はじめに
こんにちは、初めまして。
突然ですが、ウマのゲームが大流行していますね。
ゲームに影響されて実際の競馬を始めてみた、という方も少なくないのではないでしょうか?
かく言う(とても影響されやすい)私もその一人です。
ちなみに、推しはサイレンススズカです ![]()
さておき、Aidemy Premiumにて「データ分析コース」の3か月コースを受講し、本記事はその最終成果物となります。
触れるなら興味ある分野がいいなということで、競馬のAI実装に挑戦してみました。
競馬もAI実装も初学者であり、拙い部分が多いですが、どうぞ最後までお付き合いください ![]()
注意
本記事はギャンブルを助長するものではありません。
競馬は節度を持って計画的に!
競馬についての前知識
分析対象となる競馬について、分析目線での簡易的な知識です。
競馬に詳しい方はスキップしてください。
- 騎手が馬に乗って決められたコースの距離を走り、一番早く走るスピードを競う競技、およびその着順を予想するもの。
- 日本中央競馬会(JRA)が主催する中央競馬と、地方自治体が主催する地方競馬に分類される。
- コースは芝、ダート、障害の3種類に分けられる。
- 中央競馬においては、距離は1000mから3600mまである。
- 中央競馬の競馬場は10か所あり、それぞれ特色が異なる。
- 着順を予想して購入する馬券には10種類あり、1着になる馬を当てる単勝や、3着までに入る馬(出走する馬が7頭以下の場合は2着まで)を当てる複勝などがある。
※本分析では中央競馬のデータのみを扱うため、上記はそちら寄りの情報となっています。
分析の流れ
次の流れで、次項より分析を行います。

| ステップ | 内容 |
|---|---|
| 目標の設定 | ・本データ分析の最終的な目標を設定 |
| データの収集 | ・分析に必要なデータを収集 |
| データの確認 | ・データの基本情報を確認 ・データの探索 ・データの品質確認 |
| データの準備 | ・データの選択 ・データの整理 ・データの加工 ・データの結合 |
| モデル作成 | ・モデルの選択 ・評価方法の設計 ・モデルの構築 ・モデルの評価 |
| 評価 | ・目標と関連してのモデルの評価 |
なお、実行環境は次の通りです。
- Python
- Google Colaboratory(スクレイピング以外)
- Windows(スクレイピング)
分析の実行
目標の設定
本分析で作成するモデルは、「各レースの馬の着順を1着/2着/3着/それ以外を予測して分類するモデル」とします。
なぜなら、競馬の馬券は1着/2着/3着の中から購入する組み合わせを選ぶものなので、それがモデルで分類できているなら後は適切な賭け方を考えるだけだと思われる……からです。
そして本来、競馬のギャンブル的な側面を見ると、方針の1つとして、的中率を考慮しながら回収率(払い戻しの金額÷馬券を購入した金額)を最大化するように賭けていくので、競馬AIとしての最終的な評価もそれを行うべきだと思われます。
ですが今回は時間や技術の関係上、賭け方の検証までは深入りしません。
まずは、各種機械学習手法を用いて比較、特徴量を変更し、精度の向上を図る。
賭け方の検証は、一番よい結果が出た手法を用いて、単勝は実行、可能なら複勝までみる、とします。
まとめると、次の通りです。
目標
- 各レースの馬の着順を1着/2着/3着/それ以外を予測して分類するモデルを作成する。
- 各種機械学習手法を用いて比較、特徴量を変更し、精度の向上を図る。
- 賭け方の検証は、一番よい結果が出た手法を用いて、単勝は実行、可能なら複勝までみる。
データの収集
分析のためのデータ収集を、競馬サイトnetkeibaより行います。
収集はWebスクレイピングで、Beautiful Soapを用いて行います。
次のサイトを参考にさせていただきました。
ありがとうございます m(_ _ )m
データベースサイト上に表示されている情報に加えて、分析に使用する可能性のある'レースID', '競走馬ID', '騎手ID', '調教師ID', '馬主ID'を収集対象に追加しました。
一応コードも載せておきます。
筆者がスクレピング初心者なのと、とりあえず取れればという感じでお見苦しい部分があると思いますが、ご了承ください。
また、実行する際は自己責任でお願いいたしますmm
サンプルコード
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from tqdm import tqdm
import time
import datetime
df1 = pd.DataFrame()
flg = 0
flg2 = 0
base = 'https://db.sp.netkeiba.com/race/' # URL先頭の固定部分
for year in tqdm(range(2016,2022)):
df1 = pd.DataFrame()
for basyo in range(1,11):
for kaisu in range(1,7):
for nichime in range(1,10):
for race in range(1,13):
# 1秒スリープ
time.sleep(1)
race_id = str(year)+str(basyo).zfill(2)+str(kaisu).zfill(2)+str(nichime).zfill(2)+str(race).zfill(2)
url = base + race_id
try:
html = requests.get(url)
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text, 'lxml')
except:
print('requests error')
break
table=soup.find(class_="table_slide_body ResultsByRaceDetail")
if (table == []) | (table == None):
print('break',url)
break
else:
for tr in table.find_all('tr')[1:]:
try:
temp=[]
temp.append(race_id) # race_id
temp.append(soup.find_all(class_="Race_Date")[0].contents[0].string.strip()) # 日付
temp.append(soup.find_all(class_="Race_Date")[0].contents[1].string.strip()) # 曜日
temp.append(race) # R数
temp.append(basyo) # 場所ID
temp.append(kaisu) # 回数
temp.append(nichime) # 日目
temp.append(soup.find_all(class_="RaceName_main")[0].string) # レース名
temp.append(soup.find_all(class_="RaceData")[0].contents[1].string) # レース時間
temp.append(soup.find_all(class_="RaceData")[0].contents[3].string) # レース場情報
temp.append(soup.find_all(class_="RaceData")[0].contents[5].contents[0]) # 天候
temp.append(soup.find_all(class_="RaceData")[0].contents[7].string) # 馬場
temp.append(soup.find_all(class_="RaceHeader_Value_Others")[0].contents[1].string) #レース情報1
temp.append(soup.find_all(class_="RaceHeader_Value_Others")[0].contents[3].string) #レース情報2
temp.append(len(table.find_all('tr')) - 1) # 頭数
cnt1 = 0
for td in tr.find_all('td'):
temp.append(td.string)
# horse_id
if cnt1 == 3:
cnt2 = 0
for alink in tr.find_all('a'):
if cnt2 == 0:
href = alink.get('href')
horse_id = href.split('/')[-2]
temp.append(horse_id)
break
cnt2 += 1
# jockey_id
if cnt1 == 6:
cnt2 = 0
for alink in tr.find_all('a'):
if cnt2 == 1:
href = alink.get('href')
jockey_id = href.split('/')[-2]
temp.append(jockey_id)
break
cnt2 += 1
# trainer_id
if cnt1 == 18:
cnt2 = 0
for alink in tr.find_all('a'):
href = alink.get('href')
if 'trainer' in href:
trainer_id = href.split('/')[-2]
temp.append(trainer_id)
break
cnt2 += 1
# owner_id
if cnt1 == 19:
cnt2 = 0
for alink in tr.find_all('a'):
href = alink.get('href')
if 'owner' in href:
owner_id = href.split('/')[-2]
temp.append(owner_id)
break
cnt2 += 1
cnt1 += 1
df1 = pd.concat([df1, pd.DataFrame(temp).T])
flg = 0
except:
flg = 1
pass
if flg == 0:
print('OK',url)
else:
print('NG',url)
flg = 0
df1.columns=['race_id','日付','曜日','R数','場所ID','回数','日目','レース名','レース時間','レース場情報','天候','馬場','レース情報1','レース情報2','頭数','着順','枠番','馬番','馬名','horse_id', '性齢','斤量','騎手','jockey_id','タイム','着差','タイム指数','通過','上り','単勝','人気','馬体重','調教タイム','厩舎コメント','備考','調教師','trainer_id','馬主','owner_id','賞金']
df1.to_csv('data' + str(year) + '.csv',encoding='utf_8_sig')
データの確認
というわけで料理番組あるあるみたいになってしまいますが、あらかじめ用意されたデータがこちらです(やり方の問題かもしれませんが、取得に5-6時間/年かかりました ![]() )。
)。
4桁の数値は、その年度の競馬データです。
これを、2008~2020を訓練データ/検証データ、2021をテストデータとして使用します。
まずは全部繋げた上で、形式やレコード数を見てみます。
import pandas as pd
df_all = pd.DataFrame()
for year in range(2008, 2022):
df = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/競馬AI/data" + str(year) + ".csv", header=0)
df_all = pd.concat([df_all, df], axis=0)
df_all.shape
(666039, 40)
df_all.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 666039 entries, 0 to 45382
Data columns (total 40 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 race_id 666039 non-null int64
1 日付 666039 non-null object
2 曜日 666039 non-null object
3 R数 666039 non-null int64
4 場所ID 666039 non-null int64
5 回数 666039 non-null int64
6 日目 666039 non-null int64
7 レース名 666039 non-null object
8 レース時間 666039 non-null object
9 レース場情報 666039 non-null object
10 天候 666039 non-null object
11 馬場 666039 non-null object
12 レース情報1 666039 non-null object
13 レース情報2 666039 non-null object
14 頭数 666039 non-null int64
15 着順 666039 non-null object
16 枠番 666039 non-null int64
17 馬番 666039 non-null int64
18 馬名 666039 non-null object
19 horse_id 666039 non-null int64
20 性齢 666039 non-null object
21 斤量 666039 non-null float64
22 騎手 666039 non-null object
23 jockey_id 666039 non-null int64
24 タイム 660348 non-null object
25 着差 613611 non-null object
26 タイム指数 66895 non-null object
27 通過 662591 non-null object
28 上り 660343 non-null float64
29 単勝 666039 non-null object
30 人気 663639 non-null float64
31 馬体重 666039 non-null object
32 調教タイム 81 non-null object
33 厩舎コメント 1571 non-null object
34 備考 520806 non-null object
35 調教師 666039 non-null object
36 trainer_id 666039 non-null int64
37 馬主 666039 non-null object
38 owner_id 666039 non-null object
39 賞金 233107 non-null object
dtypes: float64(3), int64(11), object(26)
memory usage: 208.3+ MB
この中から、特徴量として使用予定のデータに絞って記載します。
| Column | Non-Null Count | Dtype | コメント |
|---|---|---|---|
| 場所ID | 666039 | int64 | 1~10 |
| レース場情報 | 666039 | object | 'ダ1700m(右)'のように、コース('芝', 'ダ', '障')、距離(1000~3600)、方向('右', '芝', '左', '直')がくっついているので、分けて使用する。 |
| 天候 | 666039 | object | '曇', '晴', '小雨', '雨', '小雪', '雪' |
| 馬場 | 666039 | object | '良', '稍', '不', '重' |
| 頭数 | 666039 | int64 | 5~18 |
|
出走時点で得られるデータではない且つ、このデータからTargetを決めるので除外。 |
|||
| 枠番 | 666039 | int64 | 1~8 |
| 馬番 | 666039 | int64 | 1~18 |
| horse_id | 666039 | int64 | 10桁のID |
| 性齢 | 666039 | object | 性('牡', '牝', 'セ')、齢(2~12)がくっついているので、分けて使用する。 |
| 斤量 | 666039 | float64 | 54.0~61.5 |
| jockey_id | 666039 | int64 | 3桁ないし4桁のID |
| 人気 | 663639 | float64 | 1~18、NaN。 欠損値がある。着順が'除', '取' のデータの人気がNaNになっている。除外の方針。 |
| 馬体重 | 666039 | object | '554(+24)', '418(-6)'のように、その時点の馬体重と増減がくっついているので、分けて使用する。 また、'計不'となっているものは除外の方針。 |
| trainer_id | 666039 | int64 | 3桁ないし4桁のID |
|
欠損値がある。一定の着順以上のみ賞金があるため、他がNaNになっている。0で埋める。 出走時点で得られるデータではないので除外。 |
それぞれのデータについて、value_counts()、unique()、query()などを使いながら確認しました。
しかし……こういうデータ操作がしたい! という思いはあるのですがなかなか思い通りにできず、歯がゆい。
このあたりは、データサイエンス100本ノック(構造化データ加工編)などで力をつけたい所です(まだ途中)。
そして、データの成形や使用方法についても悩み所です。
カテゴリカル変数はエンコーディングが必要とのことですが、One-Hot Encodingはカテゴリが多いと特徴量が膨大になってしまうとのこと。horse_id/jockey_id/trainer_idは種類が多いので微妙そうです(このあたりはやってみるしかない?)。
別のエンコーディングとして、Label-Encodingというものがあるとのことですが、これはロジスティック回帰には向いてないらしい。
尺度水準についても気になります。
コース('芝', 'ダ', '障')は名義尺度でよさそうですが、天候や馬場もそうなのでしょうか?
一般的に、芝コースでは良馬場のタイムが最も良く、'良'>'稍'>'不'>'重'の順で遅くなって行きます。なんだか順序尺度になりそうです。
しかし、ダートコースでは'稍'や'不'の方がタイムが早くなる傾向にあり、芝と違う傾向を見せます。
このあたりは、色々チューニングしていく所になるのでしょうかね…… ![]()
最初は何も考えず、全体的にOne-Hot Encodingしてやってみましょう。
ともかく方針が決まったので、これらに対して前処理を施していきます。
データの準備
まずは、欠損値の処理と、データを使える形に分割します。
# 欠損値の処理
# '人気'列がNaNの行を除外
df_all.dropna(subset=['人気'], inplace=True)
# '着順'が数値以外の行を除外し、int型に変換
df_all['着順'] = pd.to_numeric(df_all['着順'], errors='coerce')
df_all.dropna(subset=['着順'], inplace=True)
df_all['着順'] = df_all['着順'].astype(int)
# データの分割
# 'レース場情報'を'コース', '距離', '方向'に分割
df_all['コース'] = df_all['レース場情報'].map(lambda x: str(x)[0:1])
df_all['距離'] = df_all['レース場情報'].map(lambda x: str(x)[1:5]).astype(int)
df_all['方向'] = df_all['レース場情報'].map(lambda x: str(x)[7:8])
# '性齢'を'性'と'年齢'に分割
df_all['性'] = df_all['性齢'].map(lambda x: str(x)[0:1])
df_all['年齢'] = df_all['性齢'].map(lambda x: str(x)[1:3]).astype(int)
# '馬体重'を'馬体重_当日', '馬体重_増減'に分割
df_all['馬体重_当日'] = df_all["馬体重"].str.split("(", expand=True)[0]
df_all['馬体重_増減'] = df_all["馬体重"].str.split("(", expand=True)[1].str[:-1]
# '馬体重_当日'に'計不'が残っているので、中央値で補完
df_all['馬体重_当日'] = pd.to_numeric(df_all['馬体重_当日'], errors='coerce')
df_all['馬体重_当日'] = df_all['馬体重_当日'].fillna(df_all['馬体重_当日'].median())
df_all['馬体重_当日'] = df_all['馬体重_当日'].astype(int)
# '馬体重_増減'に'None'が残っているので、中央値で補完
df_all['馬体重_増減'] = pd.to_numeric(df_all['馬体重_増減'], errors='coerce')
df_all['馬体重_増減'] = df_all['馬体重_増減'].fillna(df_all['馬体重_増減'].median())
df_all['馬体重_増減'] = df_all['馬体重_増減'].astype(int)
次に、正解ラベルを追加します。
# 正解ラベル。着順1-3はそのまま、それ以外は4
df_all['Target'] = df_all['着順'].map(lambda x: x if x <= 4 else 4)
訓練データとテストデータに分けるフラグを付与しておきます。
# 訓練データとテストデータに分けるフラグを付与
df_all['Test_Flag'] = df_all['race_id'].map(lambda x: 1 if x >= 202100000000 else 0)
カテゴリ変数に対して、One-Hot Encodingを行います。
後の検証で変更するかもしれませんが、一旦これで。
# One-Hot Encoding
df_all = pd.get_dummies(df_all, columns= ['コース','方向','天候','馬場','性'])
これで、データの前処理が完了しました。
いよいよモデル作成です!
モデル作成
モデルについては、次の3つを試してみます。
- ロジスティック回帰
- 非線形SVM
- LightGBM
また、モデルの評価は、ホールドアウト法で正解率を確認。
最も正解率が高いモデルで単勝を検証して、回収率100%を目指します。
ロジスティック回帰
まずは何もパラメーターをいじらず、モデルの学習を行ってみます。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import RandomizedSearchCV
import scipy.stats
# 訓練データとテストデータに分割
df_train = df_all[df_all['Test_Flag'] == 0].reset_index(drop = True)
df_test = df_all[df_all['Test_Flag'] == 1].reset_index(drop = True)
# targetの設定
target = df_train['Target']
# 学習に使用しないカラムを削除
# 一旦、horse_id/jockey_id/trainer_id/owner_idも除外
drop_col = [
'race_id','日付','曜日','R数','場所ID',
'回数','日目','レース名','レース時間','レース場情報',
'レース情報1','レース情報2', '着順', '馬名','horse_id','性齢',
'騎手','jockey_id','タイム','着差','タイム指数',
'通過','上り','単勝','馬体重','調教タイム',
'厩舎コメント','備考','調教師','trainer_id','馬主',
'owner_id', 'Test_Flag', 'Target'
]
df_train = df_train.drop(drop_col, axis=1)
X_train ,X_val ,y_train ,y_val = train_test_split(
df_train, target,
test_size =0.2, shuffle = False, random_state = 0
)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
print('正解率:{}'.format(accuracy_score(y_val, y_pred)))
正解率:0.7818492176386913
なかなかの正解率に見えますがどうなのでしょうか?
どのように分類されたか、割合を見てみます。
# Targetの内訳を返す関数
def targetRatio(arr):
u, counts = np.unique(arr, return_counts=True)
for i in range(0, len(np.unique(u))):
print(f'{u[i]}:{counts[i]/np.sum(counts)*100}%')
targetRatio(y_pred)
4:100.0%
なんと、全てが4という予想結果に ![]()
どうやら調べてみた所、不均衡データを扱っているためのようでした。
正解は4が多いんだから、4って予想しておけば正解率あがるやん、みたいに処理されているらしいですね。
念のためと今後用に、訓練データの正解ラベルの割合を見てみます。
余談ですが、下記割合で1/2/3着が同じになっていないのは、同着があるからでした。
targetRatio(target)
1:7.050958996751863%
2:7.044618791069089%
3:7.046894762339829%
4:78.85752744983921%
こちらも調べてみたところ、アンダーサンプリングという操作を行えばよい、とのことだったので実装しなおしてみます。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import RandomizedSearchCV
import scipy.stats
from imblearn.under_sampling import RandomUnderSampler
# 訓練データとテストデータに分割
df_train = df_all[df_all['Test_Flag'] == 0].reset_index(drop = True)
df_test = df_all[df_all['Test_Flag'] == 1].reset_index(drop = True)
# targetの設定
target = df_train['Target']
# 学習に使用しないカラムを削除
# 一旦、horse_id/jockey_id/trainer_id/owner_idも除外
drop_col = [
'race_id','日付','曜日','R数','場所ID',
'回数','日目','レース名','レース時間','レース場情報',
'レース情報1','レース情報2', '着順', '馬名','horse_id','性齢',
'騎手','jockey_id','タイム','着差','タイム指数',
'通過','上り','単勝','馬体重','調教タイム',
'厩舎コメント','備考','調教師','trainer_id','馬主',
'owner_id', '賞金', 'Test_Flag', 'Target'
]
df_train = df_train.drop(drop_col, axis=1)
X_train ,X_val ,y_train ,y_val = train_test_split(
df_train, target,
test_size = 0.2, shuffle = False, random_state = 0
)
# アンダーサンプリング
rank_1 = y_train.value_counts()[1]
rank_2 = y_train.value_counts()[2]
rank_3 = y_train.value_counts()[3]
rus = RandomUnderSampler(sampling_strategy ={1:rank_1, 2:rank_2, 3:rank_3, 4:rank_1}, random_state=0)
X_train_rus, y_train_rus = rus.fit_resample(X_train, y_train)
model = LogisticRegression()
model.fit(X_train_rus, y_train_rus)
y_pred = model.predict(X_val)
print('正解率:{}'.format(accuracy_score(y_val, y_pred)))
正解率:0.5712497459865881
正解率は下がりましたが、分類はどうでしょうか?
targetRatio(y_pred)
1:24.00162568583621%
2:5.60130054866897%
3:16.270676691729324%
4:54.126397073765496%
偏りはあるものの、分類はできているようです!
ひとまずこれで進めてみましょう。
続けて、パラメーター調整で変化するでしょうか?
ランダムサーチを試してみます。
param = {
"penalty" : ['l1', 'l2', 'elasticnet'],
"C": scipy.stats.uniform(0.00001, 1000),
"max_iter" : list(range(10, 201, 10)),
"multi_class" : ['auto', 'ovr', 'multinomial'],
"random_state": list(range(1, 101, 1))}
clf = RandomizedSearchCV(LogisticRegression(), param, cv = 5, n_iter = 30)
clf.fit(X_train_rus, y_train_rus)
model = LogisticRegression(
C = clf.best_params_['C'],
max_iter = clf.best_params_['max_iter'],
multi_class = clf.best_params_['multi_class'],
penalty = clf.best_params_['penalty'],
random_state = clf.best_params_['random_state'])
model.fit(X_train_rus, y_train_rus)
y_pred = model.predict(X_val)
print('正解率:{}'.format(accuracy_score(y_val, y_pred)))
正解率:0.5732574679943101
Before : 0.5712497459865881
After : 0.5732574679943101
微増ですね(笑)
でも、重要な値なのかもしれない。
割合は下記の通りです。
targetRatio(y_pred)
1:23.5724446250762%
2:6.29302987197724%
3:15.850436903068482%
4:54.284088599878075%
判定:1の回収率がよければ、単勝を予想するAIとしては優秀そうですがどうなのか。
検証は後にして、別のモデルも試してみましょう。
非線形SVM
今度は最初からパラメーター調整ありで行います。
from sklearn.svm import SVC
param = {
"kernel": ["linear", "poly", "rbf", "sigmoid"],
"C": scipy.stats.uniform(0.00001, 1000),
"max_iter" : list(range(10, 201, 10)),
"decision_function_shape": ["ovr", "ovo"],
"random_state": list(range(1, 101, 1))}
clf = RandomizedSearchCV(SVC(), param, cv = 5, n_iter = 30)
clf.fit(X_train_rus, y_train_rus)
model = SVC(
C = clf.best_params_['C'],
decision_function_shape = clf.best_params_['decision_function_shape'],
kernel = clf.best_params_['kernel'],
max_iter = clf.best_params_['max_iter'],
random_state = clf.best_params_['random_state'])
model.fit(X_train_rus, y_train_rus)
y_pred = model.predict(X_val)
print('正解率:{}'.format(accuracy_score(y_val, y_pred)))
正解率:0.25552529973582605
正解率としては、ロジスティック回帰より低いです。
割合はどうでしょうか。
targetRatio(y_pred)
1:34.53281853281853%
2:3.017272912009754%
3:40.72424304003251%
4:21.7256655151392%
だいぶ1と3の割合が多いですね。
次にLightGBMです。
LightGBM
import lightgbm as lgb
param = {
'num_leaves': [7, 5, 31],
'max_depth': [5, 7, 9],
'min_data_in_leaf': [20, 30, 50],
'bagging_fraction':[0.8, 0.9],
'bagging_freq': [1, 3],
'feature_fraction':[0.9, 1.0],
'reg_alpha': [0, 1, 2, 3, 4, 5, 10, 100],
'reg_lambda': [10, 15, 18, 20, 21, 22, 23, 25, 27, 29]
}
clf = RandomizedSearchCV(lgb.LGBMClassifier(), param, cv = 5, n_iter = 30)
clf.fit(X_train_rus, y_train_rus)
model = lgb.LGBMClassifier(
reg_lambda = clf.best_params_['reg_lambda'],
reg_alpha = clf.best_params_['reg_alpha'],
min_data_in_leaf = clf.best_params_['min_data_in_leaf'],
max_depth = clf.best_params_['max_depth'],
feature_fraction = clf.best_params_['feature_fraction'],
bagging_freq = clf.best_params_['bagging_freq'],
bagging_fraction = clf.best_params_['bagging_fraction'])
model.fit(X_train_rus, y_train_rus)
y_pred = model.predict(X_val)
print('正解率:{}'.format(accuracy_score(y_val, y_pred)))
正解率:0.5742653932127616
targetRatio(y_pred)
1:13.414346677504572%
2:9.201381832960779%
3:23.23836618573461%
4:54.14590530380005%
大きな差ではないですが、3つの中では一番よい正解率となりました。
この結果を用いて、モデルを評価していきます!
評価
前述の通り、単勝の回収率を見てみます。
単勝は、当たった時の倍率が各行(データ)ごとに定義されています。
購入1点100円で計算したとすると、
- 予想結果が1のデータをすべて購入したと仮定し、100を掛ける(購入額:①)
- 予想も結果も1だった(当たった)買い目の単勝倍率の合計値に100を掛け(回収額)、①で割る
という形で回収率が求められるはずです。
取っておいた2021年のデータをモデルを用いて予想し、回収率(等)を見てみます。
# 評価用にデータをバックアップ
df_eval = pd.DataFrame({"race_id": df_test['race_id'], "単勝": df_test['単勝'], "結果": df_test['Target']})
df_eval['単勝'] = pd.to_numeric(df_eval['単勝'], errors='coerce')
# targetの設定
target_test = df_test['Target']
# 使用しないカラムを削除
drop_col = [
'race_id','日付','曜日','R数','場所ID',
'回数','日目','レース名','レース時間','レース場情報',
'レース情報1','レース情報2', '着順', '馬名','horse_id','性齢',
'騎手','jockey_id','タイム','着差','タイム指数',
'通過','上り','単勝','馬体重','調教タイム',
'厩舎コメント','備考','調教師','trainer_id','馬主',
'owner_id', '賞金', 'Test_Flag', 'Target'
]
df_test = df_test.drop(drop_col, axis=1)
# モデルで予測
y_pred_test = model.predict(df_test)
# 結果を評価用データに連結
df_eval['予想'] = y_pred_test
# 回収率等を算出
cntRace = df_eval['race_id'].unique().shape[0] # 全レース数
cntBetRace = df_eval[df_eval['予想'] == 1]['race_id'].unique().shape[0] # 購入レース数
betRaceRate = cntBetRace / cntRace * 100 # 購入レース率
cntBetPoint = df_eval[df_eval['予想'] == 1].shape[0] # 購入点数
betMoney = cntBetPoint * 100 # 購入額
cntBetPointByRace = 0 if cntBetRace == 0 else cntBetPoint / cntBetRace # 購入レース毎購入点数(購入点数/購入レース数)
cntHitRace = df_eval[df_eval['予想'] == 1][df_eval['結果'] == 1]['race_id'].unique().shape[0] # 的中レース数
hitRate = 0 if cntBetRace == 0 else cntHitRace / cntBetRace * 100 # 的中率(的中レース数/購入レース数*100)
sumWin = df_eval[df_eval['予想'] == 1][df_eval['結果'] == 1]['単勝'].sum() # 的中した買い目の倍率の合計
backMoneyAll = sumWin * 100 # 払戻額(的中した買い目の倍率の合計*100)
backMoneyHit = backMoneyAll - betMoney # 回収額(払戻額-購入額)
backRateHit = 0 if betMoney == 0 else (backMoneyAll / betMoney) * 100 # 回収率(払戻額/購入額*100)
print(f'全レース数:{cntRace}')
print()
print(f'購入レース数:{cntBetRace}')
print(f'購入レース率:{betRaceRate}%')
print(f'購入点数:{cntBetPoint}')
print(f'購入額:{betMoney}円')
print(f'購入レース毎購入点数(購入点数/購入レース数):{cntBetPointByRace}')
print()
print(f'的中レース数:{cntHitRace}')
print(f'的中率(的中レース数/購入レース数*100):{hitRate}%')
print()
print(f'払戻額(的中した買い目の倍率の合計*100):{backMoneyAll}円')
print(f'回収額(払戻額-購入額):{backMoneyHit}円')
print(f'回収率(払戻額/購入額*100):{backRateHit}%')
全レース数:3276
購入レース数:3272
購入レース率:99.87789987789988%
購入点数:6122
購入額:612200円
購入レース毎購入点数(購入点数/購入レース数):1.8710268948655258
的中レース数:1624
的中率(的中レース数/購入レース数*100):49.63325183374083%
払戻額(的中した買い目の倍率の合計*100):508080.0000000001円
回収額(払戻額-購入額):-104119.99999999988円
回収率(払戻額/購入額*100):82.9924861156485%
というわけで、回収率は約83%(回収額-104120円)!
このモデルに従い単勝馬券を購入しても損をしそう、という結果となりました! ![]()
ただこれは、1位予想した買い目を全て買っているから、というのもありそうです。
約99.9%のレースで購入、購入レース毎に約1.87点買っています。
的中率(的中レース数÷購入レース数×100)も49.6%あって、買いすぎに見えます。
これを買い方を考えて、人気がn番目のものだけ買う……とか、単勝倍率がn倍以上のものを買う、など工夫できそうです。
評価 - 延長戦
というわけで延長戦です。
試しに、単勝倍率がn倍以上の予想1位を買った場合の変化を見てみます。
Y軸は的中率と、回収率とします。
!pip install japanize_matplotlib # 日本語ラベル対応
import japanize_matplotlib
import matplotlib.pyplot as plt
x_winRate = []
y_hitRate = []
y_backRate = []
# 単勝倍率ごとの結果データを取得
for i in range(0, 16):
# 単勝倍率
x_winRate.append(i)
# 必要なデータの計算
cntBetRace = df_eval[df_eval['予想'] == 1][df_eval['単勝'] >= i]['race_id'].unique().shape[0] # 購入レース数
cntBetPoint = df_eval[df_eval['予想'] == 1][df_eval['単勝'] >= i].shape[0] # 購入点数
betMoney = cntBetPoint * 100 # 購入額
cntHitRace = df_eval[df_eval['予想'] == 1][df_eval['結果'] == 1][df_eval['単勝'] >= i]['race_id'].unique().shape[0] # 的中レース数
hitRate = 0 if cntBetRace == 0 else cntHitRace / cntBetRace * 100 # 的中率(的中レース数/購入レース数*100)
sumWin = df_eval[df_eval['予想'] == 1][df_eval['結果'] == 1][df_eval['単勝'] >= i]['単勝'].sum() # 的中した買い目の倍率の合計
backMoneyAll = sumWin * 100 # 払戻額(的中した買い目の倍率の合計*100)
backMoneyHit = backMoneyAll - betMoney # 回収額(払戻額-購入額)
backRateHit = 0 if betMoney == 0 else (backMoneyAll / betMoney) * 100 # 回収率(払戻額/購入額*100)
# 的中率
y_hitRate.append(hitRate)
# 回収率
y_backRate.append(backRateHit)
fig = plt.figure()
ax1 = fig.subplots()
ax2 = ax1.twinx()
label_x_winRate = '単勝倍率(この倍率以上の予想1位を買う)'
label_y_hitRate = '的中率'
label_y_backRate = '回収率'
# グラフ描画
ax1.plot(x_winRate, y_hitRate, color="b", label = label_y_hitRate)
ax2.plot(x_winRate, y_backRate, color="r", label = label_y_backRate)
# 軸ラベルの色を変更
ax1.set_xlabel(label_x_winRate)
ax1.set_ylabel(label_y_hitRate, color="b")
ax2.set_ylabel(label_y_backRate, color="r")
# 軸の目盛りの色を変更
ax1.tick_params(axis = 'y', colors ='b')
ax2.tick_params(axis = 'y', colors ='r')
plt.show()
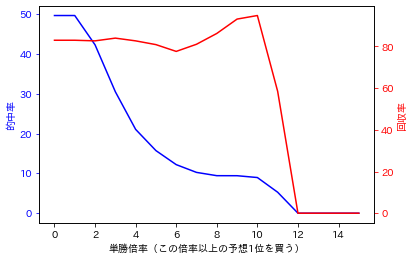
15倍まで見てみましたが、100%を超えることはなさそうでした。
世知辛いですね ![]()
ただこれは、単勝倍率n倍以上の買い目を全て買っています。
さらにあがいて、単勝倍率n倍以上n+m倍未満を全て買う、みたいに幅を設定して購入した場合はどうでしょう?
基礎倍率nを0~15倍、加算倍率mを1~10倍で見てみます。
!pip install japanize_matplotlib # 日本語ラベル対応
import japanize_matplotlib
import matplotlib.pyplot as plt
# 最大回収額時のデータを保持する変数
maxBack_winRateBase = 0 # 基礎倍率
maxBack_winRatePlus = 0 # 加算倍率
maxBack_cntBetRace = 0 # 購入レース数
maxBack_cntBetPoint = 0 # 購入点数
maxBack_betMoney = 0 # 購入額
maxBack_cntBetPointByRace = 0 # レース毎購入点数
maxBack_cntHitRace = 0 # 的中レース数
maxBack_hitRate = 0 # 的中率
maxBack_backMoneyAll = 0 # 払戻額
maxBack_backMoneyHit = (df_eval.shape[0] + 1) * -100 # 回収額(全購入点数+1負けた場合で初期化)
maxBack_backRateHit = 0 # 回収率
# 単勝倍率に加算してどこまで購入するかを決定
for j in range(1, 11):
x_winRate = []
y_hitRate = []
y_backRate = []
# 単勝倍率ごとの結果データを取得
for i in range(0, 16):
# 単勝倍率
x_winRate.append(i)
# 必要なデータの計算
cntRace = df_eval['race_id'].unique().shape[0] # 全レース数
cntBetRace = df_eval[df_eval['予想'] == 1][df_eval['単勝'] >= i][df_eval['単勝'] < i + j]['race_id'].unique().shape[0] # 購入レース数
cntBetPoint = df_eval[df_eval['予想'] == 1][df_eval['単勝'] >= i][df_eval['単勝'] < i + j].shape[0] # 購入点数
betMoney = cntBetPoint * 100 # 購入額
cntBetPointByRace = 0 if cntBetRace == 0 else cntBetPoint / cntBetRace # 購入レース毎購入点数(購入点数/購入レース数)
cntHitRace = df_eval[df_eval['予想'] == 1][df_eval['結果'] == 1][df_eval['単勝'] >= i][df_eval['単勝'] < i + j]['race_id'].unique().shape[0] # 的中レース数
hitRate = 0 if cntBetRace == 0 else cntHitRace / cntBetRace * 100 # 的中率(的中レース数/購入レース数*100)
sumWin = df_eval[df_eval['予想'] == 1][df_eval['結果'] == 1][df_eval['単勝'] >= i][df_eval['単勝'] < i + j]['単勝'].sum() # 的中した買い目の倍率の合計
backMoneyAll = sumWin * 100 # 払戻額(的中した買い目の倍率の合計*100)
backMoneyHit = backMoneyAll - betMoney # 回収額(払戻額-購入額)
backRateHit = 0 if betMoney == 0 else (backMoneyAll / betMoney) * 100 # 回収率(払戻額/購入額*100)
# 的中率
y_hitRate.append(hitRate)
# 回収率
y_backRate.append(backRateHit)
# 最大回収額時のデータを保持
if backMoneyHit > maxBack_backMoneyHit:
maxBack_winRateBase = i # 単勝基礎倍率
maxBack_winRatePlus = j # 単勝加算倍率
maxBack_cntBetRace = cntBetRace # 購入レース数
maxBack_cntBetPoint = cntBetPoint # 購入点数
maxBack_betMoney = cntBetPoint * 100 # 購入額
maxBack_cntBetPointByRace = cntBetPointByRace # 購入レース毎購入点数
maxBack_cntHitRace = cntHitRace # 的中レース数
maxBack_hitRate = hitRate # 的中率
maxBack_backMoneyAll = backMoneyAll # 払戻額
maxBack_backMoneyHit = backMoneyHit # 回収額
maxBack_backRateHit = backRateHit # 回収率
fig = plt.figure()
ax1 = fig.subplots()
ax2 = ax1.twinx()
label_x_winRate = '単勝倍率' + ' < + ' + str(j)
label_y_hitRate = '的中率'
label_y_backRate = '回収率'
# グラフ描画
ax1.plot(x_winRate, y_hitRate, color="b", label = label_y_hitRate)
ax2.plot(x_winRate, y_backRate, color="r", label = label_y_backRate)
# 軸ラベルの色を変更
ax1.set_xlabel(label_x_winRate)
ax1.set_ylabel(label_y_hitRate, color="b")
ax2.set_ylabel(label_y_backRate, color="r")
# 軸の目盛りの色を変更
ax1.tick_params(axis = 'y', colors ='b')
ax2.tick_params(axis = 'y', colors ='r')
plt.show()
# 最大回収額
print()
print(f'基礎倍率:{maxBack_winRateBase}')
print(f'加算倍率:{maxBack_winRatePlus}')
print()
print(f'全レース数:{cntRace}')
print()
print(f'購入レース数:{maxBack_cntBetRace}')
print(f'購入点数:{maxBack_cntBetPoint}')
print(f'購入額:{maxBack_betMoney}円')
print(f'購入レース毎購入点数(購入点数/購入レース数):{maxBack_cntBetPointByRace}')
print()
print(f'的中レース数:{maxBack_cntHitRace}')
print(f'的中率(的中レース数/購入レース数*100):{maxBack_hitRate}%')
print()
print(f'払戻額(的中した買い目の倍率の合計*100):{maxBack_backMoneyAll}円')
print(f'回収額(払戻額-購入額):{maxBack_backMoneyHit}円')
print(f'回収率(払戻額/購入額*100):{maxBack_backRateHit}%')
基礎倍率:10
加算倍率:2
全レース数:3276
購入レース数:41
購入点数:41
購入額:4100円
購入レース毎購入点数(購入点数/購入レース数):1.0
的中レース数:6
的中率(的中レース数/購入レース数*100):14.634146341463413%
払戻額(的中した買い目の倍率の合計*100):6450.0円
回収額(払戻額-購入額):2350.0円
回収率(払戻額/購入額*100):157.3170731707317%
なんと、回収率が約157%となりました!(。・ω・ノノ゙パチパチ
この買い方をすれば大金持ち! ……とはなりませんね。
見てのとおり、1年通じて回収額が2350円しかありません。
1年間のお昼ご飯代も稼げなそうです。
購入金額を上げれば……は危険な思考です。
この少ない買い目が当たるとは限りませんし ![]()
最大回収額の場合でもこれなので、このモデルではやはりそもそものベースの正解率を上げる必要がありそうです。
的中率はいいバランスかな? と思いつつ、購入点数が低いことも要因かもです。
ちなみに、回収額が最大の時のグラフはこんな感じでした。
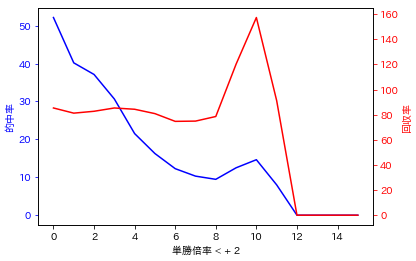
回収率は基礎倍率n=10、加算倍率m=1の時(1位予想かつ単勝倍率が10倍以上11倍未満を購入)のほうが高かったです。
このモデルは大穴狙いなのかな?w
もう少し切り口を変えれば、回収率/回収額のいいポイントが探れるかもしれません。
これは競馬AIの評価としては重要な観点ですね。
まとめ
というわけで、競馬AI実装を試してみる話でした。
色々苦労はしたのですが、主だったものといえば、
- 最初、学習データに'着順'を含んでいて、LightGBMの予想結果が 正解率100% になった(着順は正解ラベルの元としていたデータ。実際の予想時には存在しない)
- '着順'除外後も、LightGBMの学習結果を評価したら 回収率が900% ぐらいあった。おそらく'賞金'データを含んでいたため(これも実際の予想時には存在しないデータ)
でしょうか(リーケージというらしいですね)。
これを修正しても予想が偏って迷って、アンダーサンプリングを試して……と、ここまでの記事にはすべてを書ききれていないですが、一筋縄ではいきませんでした。
でもやってみて考えながら実装してみたからこそ身についた部分も本当に大いにあって、ためになりました。
扱った競馬という題材も、データにある程度欠損があったり意図しない形式が紛れ込んでいたりで、初学者にはちょうどよいものだった印象があります。
まだまだこれで終わりではなく、特徴量(血統、前走データなど)を追加したり切り口を変えたりすれば、モデルとしての評価も上がると思いますし、それこそ機械学習でやっていくべきことなのかな、と感じています。
ともあれ、今回はここまでです。
長文となりましたが、ご視聴ありがとうございました!mm