この記事は何
TensorFlow が 2.0 にアップデートされ、学習コードのカスタムループ ( Keras での .fit() などではなく、自前で iteration を回す書き方 )が非常に書きやすくなりました。
その中で Gradient Accumulation を実装しようとしたときに少し詰まったため、メモとして公開します。ここ間違ってるよ!とかもっと良いやり方があるよ!という場合はぜひ教えてほしいです🙏
Gradient Accumulation とは
ざっくりです。詳しい説明は他を当たってください🙇♂️
Deep Learning モデルの学習のためには、一般的に多くの GPU メモリが必要となります。
より大きなモデルを学習する際には数十 GB というメモリが必要となるため、多くの場合は単純に入力の batch size を小さくすることで対応します。
この方法を選択した場合、batch size が小さくなるので次のようなデメリットがあります。
- 学習に時間がかかる
- 精度が劣化する
特に後者は深刻な問題で、batch size を小さくすることで精度が劣化するという報告や、学習時に learning rate を調整するのではなく batch size を大きくするほうが性能改善につながるなどの報告がされています(特に自然言語処理の分野)123。
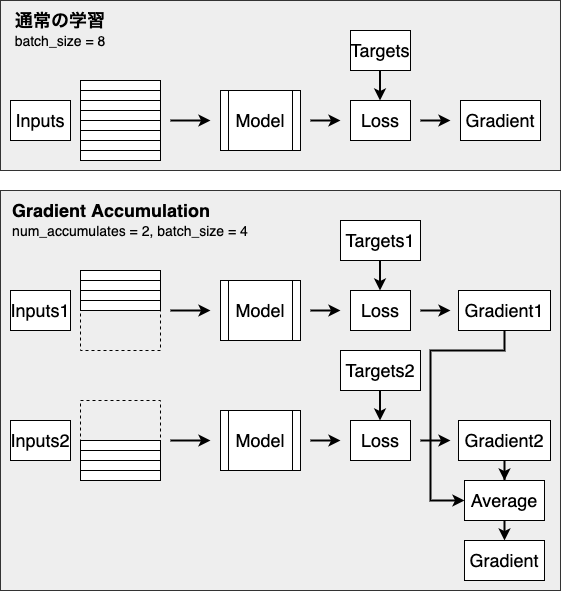
そこで、batch size を大きくしたまま、メモリ効率をよく計算する方法の1つとして、gradient accumulation が挙げられます。
やることは単純で、小さい(メモリに乗る量の) batch size で計算した gradient を保存しておき、複数回分ためてから平均を取り、それを用いてモデルのパラメータを更新する、というものです。
複数回分の batch の計算で 1 step となるため、時間はかかってしまいますが、大きな batch size でモデルを学習させるのと同等になるため、精度は維持することができます。
TensorFlow 2.0 カスタムループでの実装
雑に簡略化した学習用コードを書いてみました。
説明用の notebook はこちらにおいてるので詳細見たい方はご覧ください〜😎
通常の学習 (gradient accumulation を使用しない) の場合
train_step 内の tape.gradient(loss, model.trainable_variables) で loss から gradient を計算し、optimizer に渡して更新しています。
def train(config: Config,
dataset: tf.data.Dataset,
model: Model):
global_step = 0
for e in range(config.num_epochs):
global_step = train_epoch(config, dataset, model, global_step)
print(f'{e+1} epoch finished. step: {global_step}')
save(config.ckptdir, model)
def train_epoch(config: Config,
dataset: tf.data.Dataset,
model: Model,
start_step: int = 0) -> tf.Tensor:
'''Train 1 epoch
'''
gradients = None
global_step = start_step
for i, batch in enumerate(dataset):
global_step = i + start_step
x_train, y_train = batch
gradients = train_step(x_train, y_train, loss_fn, optimizer)
gradient_zip = zip(gradients, model.trainable_variables)
optimizer.apply_gradients(gradient_zip)
return global_step
@tf.function
def train_step(x_train: tf.Tensor,
y_train: tf.Tensor,
loss_fn: tf.keras.losses.Loss,
optimizer: tf.keras.optimizers.Optimizer):
'''Train 1 step and return gradients
'''
with tf.GradientTape() as tape:
outputs = model(x_train)
loss = tf.reduce_mean(loss_fn(y_train, logits))
gradients = tape.gradient(loss, model.trainable_variables)
return gradients
gradient accumulation の場合
複数ステップの gradients の平均を計算するためのメソッドを追加します。 tape.gradient(loss, model.trainable_variables) では各パラメータごとの tf.Tensor 型の gradientが List で返るため、それぞれの要素について平均を取るようにします。
def accumulated_gradients(gradients: Optional[List[tf.Tensor]],
step_gradients: List[tf.Tensor],
num_grad_accumulates: int) -> tf.Tensor:
'''Compute accumulated gradients by ones of this step and ones of accumulated
Args:
gradients: computed accumulated gradients so far
step_gradients: gradients for this step
num_grad_accumulates: the amount of accumulation
'''
if gradients is None:
gradients = [g / num_grad_accumulates for g in step_gradients]
else:
for i, g in enumerate(step_gradients):
gradients[i] += g / num_grad_accumulates
return gradients
train_step で得られた step_gradients に上記の accumulated_gradients を適用して平均の gradients を得ます。
加えて、指定回数分計算されたときだけ optimizer でパラメータ更新を行うようにします。
def train_epoch(config: Config,
dataset: tf.data.Dataset,
model: Model,
start_step: int = 0) -> tf.Tensor:
'''Train 1 epoch
'''
gradients = None
global_step = start_step
for i, batch in enumerate(dataset):
dummy_step = i + start_step * config.num_grad_accumulates
x_train, y_train = batch
step_gradients = train_step(x_train, y_train, loss_fn, optimizer)
gradients = accumulated_gradients(gradients, step_gradients, config.num_grad_accumulates)
if (dummy_step + 1) % config.num_grad_accumulates == 0:
gradient_zip = zip(gradients, model.trainable_variables)
optimizer.apply_gradients(gradient_zip)
gradients = None
if (global_step + 1) % config.step_summary_output == 0:
write_train_summary(train_summary_writer, metrics, step=global_step + 1)
global_step += 1
return global_step
@tf.function
def train_step(x_train: tf.Tensor,
y_train: tf.Tensor,
loss_fn: tf.keras.losses.Loss,
optimizer: tf.keras.optimizers.Optimizer):
with tf.GradientTape() as tape:
outputs = model(x_train)
loss = tf.reduce_mean(loss_fn(y_train, logits))
gradients = tape.gradient(loss, model.trainable_variables)
return gradients
tf.gather などの IndexSlices が得られる演算を使用している場合
先に結論
次のような flat_gradient をかませばOKだと思います。メモリ効率は若干悪くなるので、もっと良いやり方が分かる方は教えていただけると幸いです ![]()
def accumulated_gradients(gradients: Optional[List[tf.Tensor]],
step_gradients: List[Union[tf.Tensor, tf.IndexedSlices]],
num_grad_accumulates: int) -> tf.Tensor:
'''Compute accumulated gradients by ones of this step and ones of accumulated
Args:
gradients: computed accumulated gradients so far
step_gradients: gradients for this step
num_grad_accumulates: the amount of accumulation
'''
if gradients is None:
gradients = [flat_gradients(g) / num_grad_accumulates for g in step_gradients]
else:
for i, g in enumerate(step_gradients):
gradients[i] += flat_gradients(g) / num_grad_accumulates
return gradients
def flat_gradients(grads_or_idx_slices: tf.Tensor) -> tf.Tensor:
'''Convert gradients to original size tf.Tensor if it's tf.IndexedSlices.
When computing gradients for operation concerning `tf.gather`, the type of gradients is tf.IndexedSlices.
'''
if type(grads_or_idx_slices) == tf.IndexedSlices:
return tf.scatter_nd(
tf.expand_dims(grads_or_idx_slices.indices, 1),
grads_or_idx_slices.values,
grads_or_idx_slices.dense_shape
)
return grads_or_idx_slices
説明
自然言語処理の分野で embedding layer を使用しているなどのケースでは、モデルで tf.gather を利用していることが多いと思います。tf.gather を使っていると、 tape.gradient(loss, model.trainable_variables) の返り値の List の中身の型が変わります。
具体的に BERT のモデルで gradients を計算したものを見てみたのが下記です。
[
<tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6358>,
<tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6400>,
<tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6438>,
<tf.Tensor: shape=(1024,), dtype=float32, numpy=array([ 0.00075448, 0.00063159, 0.00468317, ..., 0.00663265, 0.00084392, -0.00198008], dtype=float32)>,
....
]
4行目からは通常の tf.Tensor 型の gradients が続きますが、3行目までが tf.IndexedSlices 型になってます。
tf.gather は Embedding Matrix のような大きな行列から、特定の index の部分を取ってくるのに使われます。
TensorFlow > API > TensorFlow Core r2.1 > Python > tf.gather
自然言語処理の例で言うなら、元の embedding matrix は [vocab_size, embedding_size] の shape の行列で、vocab_size は数万オーダーになることが多いので、めちゃでかいです。
メモリ効率を上げるために、元の embedding matrix をまるまる保持するのではなく、必要な部分の Slice のみを保持するようにしたのが tf.IndexSlices 型になります。
TensorFlow > API > TensorFlow Core r2.1 > Python > tf.IndexedSlices
このまま gradients の平均を取ろうとすると、 tf.Tensor 型ではないので四則演算などがそのまま適用できずエラーになります。今回は次のように元の matrix を復元して対応しています4。
tf.scatter_nd(tf.expand_dims(idx_slices.indices, 1),
idx_slices.values,
idx_slices.dense_shape)
-
Large Scale GAN Training for High Fidelity Natural Image Synthesis ↩
-
RoBERTa: An optimized method for pretraining self-supervised NLP systems ↩
-
How can I make TensorFlow 2.0 handle piecewise gradients (e.g. across
tf.gather)?
以上です。
Pytorch は gradient accumulation めっちゃ簡単に出来るので羨ましいです ↩
↩