この記事は大半をAIに書かせたものを加筆修正しております。
はじめに
オンライン翻訳は手軽ですが、入力テキストがクラウドに送信されるという前提ゆえに、機密保持の観点で使いづらい場面があります。実際、DeepL の無料版では、入力テキストやアップロードした文書・訳文が「『ニューラルネットワークの訓練および性能向上』を目的に一定期間保存される」と、公式の日本語プライバシーポリシーに明記されています(有料版では保存・学習に用いない運用が別途示されています)。(DeepL)
また、クラウド送信による情報露出のリスクは過去の事例からも読み取れます。2015年には無料翻訳サイト 「I Love Translation」 で、ユーザーが入力した原文や訳文が誰でも閲覧できる状態となり、検索エンジン経由で見えてしまったことが報じられ、国内でも複数メディアが注意喚起や解説を行いました。(piyolog)
本OSSは、こうしたクラウド送信の前提を持たないローカル翻訳を実現するためのものです。ローカルの LM Studio(OpenAI 互換 API)へ、PLaMo翻訳固有の設定(後述)を自動付与して送信します。テキストを外部に出さずに和⇔英のローカル翻訳ワークフローを構成できます。以下では、何を作ったのか・どう使うのかを順に説明します。
何を作ったか
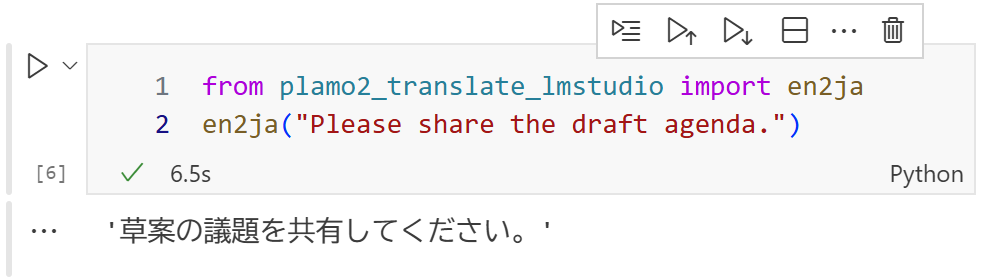
最初に述べた課題(クラウド送信を前提としない翻訳)に対し、plamo-2-translate を用いた実装としました。
LM Studio の OpenAI 互換 APIへ、plamo-2-translate が要求する固有の設定(後述)を付与・送信するPythonモジュール plamo2_translate_lmstudio を作成しました。和⇔英を中心に、ローカルのJupyter Notebook上での使用を想定しています。
インストール方法・使い方は下記リポジトリを参照ください。
リポジトリ:
Jupyter Notebookでの使用例:
(参考) plamo-2-translateとは
plamo-2-translate(PLaMo翻訳)は、Preferred Networks(PFN)グループが開発した翻訳特化型の国産LLMです。2025年5月27日のPFN公式リリースでは、デモ公開とともに「PLaMo Community License」での提供が発表され、個人と年商10億円未満の企業はオンプレミス環境で商用・非商用を問わず無償利用可能と説明されています。(Preferred Networks, Inc.)
PFNの技術ブログでも、PLaMo翻訳をPLaMoシリーズの“特化モデル”として位置づけ、公開デモや配布形態、開発背景が解説されています。PFN/Preferred Elementsの取り組みとして、高性能かつ軽量なモデル群(PLaMo 2系)の一環であり、実運用を強く意識した設計であることが示されています。(tech.preferred.jp)
国内メディアの報道では、PLaMo翻訳は日本語⇔英語の高品質な訳出を狙って和英比率の高い独自データセットで学習されたことの紹介や、ブラウザ拡張や翻訳デモの公開が示されています。(IT Leaders)
PFNは、PLaMoシリーズの公共分野への提供や国内研究機関との共同開発もニュースになっています。plamo-2-translate はその一系統として、“翻訳に特化しつつローカル運用も視野に入れた”現実解のモデルだと理解できます。(Preferred Networks, Inc.)
この記事で扱うモジュールは、上記 plamo-2-translate を LM Studio(OpenAI互換API) 経由で“そのまま”ローカル実行しやすくするための薄いラッパーです(詳細は次節)。
既存ツールとの違い
下記に、LM Studio を翻訳エンジンとして活用できる周辺ツールを挙げます。
- PFN公式 plamo-translate-cli(Python/CLI):PLaMo翻訳の公式コマンドライン。ローカル実行に最適化されているが LM Studio 専用ではない。
-
LM Studio 公式SDK/OpenAI互換API:
pip install lmstudioでPythonから直接呼び出せ、既存のOpenAIクライアントもbase_url=http://localhost:1234/v1に切り替えて利用できる 汎用API。 - llama-index-llms-lmstudio:LlamaIndexからLM Studioを叩く 汎用統合。
- llm-translate(Web/JS):LM Studioをバックエンドにできる Webツール(PLaMo-2の利用ガイドあり)。
- llmtranslate(Python):LangChain依存の翻訳ライブラリ。
-
Subtitle-Translator-for-LM-Studio(Web):
.srt字幕の一括翻訳に特化した Webアプリ。 - VNTranslator 連携:ビジュアルノベル翻訳アプリからLM Studioを 設定で利用可能。
これらは「ローカルでモデルを呼ぶ」「UIから素早く訳す」といった用途には十分ですが、Notebook/スクリプト前提で、和⇔英の往復やPLaMo翻訳固有の設定(後述)、言語切替までを“翻訳用の最小API”として丸ごと吸収する設計ではありません。特にPythonライブラリ系は LangChainのような重量級依存が前提になりやすく、軽量に直接組み込みたいニーズとは相性が分かれます。
本モジュールは PLaMo翻訳に特化し、LM Studio を前提に、en2ja/ja2en/translate/translate_ja_en の4関数だけでコードから安定運用できるよう、PLaMo書式等を裏側で処理します。GUIに寄らずNotebookで翻訳したい、LM Studio×PLaMo翻訳前提で一括処理など自由度の高い処理を行いたいといった場面で最短経路になるはずです。なお 「PLaMo翻訳特化 × LM Studio前提 × OSS Pythonモジュール」に該当する同等OSSは、執筆時点(2025-09-29)では未確認です。
本モジュールの特徴
入力フォーマットとNotebookでの簡単実行
PLaMo翻訳は下記の専用フォーマットで入力します(PFNモデルカードの Usage 準拠)。和→英なら input/output を入れ替え、生成時は stop=["<|plamo:op|>"] を指定します。
<|plamo:op|>dataset
translation
<|plamo:op|>input lang=English
(本文)
<|plamo:op|>output lang=Japanese
本モジュールはこの面倒な書式を自動生成するので、リポジトリ同梱Jupyter Notebookのサンプルのように通常の関数呼び出しだけで翻訳できます。
from plamo2_translate_lmstudio import translate
# 英→和
print(translate("Where are you from?", src_lang="English", tgt_lang="Japanese"))
# 和→英
print(translate("本日の会議資料を共有しました。", src_lang="Japanese", tgt_lang="English"))
普段使いの4関数(用途で使い分け)
-
en2ja(text): 英→和 -
ja2en(text): 和→英 -
translate(text, src_lang="English", tgt_lang="Japanese"): 任意ペア -
translate_ja_en(src_lang, text):
"Japanese"・"ja"・"jp"/"English"・"en"を入力で和⇔英を自動切替
from plamo2_translate_lmstudio import en2ja, ja2en, translate_ja_en
print(en2ja("Please review the pull request.")) # 英→和
print(ja2en("来週の予定を確認してください。")) # 和→英
print(translate_ja_en("ja", "議事録を送付しました。")) # 和→英
print(translate_ja_en("en", "The glossary has been updated.")) # 英→和
他の PLaMo 翻訳モデルを使う
量子化違い等の別モデルIDを使いたい場合は、PlamoTranslator への引数入力で指定できます(LM Studio の My Models に表示される identifier を利用)。
from plamo2_translate_lmstudio import PlamoTranslator
translator = PlamoTranslator(
base_url="http://localhost:1234/v1",
model="mmnga/plamo-2-translate-gguf", # 任意のPLaMo翻訳モデルIDに差し替え
timeout_sec=45,
)
en2ja = translator.en2ja
translate = translator.translate # 他も同様にtranslatorから呼び出せる
# 実行が1行のみの場合はそのままreturnできるためprint()不要
en2ja("Please submit the quarterly report.")
ヒント:トップレベル4関数でも
temperature/top_p/top_k/max_tokens/stop等の生成パラメータをそのまま渡せます。用途に合わせて微調整してください。
ループを使って一括処理
長大な文章に対しては、いくつかの要素に分割することで一括処理を行うことが可能です。下記はその簡単な例です。実運用時は「複数の論文を順次翻訳する」というようなことも可能でしょう。
長文翻訳時には、en2ja = PlamoTranslator(timeout_sec=20000).en2jaやen2ja(text, timeout_sec=20000)のようにタイムアウト時間の変更が必要です。規定は10000秒です。
texts = [
"When teams discuss “local-first” machine translation, the debate often begins with infrastructure and ends with policy. In between, there is a messier middle: procurement constraints, GPU scarcity, endpoint hygiene, and the social dynamics of who trusts what. This report summarizes what we learned while moving a medium-sized organization from cloud-based translation to a local stack powered by a compact, domain-adaptable model.",
"The baseline problem looked simple. Analysts needed fast EN↔JA translation for product documentation, incident postmortems, and contracts. The cloud service they had used for years was accurate and convenient, but several red flags accumulated: data residency questions from customers, a new internal policy banning externally hosted NLP for “confidential by default” artifacts, and a growing concern about inadvertent training on proprietary phrasing. The result was a mandate: keep text inside our network and maintain comparable quality and latency.",
"We approached the transition with four constraints: (1) minimal change to end-user workflow, (2) auditable request logs, (3) predictable cost per month, and (4) steady latency under 500 ms for short sentences (≤ 30 tokens). The fourth constraint turned out to be aspirational. With CPU-only servers and mixed loads, we initially saw 1.2–2.0 s per request for short inputs and a steep curve for longer paragraphs. The pragmatic fix was a warm-up routine and a small pool of persistent workers. It wasn’t glamorous, but it stabilized tail latency.",
"Quality raised a different set of issues. Generic models handled everyday phrasing well, but they struggled with house style and internal nomenclature—especially for product component names, error taxonomies, and phrases that look ordinary but carry legal nuance. We introduced a controlled glossary and a small “micro-fine-tune” pass using parallel snippets extracted from our own repositories. The change was not dramatic on standard metrics, but reviewer comments became more consistent: fewer awkward word orders, fewer “English-shaped Japanese,” and better handling of negative statements in incident summaries."]
from plamo2_translate_lmstudio import en2ja
for text in texts:
print(en2ja(text, timeout_sec=10000)) # PCスペックなどに応じてタイムアウト時間を調整 (上記文章量に対して1万秒は過剰だが)
実行時間計測
実行環境 (ノートPC)
- OS: Windows 11 Home
- CPU: 13th Gen Intel(R) Core(TM) i7-1355U 1.70 GHz
- RAM: 32.0 GB
- 使用モデル: plamo-2-translate-gguf (Q4_K_S)
- LM Studio コンテキスト制限: 4096
- その他翻訳生成関係のパラメータは本リポジトリ既定値
実行結果
ChatGPTに書かせた英語と日本語それぞれの長文について、翻訳するのにかかる時間を計測しました。
検証1
元文章
"""
Local-First Translation in Practice: A Candid Field Report
When teams discuss “local-first” machine translation, the debate often begins with infrastructure and ends with policy. In between, there is a messier middle: procurement constraints, GPU scarcity, endpoint hygiene, and the social dynamics of who trusts what. This report summarizes what we learned while moving a medium-sized organization from cloud-based translation to a local stack powered by a compact, domain-adaptable model.
The baseline problem looked simple. Analysts needed fast EN↔JA translation for product documentation, incident postmortems, and contracts. The cloud service they had used for years was accurate and convenient, but several red flags accumulated: data residency questions from customers, a new internal policy banning externally hosted NLP for “confidential by default” artifacts, and a growing concern about inadvertent training on proprietary phrasing. The result was a mandate: keep text inside our network and maintain comparable quality and latency.
We approached the transition with four constraints: (1) minimal change to end-user workflow, (2) auditable request logs, (3) predictable cost per month, and (4) steady latency under 500 ms for short sentences (≤ 30 tokens). The fourth constraint turned out to be aspirational. With CPU-only servers and mixed loads, we initially saw 1.2–2.0 s per request for short inputs and a steep curve for longer paragraphs. The pragmatic fix was a warm-up routine and a small pool of persistent workers. It wasn’t glamorous, but it stabilized tail latency.
Quality raised a different set of issues. Generic models handled everyday phrasing well, but they struggled with house style and internal nomenclature—especially for product component names, error taxonomies, and phrases that look ordinary but carry legal nuance. We introduced a controlled glossary and a small “micro-fine-tune” pass using parallel snippets extracted from our own repositories. The change was not dramatic on standard metrics, but reviewer comments became more consistent: fewer awkward word orders, fewer “English-shaped Japanese,” and better handling of negative statements in incident summaries.
Security and governance were decisive. Local inference did not automatically solve everything, but it made the threat model legible. We could say, with logs to prove it, that input never left subnets A/B, that models were pinned to checksummed artifacts, and that retention was limited to operational telemetry. During an external audit in March 2025, the ability to replay requests and show model versions shaved days off the review.
From a human-factors perspective, the most surprising friction came from expectations. People equate “local” with “instant” and “perfect.” Neither is a safe default. We set three simple norms: (a) default temperature 0.0 for determinism, (b) a one-click “re-run with diversity” button for tricky edge cases, and (c) a visible banner indicating token limits and expected runtime. Once these norms were in place, complaints dropped notably.
We also learned to communicate failure modes. For example, numeric tables sometimes suffered from spurious unit conversions or misplaced thousand separators. Instead of burying the risk in a footnote, we added a validator that flags potential unit shifts (“MB” vs “MiB,” “billion” vs “one hundred million”) and prompts the reviewer to double-check those lines.
By Q3, we had enough confidence to expand scope. Marketing asked for batch translation of campaign assets (roughly 12,000 lines) under a 24-hour window. The pipeline was straightforward: chunk → queue → translate → QA sampling → publish. The surprising part was cost. With two modest GPUs (24 GB each) and off-peak scheduling, we stayed within the monthly cap while maintaining a comfortable throughput of ~18–22 tokens/s per worker for mid-length content.
What did not work? Pushing “style transfer” too hard. Attempts to force a cheerful tone across technical postmortems backfired; reviewers preferred a neutral register with clearly marked exceptions. Another misstep was hiding advanced controls. Power users wanted access to per-request parameters (temperature, top_p, max_tokens), not just a single “translate” button. We compromised by exposing a compact “advanced” drawer and remembering preferences per user.
In hindsight, the local-first decision was less about ideology and more about clear boundaries: where text lives, who can see it, and how changes are reviewed. The gains were practical—governance clarity, stable costs, and fewer awkward emails about data sharing. The cloud tools we used to love did not become worse; our constraints became sharper. Local-first simply fit those constraints.
Three takeaways:
• Start with observability: logs, checksums, and a retention story.
• Respect house style with a light, documented adaptation loop.
• Normalize expectations early; speed and perfection are separate levers.
This may sound unromantic, but it’s exactly what the team needed: something reliable, explainable, and sufficiently fast to fade into the background.
"""
翻訳結果
"""
実践における「ローカルファースト」翻訳:率直な現場レポート
チームが「ローカルファースト」機械翻訳について議論する際、議論の流れは通常インフラストラクチャから始まり、最終的にはポリシーで締めくくられる。その間にある中間領域は、調達上の制約やGPU不足、エンドポイント環境の整備、そして各関係者がどの要素をどこまで信頼しているかという複雑な社会的力学によって混沌としている。本稿では、中規模組織においてクラウドベースの翻訳システムから、コンパクトでドメイン適応可能なモデルを採用したローカルスタックへの移行過程で得られた知見をまとめる。
当初の課題は一見単純に見えた。アナリストチームは、製品ドキュメントやインシデント事後分析報告書、契約書などの作成において、迅速な英語↔日本語間の翻訳を必要としていた。長年利用してきたクラウドサービスは精度が高く使い勝手も良かったが、いくつかの懸念事項が蓄積しつつあった。顧客側からデータ所在地に関する問い合わせが寄せられたり、「デフォルトで機密扱い」とする新たな社内ポリシーにより外部ホスト型NLPツールの使用が禁止されたこと、さらに自社特有の言い回しが意図せず学習されてしまうリスクへの懸念が高まっていたのだ。結果として、テキストデータを当社ネットワーク内に保持し、クラウド利用時と同等の品質とレイテンシを維持するという方針が決定された。
移行にあたっては4つの制約条件を設定した:(1)エンドユーザーワークフローへの最小限の変更、(2)監査可能なリクエストログの取得、(3)月額コストの予測可能性、(4)短文(トークン数≤30)における500ms以下の安定したレイテンシ。この4つ目の要件は特に理想論的な側面が強かった。CPU専用サーバーで負荷が混在する環境下では、当初、短い入力テキストでもリクエスト1件あたり1.2~2.0秒を要し、長文パラグラフでは急激な遅延曲線を描く状況だった。現実的な解決策として、ウォームアップ処理と持続的ワーカープールの小規模運用を導入した。これは見栄えの良い手法ではなかったが、テールレイテンシの安定化には効果的であった。
品質面においては別種の課題が生じた。汎用モデルは日常的な言い回しには十分対応できたものの、社内独自の文体や専門用語、特に製品コンポーネント名やエラー分類用語、さらには一見普通に見えるが法的ニュアンスを含む表現などには苦戦した。そこで我々は、統制された用語集を導入するとともに、自社リポジトリから抽出した並列テキスト断片を用いた小規模な「マイクロファインチューニング」処理を実施した。標準的な評価指標では劇的な改善は見られなかったが、レビュアーのコメント内容はより一貫性のあるものに変化した。不自然な語順が減り、「英語風日本語」現象も減少し、インシデント要約における否定表現の扱いが改善された。
セキュリティとガバナンスの観点からは、ローカル推論が万能薬ではなかったものの、脅威モデルを明確に可視化できた点が重要だった。ログデータにより、入力データがサブネットA/B領域外に流出していないこと、使用モデルがチェックサム付きアーティファクトに固定されていること、そして保持期間が運用テレメトリ管理に必要な範囲に限られていることを実証的に証明できるようになった。2025年3月の外部監査時には、リクエスト履歴の再現機能やモデルバージョン表示が可能だったことで、審査プロセスが大幅に短縮された。
人的要因の観点から最も意外だった摩擦は、人々の期待値から生じたものである。「ローカル」という言葉から「即時性」と「完璧さ」を連想する傾向があったが、どちらも安全なデフォルト設定とは言えない。我々は以下3つのシンプルな規範を設定した:(a)決定論的動作のための温度パラメータ値0.0を初期設定とする、(b)複雑なエッジケースに対応するワンクリック式「多様性を考慮した再実行」ボタンを実装する、(c)トークン数制限と予想処理時間を示す可視化バナーを表示する。これらの規範が確立されると、苦情件数は明らかに減少した。
また、失敗モードに関する適切なコミュニケーションの重要性も学んだ。例えば数値表の場合、単位変換ミスや千位区切り記号の不適切な配置といった問題が発生することがあった。このリスクを脚注に埋もれさせる代わりに、潜在的な単位変更(「MB」と「MiB」、「billion」と「one hundred million」など)を自動で検知し、レビュアーにその行を再チェックするよう促すバリデーター機能を追加した。
第3四半期までに、我々は十分な自信を得て適用範囲を拡大した。マーケティング部門からは、キャンペーン用アセット約12,000行のバッチ翻訳を24時間以内で完了させる要望があった。パイプラインは以下のように単純明快だった:分割処理→キューイング→翻訳実行→QAサンプリング→公開。驚くべきはそのコスト面だった。控えめなスペックのGPU2台(各24GB)を使用し、オフピーク時間帯を活用することで、月額予算枠内に収まりつつ、中程度の長さのコンテンツに対してワーカーあたり約18~22トークン/秒という快適なスループットを維持できた。
一方でうまくいかなかった点もある。「スタイル転送」機能を過度に追求したことがその一つだ。技術系インシデントレポート全体に明るいトーンを強制しようとした試みは裏目に出た。レビュアーたちは、例外事項を明確にマークした中立的な文体を好むことが判明した。もう一つの失敗は、高度な制御機能を隠してしまったことだ。パワーユーザー層からは、単一の「翻訳」ボタンではなく、リクエストごとに温度パラメータやtop_p値、max_tokensなどの設定を自由に調整できるアクセス権が求められていた。我々は妥協策として、コンパクトな「詳細設定」パネルを公開するとともに、各ユーザーごとの設定履歴を保持する仕組みを採用した。
振り返ってみると、ローカルファースト採用の決定はイデオロギー的なものというより、明確な境界線を設定することに重点を置いていた。すなわち、テキストデータの所在範囲、閲覧権限者、そして変更内容のレビュープロセスに関する境界である。得られた成果は実用的なものばかりだった:ガバナンスの明確化、コスト管理の安定化、データ共有をめぐる煩雑なメールやり取りの減少。以前まで愛用していたクラウドツールが悪化したわけではなく、我々の制約条件がより明確になっただけだ。ローカルファーストは、まさにこれらの制約条件に合致する解決策だった。
この経験から得られる3つの教訓は以下の通りである:
• 可観測性を最優先すること:ログ記録、チェックサム管理、そしてデータ保持ポリシーに関する明確な説明を用意すること。
• 社内文体を尊重しつつ、簡潔で文書化された適応ループを構築すること。
• 期待値は早期に正常化させること。速度と完璧さは別のレバーであることを認識すること。
これらの内容はロマンチックな響きはないかもしれないが、まさにチームが求めていたものだった:信頼性が高く、説明可能で、背景に自然と溶け込むほど十分な速さを備えたソリューションである。
"""
出力:1200 tokens
時間:7分13秒
出力速度:2.77 token/sec
検証2
元文章
"""
ローカル優先の翻訳運用:現場で見えた要件と落とし穴
「ローカルで翻訳を回したい」という要望は、単に“外に出したくない”という感情論ではなく、監査対応・コスト予測・業務継続性といった実務上の要件から生まれることが多い。私たちの組織でも、クラウド依存の翻訳ワークフローを段階的に置き換える過程で、期待と現実のギャップがいくつも露呈した。本稿は、そのときに学んだ知見を簡潔にまとめたものである。
まず痛感したのは、品質の“型”である。一般的なモデルは通じるが、社内の用語体系や法務部門が好む日本語の言い回しには、独特の癖がある。たとえば、障害報告書における否定表現や、契約条項で使われる助動詞の強度(「〜してはならない」「〜しないものとする」など)は、読み手の解釈に直結する。私たちは、ごく小さな並列コーパスを作って用例を固定化し、用語集(英⇔日)の粒度を“機能名/UIラベル/契約上の定型句”に分けた。これだけで、レビュー時の指摘が目に見えて減った。
次に、レイテンシの問題である。利用者は“ローカル=高速”と無意識に期待するが、現実にはウォームアップや同時実行数の調整、キューの監視が欠かせない。短文(30トークン以下)なら体感は十分だが、段落単位になると急に遅く感じられることがある。私たちは、最初の1リクエストを捨てる“肩慣らし”を導入し、ピーク時だけワーカーを増やす運用に切り替えた。結果としてスループットは向上し、ばらつきも抑えられた。
監査対応は、ローカル化の大きな利点だ。テキストがどのネットワーク区画を通過し、どのモデル(ハッシュ値付き)で推論されたかを、ログで再現できることは説得力がある。2025年3月の外部監査では、要求されたのは“理想の制度”ではなく“実際に回っている手続き”だった。再実行可能性と保全の説明に時間を割いた分、議論は短く済んだ。
一方で、失敗もあった。スタイル変換を過度に試みた結果、技術文書が不自然に軽い文体になり、レビューが差し戻された。また、上級者向けのパラメータ(temperature, top_p など)を隠したところ、かえって不満が増した。最終的には、簡易モードと詳細モードを併設し、ユーザーごとの既定値を記憶するUIで落ち着いた。
運用ルールはシンプルなほど強い。私たちは、(a) 既定は決定論(temperature=0)、(b) 例外時のみ多様性を許可、(c) 単位や桁区切りの自動検査を必ず通す――の三点を“最低限の約束事”として徹底した。これにより、数字の取り違えや単位の取り違え(MB/MiB、億/billion など)を機械的にあぶり出せるようになった。
結局のところ、ローカル優先はイデオロギーではない。テキストの所在を明確にし、費用とリスクの分布を読みやすくし、レビューの手戻りを減らすための“現実的な選択”にすぎない。雲を悪者にする必要はない。こちらの制約が明確になっただけだ。だからこそ、私たちは“速さ”と“完璧さ”を同一視しない。必要な速度と、要求される正確さは、別々のつまみで調整すべきなのだ。
最後に、導入を検討する人への三つの提案を記す。
・まず可観測性――ログ、チェックサム、保持期間の方針――を整えること。
・次に、社内の語彙と調子に合わせた軽い適応ループを設けること。
・そして、利用者の期待値を早い段階で言語化すること。速度と多様性のトレードオフは、運用を始める前に共有した方がよい。
華やかさはないが、これで十分だった。必要なときに、必要な精度で、必要な場所で動く。それが私たちの“ローカル優先”である。
"""
翻訳結果
"""
Local-First Translation Operations: Lessons Learned from the Field and Common Pitfalls
The demand for "local translation processing" often stems from practical requirements—not just emotional resistance to externalization—such as audit compliance, cost forecasting, and business continuity. In our organization's gradual replacement of cloud-dependent translation workflows, we encountered several gaps between expectations and reality. This article concisely summarizes the insights we gained during that process.
First and foremost was the issue of quality standards. While generic models sufficed, there were unique quirks in our company's in-house terminology and the preferred Japanese phrasing favored by our legal department. For example, negation expressions in incident reports and the strength of auxiliary verbs used in contract clauses—like "shall not" or "is to be avoided"—directly impact how readers interpret them. We addressed this by creating a small parallel corpus to standardize usage patterns and refined our termbase (English↔Japanese) into granular categories: "function names," "UI labels," and "contractual boilerplate." This alone significantly reduced the number of issues identified during review.
Next came the latency challenge. Users naturally expect "local" to mean faster, but in reality, warm-up periods, concurrent execution adjustments, and queue monitoring are indispensable. For short texts (30 tokens or less), the performance difference was negligible, but when dealing with paragraph-length content, the system suddenly felt much slower. We implemented a "warmup phase" where the first request is discarded and switched to a configuration that scales up workers only during peak times. The result was improved throughput with reduced variability.
Audit compliance turned out to be a major advantage of localization. The ability to log and reproduce exactly which network segments text passed through, which models were used (with hash values), and how the inference was performed provided compelling evidence. During an external audit in March 2025, what they were actually looking for wasn't some idealized system but "the actual operational procedures in place." By dedicating time to explaining reproducibility and preservation, the discussion became much shorter.
However, we did encounter failures too. Our overzealous attempts at style conversion resulted in technical documentation that sounded unnaturally casual, leading to review rejections. Additionally, when we concealed advanced parameters like temperature and top_p, this actually increased user dissatisfaction. In the end, we settled on a UI design featuring both simplified and detailed modes, while also remembering each user's default preferences.
Operational rules are strongest when kept simple. We established three "minimum commitments": (a) defaults should be deterministic (temperature=0), (b) only exception cases should permit variability, and (c) automatic inspection must always cover unit formatting and decimal separators. We implemented this to mechanically detect errors like number misinterpretations and unit mix-ups—whether it was MB/MiB confusion or billion vs. billion mistakes.
Ultimately, local-first isn't an ideological choice. It's simply a "pragmatic decision" to clarify where text resides, make cost and risk distributions more transparent, and minimize review rework. You don't need to villainize the cloud; it just makes your own constraints clearer. That's why we never conflate speed with perfection. The required velocity and the demanded accuracy should be adjusted on separate dials.
Finally, here are three recommendations for those considering implementation:
• First, establish observability—logs, checksums, and retention policies.
• Next, implement a lightweight adaptation loop tailored to your company's vocabulary and tone.
• And finally, clearly articulate user expectations early on—the tradeoffs between speed and variability should be shared before operations begin.
It may not be glamorous, but these basics proved more than sufficient. When needed, they operate precisely where and with the accuracy required. That's our "local-first" approach.
"""
出力:676 tokens
時間:4分14秒
出力速度:2.66 token/sec
和→英、英→和関係なく、トークンの出力速度はほぼ同様で平均 2.72 token/sec で翻訳していたことが分かりました。遅いですね。
また、長文であったことがこの遅さの原因なのではないかと思い、検証1・2の各元文章について、タイトルと最初の段落の部分だけを残した短縮版を翻訳してみました。そうしたところ、検証1の短縮文は 2.73 token/sec、検証2の短縮文は 2.62 token/secとなりました。ほとんど変わりませんね。
どちらにせよ遅いことが分かったので、CPU実行ではあまり使い勝手が良くないかもしれません。ただし、時間がかかる前提で放置で翻訳させ続けるとか、強力なGPU付きデスクトップPCへ乗り換えたりできるならこのツールは役に立つものと思います。