Alexnetでなにができるか?
- 最初の論文 in 2012
- 画像を入れると1000クラスのそれぞれに属する確率を推定する
- そこからその画像の判別が行える
- 中身のわかりやすい解説
- 他のモデルとの比較
-
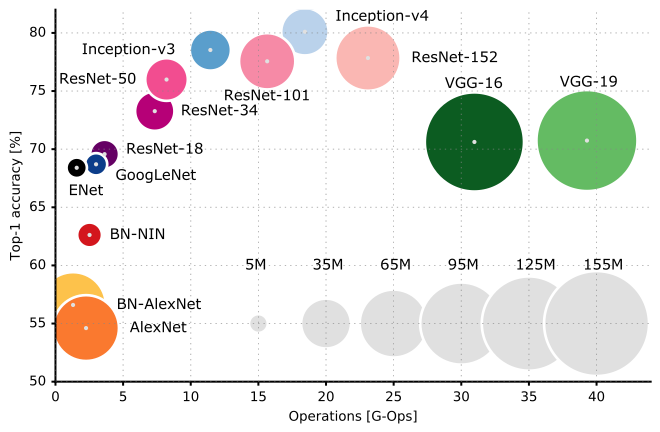
こちらより
ooO ( まぁ最初期に出てきたもの、ということで一般的に精度が出るものではない模様
使うもの
Googleの公開しているモデル
- github
- 元論文
- トレーニングの際にFull connected layerとConvolutional layerにそれぞれ別の並列化を導入したもの
- models/research/slim/nets/alexnet.pyに中身があります
- 既存のモデルを実装してslimというより高次のラッパーからアクセスできるような形式になっています
README.md
TF-slim is a new lightweight high-level API of TensorFlow
(tensorflow.contrib.slim) for defining, training and evaluating
complex models.
中を見る
中身はいたってシンプル。関数は二つだけ。
中で使われているパーツをslimのargument構造で返す
- weight_decayは受け取れるということは任意に設定可能?
alexnet.py
def alexnet_v2_arg_scope(weight_decay=0.0005):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
biases_initializer=tf.constant_initializer(0.1),
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope([slim.conv2d], padding='SAME'):
with slim.arg_scope([slim.max_pool2d], padding='VALID') as arg_sc:
return arg_sc
本体
- conv2d, max_pool2d, conv2d, max_pool2d, cov2d, conv2d, conv2d, max_pool2dにfully connected or cov2dが2つ重ねられる構造。クラス数が指定されている場合にはdropout+そのクラス数に合わせた出力層が一層入っている。
alexnet.py
def alexnet_v2(inputs,
num_classes=1000,
is_training=True,
dropout_keep_prob=0.5,
spatial_squeeze=True,
scope='alexnet_v2',
global_pool=False):
with tf.variable_scope(scope, 'alexnet_v2', [inputs]) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
# Collect outputs for conv2d, fully_connected and max_pool2d.
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d],
outputs_collections=[end_points_collection]):
net = slim.conv2d(inputs, 64, [11, 11], 4, padding='VALID',
scope='conv1')
net = slim.max_pool2d(net, [3, 3], 2, scope='pool1')
net = slim.conv2d(net, 192, [5, 5], scope='conv2')
net = slim.max_pool2d(net, [3, 3], 2, scope='pool2')
net = slim.conv2d(net, 384, [3, 3], scope='conv3')
net = slim.conv2d(net, 384, [3, 3], scope='conv4')
net = slim.conv2d(net, 256, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [3, 3], 2, scope='pool5')
# Use conv2d instead of fully_connected layers.
with slim.arg_scope([slim.conv2d],
weights_initializer=trunc_normal(0.005),
biases_initializer=tf.constant_initializer(0.1)):
net = slim.conv2d(net, 4096, [5, 5], padding='VALID',
scope='fc6')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout6')
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
# Convert end_points_collection into a end_point dict.
end_points = slim.utils.convert_collection_to_dict(
end_points_collection)
if global_pool:
net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
end_points['global_pool'] = net
if num_classes:
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout7')
net = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
biases_initializer=tf.zeros_initializer(),
scope='fc8')
if spatial_squeeze:
net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
end_points[sc.name + '/fc8'] = net
return net, end_points
alexnet_v2.default_image_size = 224
alexnet.py(comment)
"""AlexNet version 2.
Described in: http://arxiv.org/pdf/1404.5997v2.pdf
Parameters from:
github.com/akrizhevsky/cuda-convnet2/blob/master/layers/
layers-imagenet-1gpu.cfg
Note: All the fully_connected layers have been transformed to conv2d layers.
To use in classification mode, resize input to 224x224 or set
global_pool=True. To use in fully convolutional mode, set
spatial_squeeze to false.
The LRN layers have been removed and change the initializers from
random_normal_initializer to xavier_initializer.
Args:
inputs: a tensor of size [batch_size, height, width, channels].
num_classes: the number of predicted classes. If 0 or None, the logits layer
is omitted and the input features to the logits layer are returned instead.
is_training: whether or not the model is being trained.
dropout_keep_prob: the probability that activations are kept in the dropout
layers during training.
spatial_squeeze: whether or not should squeeze the spatial dimensions of the
logits. Useful to remove unnecessary dimensions for classification.
scope: Optional scope for the variables.
global_pool: Optional boolean flag. If True, the input to the classification
layer is avgpooled to size 1x1, for any input size. (This is not part
of the original AlexNet.)
Returns:
net: the output of the logits layer (if num_classes is a non-zero integer),
or the non-dropped-out input to the logits layer (if num_classes is 0
or None).
end_points: a dict of tensors with intermediate activations.
"""
-
本来のAlexnetではfully-connected layersが3つ後ろに入るはずだが、デフォルトではconv2dに置き換えられている(多分精度の面?)。spatial_squeeze=Falseとすると、圧縮せずにfully connectedで実装される。中身はtf.squeezeを呼び出しており、networkの中の次元が1しかないlayerを削除するので、(以降調査中)
-
初期化の際のLRN (local response normalization) layerは削除されている(中身の解説によるとReLUの際には特に必要とされないらしい)
-
global_poolでclassificationを行うことができる(TrueにするとブーリアンのFLAGを返す。)
- このオプションは2017年の10/29に初めて追加されたので、古いtensorflowから呼び出すとないことがある。わからない場合は以下のようにすると、今のバージョンのソースコードが見られる。
-
ない場合にはソースコードを今のディレクトリにコピーして
from tensorflow.contrib.slim.python.slim.nets import alexnet->import alexnetと書き換えると、とりあえず動かせる。
import inspect
from tensorflow.contrib.slim.python.slim.nets import alexnet
inspect.getsourcelines(alexnet.alexnet_v2)
OK Alexnet, run!
とりあえず動くコードを
from tensorflow.contrib.slim.python.slim.nets import alexnet
from tensorflow.python.ops import random_ops
from tensorflow.python.ops import math_ops
import tensorflow as tf
sess = tf.InteractiveSession()
num_classes = 50
eval_batch_size = 2
eval_height, eval_width = 300, 400
eval_inputs = random_ops.random_uniform(
(eval_batch_size, eval_height, eval_width, 3))
print(eval_inputs.shape)
logits, _ = alexnet.alexnet_v2(
eval_inputs, is_training=False, spatial_squeeze=True, num_classes=num_classes, global_pool=True)
predictions = math_ops.argmax(logits, 1)
sess.run(tf.global_variables_initializer())
best = sess.run(predictions)
print(best)
出力は下みたいな感じになるはず。
(2, 300, 400, 3) # evaluate setの次元数
[39, 39] # 分類されたクラス番号
同じクラスになるのは、randomだとそうなるのだろうか。
(しかも毎回違う)
これはトレーニングなしにとりあえず評価させる。
トレーニングのための関数など、alexnet.pyのソースコードと同じディレクトリに入っているalexnet_test.pyを見ると動かし方がなんとなくわかる。
slimで果たしていいのか?
- slim自体はgoogleの知見がいろいろ詰まっていそうなのだが、ちゃんといじれるのか、他のものが使えるのか(、kerasの開発に吸収されないか)という不安がある
- 生Tensorflow
- Keras (落ちてたAlexnetのコードがエラーでいろいろ動かなかった悲しみ)
- (参考)[https://qiita.com/rindai87/items/546991f5ecae0ef7cde3}
デバッグ
- TensorBoard使えるようになりたい
- 謎のグラフがでて終わった
- (参考)[https://deepage.net/tensorflow/2017/04/25/tensorboard.html]
他がベースのものを使ってみる
Tensorflow生身finetuning
- こちら
- github
- Caffeベースのモデル(bvlc_alexnet.npy)が必要です
- 学習率が高いせいで止まったが小さくしたらepoch7ぐらいまで動いた
Nan in summary histogram for: fc7/biases_0- /tmp/finetune_alexnet/あたりにチェックポイントでのモデルが保存されているのでloadして予測してみてください
Keras
-
- Xception
- VGG16
- VGG19
- ResNet50
- InceptionV3
- InceptionResNetV2
- MobileNet
他の記事に続く。