目次
1.初めに
2.対象となる人
3.使用した環境・技術
4.手順
5.完成したもの
6.最後に
1.初めに
2021年4月末よりaidemyで、Python(主として自然言語処理)の勉強を開始。
気がつくと半年近くとなり私のAidemy生活も残すところ僅かとなりました。
基礎学習さまざまな学習を行い、当初の目的であった業務に転用可能なプログラムを教えていただいたりと充実した日々を々を送ることができました。ブログねたとして、授業内容の再確認を兼ねて、ジャ〇〇ズぽい会話をしていくシステムづくりに挑戦した内容を書いていきます。
2.対象となる人
・会話システムに興味のある方
・自然言語処理に興味のある方
・前回との成長を比較したい人
3.使用した環境・技術
☆環境
Windows10
Visual Studio Code
python3.8.11(anaconda3)
☆技術
Sequence to Sequence Model:
mecab:形態素解析に使用します
Chainer:
フレームワークのひとつ
↓詳しくはこちらで解説されています
[Chainer チュートリアル]
(https://tutorials.chainer.org/ja/tutorial.html)
BiLSTM:
2つの入力させる向きを組み合わせた双方向再帰ニューラルネットです。
ミニバッチ学習:
機械学習のパラメータ更新方法のひとつ
学習に用いるデータ全てで勾配を計算した後にモデルのパラメータを更新する
バッチ学習と学習データ1つごとにモデルのパラメータを更新するオンライン学習
の中間的手法となります。
1万件のデータがあった場合、例えば、その1万件のデータからランダムに100件
(ミニバッチ)、選び、その損失関数の平均を求め学習させ、学習が終わったら、
また100件ランダムに選び学習、といったのを繰り返していくといった手法です。
Attention :
Attentionは、入力データのどの部分に注意を向けるのかを指示します
↓こちらの記事でわかりやすく解説されています
[【深層学習】Attention機構とは何のか?]
(https://dendenblog.xyz/what-is-attention/)
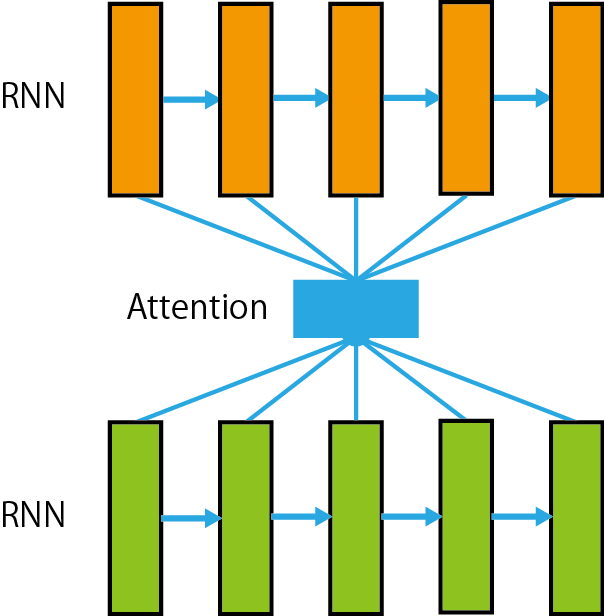
モデルの全体図や手順はAidemy教材にわかりやすくまとめられていましたのでそれを引用させていただきます。
モデルの全体像は図。(図は1方向となっていますが、双方向の場合でも使用できます。)
まずQuestionとAnswerを別々にBiLSTMに入力します。
次にQuestionからAnswerに対してAttentionをし、Questionを考慮したAnswerの情報を得ることができます。
その後にQuestionの各時刻の隠れ状態ベクトルの平均をとって(mean pooling)ベクトルqを得ます。
一方でQuestionからAttentionを施した後、Answerの各時刻の隠れ状態ベクトルの平均をとってベクトル$a$を得ます。
最後にこの2つのベクトルを$[q;a;|q-a|;qa]$のように$q$, $a$, $|q-a|$, $qa$ベクトルを結合して、順伝播ニューラルネット、Softmax関数を経て2つのユニットからなる出力になります。
この結合の仕方はFacebook researchが発表した
InferSentという有名な手法を参考にしています。
このモデルの出力層はユニットが2つありますが、正解の回答文については[1,0]を、不正解の回答文については[0,1]を予測するように学習していきます。
図2.3.1-1 モデルの全体像
4.手順
①必要なものをインポートしていきます。
# -*- coding: utf-8 -*-
import datetime
import numpy as np
import chainer
import chainer.functions as F
import chainer.links as L
import MeCab
②問と答えの組み合わせを用意します。最初の[]が問で後[]がその答えとなるようにデータを準備します。本来は何千、何万というものを用意し、きちんと学習させていくのですが、、今回は流れを理解することに重点を置いていますので少しだけの教師データとなっています。
# 教師データ
data = [
[["初めまして。"], ["初めまして。camiよろしくね。"]],
[["どこから来たんですか?"], ["日本から来ました。"]],
[["日本のどこに住んでるんですか?"], ["東京に住んでいます。"]],
[["仕事は何してますか?"], ["夢を売る仕事です。"]],
[["お会いできて嬉しかったです。"], ["YOU誰?"]],
[["おはよう。"], ["おはようございます。"]],
[["こんにちわ"], ["おはようございます。"]],
[["こんばんわ"], ["おはようございます。"]],
[["いつも何時に起きますか?"], ["入りの2時間前置きます。"]],
[["朝食は何を食べますか?"], ["たいていトーストと卵を食べます。"]],
[["朝食は毎日食べますか?"], ["たまに朝食を抜くことがあります。"]],
[["野菜をたくさん取っていますか?"], ["毎日野菜を取るようにしています"]],
[["週末は何をしていますか?"], ["メンバーと会っていることが多いです。"]],
[["どこに行くのが好き?"], ["私たちは帝劇に行くのが好きです。"]],
[["挑戦した方がいいかな?"], ["YOUやっちゃいなよ"]],
[["ありがとう"], ["セクシィーサンキュー"]]
]
③最初にGPUが入っている環境であればGPUを使うように設定します。
# GPUが入っている場合は、0以上に設定する。GPUがあると学習時間が早くなります
# ない場合はCPUを使って学習されます
gpu = -1
if gpu >= 0: # numpyかcuda.cupyか
xp = chainer.cuda.cupy
chainer.cuda.get_device(gpu).use()
else:
xp = np
④まずは、データ変換の定義を行っていきます。
# データ変換クラスの定義
class DataConverter:
def __init__(self, batch_col_size):
"""クラスの初期化
Args:
batch_col_size: 学習時のミニバッチ単語数サイズ
"""
self.mecab = MeCab.Tagger(r'-Owakati -d "C:\mecab-ipadic-neologd"') # 形態素解析器
self.vocab = {"<eos>":0, "<unknown>": 1} # 単語辞書
self.batch_col_size = batch_col_size
def load(self, data):
"""学習時に、教師データを読み込んでミニバッチサイズに対応したNumpy配列に変換する
Args:
data: 対話データ
"""
# 単語辞書の登録
self.vocab = {"<eos>":0, "<unknown>": 1} # 単語辞書を初期化
for d in data:
sentences = [d[0][0], d[1][0]] # 入力文、返答文
for sentence in sentences:
sentence_words = self.sentence2words(sentence) # 文章を単語に分解する
for word in sentence_words:
if word not in self.vocab:
self.vocab[word] = len(self.vocab)
# 教師データのID化と整理
queries, responses = [], []
for d in data:
query, response = d[0][0], d[1][0] # エンコード文、デコード文
queries.append(self.sentence2ids(sentence=query, train=True, sentence_type="query"))
responses.append(self.sentence2ids(sentence=response, train=True, sentence_type="response"))
self.train_queries = xp.vstack(queries)
self.train_responses = xp.vstack(responses)
def sentence2words(self, sentence):
"""文章を単語の配列にして返却する
Args:
sentence: 文章文字列
"""
sentence_words = []
for m in self.mecab.parse(sentence).split("\n"): # 形態素解析で単語に分解する
w = m.split("\t")[0].lower() # 単語
if len(w) == 0 or w == "eos": # 不正文字、EOSは省略
continue
sentence_words.append(w)
sentence_words.append("<eos>") # 最後にvocabに登録している<eos>を代入する
return sentence_words
def sentence2ids(self, sentence, train=True, sentence_type="query"):
"""文章を単語IDのNumpy配列に変換して返却する
Args:
sentence: 文章文字列
train: 学習用かどうか
sentence_type: 学習用でミニバッチ対応のためのサイズ補填方向をクエリー・レスポンスで変更するため"query"or"response"を指定
Returns:
ids: 単語IDのNumpy配列
"""
ids = [] # 単語IDに変換して格納する配列
sentence_words = self.sentence2words(sentence) # 文章を単語に分解する
for word in sentence_words:
if word in self.vocab: # 単語辞書に存在する単語ならば、IDに変換する
ids.append(self.vocab[word])
else: # 単語辞書に存在しない単語ならば、<unknown>に変換する
ids.append(self.vocab["<unknown>"])
# 学習時は、ミニバッチ対応のため、単語数サイズを調整してNumpy変換する
if train:
if sentence_type == "query": # クエリーの場合は前方にミニバッチ単語数サイズになるまで-1を補填する
while len(ids) > self.batch_col_size: # ミニバッチ単語サイズよりも大きければ、ミニバッチ単語サイズになるまで先頭から削る
ids.pop(0)
ids = xp.array([-1]*(self.batch_col_size-len(ids))+ids, dtype="int32")
elif sentence_type == "response": # レスポンスの場合は後方にミニバッチ単語数サイズになるまで-1を補填する
while len(ids) > self.batch_col_size: # ミニバッチ単語サイズよりも大きければ、ミニバッチ単語サイズになるまで末尾から削る
ids.pop()
ids = xp.array(ids+[-1]*(self.batch_col_size-len(ids)), dtype="int32")
else: # 予測時は、そのままNumpy変換する
ids = xp.array([ids], dtype="int32")
return ids
def ids2words(self, ids):
"""予測時に、単語IDのNumpy配列を単語に変換して返却する
Args:
ids: 単語IDのNumpy配列
Returns:
words: 単語の配列
"""
words = [] # 単語を格納する配列
for i in ids: # 順番に単語IDを単語辞書から参照して単語に変換する
words.append(list(self.vocab.keys())[list(self.vocab.values()).index(i)])
return words
⓹実際に学習するためのモデルを作成していきます
# モデルクラスの定義
# LSTMエンコーダークラス
class LSTMEncoder(chainer.Chain):
def __init__(self, vocab_size, embed_size, hidden_size):
"""Encoderのインスタンス化
Args:
vocab_size: 使われる単語の種類数
embed_size: 単語をベクトル表現した際のサイズ
hidden_size: 隠れ層のサイズ
"""
super(LSTMEncoder, self).__init__(
xe = L.EmbedID(vocab_size, embed_size, ignore_label=-1),
eh = L.Linear(embed_size, 4 * hidden_size),
hh = L.Linear(hidden_size, 4 * hidden_size)
)
def __call__(self, x, c, h):
"""Encoderの計算
Args:
x: one-hotな単語
c: 内部メモリ
h: 隠れ層
Returns:
次の内部メモリ、次の隠れ層
"""
e = F.tanh(self.xe(x))
return F.lstm(c, self.eh(e) + self.hh(h))
# Attention Model + LSTMデコーダークラス
class AttLSTMDecoder(chainer.Chain):
def __init__(self, vocab_size, embed_size, hidden_size):
"""Attention ModelのためのDecoderのインスタンス化
Args:
vocab_size: 語彙数
embed_size: 単語ベクトルのサイズ
hidden_size: 隠れ層のサイズ
"""
super(AttLSTMDecoder, self).__init__(
ye = L.EmbedID(vocab_size, embed_size, ignore_label=-1), # 単語を単語ベクトルに変換する層
eh = L.Linear(embed_size, 4 * hidden_size), # 単語ベクトルを隠れ層の4倍のサイズのベクトルに変換する層
hh = L.Linear(hidden_size, 4 * hidden_size), # Decoderの中間ベクトルを隠れ層の4倍のサイズのベクトルに変換する層
fh = L.Linear(hidden_size, 4 * hidden_size), # 順向きEncoderの中間ベクトルの加重平均を隠れ層の4倍のサイズのベクトルに変換する層
bh = L.Linear(hidden_size, 4 * hidden_size), # 順向きEncoderの中間ベクトルの加重平均を隠れ層の4倍のサイズのベクトルに変換する層
he = L.Linear(hidden_size, embed_size), # 隠れ層サイズのベクトルを単語ベクトルのサイズに変換する層
ey = L.Linear(embed_size, vocab_size) # 単語ベクトルを語彙数サイズのベクトルに変換する層
)
def __call__(self, y, c, h, f, b):
"""Decoderの計算
Args:
y: Decoderに入力する単語
c: 内部メモリ
h: Decoderの中間ベクトル
f: Attention Modelで計算された順向きEncoderの加重平均
b: Attention Modelで計算された逆向きEncoderの加重平均
Returns:
語彙数サイズのベクトル、更新された内部メモリ、更新された中間ベクトル
"""
e = F.tanh(self.ye(y)) # 単語を単語ベクトルに変換
c, h = F.lstm(c, self.eh(e) + self.hh(h) + self.fh(f) + self.bh(b)) # 単語ベクトル、Decoderの中間ベクトル、順向きEncoderのAttention、逆向きEncoderのAttentionを使ってLSTM
t = self.ey(F.tanh(self.he(h))) # LSTMから出力された中間ベクトルを語彙数サイズのベクトルに変換する
return t, c, h
# Attentionモデルクラス
class Attention(chainer.Chain):
def __init__(self, hidden_size):
"""Attentionのインスタンス化
Args:
hidden_size: 隠れ層のサイズ
"""
super(Attention, self).__init__(
fh = L.Linear(hidden_size, hidden_size), # 順向きのEncoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
bh = L.Linear(hidden_size, hidden_size), # 逆向きのEncoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
hh = L.Linear(hidden_size, hidden_size), # Decoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
hw = L.Linear(hidden_size, 1), # 隠れ層サイズのベクトルをスカラーに変換するための線形結合層
)
self.hidden_size = hidden_size # 隠れ層のサイズを記憶
def __call__(self, fs, bs, h):
"""Attentionの計算
Args:
fs: 順向きのEncoderの中間ベクトルが記録されたリスト
bs: 逆向きのEncoderの中間ベクトルが記録されたリスト
h: Decoderで出力された中間ベクトル
Returns:
順向きのEncoderの中間ベクトルの加重平均、逆向きのEncoderの中間ベクトルの加重平均
"""
batch_size = h.data.shape[0] # ミニバッチのサイズを記憶
ws = [] # ウェイトを記録するためのリストの初期化
sum_w = chainer.Variable(xp.zeros((batch_size, 1), dtype='float32')) # ウェイトの合計値を計算するための値を初期化
# Encoderの中間ベクトルとDecoderの中間ベクトルを使ってウェイトの計算
for f, b in zip(fs, bs):
w = F.tanh(self.fh(f)+self.bh(b)+self.hh(h)) # 順向きEncoderの中間ベクトル、逆向きEncoderの中間ベクトル、Decoderの中間ベクトルを使ってウェイトの計算
w = F.exp(self.hw(w)) # softmax関数を使って正規化する
ws.append(w) # 計算したウェイトを記録
sum_w += w
# 出力する加重平均ベクトルの初期化
att_f = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
att_b = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
for f, b, w in zip(fs, bs, ws):
w /= sum_w # ウェイトの和が1になるように正規化
# ウェイト * Encoderの中間ベクトルを出力するベクトルに足していく
att_f += F.reshape(F.batch_matmul(f, w), (batch_size, self.hidden_size))
att_b += F.reshape(F.batch_matmul(b, w), (batch_size, self.hidden_size))
return att_f, att_b
# Attention Sequence to Sequence Modelクラス
class AttSeq2Seq(chainer.Chain):
def __init__(self, vocab_size, embed_size, hidden_size, batch_col_size):
"""Attention + Seq2Seqのインスタンス化
Args:
vocab_size: 語彙数のサイズ
embed_size: 単語ベクトルのサイズ
hidden_size: 隠れ層のサイズ
"""
super(AttSeq2Seq, self).__init__(
f_encoder = LSTMEncoder(vocab_size, embed_size, hidden_size), # 順向きのEncoder
b_encoder = LSTMEncoder(vocab_size, embed_size, hidden_size), # 逆向きのEncoder
attention = Attention(hidden_size), # Attention Model
decoder = AttLSTMDecoder(vocab_size, embed_size, hidden_size) # Decoder
)
self.vocab_size = vocab_size
self.embed_size = embed_size
self.hidden_size = hidden_size
self.decode_max_size = batch_col_size # デコードはEOSが出力されれば終了する、出力されない場合の最大出力語彙数
# 順向きのEncoderの中間ベクトル、逆向きのEncoderの中間ベクトルを保存するためのリストを初期化
self.fs = []
self.bs = []
def encode(self, words, batch_size):
"""Encoderの計算
Args:
words: 入力で使用する単語記録されたリスト
batch_size: ミニバッチのサイズ
"""
c = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
h = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
# 順向きのEncoderの計算
for w in words:
c, h = self.f_encoder(w, c, h)
self.fs.append(h) # 計算された中間ベクトルを記録
# 内部メモリ、中間ベクトルの初期化
c = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
h = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
# 逆向きのEncoderの計算
for w in reversed(words):
c, h = self.b_encoder(w, c, h)
self.bs.insert(0, h) # 計算された中間ベクトルを記録
# 内部メモリ、中間ベクトルの初期化
self.c = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
self.h = chainer.Variable(xp.zeros((batch_size, self.hidden_size), dtype='float32'))
def decode(self, w):
"""Decoderの計算
Args:
w: Decoderで入力する単語
Returns:
予測単語
"""
att_f, att_b = self.attention(self.fs, self.bs, self.h)
t, self.c, self.h = self.decoder(w, self.c, self.h, att_f, att_b)
return t
def reset(self):
"""インスタンス変数を初期化する
"""
# Encoderの中間ベクトルを記録するリストの初期化
self.fs = []
self.bs = []
# 勾配の初期化
self.zerograds()
def __call__(self, enc_words, dec_words=None, train=True):
"""順伝播の計算を行う関数
Args:
enc_words: 発話文の単語を記録したリスト
dec_words: 応答文の単語を記録したリスト
train: 学習か予測か
Returns:
計算した損失の合計 or 予測したデコード文字列
"""
enc_words = enc_words.T
if train:
dec_words = dec_words.T
batch_size = len(enc_words[0]) # バッチサイズを記録
self.reset() # model内に保存されている勾配をリセット
enc_words = [chainer.Variable(xp.array(row, dtype='int32')) for row in enc_words] # 発話リスト内の単語をVariable型に変更
self.encode(enc_words, batch_size) # エンコードの計算
t = chainer.Variable(xp.array([0 for _ in range(batch_size)], dtype='int32')) # <eos>をデコーダーに読み込ませる
loss = chainer.Variable(xp.zeros((), dtype='float32')) # 損失の初期化
ys = [] # デコーダーが生成する単語を記録するリスト
# デコーダーの計算
if train: # 学習の場合は損失を計算する
for w in dec_words:
y = self.decode(t) # 1単語ずつをデコードする
t = chainer.Variable(xp.array(w, dtype='int32')) # 正解単語をVariable型に変換
loss += F.softmax_cross_entropy(y, t) # 正解単語と予測単語を照らし合わせて損失を計算
return loss
else: # 予測の場合はデコード文字列を生成する
for i in range(self.decode_max_size):
y = self.decode(t)
y = xp.argmax(y.data) # 確率で出力されたままなので、確率が高い予測単語を取得する
ys.append(y)
t = chainer.Variable(xp.array([y], dtype='int32'))
if y == 0: # EOSを出力したならばデコードを終了する
break
return ys
⓹作成したモデルに教師データを読込学習させていきます
# 学習
# 定数
embed_size = 100
hidden_size = 100
batch_size = 6 # ミニバッチ学習のバッチサイズ数
batch_col_size = 15
epoch_num = 50 # エポック数
N = len(data) # 教師データの数
# 教師データの読み込み
data_converter = DataConverter(batch_col_size=batch_col_size) # データコンバーター
data_converter.load(data) # 教師データ読み込み
vocab_size = len(data_converter.vocab) # 単語数
# モデルの宣言
model = AttSeq2Seq(vocab_size=vocab_size, embed_size=embed_size, hidden_size=hidden_size, batch_col_size=batch_col_size)
opt = chainer.optimizers.Adam()
opt.setup(model)
opt.add_hook(chainer.optimizer.GradientClipping(5))
if gpu >= 0:
model.to_gpu(gpu)
model.reset()
# 学習
st = datetime.datetime.now()
for epoch in range(epoch_num):
# ミニバッチ学習
perm = np.random.permutation(N) # ランダムな整数列リストを取得
total_loss = 0
for i in range(0, N, batch_size):
enc_words = data_converter.train_queries[perm[i:i+batch_size]]
dec_words = data_converter.train_responses[perm[i:i+batch_size]]
model.reset()
loss = model(enc_words=enc_words, dec_words=dec_words, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
opt.update()
if (epoch+1)%10 == 0:
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st))
st = datetime.datetime.now()
def predict(model, query):
enc_query = data_converter.sentence2ids(query, train=False)
dec_response = model(enc_words=enc_query, train=False)
response = data_converter.ids2words(dec_response)
print(query, "=>", response)
5.完成したもの
eos は end of sentence で文末を意味しています
会話モデルの結果、
初めまして。 => ['初め まして 。 cami よろしく ね 。 ', '<eos>']
どこから来たんですか? => ['日本 から 来 まし た 。 ', '<eos>']
日本のどこに住んでるんですか? => ['you 東京 に 住ん で い ます 。 ', '<eos>']
仕事は何してますか? => ['夢 を 売る 仕事 です 。 ', '<eos>']
おはよう。 => ['おはよう ござい ます 。 ', '<eos>']
こんにちわ => ['おはよう ござい ます 。 ', '<eos>']
こんばんわ => ['おはよう ござい ます 。 ', '<eos>']
いつも何時に起きますか? => ['6時 に 起き ます 。 ', '<eos>']
朝食は何を食べますか? => ['たいてい トースト と 卵 を 食べ ます 。 ', '<eos>']
朝食は毎日食べますか? => ['たまに 朝食 を 抜く こと が あり ます 。 ', '<eos>']
野菜をたくさん取っていますか? => ['毎日 野菜 を 取る よう に し て い ます ', '<eos>']
週末は何をしていますか? => ['メンバー と 会っ て いる こと が 多い です 。 ', '<eos>']
どこに行くのが好き? => ['私たち は 帝劇 に 行く の が 好き です 。 ', '<eos>']
挑戦した方がいいかな? => ['you やっ ちゃ い な よ ', '<eos>']
お会いできて嬉しかったです。 => ['you 誰 ? ', '<eos>']
6.最後に
この記事を書くにあたり以下の記事を参考とさせていただきました。
↓こちらの記事でやってみたいことが見えてきました
機械学習でツイートが炎上するか予測してみた
↓こちらの記事を参考にしながら少しアレンジし作成していきました
[戦略コンサルで働くデータサイエンティストのブログ]
(https://ie110704.net/2017/08/21/attention-seq2seq%E3%81%A7%E5%AF%BE%E8%A9%B1%E3%83%A2%E3%83%87%E3%83%AB%E3%82%92%E5%AE%9F%E8%A3%85%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F/)
記事を書いて下さった皆様ありがとうございます。またAidemyの先生方にもたくさんお力を貸していただきありがとうございます。
最後は、ジャニさんが出てきて、お決まりの?「YOU誰?」で終わってみました。
この事務所を作ってくださったジャニさんには感謝です。
今回は、教師データにした数が少なかったので、教師データのままでしたが、教師データに様々な会話パターンを入れていくと、より〇〇っぽい会話ができるようになると思います。
これをアプリなどに展開できれば面白くなっていくのではないか?と思います。
。。。いや思うだけでなく、これからそれを多分挑戦してみるぞ!!
しらんけど