStart=/work/a/startup.sh (code=exited, status=0/SUCCESS)
Main PID: 7277 (main.sh)
CGroup: /system.slice/complex.service
|-7277 /bin/bash -xv /work/a/main.sh
|-7286 sleep 1000
|-7287 sleep 1000
|-7300 sleep 6
現場ではうまくいかなかったのだが、うまくいった(main.shがメインプロセスであると認識している)。
現場ではsrvctl.shがメインプロセスであると誤認し、srvctl.shがexitしたタイミングでmain.sh以下も強制終了するような状態だったが、setsidで起動したプロセスがメインプロセスであるときちんと認識している。
man systemd.serviceの"GuessMainPID="の項目には、
The guessing algorithm might come to incorrect conclusions if a daemon consists of more than one process.
と記載されているから、このアルゴリズムと相性の悪い起動シーケンスを持った(おそらくは相対的に)複雑な起動コマンドでは、そのような目にあう可能性がある。現場のケースでは、幸いにもメインプロセスがPIDファイルを出力することが分かったので、PIDFileをユニット定義に指定することで事なきを得た。OSバージョンも違う(現場はRHEL7.3)ので単純に挙動が異なるだけかもしれない。
やはり具体的にどのようなアルゴリズムなのかが気になるので、ソースを追いかけてみる(とりあえず現時点最新版)。
static void service_search_main_pid(Service *s) {
pid_t pid = 0;
int r;
assert(s);
/* If we know it anyway, don't ever fallback to unreliable
* heuristics */
if (s->main_pid_known)
return;
if (!s->guess_main_pid)
return;
assert(s->main_pid <= 0);
if (unit_search_main_pid(UNIT(s), &pid) < 0)
return;
log_unit_debug(UNIT(s), "Main PID guessed: "PID_FMT, pid);
if (service_set_main_pid(s, pid) < 0)
return;
r = unit_watch_pid(UNIT(s), pid, false);
if (r < 0)
/* FIXME: we need to do something here */
log_unit_warning_errno(UNIT(s), r, "Failed to watch PID "PID_FMT" from: %m", pid);
}
unit_search_main_pid()が実装部らしい。これを探すとどうやらcore/cgroup.cあたりにあるのがそれっぽい。
int unit_search_main_pid(Unit *u, pid_t *ret) {
_cleanup_fclose_ FILE *f = NULL;
pid_t pid = 0, npid;
int r;
assert(u);
assert(ret);
if (!u->cgroup_path)
return -ENXIO;
r = cg_enumerate_processes(SYSTEMD_CGROUP_CONTROLLER, u->cgroup_path, &f);
if (r < 0)
return r;
while (cg_read_pid(f, &npid) > 0) {
if (npid == pid)
continue;
if (pid_is_my_child(npid) == 0)
continue;
if (pid != 0)
/* Dang, there's more than one daemonized PID
in this group, so we don't know what process
is the main process. */
return -ENODATA;
pid = npid;
}
*ret = pid;
return 0;
}
whileのところでCGroup内のPIDをひとつずつチェックし、PID=0と自分(つまりsystemdそのもの)の子プロセス以外はスキップする。スキップされなかったらそのPIDをpidにセットし、さらにスキップされないPIDがみつかったらreturn -ENODATAしている(ように読み取れる)。
あれ?ということは複数プロセス生成するパターンはいったんこの処理はエラーで抜けるということか、、、参照ソースが違う?
本件はしばらく保留としておく(気が向いたらまた調べてこっそり追記予定)。
-
例えばWebSphere Application Serverの停止コマンドはWASプロセス(つまりjavaプロセス)にSOAP通信でシャットダウン命令を出すため、プロセスがOOME寸前のような不安定な状態だと正常に停止できない可能性がある。 ↩