どうしてこの記事を書いたのか
Elasticsearch/Neo4j 活用していらっしゃいますでしょうか?
どちらも著名なデータベース(DB)ですが,その特徴・用途は異なります.
Elasticsearch は文字情報の検索に強く,Neo4j は関連性を早く調べたいという場合に利用されているイメージです.
所感ですが,Neo4j でもデータのプロパティを基準にクエリをかけたいこともありますし,Elasticsearch に入っているデータ同士を紐づけたいことも往々にしてあります.
しかし,愚直にそうしてしまうとスループットが低くなったり,実装に継続的な作りこみが必要だったり,なかなか考え物です.
そこで,データ構造を見直しつつ何とか良いとこ取りできないかなと検討するようになりました.
Neo4j と Elasticsearch の連携を行うことで,
- Elasticsearchに投入したデータを元にNeo4jでデータの関連性を可視化する.
- Neo4jに投入した関連性をもつデータをElasticsearchで全文検索する.
といったユースケースを実現したい,というのが本記事の執筆動機です.
連携するためのプラグインについては,Neo4jの公式ページに記載があります.
こちらのプラグインを活用した連携も可能のよう1ですが,最新版の Neo4j には対応していなかったり,GitHubリポジトリの更新がしばらく行われていなかったりするために利用する上では不安が残ります.
本記事では,両者の間に Kafka を置くことで連携/通信制御できるようにしたいと思います.
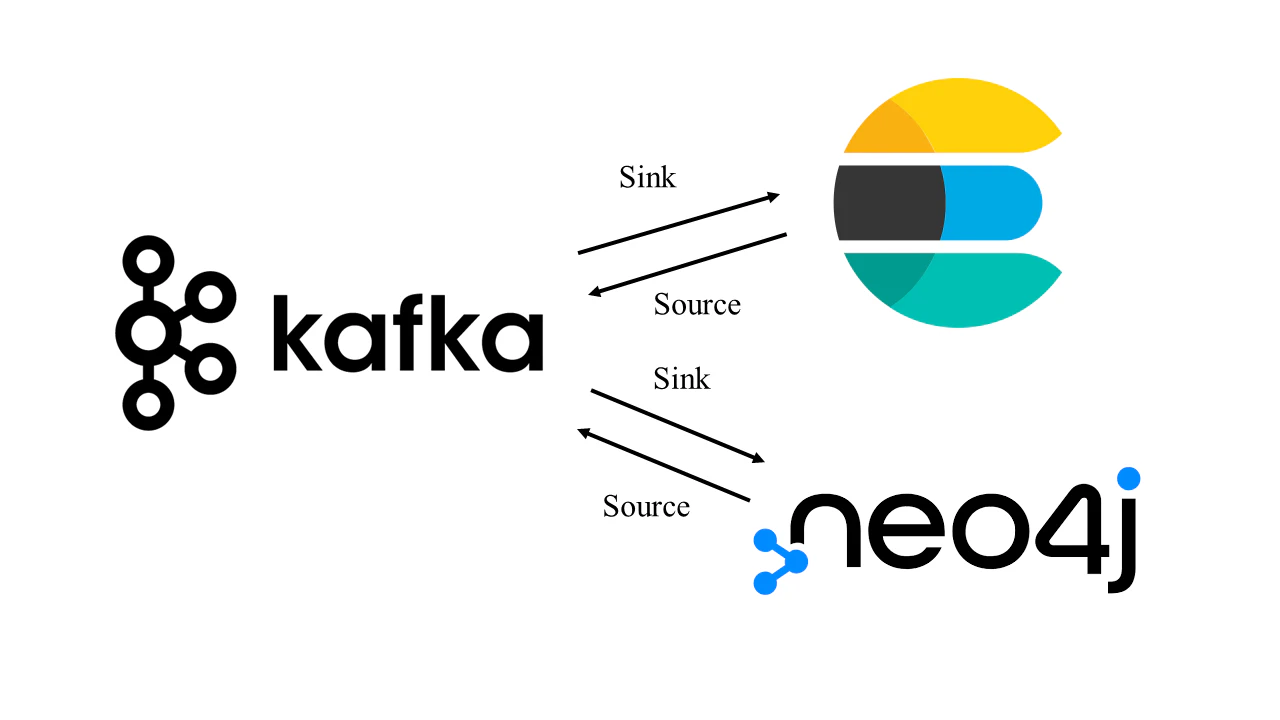
Kafka は Windows非推奨ということ2なので,今回は WSL2 で環境を作ってみたいと思います.
本記事は
- 「Linux環境は持ってるけど何も設定したことない」
- 「WSLの存在は知っているけど使ったことない」
という方でも再現できるようにできるだけ詳しく作業を書いています.
初期のWSL2ではホストとlocalhostのIPが違うことでかなり不便でしたが今は解決している3ので,サービスを立ち上げた後ブラウザでそのまま http://localhost に接続できます.
各サービスの簡単な紹介
Elasticsearch

Elasticsearchは、分散型で無料かつオープンな検索・分析エンジンです。テキスト、数値、地理空間情報を含むあらゆる種類のデータに、そして構造化データと非構造化データの双方に対応しています
Elasticsearch は高速な全文検索を提供するDBで,Elastic社が提供する Elastic Stack の中核を為す製品です.
形態素解析などを活用したリッチな全文検索が可能になっています.
Neo4j

With proven trillion+ entity performance, developers, data scientists, and enterprises rely on Neo4j as the top choice for high-performance, scalable analytics, intelligent app development, and advanced AI/ML pipelines.
Neo4j はグラフ型DBの中でも突出して支持され展開されている4製品です.
グラフ型DBの説明は詳しく書かれているものが沢山転がっているのでここでは書きませんが,関係性に注目して検索・描画するニーズに対してはRDBMSより得意であるのが特徴です.
Apache Kafka

Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Apache Kafka はサービス間の通信を仲介して分散ストア・ストリーミング処理を実現してくれるオープンソースです.
内部の話は非常に難しいのでこれも省きますが,私が特に好きなオープンソースだったりします.
Confluent社は Kafka の活用に着目したアメリカの企業で,独自のコミュニティでは以下で紹介する Connector の提供などをしています.
Kafka-DBサービス間の連携設定
Kafka と DB の接続には Kafka Connectors を使います.
Connectors は各サービスの API をラップし,データ形式を整えてやり取りしてくれる機能を持った jar ファイルです.
サービスごとにSink(データを送る)/ Source(データを送ってもらう)を設定します.
ElasticSearch Sink Connector
The Elasticsearch connector allows moving data from Kafka to Elasticsearch 2.x, 5.x, 6.x, and 7.x. It writes data from a topic in Kafka to an index in Elasticsearch and all data for a topic have the same type.
ElasticSearch Sink Connector は,Kafka のメッセージを Elasticsearch に投入するための Connector です.
GitHubで公開されており,Confluent Community ライセンス で利用できます.
Elasticsearch は明示されない限り投入されたデータからマッピングを自動判別しますが,小数やタイムスタンプなどについて型が適切に推測できない場合があります.
ElasticSearch Sink Connector は Kafka のメッセージスキーマからマッピングを推測して投入する機能も持ちます.
Elasticsearch 2.x, 5.x, 6.x & 7.x に対応しています.
Elasticsearch Source Connector
This is a connector for getting data out of Elasticsearch into Apache Kafka.
Elasticsearch Source Connector は,Elasticsearch から Kafka へメッセージを渡すための Connector です.
GitHubで公開されていて,Apacheライセンス Ver.2.0 で利用可能です.
Elasticsearch 6.x & 7.x に対応しています.
Neo4j Connector
It's a basic Apache Kafka Connect Neo4j Connector which allows moving data from Kafka topics into Neo4j via Cypher templated queries and vice versa.
Neo4j Connector は Sink と Source のどちらもサポートしている Connector で,Neo4j 公式のユーザガイドもあります.
こちらもGitHubで公開,Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International というライセンスで管理されています.
Neo4j 5.x まで対応しています.
動作確認環境
| 名称 | バージョン |
|---|---|
| Windows 10 | 21H2 |
| Ubuntu (WSL2) | 20.04.5 |
| OpenJDK | 11 |
| Elasticsearch | 7.17.8 |
| Kibana | 7.17.8 |
| Neo4j | 4.4.16-community |
| Kafka (Apache) | 3.3.1 |
| Gradle | 7.4.2 |
| ElasticSearch Sink Connector | 14.0.3 |
| Elasticsearch Source Connector | 1.5.2 |
| Neo4j Connector | 5.0.0 |
本記事では,Elasticsearch に対するリクエスト/レスポンスの取得が楽なので Kibana を利用しますが,必須ではありません.
Java は Elasticsearch と Kafka で利用します.
Gradle は Kafka のビルドに使いますが,特別インストール作業をする必要はありません.
環境準備
各サービスのインストール方法は,それぞれ公式HPに従います.
署名のチェックは省略しているので,必要に応じて適宜追加してください.
# Java
## tar(gzip)を取得
curl -OL https://download.java.net/java/ga/jdk11/openjdk-11_linux-x64_bin.tar.gz
## (どこでも良いが)ユーザディレクトリ下に展開
sudo tar xfz ./openjdk-11_linux-x64_bin.tar.gz --directory $HOME
## JAVA環境変数を登録
echo '# OpenJDK-11' >> ~/.bashrc
echo 'export JAVA_HOME=$HOME/jdk-11' >> ~/.bashrc
echo 'export CLASSPATH=$JAVA_HOME/lib' >> ~/.bashrc
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> ~/.bashrc
source ~/.bashrc
# Elasticsearch
## tar(gzip)を取得
curl -OL https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.8-linux-x86_64.tar.gz
## (どこでも良いが)ユーザディレクトリ下に展開
tar -xzf ./elasticsearch-7.17.8-linux-x86_64.tar.gz --directory $HOME
# Kibana
## tar(gzip)を取得
curl -OL https://artifacts.elastic.co/downloads/kibana/kibana-7.17.8-linux-x86_64.tar.gz
## (どこでも良いが)ユーザディレクトリ下に展開
tar -xzf ./kibana-7.17.8-linux-x86_64.tar.gz --directory $HOME
# Neo4j
## tar(gzip)を取得
curl -L -o neo4j-community-4.4.16-unix.tar.gz https://neo4j.com/artifact.php?name=neo4j-community-4.4.16-unix.tar.gz
## (どこでも良いが)ユーザディレクトリ下に展開
tar -xzf ./neo4j-community-4.4.16-unix.tar.gz --directory $HOME
# Kafka
## tar(gzip)を取得
curl -OL https://downloads.apache.org/kafka/3.3.1/kafka-3.3.1-src.tgz
## (どこでも良いが)ユーザディレクトリ下に展開
tar -xzf ./kafka-3.3.1-src.tgz --directory $HOME
起動確認をします.
まずは Elasticsearch/Kibana から.
# Elasticsearchを起動
cd $HOME/elasticsearch-7.17.8
./bin/elasticsearch
# Kibanaを起動
cd $HOME/kibana-7.17.8
./bin/kibana
起動後 Kibana http://localhost:5601 に接続し,Dev Tools > Console を開いて Elasticsearch のヘルスチェックをします.

上の画像通りであればOK.
次にNeo4jを起動します.
cd $HOME/neo4j-community-4.4.16
# Neo4jの起動設定,Javaヒープサイズとリッスンするアドレスのコメントを外しておく
vi ./conf/neo4j.conf
> dbms.memory.heap.initial_size=512m
> dbms.memory.heap.max_size=512m
> dbms.default_listen_address=0.0.0.0
# Neo4jを起動
./bin/neo4j console
> 2022-12-22 05:55:21.669+0000 INFO Started.
起動した後,Neo4j http://localhost:7474 に接続し,bolt://localhost:7687 に対してデフォルトユーザ/パスワードの neo4j/neo4j でログインします。
パスワードの変更を求められるので行います。本記事では neo4j/password で設定しました.

上の画像通りであればOK.
最後に Kafka を起動します.
cd $HOME/kafka-3.3.1-src
# Gradleを使ってビルド
./gradlew jar -PscalaVersion=2.13.8
> BUILD SUCCESSFUL
# Zookeeperの起動
./bin/zookeeper-server-start.sh config/zookeeper.properties
> (大きな文字でZookeeperと表示される)
# "Kafka"(Broker)の起動
./bin/kafka-server-start.sh config/server.properties
> (Startingログが沢山表示される)
# Kafka Topicを作成,Brokerはlocalhost:9092で立っている.
./bin/kafka-topics.sh --create --topic kafka-elastic-topic --bootstrap-server localhost:9092
# Kafka Topicにデータを入れてみる.Ctrl+cで終了
./bin/kafka-console-producer.sh --topic kafka-elastic-topic --bootstrap-server localhost:9092
> {"name":"ab cde", "comment": "Hello"}
> {"name":"fgh ij", "comment": "Bonjour"}
# Topicに入っていることを確かめる.Ctrl+cで終了
./bin/kafka-console-consumer.sh --topic kafka-elastic-topic --bootstrap-server localhost:9092 --from-beginning
> {"name":"ab cde", "comment": "Hello"}
> {"name":"fgh ij", "comment": "Bonjour"}
> Processed a total of 2 messages
上記まで確認できていればOK.
Kafka Connect の設定
ElasticSearch Sink Connector
公式ページからzipファイルをダウンロードしてunzip、パスを通して Kafka Connect を起動します.
設定はKafkaディレクトリ内にある ./config/connect-distributed.properties に記載します.
# unzipしてコピー
mkdir -p $HOME/kafka-3.3.1-src/connectors
unzip -d $HOME/kafka-3.3.1-src/connectors confluentinc-kafka-connect-elasticsearch-14.0.3.zip
# jarのパスを通す&JsonConverterを設定する
vi $HOME/kafka-3.3.1-src/config/connect-distributed.properties
(追記)
> internal.key.converter=org.apache.kafka.connect.json.JsonConverter
> internal.value.converter=org.apache.kafka.connect.json.JsonConverter
> internal.key.converter.schemas.enable=false
> internal.value.converter.schemas.enable=false
(変更)
> key.converter.schemas.enable=false
> value.converter.schemas.enable=false
> plugin.path=$HOME/kafka-3.3.1-src/connectors
# Connectを起動
cd $HOME/kafka-3.3.1-src
./bin/connect-distributed.sh config/connect-distributed.properties
# ログからLoading Pluginを探してもいいが大変なので,以下を叩いてConnectorを認識していることを確認
curl -s localhost:8083/connector-plugins | jq '.[].class'
> "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector"
curlを利用して,Connect の設定をします.
本記事では指定しませんでしたが,リトライ数やタイムアウト,Proxy の設定などもここで行います.
設定後,先ほどテストで投入したメッセージが Elasticsearch に投入されるはずです.
# Connector経由でElasticsearchに投入する設定をする,Connectはlocalhost:8083で立っている.
curl -i -X POST -H "Content-Type: application/json" -H "Accept: application/json" http://localhost:8083/connectors/ \
-d '{
"name": "elasticsearch-connector-test",
"config":{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"topics": "kafka-elastic-topic",
"tasks.max": "1",
"connection.url": "http://localhost:9200",
"type.name": "_doc",
"name": "elasticsearch-connector-test",
"key.ignore": "true",
"schema.ignore": "true"
}
}'
> HTTP/1.1 201 Created
> Date: Thu, 22 Dec 2022 12:37:49 GMT
> Location: http://localhost:8083/connectors/elasticsearch-connector
> Content-Type: application/json
> Content-Length: 335
> Server: Jetty(9.4.48.v20220622)
Elasticsearch で Topic 名が index 名となっているデータにクエリをかけて,ちゃんと送られたか確認します.
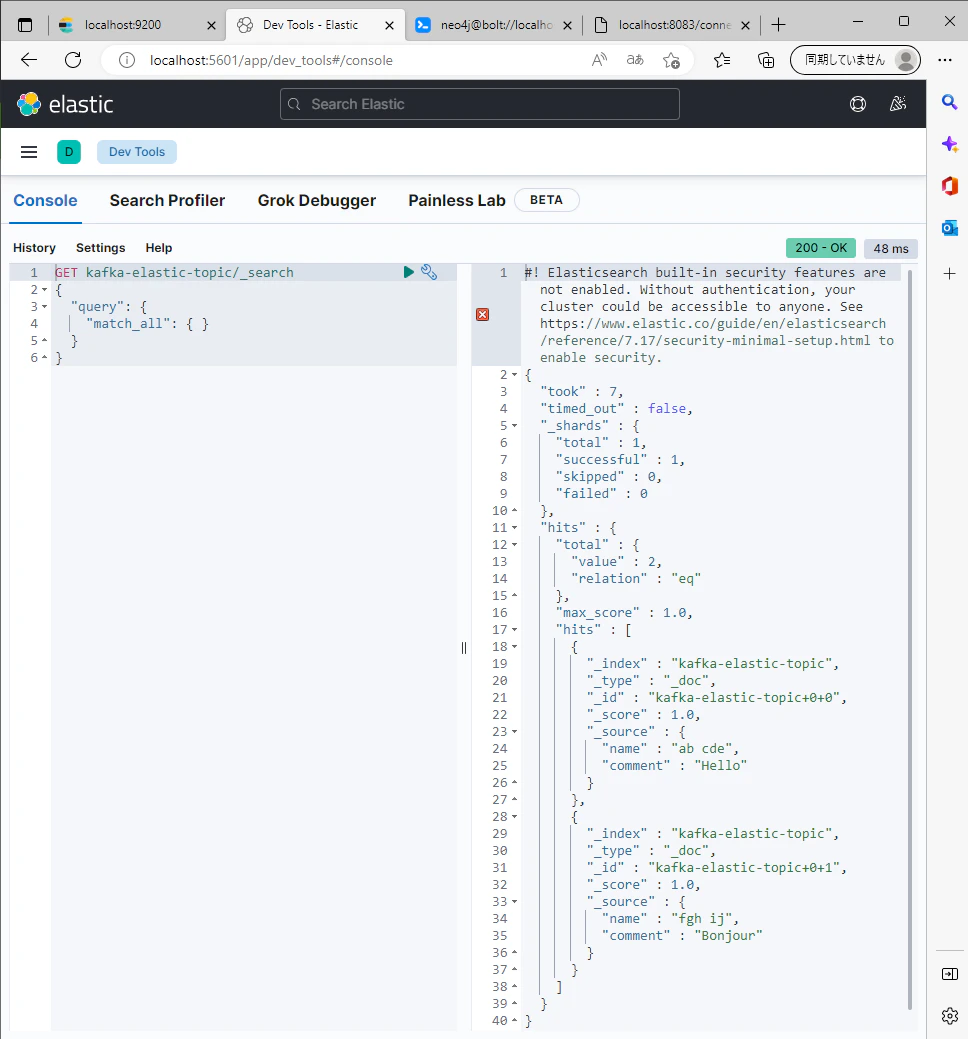
ちゃんと入ってますね.
Elasticsearch Source Connector
ElasticSearch Sink Connectorと同様に設定を行います.
公式ページからzipファイルをダウンロードしてunzip、パスを通して Kafka Connect を起動します.
本記事で設定する ElasticSearch Sink Connector との違いは以下です.
- configファイルを自前で作成する.
- Elasticsearchに
@timestampのPipelineを設定する.
# unzipしてコピー, jarのパスはElasticsearch Sink Connectorの設定で既に通っている
unzip -d $HOME/kafka-3.3.1-src/connectors ariobalinzo-kafka-connect-elasticsearch-source-1.5.2.zip
# configファイルを作成する
vi $HOME/kafka-3.3.1-src/es-source-config.json
> {
> "name":"elastic-source",
> "config":{
> "connector.class":"com.github.dariobalinzo.ElasticSourceConnector",
> "tasks.max": "1",
> "es.host" : "localhost",
> "es.port" : "9200",
> "poll.interval.ms": "5000",
> "index.prefix" : "elastic-kafka-topic",
> "topic.prefix" : "source_conf_",
> "incrementing.field.name" : "timestamp",
> "behavior.on.null.values": "ignore",
> "behavior.on.malformed.documents": "ignore",
> "drop.invalid.message": "true"
> }
> }
Elasticsearch Source Connectorを利用するには,Elasticsearchのマッピング定義に存在する incrementing.field.name を指定する必要があります.
この値はデフォルトで @timestamp を利用します5.
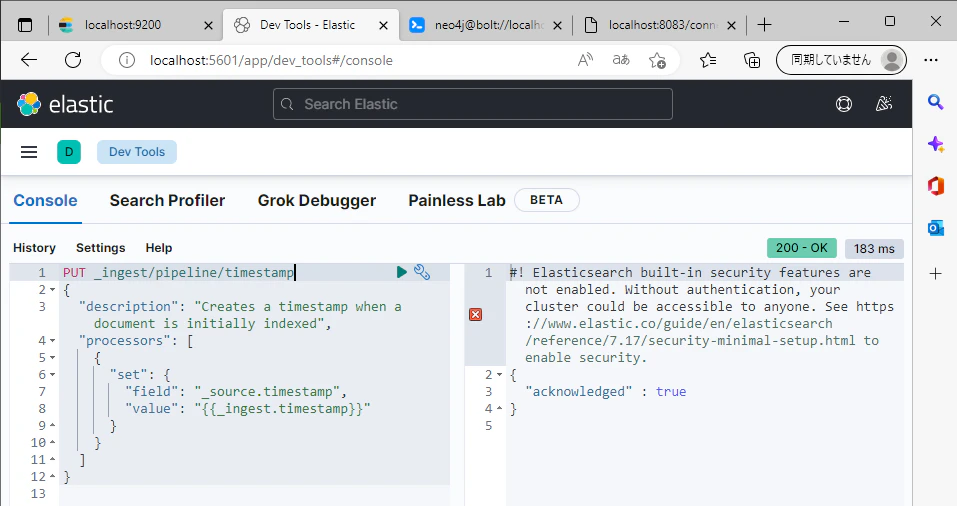
Elasticsearchに投入されたどんなデータにも対応できるように,@timestamp を自動で追加する Pipeline を設定しておきます6.
@timestamp Pipeline の設定は以下を参考にしてください.
# Connectを起動
cd $HOME/kafka-3.3.1-src
./bin/connect-distributed.sh config/connect-distributed.properties
# ログからLoading Pluginを探してもいいが大変なので,以下を叩いてConnectorを認識していることを確認
curl -s localhost:8083/connector-plugins | jq '.[].class'
> "com.github.dariobalinzo.ElasticSourceConnector"
# Connectにconfig設定を送る
curl -X POST -H "Content-Type: application/json" --data @es-source-config.json http://localhost:8083/connectors | jq
Elasticsearchにデータを投入します.
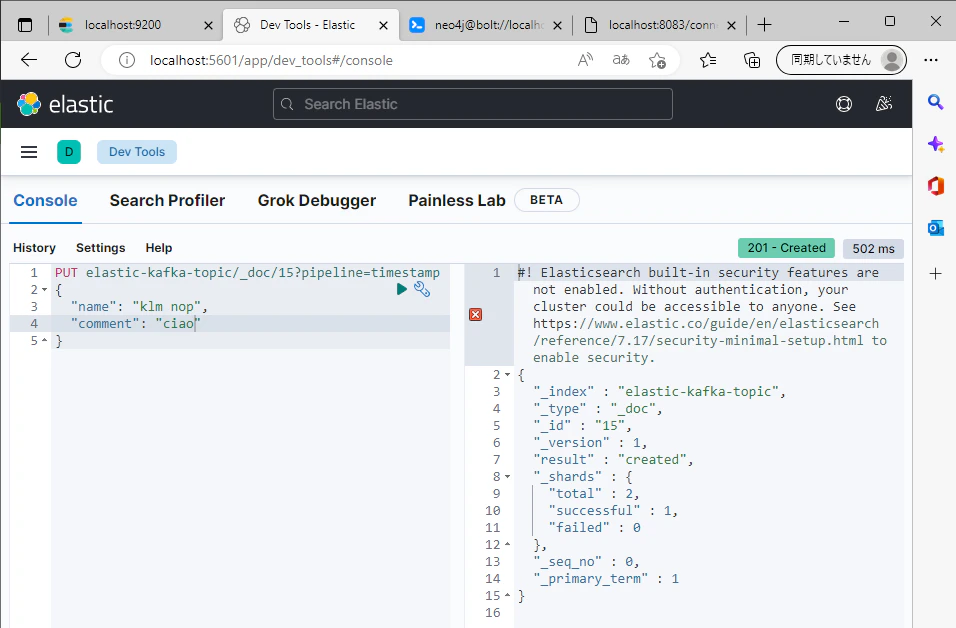
# Elasticsearchに投入されたデータがKafkaに送られているか確認,Topic名はes-source-config.jsonの設定に基づく
./bin/kafka-console-consumer.sh --topic source_conf_elastic-kafka-topic --bootstrap-server localhost:9092 --from-beginning
> {"name":"klm nop","comment":"ciao","esindex":"elastic-kafka-topic","esid":"15","timestamp":"2022-12-23T02:14:13.454334Z"}
> Processed a total of 1 messages
こちらもちゃんと入っていますね.
Neo4j Connector
公式ページからzipファイルをダウンロードしてunzip、パスを通して Kafka Connect を起動します.
また,guava-20.0.jar が必要になってくるのでダウンロードしておいて配置します.
Sinkから設定していきます.
# unzip してコピー, jarのパスはElasticsearch Sink Connectorの設定で既に通っている
unzip -d $HOME/kafka-3.3.1-src/connectors neo4j-kafka-connect-neo4j-5.0.0.zip
# guava.jar をコピー
cp guava-20.0.jar $HOME/kafka-3.3.1-src/connect/runtime/build/dependant-libs
# Kafka Topicを作成&データを追加
cd $HOME/kafka-3.3.1-src
./bin/kafka-topics.sh --create --topic kafka-neo4j-topic --bootstrap-server localhost:9092
./bin/kafka-console-producer.sh --topic kafka-neo4j-topic --bootstrap-server localhost:9092
> {"id": "1234", "name": "hoge"}
> {"id": "5678", "name": "fuga"}
> {"id": "9100", "name": "poyo"}
# Connectを起動
./bin/connect-distributed.sh config/connect-distributed.properties
# ログからLoading Pluginを探してもいいが大変なので,以下を叩いてConnectorを認識していることを確認
curl -s localhost:8083/connector-plugins | jq '.[].class'
> "streams.kafka.connect.sink.Neo4jSinkConnector"
# Connector経由でNeo4jに投入する設定をする
curl -i -X POST -H 'Content-Type: application/json' -H 'Accept: application/json' http://localhost:8083/connectors \
-d '{
"name": "Neo4jSinkConnector",
"config": {
"topics": "kafka-neo4j-topic",
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"errors.retry.timeout": "-1",
"errors.retry.delay.max.ms": "1000",
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"neo4j.server.uri": "bolt://localhost:7687",
"neo4j.authentication.basic.username": "neo4j",
"neo4j.authentication.basic.password": "password",
"neo4j.encryption.enabled": false,
"neo4j.topic.cypher.kafka-neo4j-topic": "CREATE (n:Test1:Test2 {id: event.id , name: event.name })"
}
}'
> HTTP/1.1 201 Created
> Date: Thu, 22 Dec 2022 16:51:36 GMT
> Location: http://localhost:8083/connectors/Neo4jSinkConnector
> Content-Type: application/json
> Content-Length: 765
> Server: Jetty(9.4.48.v20220622)
Neo4jにデータが入っていることを確認します.
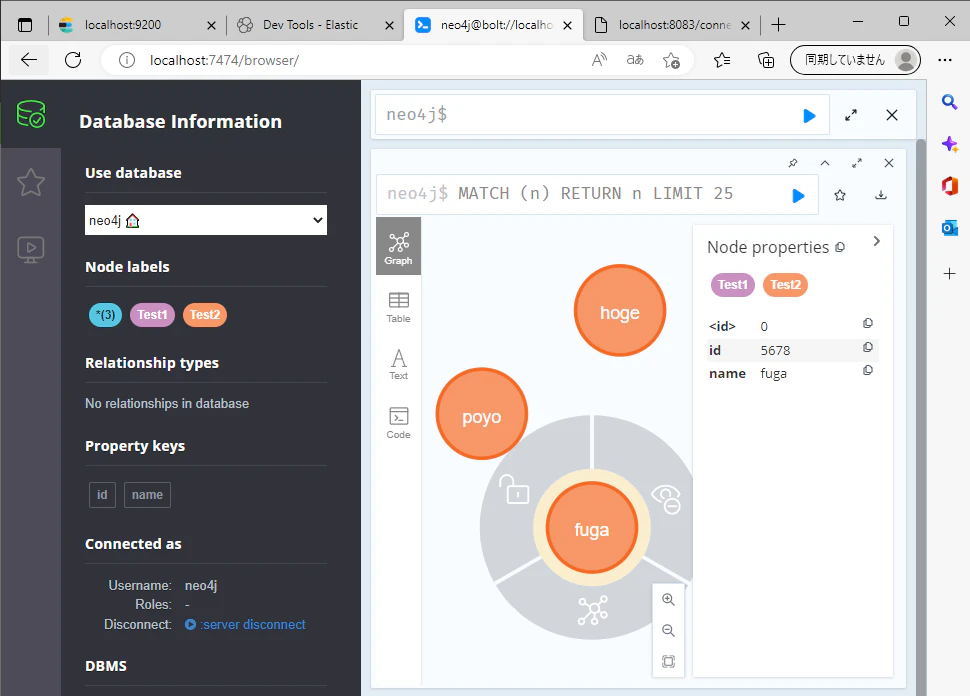
ラベルがすべて同じなので,全てのノードが同じ色で表現されています.
ラベルを変えるにはTopicを変えるか,neo4j.topic.cypher.kafka-neo4j-topic で場合分けするように書いてあげる必要がありそうです.
続けて Source を設定します.
Elasticsearchと同様に,Sourceではconfigファイルを作成します.
# Connectを起動
cd $HOME/kafka-3.3.1-src
./bin/connect-distributed.sh config/connect-distributed.properties
# configファイルを作成する
vi $HOME/kafka-3.3.1-src/neo4j-source-config.json
> {
> "name": "neo4j-source",
> "config": {
> "topic": "neo4j-kafka-topic",
> "connector.class": "streams.kafka.connect.source.Neo4jSourceConnector",
> "neo4j.server.uri": "bolt://localhost:7687",
> "neo4j.authentication.basic.username": "neo4j",
> "neo4j.authentication.basic.password": "password",
> "neo4j.encryption.enabled": false,
> "neo4j.streaming.poll.interval.msecs": 1000,
> "neo4j.streaming.property": "timestamp",
> "neo4j.streaming.from": "NOW",
> "neo4j.enforce.schema": true,
> "neo4j.source.query": "MATCH (n:Test3) WHERE n.timestamp > $lastCheck RETURN n.name AS name, n.timestamp AS timestamp",
> "errors.tolerance": "none",
> "errors.deadletterqueue.topic.name": "neo4j-kafka-topic",
> "errors.deadletterqueue.context.headers.enable": true
> }
> }
# Connectにconfig設定を送る
curl -X POST -H "Content-Type: application/json" --data @neo4j-source-config.json http://localhost:8083/connectors | jq
Neo4j にデータを登録します.

# Neo4jに投入されたデータがKafkaに送られているか確認,Topic名はneo4j-source-config.jsonの設定に基づく
./bin/kafka-console-consumer.sh --topic neo4j-kafka-topic --bootstrap-server localhost:9092 --from-beginning
> {"name":"piyo","timestamp":1671733082653}
> Processed a total of 1 messages
Kafkaにメッセージが反映されていました.
Elasticsearchに投入したデータを元にNeo4jでデータの関連性を可視化する

利用例として,Elasticsearch に投入したデータを Kafka で自動連携し,Neo4j でデータの関連性を可視化してみようと思います.
まずは Elasticsearch Source Connector を以下の json で設定します.
Neo4j のノードとリレーション用に Elasticsearch の index を分ける想定です.
{
"name": "elastic-source-to-neo4j-node",
"config": {
"connector.class": "com.github.dariobalinzo.ElasticSourceConnector",
"tasks.max": "1",
"es.host": "localhost",
"es.port": "9200",
"poll.interval.ms": "5000",
"index.prefix": "elastic-kafka-node-topic",
"topic.prefix": "source_conf_",
"incrementing.field.name": "timestamp",
"behavior.on.null.values": "ignore",
"behavior.on.malformed.documents": "ignore",
"drop.invalid.message": "true"
}
}
{
"name": "elastic-source-to-neo4j-relation",
"config": {
"connector.class": "com.github.dariobalinzo.ElasticSourceConnector",
"tasks.max": "1",
"es.host": "localhost",
"es.port": "9200",
"poll.interval.ms": "5000",
"index.prefix": "elastic-kafka-relation-topic",
"topic.prefix": "source_conf_",
"incrementing.field.name": "timestamp",
"behavior.on.null.values": "ignore",
"behavior.on.malformed.documents": "ignore",
"drop.invalid.message": "true"
}
}
上記で elastic-kafka-node-topic index に投入されたデータは source_conf_elastic-kafka-node-topic Topic に,elastic-kafka-relation-topic index に投入されたデータは source_conf_elastic-kafka-node-topic Topic に格納されるはずです.
次に,Kafka Connect を起動して Elastic Source Connector のconfig を送信後,Neo4j Sink Connector の設定も行います.
# Connectを起動
cd $HOME/kafka-3.3.1-src
./bin/connect-distributed.sh config/connect-distributed.properties
# ConnectにElasticsearch Source Connectorのconfig設定を送る
## ノード
curl -X POST -H "Content-Type: application/json" --data @es-source-config-test-node.json http://localhost:8083/connectors | jq
## リレーション
curl -X POST -H "Content-Type: application/json" --data @es-source-config-test-relation.json http://localhost:8083/connectors | jq
# ConnectにNeo4j Sink Connectorのconfig設定を送る
## ノード
curl -i -X POST -H 'Content-Type: application/json' -H 'Accept: application/json' http://localhost:8083/connectors \
-d '{
"name": "Neo4jSinkConnector-Node",
"config": {
"topics": "source_conf_elastic-kafka-node-topic",
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"errors.retry.timeout": "-1",
"errors.retry.delay.max.ms": "1000",
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"neo4j.server.uri": "bolt://localhost:7687",
"neo4j.authentication.basic.username": "neo4j",
"neo4j.authentication.basic.password": "password",
"neo4j.encryption.enabled": false,
"neo4j.topic.cypher.source_conf_elastic-kafka-node-topic": "CREATE (n:Pokemon {id: event.id , name: event.name})"
}
}'
## リレーション
curl -i -X POST -H 'Content-Type: application/json' -H 'Accept: application/json' http://localhost:8083/connectors \
-d '{
"name": "Neo4jSinkConnector-Relation4",
"config": {
"topics": "source_conf_elastic-kafka-relation-topic",
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"errors.retry.timeout": "-1",
"errors.retry.delay.max.ms": "1000",
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"neo4j.server.uri": "bolt://localhost:7687",
"neo4j.authentication.basic.username": "neo4j",
"neo4j.authentication.basic.password": "password",
"neo4j.encryption.enabled": false,
"neo4j.topic.cypher.source_conf_elastic-kafka-relation-topic": "MATCH (n:Pokemon {id: event.fromid}), (m:Pokemon {id: event.toid}) CREATE (n)-[:Evole]->(m)"
}
}'
Elasticsearch にデータを投入して,Neo4j で結果を確認します.
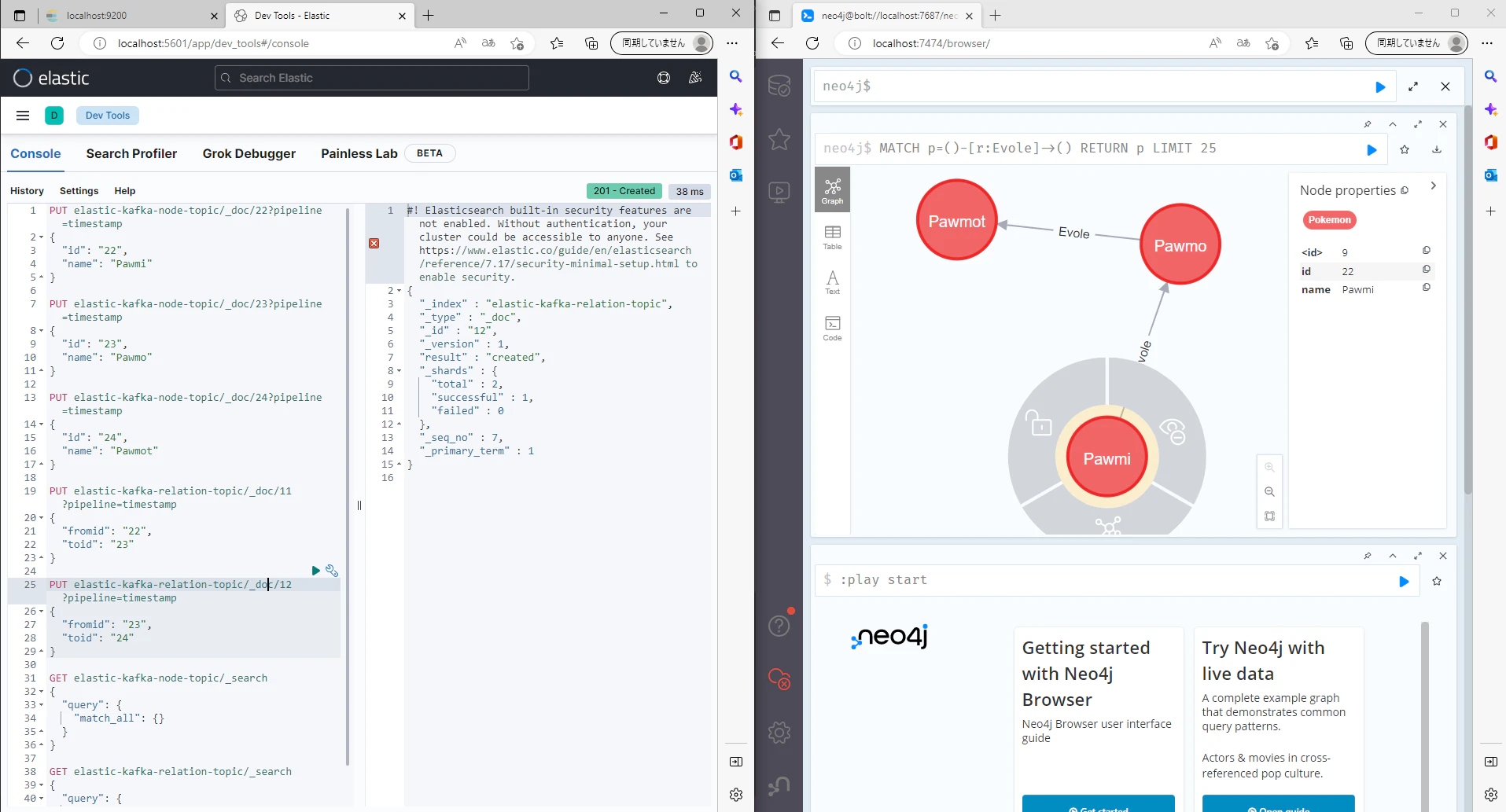
無事Neo4jまで届いていることが確認できました!
Neo4j は存在しないノードのリレーションは張れないので,投入順序は正しく制御してあげる必要があります.
実は潜んでいた落とし穴について
冒頭で,既存の連携プラグインは最新版の Neo4j には対応していなかったりGitHubリポジトリの更新がされていなかったりするため,本記事では Kafka を活用して連携すると書きました.
Elastic 製品を普段から使っている方なら気付かれたかもしれないですが,実は今回利用した Connectors は最新版の Elasticsearch をまだサポートしていません.
最新版 (8.x) では,Elasticsearch 起動時に表示されたパスワード・連携コードを利用して接続を開始します.
プロトコルはデフォルトで HTTPS を使用します.
# Elasticsearchを起動
cd $HOME/elasticsearch-8.5.3
./bin/elasticsearch
> ℹ️ Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`): hogeeee
> ...
> ℹ️ Configure Kibana to use this cluster:
> • Run Kibana and click the configuration link in the terminal when Kibana starts.
> • Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30 minutes): fugaaaa
> ...
# Kibanaを起動
cd $HOME/kibana-8.5.3
./bin/kibana
> ℹ️ Kibana has not been configured.
> Go to http://localhost:5601/?code=986486 to get started.
> ...
> (以下はElasticsearchとKibanaの連携作業を始めると現れる)
> Your verification code is: xxx xxx
本記事の検証では Kibana の画面で Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. と表示されていたり,Elasticserch へ curl する際に HTTP を使ったりしていました.
実は 7.x と 8.x ではデフォルトのセキュリティ機能が変更されており7,本記事そのままに進めようとすると Elasticsearch-Kafka 連携することができません.
調べてみるとセキュリティ機能を無効化する設定がある8みたいなので,最後にこれを検証したいと思います.
| 名称 | バージョン |
|---|---|
| Elasticsearch | 8.5.3 |
| Kafka (Apache) | 3.3.1 |
# elasticsearch.yml で xpack.security.enabled を無効化
vi $HOME/elasticsearch-8.5.3/config/elasticsearch.yml
> xpack.security.enabled: false
# Elasticsearchを起動
cd $HOME/elasticsearch-8.5.3
./bin/elasticsearch
確かにパスワード情報は表示されず,HTTPで接続可能でした.
# Zookeeperの起動
cd $HOME/kafka-3.3.1-src
./bin/zookeeper-server-start.sh config/zookeeper.properties
# Broker/Connectを含む"Kafka"の起動
./bin/kafka-server-start.sh config/server.properties
# Kafka Topicを作成
./bin/kafka-topics.sh --create --topic new-elastic-topic --bootstrap-server localhost:9092
# Kafka Topicにデータを入れる.Ctrl+cで終了
./bin/kafka-console-producer.sh --topic new-elastic-topic --bootstrap-server localhost:9092
> {"name":"8.5.3", "comment": "New Version"}
# Topicに入っていることを確かめる.Ctrl+cで終了
./bin/kafka-console-consumer.sh --topic new-elastic-topic --bootstrap-server localhost:9092 --from-beginning
> {"name":"8.5.3", "comment": "New Version"}
> Processed a total of 1 messages
# Connectを起動
./bin/connect-distributed.sh config/connect-distributed.properties
# Connector経由でElasticsearchに投入する設定をする
curl -i -X POST -H "Content-Type: application/json" -H "Accept: application/json" http://localhost:8083/connectors/ \
-d '{
"name": "elasticsearch-connector-test-new",
"config":{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"topics": "new-elastic-topic",
"tasks.max": "1",
"connection.url": "http://localhost:9200",
"type.name": "_doc",
"name": "elasticsearch-connector-test-new",
"key.ignore": "true",
"schema.ignore": "true"
}
}'
> HTTP/1.1 201 Created
> Date: Fri, 23 Dec 2022 06:26:43 GMT
> Location: http://localhost:8083/connectors/elasticsearch-connector-test-new
> Content-Type: application/json
> Content-Length: 351
> Server: Jetty(9.4.48.v20220622)
# Elasticsearch に問い合わせてみる
curl -sS -XGET 'localhost:9200/new-elastic-topic/_search?pretty'
> {
> "took" : 13,
> "timed_out" : false,
> "_shards" : {
> "total" : 1,
> "successful" : 1,
> "skipped" : 0,
> "failed" : 0
> },
> "hits" : {
> "total" : {
> "value" : 1,
> "relation" : "eq"
> },
> "max_score" : 1.0,
> "hits" : [
> {
> "_index" : "new-elastic-topic",
> "_id" : "new-elastic-topic+0+0",
> "_score" : 1.0,
> "_source" : {
> "name" : "8.5.3",
> "comment" : "New Version"
> }
> }
> ]
> }
> }
Kafka Topic に投入したデータが無事 Elasticsearch に入っていました!
セキュリティ機能を無効化すれば,同一の構成で通信できそうですね.
コンテナでたてる場合の話
本記事を書き始めるにあたって,最初は Confluent社のDockerイメージを利用して構築していました.
ここで紹介している方法ではディレクトリの移動も多くて大変だったと思いますが,コンテナ構成にするともっとすっきりします.
Kafkaのビルドも不要なので,正直言えばコンテナの方が準備は楽でした.
ではなぜこのコンテナ構成をご紹介しなかったかというと,ネットワークの設定が難しいからです.
今回利用した tar kafka-3.3.1-src.tgz では,同じディレクトリ内からシェルをたたいて複数ポートの通信をしていました.
これだけだと認知しづらいですが,実はこれは Zookeeper,Broker,Connect などの複数のサービスをたてています.
(Kafkaを知っている方は「何を今更...」かもしれませんが...)
一方,コンテナ構成にすると(マイクロサービス的に)これらを分けて docker-compose.yml を書くのが主流です.
docker nework を張るのはもちろんですが,LISTENERS や ADVERTISED_LISTENERS を適切に設定していく9ことになり,ここを説明しだすと話としてまとまらなさそう(自分の理解をもっと深めてからがいいなという思いもある)なのでやめました.
需要があれば,そのうち追加で書きたいなと思っています.
本記事では,参考情報だけ記載しておきます.
- Confluent社が出している all-in-one な
docker-compose.ymlの見本がある - Kafkaコンテナの立て方ガイドもある
- 環境変数に設定する値はよく確認する
- all-in-one に含まれるサービスのライセンスはバラバラなので必ず確認する(例えば,Schema Registry は Confluent Community ライセンス)
For example, it does not allow hosting of Confluent ksqlDB, Confluent Schema Registry, Confluent REST Proxy, or other software licensed under the Confluent Community License as online service offerings that compete with Confluent SaaS products or services that provide the same software.
- Confluent社のKafkaコンテナイメージ (7.3.0) のOS:
Red Hat Enterprise Linux 8 - Elasticsearch, Kibana, Neo4j それぞれにも docker を使った立て方ガイドがある
- 初めてコンテナで Elastic Stack をたてる際は
bootstrap checks failedのエラーが出てしまうことがあるので,vm.max_map_countの設定を行う