本記事は、ミクシィグループ Advent Calendar 2018 の15日目の記事です。
この記事について
私のチームは、新規事業として chatbot 周りの技術に取り組んでいます。
自然言語処理の分野では、昨年の6月に Attention Is All You Need [1] という論文で発表された、 Attention ベースのモデルである Transformer がもはやデファクトスタンダードとなりつつあります。
その一環で Unviersal Transformer [2]という Transformer を拡張した(と主張している)モデルを実装・検証しました。
最終的に業務ではまだ使えないねという結論になったのですが、せっかくなのでアドベントカレンダーの場を借りて紹介記事を書きたいと思います。いわば墓場です。
目次
- Universal Transformer 論文概要
- 実装の紹介 cfiken/universal_transformer
- 学習能力についての簡単な実験
- 業務での検討
- まとめ
Universal Transformer 論文概要
はじめに述べたとおり、Universal Transformer は Transformer を拡張したモデルです。Universal Transformer の概要を理解するには、Transformer を理解している必要がありますが、Transformer については既に著名な方による解説があるため、ここでは割愛します。
Transformer について知りたい方は、下記を読むと良いと思います ![]()
論文解説 Attention Is All You Need (Transformer)
作って理解する Transformer / Attention
本記事では、主に Transformer との違いを中心に説明します。
Transformer の欠点と Universal Transformer
Transformer は RNN に比べて並列計算効率がよく、性能が高いことが知られていますが、次のような欠点も挙げられています。
- inductive bias (帰納バイアス) が弱く、未知の系列に対応しづらい
- 例えば、 トレーニング時にないような長い系列が来ると対応できない
- RNN は、recursive な構造によりこの点が多少保証されていると言われている
- 結果的に Algorithmic なタスクや言語理解のタスクは苦手
これに対して、著者らは
- Transformer の並列計算の効率性と広い receptive field を維持したまま、
- RNN のような recurrent な構造による inductive bias を得る
ことを目的として、 Universal Transformer を提案しました。
Universal Transformer と Transformer の違いは大きく分けて次の2点です。
- 各ブロックを Recurrent に適用する(変数を共有する)
- 各 Symbol のブロック数に Adaptive Computation Time を適用する
これらの改善により、具体的に次を達成しました。
- QA のデータセット bAbI で state of the art を達成 (10kデータ使用で全問正解)
- 機械翻訳のタスクで Transformer とだいたい同じパラメータ数で Transformer を上回った (翻訳能力も高い)
他にも Algorithmic なタスクや、LAMBADAなど、いくつか実験をされているので、詳しくは論文を読んでください ![]()
ここからは、2つの違いについて順に説明します。
各ブロックを Recurrent に適用する
Transformer では、入力系列に対して適用する一連の処理を1ブロックとし、ブロックを複数重ねることで特徴を作っています。
下記が Transformer のアーキテクチャ図[^1]です。
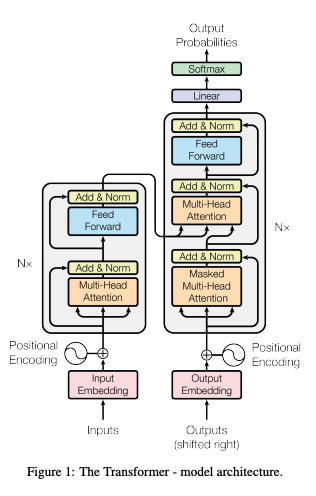
図1: Attention Is All You Need, Figure 1 より引用
Encoder と Decoder に分かれていますが、それぞれでブロックになっており、Encoder では Mulit-Head Attention レイヤと FFN レイヤで、Decoder では2つの Multi-Head Attention レイヤと FFN レイヤで1つのブロックになっています。
横に Nx と書かれている通り、このブロックを$N$回分 (Transformer では $N=6$) 繰り返します。
そして、下記が Universal Transformer の論文にあるアーキテクチャ図[^2]です。
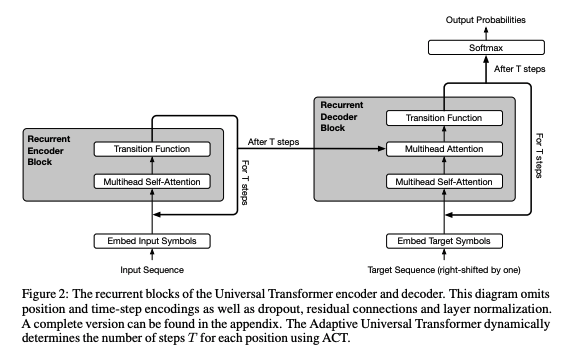
図2: Universal Transformers, Figure 2 より引用
Transformer と同様に Encoder-Decoder の構造ですが、For T Step や Recurrent Encoder Block などとあるように、Transformer と違って同じ変数を持つレイヤを繰り返し適用する Recurrent な構造になっています。
これについては Universal Transformer が紹介されている Google AI Blog の画像がわかりやすいです。
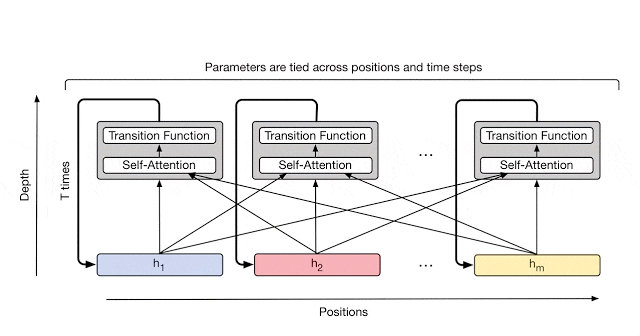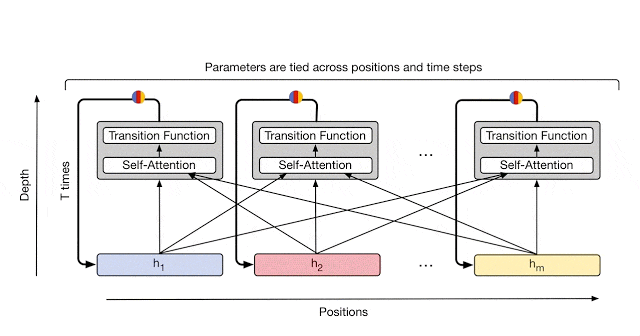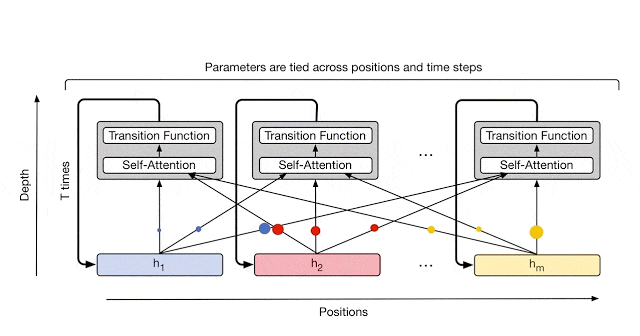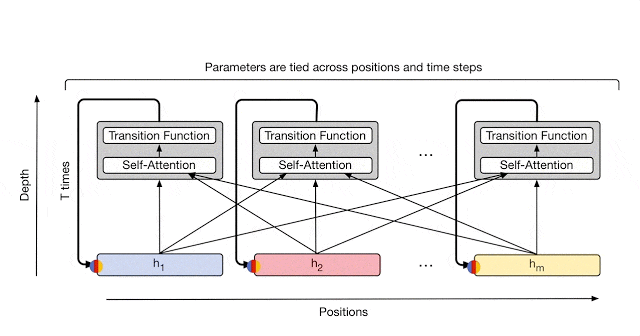
図3: https://ai.googleblog.com/2018/08/moving-beyond-translation-with.html より引用
この点で、Universal Transformer は Transformer と RNN を組み合わせた手法だと考えることが出来ます。
RNN との違いは、RNN では、Recurrence が symbol 方向に発生するのに対して、 Universal Transformer は Depth 方向 (全ての symbol の representation ごと) に Recurrence を持つ構造になっています。
これにより、RNN の inductive bias を得つつ、Transformer のメリットである並列計算の効率性(各 symbol ごとに並列計算できる)を担保しています。
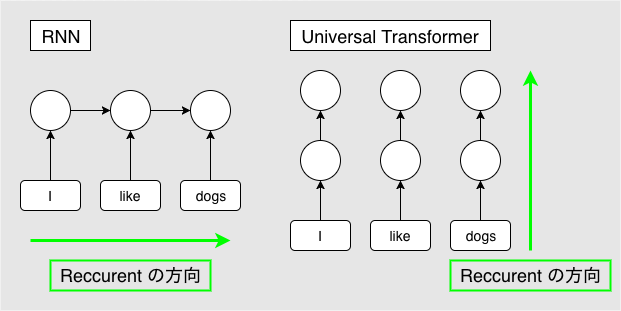
図4: RNN と Universal Transformer の Reccurent 方向の違い
Adaptive Computation Time (ACT) を導入する
Adaptive Computation Time [4] は2016年に RNN に対して提案された手法です。
詳しくは元論文 Adaptive Computation Time for Recurrent Neural Networks もしくは、Qiita の解説記事である ACT (Adaptive Computation Time) が詳しいです。
詳解はしませんが、仕組み自体はそこまで難しいものではありません。
前節で紹介した Reccurent Block の適用回数を、 symbol ごとに動的に決める仕組みです。
これにより、解釈がはっきりしている symbol については少なく、曖昧性の強い symbol は多く適用することが可能になり、実際にいくつかのタスクでスコアが上がったことが実験にて確認されています。
上記ブログでの例を引用します。次のような文章を考えます。
“I arrived at the bank after crossing the river”
ここで、 I や river という一意な単語に対して、 bank という単語は「土手」や「銀行」などと複数の意味があるため、特定にはコンテキストを見る(riverを見つける)必要があります。
相対的に曖昧性の強い単語(今回で言う bank)があるとき、それに計算リソースをより多く使うのは合理的と言えるでしょう。
通常の Universal Transformer では、全ての symbol に対して同じ回数分 Block を適用しますが、ACT を導入することで曖昧性の高い単語のみをより多く反復させ、計算量を抑えつつより高次の特徴を捉えることが出来る、とのことです。
今回の例だと、 I や river は早い段階で反復を終え(halt)、残りの反復の間は値をコピーして渡します。
ACT を導入した Universal Transformer を、通常のものと区別するために Adaptive Universal Transformer と呼びます。
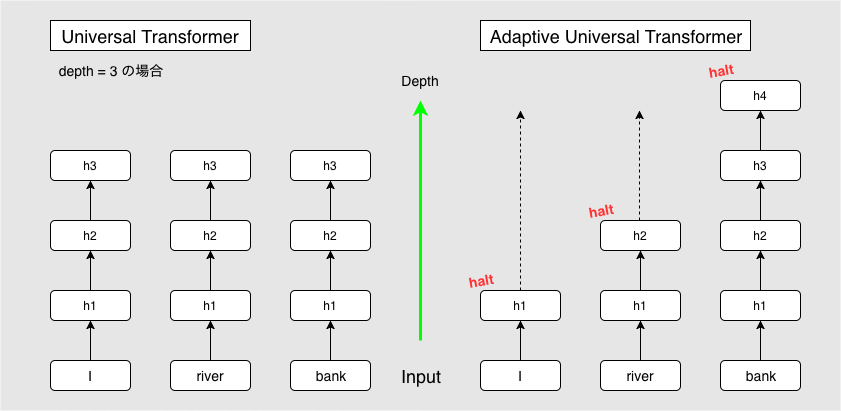
図5: Adaptive Computation Time (矢印を省略していますが Attention レイヤがあるため実際は全入力から全出力に矢印が伸びます。)
実装の紹介
公式の実装
論文にもある通り、tensorflow のリポジトリである tensor2tensor で実装が公開されています。主要部分は下記です。
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/research/universal_transformer.py
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/research/universal_transformer_util.py
私見ですが、まぁまぁ読みづらいです。tensor2tensor のベースの上に乗っていること、実験コードらしく論文にもないようなハイパーパラメータが色々と定義されていること、たまに謎な箇所があることなど、普段から利用している人ならともかく、初見で読み解くには結構体力を使う上に、誤解を生みやすいように思います。
TensorFlow の Eager Execution (と Keras)による実装
しばらく前に、TensorFlow/models リポジトリ の official 以下に Transformer が移植されました。tensor2tensor の実装とは違い、こちらはレイヤーベースで各処理が定義され、整理もされて読みやすくなっています。
今回は、 Universal Transformer を上記 official の Transformer を基にして実装しました。
https://github.com/cfiken/universal_transformer
公開してますがモデル周り以外はあまり整理できていません。ちょっとずつきれいにして他の方でも使えるように出来たらと考えています(果たしているのか??)。何かあればツッコミいただけると助かります ![]()
せっかくなのでオリジナルの Transformer も次のように少し変更しています。
- Eager Execution 前提で作っている (Graph モードでは未検証)
- Keras のモデルやレイヤーを使っている (tf.layer.Layer を見ると Keras を使うよう書かれている)
official の Transformer に合わせて作ったため、 tensor2tensor の Universal Transformer とはアーキテクチャが微妙に変わっています(official Transformer に合わせただけなので、そこまで影響はないと考えています)。
Eager Execution を使うことで、ACT などループの部分がかなり書きやすかったです。例えば tensor2tensor では、 ACT 部分を tf.while_loop を使って実装していますが、これめちゃくちゃややこしいんですよね。普通のループで書けるのはかなり助かりました。
学習能力についての簡単な実験
Universal Transformer と Transformer を比較して、論文内にあったような Universal Transformer のメリットが分かるような実験をする予定だったのですが、学習に時間がかかってしまい、それは次回にしたいと思います。
今回は、単純な学習能力を Transformer と比較してみました。適当な会話のデータセットを使って、トレーニング時の accuracy がどれほど上がるか(訓練データセットをどれくらい再現できるか)を比べてみました。
予測としては、Universal Transformer は特に汎化性能に影響があると解釈していたため、トレーニングデータに対する性能は Transformer と同じか、上がっても少しかな、と考えていました。
モデル
次のモデルで比較を行いました。
- Transformer: 1 Layer, 1024 Units
- Transformer: 4 Layer, 512 Units
- Universal Transformer: 4 Block, 1024 Units
- Adaptive Universal Transformer: Max 20 Block, 1024 Units, ACT loss weight 0.01
パラメータ数は(1)以外はだいたい同じで、31~32M個です。
(1)は Universal Transformer と同じユニット数で 1Layer だった場合(Universal Transformer で繰り返し数が0だった場合)の比較のため追加しました。
トレーニング
下記の設定で、データの ask (問い) を入れて res (返事) を予測するように学習を行いました。翻訳などと同じようなものです。
batch size: 32 (もっと大きくしたかったがメモリが... ![]() )
)
learning rate: Transformer の論文に書かれているもの (warmup steps = 4000)
vocab_size: 3278 (データセットから作成)
データ数: 約30万セット(ask & res)の会話
(他にも細かいの色々ありますが割愛、リポジトリに置いてます)
結果
今回は学習能力の検証ということで、これはトレーニングデータに対する accuracy の Tensorboard のグラフです。
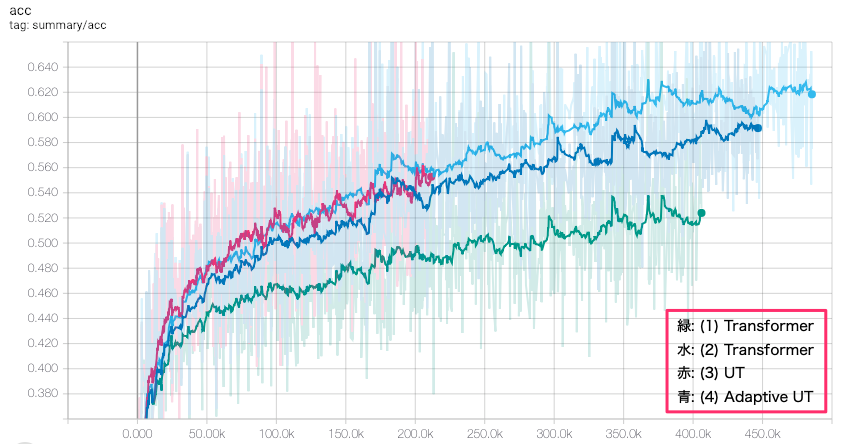
図6: トレーニングデータに対する accuracy (横軸ステップ数)
パラメータ数がだいたい同じである2~4については、だいたい同程度の性能となりました。
青の Adaptive UT は、Transformer よりも明らかに性能が落ちている、ということはなさそうですが、少なくとも優ってはいないです。深さがある分、単純な学習能力においては Transformer の方が期待できそうです。
また、ユニット数が同等でレイヤー数1の Transformer と比較すると、明らかに良くなっているので、Recurrent な構造による効果といえるでしょう。
次に、横軸をステップ数ではなく時間で見てみます。学習にかかる時間は気になるところです。
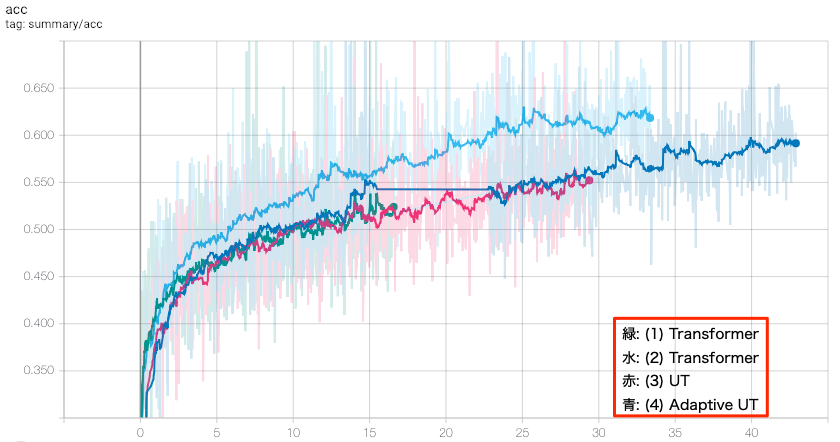
図7: トレーニングデータに対する accuracy (横軸時間)
青の Adaptive UT の例のみ、途中で一度止めてしまったためまっすぐ伸びているところがあります。
スピードでいうとやはり Transformer にはかなり差をつけられています。ざっと見で二倍以上は違いそうです。
最後に、Adaptive UT の pondering (繰り返し回数) を見てみます。
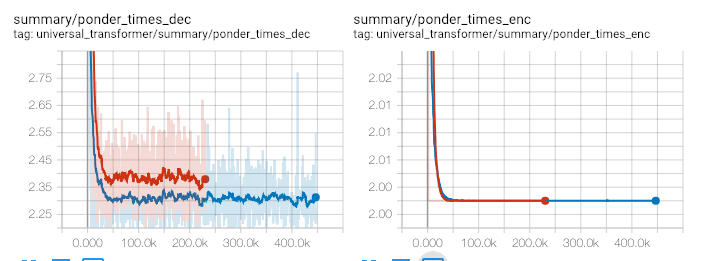
図8: トレーニング時の Adaptive UT の pondering 平均回数(繰り返し数)
左が Decoder, 右が Encoder、赤が act loss weight = 0.001, 青が act loss weight = 0.01
Encoder の pondering はほぼ2回で収束していました。Decoder についても、2.3~4回ほどに収まっています。今回のタスクのせいなのかもしれませんが、あまり pondering していない、という結果になりました。推論時の方がわかりやすそうなので、こちらも今後試してみたいと思います。
チームでの chatbot としての検討
最初にも述べた通り、今回の実装ではまだ使えないね、ということになりました。
理由は単純で、推論が Transformer に比べてかなり遅いという点です。
ある程度遅いのは予想していましたが、想像以上(Transformer の5倍~)に遅かったため、細かい実験はまだ出来ていませんが一旦見送りとなりました ![]()
論文中にもありますが、 Universal Transformer は Transformer と Computational Universal な手法 (Neural GPU [6] など)の間を取ったような手法で、今後も発展がありそうではあるので、引き続き改善があれば挑戦してみたいと思います。
まとめ
- Universal Transformer について、 Transformer との違いを中心に紹介しました。
- TensorFlow の Eager Execution モードで実装し、github で公開しました。
- 学習能力についての簡単な実験を行いました。
- 残念ながらチーム内では採用とはなりませんでしたが、いい勉強になりました

- アルゴリズム的なタスクについての実験はまた記事にしたいと思います。