参考、引用した記事
こちらの記事は@Brutusさんが2021年05月21日に投稿されたAWSのGPUインスタンス構築 値段を抑えて最短で構築する という記事を参考に2023年3月8日にec2インスタンスを利用し、 1からGPUの環境を構築していきます。
Brutusさんの記事からの引用が多く含まれ、文章構成等も参考にしています。
また、なるべくエラー解決も含めて公式のドキュメントを参考にしています。
初めに
本記事はAWSクラウド(以降、AWS)でGPUインスタンスのg4dn.xlargeを利用して、構築する方法について記載しています。後述しますが、g4dn.xlargeインスタンスの立ち上げには申請が必要です。
またベースはubuntuなのでubuntuosのGPUサーバーの環境構築も同様の方法でできます。
有料のAMIを利用してGPUインスタンスを構築することもできますが、無駄なものが多くなんだか動作がもっさりしていて微妙だったので1から構築して必要最低限のものだけインストールします。
GPUを利用する場合は、前提としてNVIDIAドライバ、CUDA、cuDNN等の知識が必要です。これらについてはBrutusさんが以前書かれたUbuntuでGPUマシーンを構築するを参照してみるといいと思います。
1.今回利用するバージョン
- AMI(OSバージョン Ubuntu22.04)
- nvidia-driver-525
- ec2インスタンス g4dn.xlarge
- CUDAのバージョン 12.0
- cuDNNのバージョン 8.8.1.3
2. ec2インスタンスの立ち上げ
初めに
今回は詳細なec2インスタンスの説明は僕が詳しくないので省きます。(詳細はaws公式のこちらの記事を見てみてください)
様々なインスタンスタイプがある中でg4dnを利用する理由としては、GPU系のインスタンスで最も価格が安いためです。(他にも色々良い点があるのですが、ここでは触れません)
また、今回利用するg4dn.xlargeを使うためには、リソース制限があるため事前にAWSサポートなどから申請する必要があります。
リソース制限の上限を上げる申請
1.まずは、awsにアクセスし、検索バーに「サポート」と打ち、サポートセンターにアクセスします。
2.左のサイドバーから「お客様のサポートケース」を選択
3.ケースの選択をクリック
4.どのようなサポートをご希望ですかと聞かれるので、「サービスの緩和をお求めですか?」という文章をクリックする
5.Create caseのService limit increaseが選択されているのを確認し、limite typeのec2インスタンスを選択
6.リージョンを選択する(どのリージョンがいいとかは断言できないのですが、基本的には日本にいるなら東京でいいと思います)
7.プライマリーインスタンスタイプを選択します。今回はg4dnを使用するので「All G instance」を選択する
8.New limit value を聞かれます。ここで必要なvCPUsの量を選択します。こちらの記事からG4インスタンスについての記事に移動し、必要なvCPUsの数を確認します。
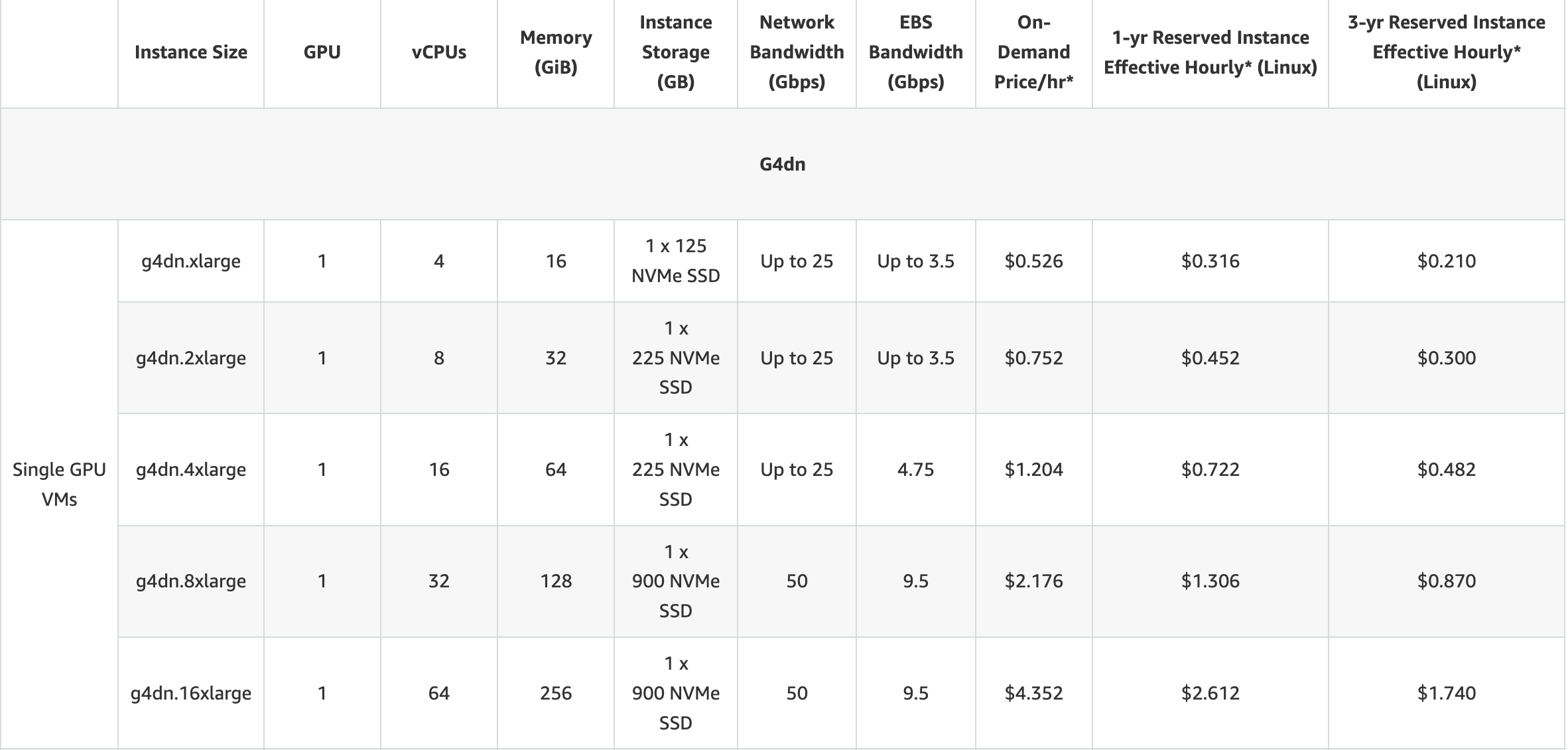
引用 https://aws.amazon.com/ec2/instance-types/g4/
この表のvCPUsを確認します。すると今回導入するg4dn.xlargeに必要なvCPUsは4つだということが分かります。
反映には数時間から遅いと数日かかるので念のため一つ上の「8」と入力しておきます。
9.最後にCase descriptionですが、こちらは基本なんでもいいです。私は、機械翻訳を使って「個人開発でGPUを用いた深層学習をしたい。」とかを英語で書いて申請した気がします。
10.これでsubmitします。このようにお客様のサポートケースを確認してステータスが解決済みになっていれば完了です。

ec2インスタンスの立ち上げ
1.ec2と検索して、ec2ダッシュボードにアクセスする。
2.その中からオレンジ色で囲まれたインスタンスを起動をクリック。
3.名前とタグ
名前を付ける(タグはなくてもいい)
4.アプリケーションおよびosイメージの選択
「Ubuntu Server 22.04 LTS (HVM), SSD Volume Type」を選択
5.インスタンスタイプの選択
今回利用する「g4dn.xlarge」を選択
6.キーペア(ログイン)
ここでは、新しいキーペアの作成をする。
- 新しいキーペアの作成をクリック
- キーペア名をつける
- キーペアタイプがRSA、プライベートファイル形式が.pemになっているのを確認
- キーペアを作成をクリック。
- するとキーペアがダウンロードされる。
- 以下のようにキーペアの権限を変更する
$ mv ~/Downloads/{ダウンロードしたキーペア} ~/.ssh #キーペアを移動
$ chmod 400 ~/.ssh/{ダウンロードしたキーペア} #権限を変更
7.ストレージを設定
後から簡単にストレージを追加できが、念のため「20」に変更しておく。
8.インスタンスを起動を押して、しばらく待つ
ec2インスタンスの起動からssh接続と停止
注意!!
学習や開発が終わったら必ずインスタンスは停止しましょう。インスタンスは停止しない限り、料金が発生し続けてしまいます。
また、インスタンスを作成した直後は勝手にインスタンスが起動した状態になっています。
インスタンスの開始とssh接続
-
ec2インスタンスのページのサイドバーからインスタンスを選択
-
起動したいインスタンスのNameの左にあるチェックボックスをクリックして、上にある「インスタンスの状態」からインスタンスを開始を選択する

こうなってたら成功 -
インスタンスIDの隣のが実行中となったのを確認し、インスタンスIDをクリック
-
そこからパブリック IPv4 DNSをコピーする(ec2-〇〇-〇〇〇-〇〇-〇〇〇.ap-northeast-1.compute.amazonaws.com )ってやつ
-
ターミナルからec2インスタンスにsshで接続
$ ssh -i ~/.ssh/{設定したキーペア} {ユーザー名を適当に入れる。ここではubuntuとする}@{コピーしたパブリック IPv4 DNS}
$ {ユーザー名}@ip-〇〇-〇〇〇-〇〇-〇〇〇: #こうなったら成功
*余談
vscodeを使うともっと簡単かつ楽にssh接続できます。(参考)
インスタンスの停止、終了
- ec2インスタンスのページのサイドバーからインスタンスを選択
- 起動したいインスタンスのNameの左にあるチェックボックスをクリックして、上にある「インスタンスの状態」からインスタンスを停止を選択する
- 完全にこのインスタンスを削除したい場合を終了を選択
3. GPU環境構築
sshで接続した後、はじめにubuntu-drivers-commonパッケージをインストールします。
# apt-get update
# sudo apt install -y ubuntu-drivers-common
NNvidiaドライバ
*AWSのGPUインスタンス構築 値段を抑えて最短で構築するから引用。
以下のコマンドを実行し、GPUが認識されていることを確認します。(vscodeからssh接続している場合はコマンドの先頭にsudoが必要)
実行結果より、NVIDIA TeslaのGPUが認識されているのが確認できます。
補足としてOSのバージョンの違いにより出力のされ方が変わります。
Ubuntu18.04の場合、1eb8と出力されていますが、この文字列はDevice PCI IDになり、Tesla T4を指します。文字列の詳細についてはAppendix A. Supported NVIDIA GPU Productsより確認できます。
$ lspci | grep -i nvidia
00:1e.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)
以下のコマンドを実行し、NVIDIAグラフィックカードのモデルと推奨ドライバーを検出します。
実行結果より、nvidia-driver-525が推奨されました。
$ ubuntu-drivers devices
== /sys/devices/pci0000:00/0000:00:1e.0 ==
modalias : pci:v000010DEd00001EB8sv000010DEsd000012A2bc03sc02i00
vendor : NVIDIA Corporation
model : TU104GL [Tesla T4]
driver : nvidia-driver-515 - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-418-server - distro non-free
driver : nvidia-driver-515-server - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-510 - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : nvidia-driver-525-server - distro non-free
driver : nvidia-driver-525 - distro non-free recommended
driver : xserver-xorg-video-nouveau - distro free builtin
以下のコマンドを実行しNVIDIAドライバを検索します。
$ apt-cache search nvidia-driver-525
nvidia-driver-520 - Transitional package for nvidia-driver-525
nvidia-driver-520-open - Transitional package for nvidia-driver-525
nvidia-driver-525 - NVIDIA driver metapackage
nvidia-driver-525-open - NVIDIA driver (open kernel) metapackage
nvidia-driver-525-server - NVIDIA Server Driver metapackage
nvidia-headless-525 - NVIDIA headless metapackage
nvidia-headless-525-open - NVIDIA headless metapackage (open kernel module)
nvidia-headless-525-server - NVIDIA headless metapackage
nvidia-headless-no-dkms-525 - NVIDIA headless metapackage - no DKMS
nvidia-headless-no-dkms-525-open - NVIDIA headless metapackage - no DKMS (open kernel module)
nvidia-headless-no-dkms-525-server - NVIDIA headless metapackage - no DKMS
xserver-xorg-video-nvidia-525 - NVIDIA binary Xorg driver
xserver-xorg-video-nvidia-525-server - NVIDIA binary Xorg driver
以下のコマンドを実行し、NVIDIAドライバのインストールします。
$ apt-get install nvidia-driver-525
(エラーが発生したらapt-get updateをしてみてください)
以下のコマンドを実行し、NVIDIAのパッケージを確認します。
$ dpkg -l | grep nvidia
インストール後、OSを再起動します。
$ systemctl reboot
OS再起動後、以下のコマンドを実行し、NVIDIAのドライバがロードされていることを確認します。
dmesg | grep -i nvidia
[ 4.882878] nvidia: loading out-of-tree module taints kernel.
[ 4.882891] nvidia: module license 'NVIDIA' taints kernel.
[ 4.913317] nvidia: module verification failed: signature and/or required key missing - tainting kernel
[ 4.932009] nvidia-nvlink: Nvlink Core is being initialized, major device number 234
[ 4.982258] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 525.85.05 Sat Jan 14 00:49:50 UTC 2023
[ 5.008086] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 525.85.05 Sat Jan 14 00:40:03 UTC 2023
[ 5.012433] [drm] [nvidia-drm] [GPU ID 0x0000001e] Loading driver
[ 5.206860] audit: type=1400 audit(1678777914.588:3): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe" pid=438 comm="apparmor_parser"
[ 5.206866] audit: type=1400 audit(1678777914.588:4): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe//kmod" pid=438 comm="apparmor_parser"
[ 7.068742] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:00:1e.0 on minor 0
[ 7.104057] nvidia_uvm: module uses symbols from proprietary module nvidia, inheriting taint.
[ 7.108069] nvidia-uvm: Loaded the UVM driver, major device number 510.
以下のコマンドを実行し、NVIDIAのドライバが確認できます。
$ nvidia-smi
Tue Mar 14 07:13:23 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:1E.0 Off | 0 |
| N/A 49C P8 17W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
dockerのインストール
ここまで説明すると長くなってしまうのでこちらのリンクを参考にやってみてください
https://zenn.dev/msksgm/articles/20211119-ec2-install-docker-compose
nvidia-dockerのインストール
この図のようにnvidia driverの上にnvidia-dockerを入れて、コンテナ内でcuda,cuDNNを導入していきます。
dockerの説明は次の章でします。

引用 https://github.com/NVIDIA/nvidia-docker
wslをご利用の方は、systemctlコマンドを有効にしておきます。それ以外の方は飛ばしてください
1.WSLで「/etc/wsl.conf」というファイルを作成する。
2.以下の内容を記載し保存
[boot]
systemd=true
3.WSLを再起動
powershellで以下のコマンドを実行
wsl --shutdown
4.systemdがPID 1で起動していることを確認
ps -ae
PID TTY TIME CMD
1 ? 00:00:00 systemd
2 ? 00:00:00 init
こちらのnvidia-dockerの項目からインストールする
$ sudo apt-get -y install docker
$ curl https://get.docker.com | sh \
&& sudo systemctl --now enable docker
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt-get update
$ sudo apt-get install -y nvidia-container-toolkit
$ sudo nvidia-ctk runtime configure --runtime=docker
$ sudo systemctl restart docker
最後にnvidia-docker上でcudaとcudnnが認識できているか確認します。今回はubuntu22.04のベースイメージを使います。
$ sudo docker run --rm --gpus all nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04 nvidia-smi
アンインストール
削除する場合はこれを実行
$ sudo apt-get --purge remove nvidia*
$ sudo apt-get --purge remove cuda*
$ sudo apt-get --purge remove cudnn*
$ sudo apt-get --purge remove libnvidia*
$ sudo apt-get --purge remove libcuda*
$ sudo apt-get --purge remove libcudnn*
$ sudo apt-get autoremove
$ sudo apt-get autoclean
$ sudo apt-get update
$ sudo rm -rf /usr/local/cuda*
引用 https://qiita.com/harmegiddo/items/86b295ccf96eff489e02
dockerイメージとdocker-compose.ymlの作成
次に、dockerイメージとdocker-compose.ymlを用意します。
また今回は、pythonの依存関係管理とパッケージングのためのツールpoetryを導入します。
詳細な説明は、公式ドキュメント等を見てください。
軽くdockerの説明
簡単に説明すると以下の図のようにDockerfileを元にイメージを作成して、それを元にコンテナを作成してその中にosやパッケージ、ライブラリを入れて仮想環境を作っていくというような感じです。
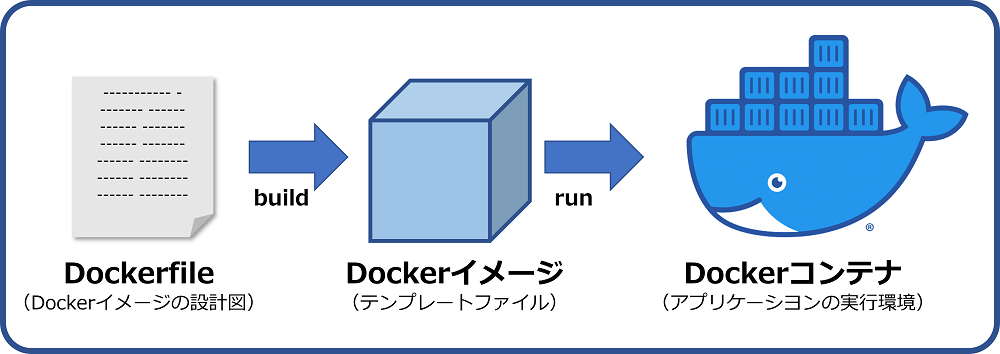
引用 https://www.kagoya.jp/howto/cloud/container/dockerimage/
また、この図の矢印の下にある「build,run」というのがdockerコマンドと呼ばれるものです。(Dockerfileからイメージの作成はbuild,イメージからコンテナの作成はrun)
これらのコマンドを記したものがdocker-compose.ymlファイルです。
最後に
pyenvでnvidiaが出しているこちらのベースイメージからPython環境をつくるDockerfileとdocker-compose.ymlの例をお見せします。
この2つは同じディレクトリに入れて、その直下で実行してください。
作成したコンテナにこのディレクトリは同期しているのでここにデータなど必要なファイルを入れて開発ができます!
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
ARG work_dir="/workspace"
# ENV PYTHON_VERSION 3.10.9
# ENV HOME /root
# ENV PYTHON_ROOT $HOME/local/python-$PYTHON_VERSION
# ENV PATH $PYTHON_ROOT/bin:$PATH
# ENV PYENV_ROOT $HOME/.pyenv
#gitのインストール
RUN apt-get update -y && apt-get install -y build-essential vim \
wget curl git zip gcc make openssl \
libssl-dev libbz2-dev libreadline-dev \
libsqlite3-dev python3-tk tk-dev python-tk \
libfreetype6-dev libffi-dev liblzma-dev
# Install nodejs for JupyterLab extension
RUN curl -sL https://deb.nodesource.com/setup_current.x | bash - && \
apt-get install -y --no-install-recommends nodejs && \
rm -rf /var/lib/apt/lists/*
RUN git clone https://github.com/pyenv/pyenv.git /root/.pyenv
ENV HOME /root
ENV PYENV_ROOT $HOME/.pyenv
ENV PATH $PYENV_ROOT/shims:$PYENV_ROOT/bin:$PATH
RUN pyenv --version
RUN pyenv install 3.10.9
RUN pyenv global 3.10.9
RUN python --version
RUN pyenv rehash && pip install --upgrade pip
# 必要に応じて、JupyterLabの拡張機能などを追加してください
RUN python3 -m pip install --upgrade pip
# pytorchの導入
RUN pip install lit
RUN python -m pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
version: '3.2'
services:
app:
build: .
# dockerfile: Dockerfile
container_name: app #任意のコンテナ名
# devices:
# - /dev/nvidia0
working_dir: '/workspace'
volumes:
- ./:/workspace/
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
ports:
- "127.0.0.1:8080:8888"
tty: true
起動方法
コンテナの作成&起動
docker-compose up -d app
コンテナの中にターミナルからアクセス
docker-compose exec app -it /bin/bash
この後はpipを使って色々ライブラリを入れて使ってください。
ちなみにjyupterlabのインストールから起動は
pip install jupyterlab
jupyter lab --allow-root --no-browser --NotebookApp.token='' --port 8888 --ip=0.0.0.0
このコマンドを打ったのちにlocalhost:8080にアクセスしてください。
おわりに
@Brutusさんが2021年05月21日に投稿されたAWSのGPUインスタンス構築 値段を抑えて最短で構築するという記事がとても分かりやすいのですが、最新バージョンに対応した記事がなかったので書いてみました。
まとめるのは結構面倒でしたが、毎度インスタンスタイプを変えるたびに調べながらやるのは骨が折れるので一回まとめてしまえばあとはコピペするだけなので時間をかけてよかったかなと思います。
次回は、dockerを使ってbertの学習環境をpytorchを使って構築していきます。
最後に、この記事を書くにあたって引用の許可をくださった@Brutusさんに感謝します。