はじめに
現在、LightGBMやXGBoostをはじめとした勾配ブースティング木はその精度の高さと使い勝手の良さから構造化データを扱う際には欠かせないものとなっています。私もコンペなどで構造化データを使う際によく使うのですが、その際にいつも「このパラメータってなんの値だっけ?....」となります。主な原因は以下の点だと考えています。
- 勾配ブースティングの理論的背景が難しく、パラメータを深く理解できていない
- ライブラリや手法によって名前や値の意味が微妙に異なり、曖昧になる
- 設定できるハイパーパラメータの数が多い
- そこまで意味を知らずに適当にパラメータをいじってもそれなりに精度が出てしまう
そこで、本記事では勾配ブースティングの中でもよく使われるXGBoostとLightGBMについて、それぞれで使われるハイパーパラメータをできる限り図解で示します。この記事を読み終えた後には、パラメータの意味を自信を持って説明できるようになることを目指しています。
ハイパーパラメータは、ライブラリのバージョンによって名称が変更されたり、削除されたりする場合があります。本記事では、2026年4月時点の公式ドキュメントをもとに解説しています。
将来のバージョンでは、本記事で紹介しているハイパーパラメータが使用できなくなる可能性がある点にご注意ください。
本記事の対象範囲
本記事では、LightGBMとXGBoostのハイパーパラメータを以下の3つの観点で整理し、
解説します。
- まず押さえたいパラメータ
- よく使うパラメータ
- 知っておくと良いパラメータ
一方で、勾配ブースティングの理論的な説明や学習スクリプトの書き方については扱いません。Pythonの基本的な文法を理解しており、LightGBMまたはXGBoostを使ったことのある方を想定読者としています。
LightGBMとXGBoostの概要
勾配ブースティングとは?
LightGBMとXGBoostはどちらも勾配ブースティングの一種です。ブースティングとは図1にあるように、前の決定木の誤りを修正する木を逐次的に追加していく手法です。追加される木は、前のモデルの誤りを直接修正するように学習します。特に二乗誤差の場合は、正解値と予測値の差である残差を近似する木を追加していく、と理解できます。
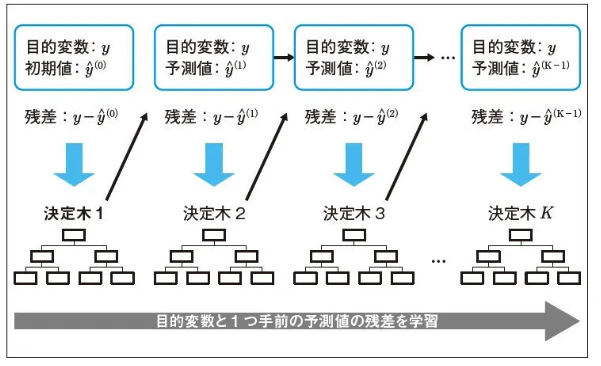
図1:ブースティングの概要図 <出典:ブースティングとバギングの違いを知ろう>
ブースティングと似た手法にバギングがあります。バギングでは、木を逐次的に追加するのではなく、図2にあるように、複数の木を独立して学習し、最終的にそれらの出力を多数決などでまとめて予測します。
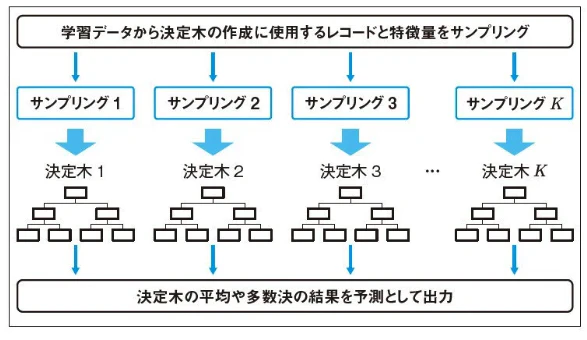
図2:バギングの概要図 <出典:ブースティングとバギングの違いを知ろう>
続いて、勾配という名前がつく理由は、各ステップで損失関数を小さくする方向、すなわち負の勾配方向に予測値を更新していくためです。二乗誤差の場合、この負の勾配は直感的には残差に対応します。
以上より、勾配ブースティングは「損失の負の勾配方向に沿って、逐次的に木を追加していく手法」であり、これが名前の由来となっています。詳細な理論や決定木の作成方法については以下の記事が参考になるので、興味のある方はあわせてご覧ください。
XGBoost
XGBoost以前の勾配ブースティングには、過学習しやすい・学習が遅い・大規模データに弱いという問題がありました。
2016年に提案されたXGBoostは、これらを3つの工夫で解決しました。
- 過学習の抑制:ペナルティ項を損失関数に組み込み、モデルが複雑になりすぎないよう数学的に制御
- 分割精度の向上:木の構築に使う情報量を増やし、より質の高い分岐を選べるように
- 学習速度の改善:並列処理・近似アルゴリズム・欠損値の自動処理により、大規模データでも実用的な速度を実現
この3つを1つのフレームワークに統合したことで、精度・速度・汎化性能をまとめて改善したのがXGBoostの革新です。
LightGBM
LightGBMはXGBoostの学習速度・大規模データへの対応をさらに改善した手法です。
主に3つの工夫で速度を実現しています。
- 全ての葉を均等に広げるのではなく、損失を最も減らせる葉だけを優先して分割する
- すでに精度よく予測できているデータ(勾配の小さいデータ)は一部だけサンプリングし、計算量を削減する
- 連続した数値をビンに丸め、分割点の探索回数を大幅に減らす
ただし、データ量が少ない場合は一方向に深くなりすぎて過学習しやすい点には注意が必要です。
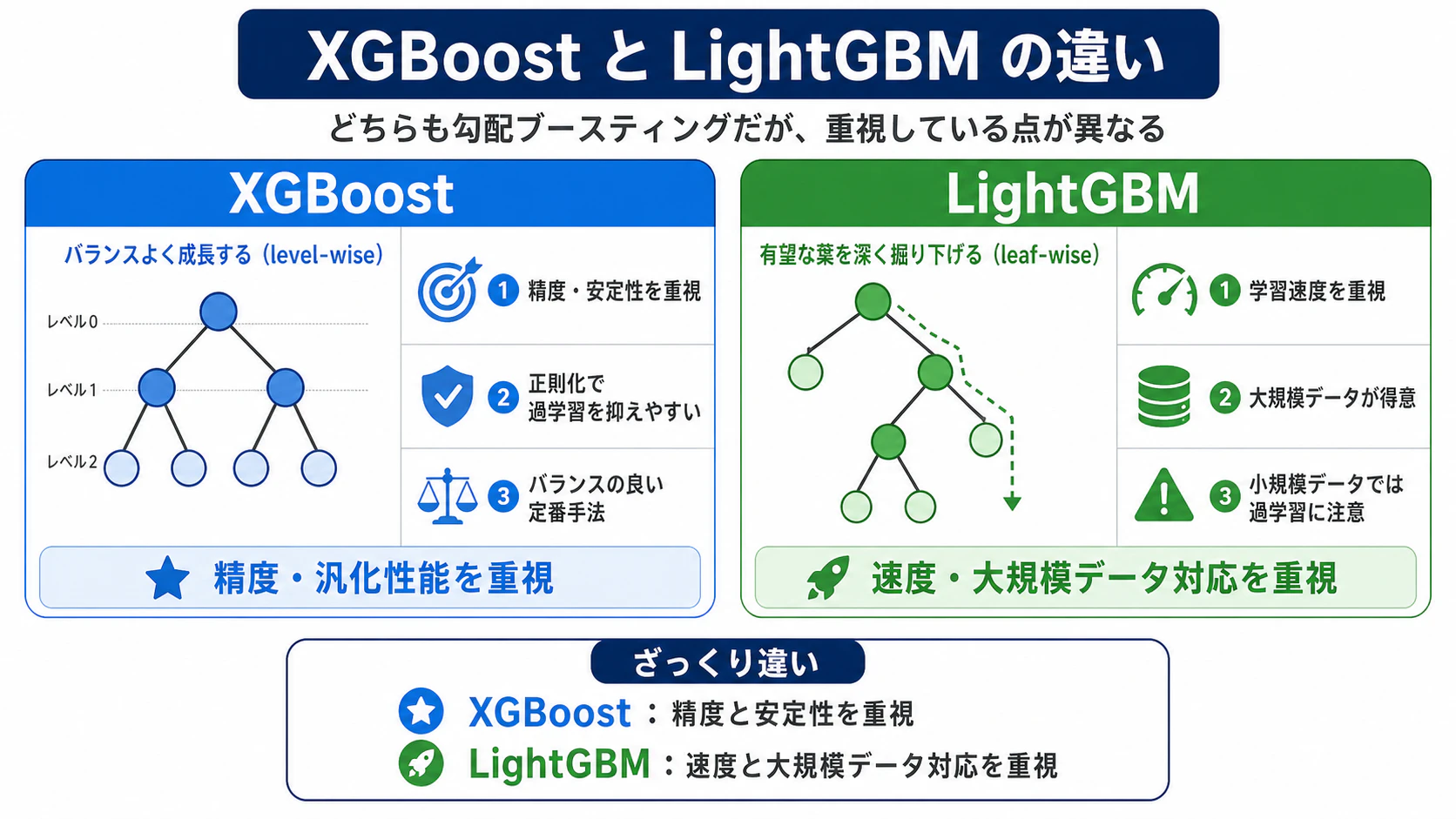
図3:XGBoostとLightGBMの比較イメージ図
ハイパーパラメータ解説
ここからはハイパーパラメータについて解説します。重要な注意点として、XGBoostとLightGBMにはSklearn APIとオリジナルAPIの2種類の呼び出し方があります。 どちらも同じアルゴリズムを使っていますが、インターフェースの違いによりパラメータ名や挙動が一部異なります。本記事ではSklearn APIの名称をベースに解説し、オリジナルAPIで名前が異なる場合はlearning_rate(eta)のように括弧内に併記します。
なお、決定木の構造に関わるパラメータなど、図で説明できるものは図解を交えて解説します。
XGBoostのハイパーパラメータ
まず押さえたいパラメータ
| パラメータ | デフォルト | 説明 |
|---|---|---|
objective |
reg:squarederror |
解くタスクの種類。回帰なら reg:squarederror、二値分類なら binary:logistic、多クラスなら multi:softmax
|
n_estimators(num_boost_round) |
100 |
作成する木の本数 |
learning_rate(eta) |
0.3 |
学習率 |
max_depth |
6 |
木の最大の深さ |
eval_metric |
タスクに応じて自動設定 | 評価指標(例:rmse、auc、logloss) |
n_estimators(num_boost_round)
残差を修正する決定木の数を調整するパラメータです。木の数を増やすほど学習データの細かい特徴まで学習できますが、過学習に陥りやすくなります。
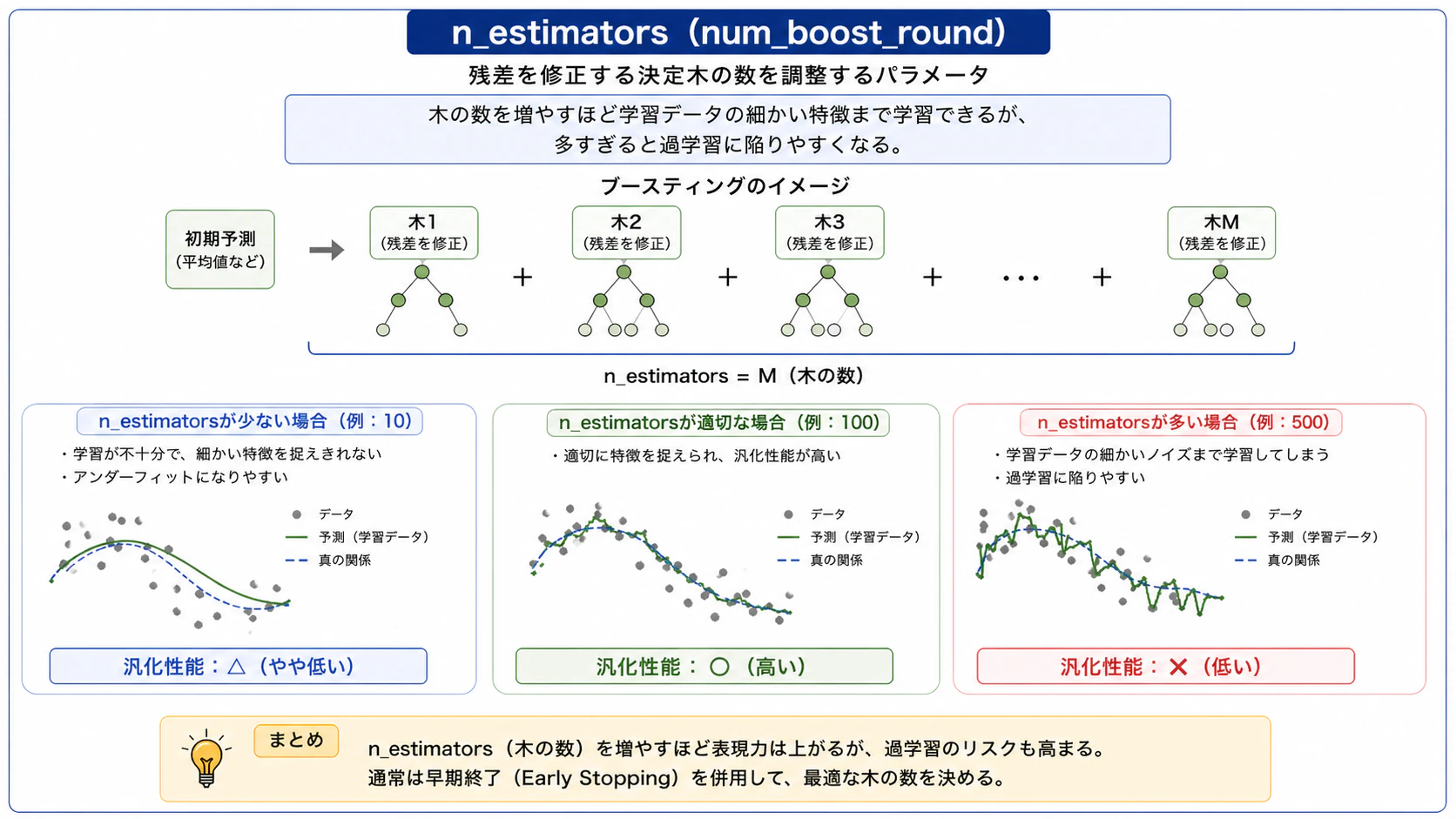
図4:n_estimatorsのイメージ図
max_depth
木の最大の深さを調整するパラメータです。深くするほど学習データの細かい特徴まで学習できますが、過学習に陥りやすくなります。
n_estimatorsとmax_depthの2つは精度に最も影響を与える基本パラメータです。チューニングの際はまずこの2つから調整するのが定石です。
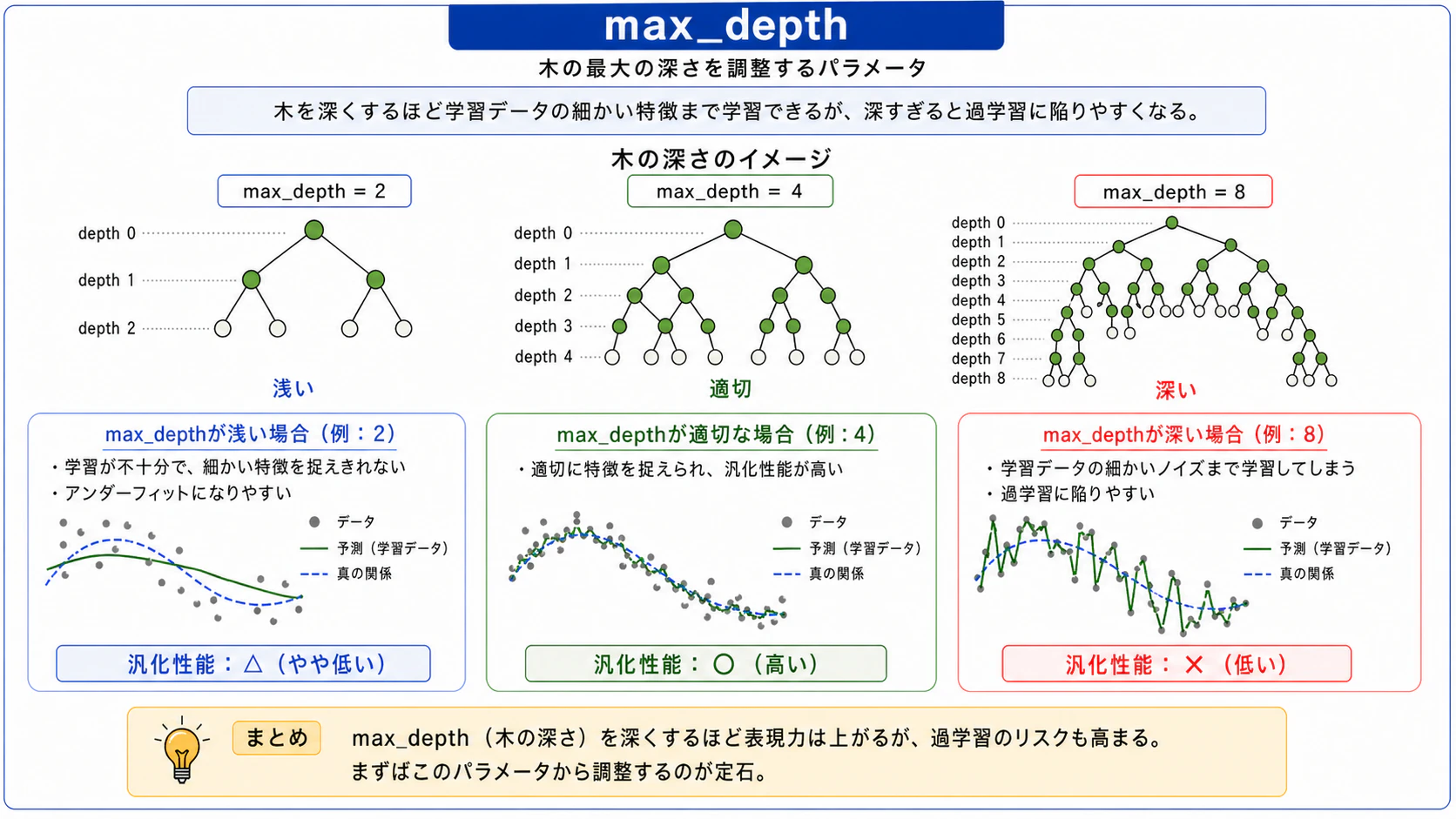
図5:max_depthのイメージ図
learning_rate(eta)
各決定木が予測した残差をどの程度取り入れるかを示す値です。図に示すように、予測値は「予測残差 × learning_rate」を逐次的に加算することで更新されます。これにより、1本の木の予測を完全に信用するのではなく、少しずつ慎重に修正することで過学習を抑える効果があります。
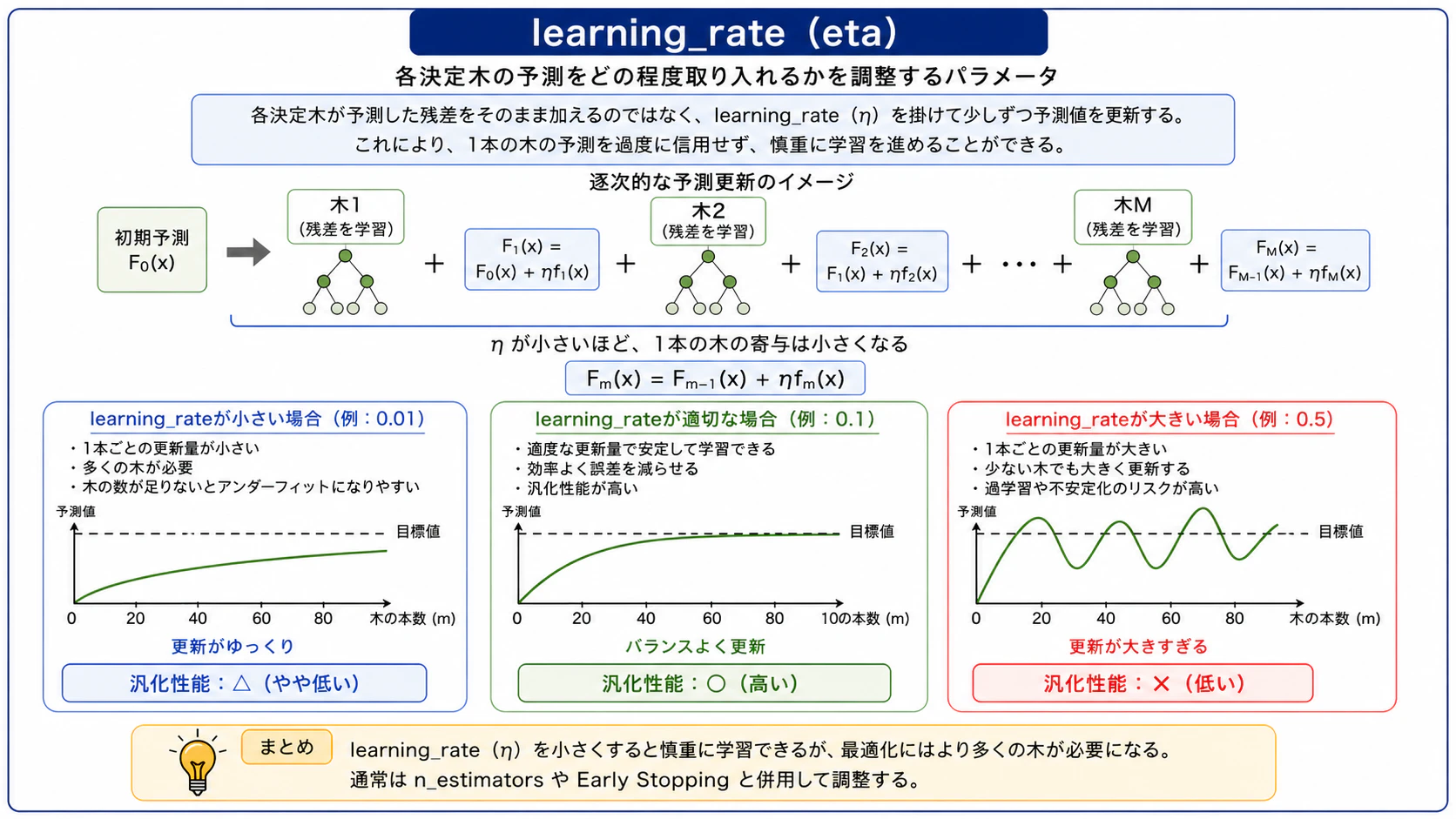
図6:learning_rate(eta)のイメージ図
よく使うパラメータ
| パラメータ | デフォルト | 説明 |
|---|---|---|
min_child_weight |
1 |
葉に必要なデータの最小量の目安 |
reg_lambda(lambda) |
1 |
葉の予測値をゼロ方向に収縮するペナルティの強さ(L2正則化) |
reg_alpha(alpha) |
0 |
葉の予測値をゼロに押しつぶすペナルティの強さ(L1正則化) |
subsample |
1.0 |
各木で使うデータの割合 |
colsample_bytree |
1.0 |
各木で使う特徴量の割合 |
early_stopping_rounds |
None |
評価指標が改善しなければ何本目で打ち切るか |
num_class |
— | 多クラス分類時のクラス数(objective=multi:softmaxのとき必須) |
min_child_weight
一つの葉に必要な最小データ数(厳密にはデータの重みの合計)の目安を示す値です。値が小さいほど細かく分割されますが、過学習に陥りやすくなります。例えばmin_child_weight=1(デフォルト)では、1件だけのデータからなる葉も作られうるため、極端な分割が起こる可能性があります。
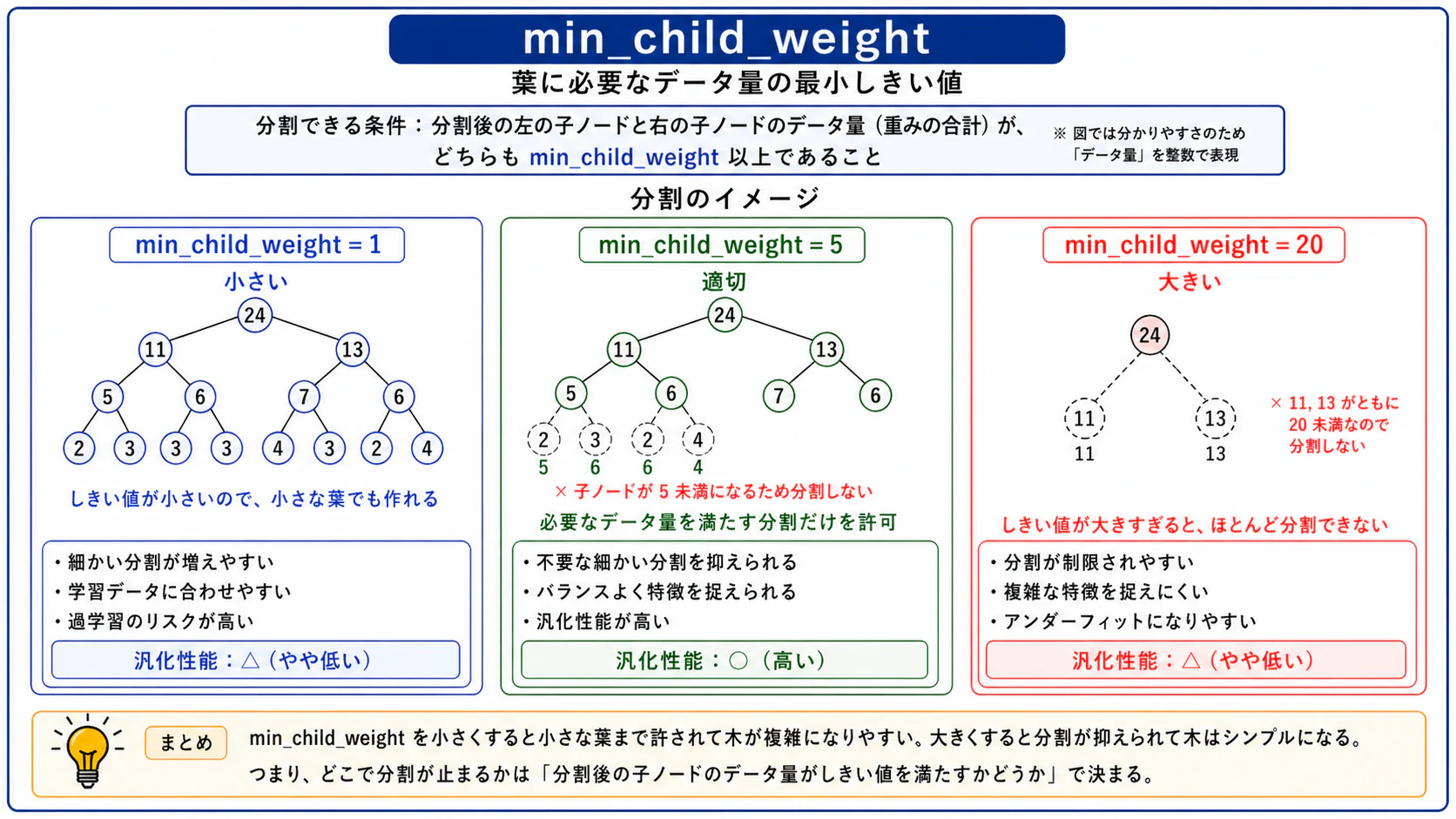
図7:min_child_weightのイメージ図
reg_lambda(lambda)
葉の予測値の絶対値が大きくなりすぎないように抑える強さ(L2正則化の強さ)を示す値です。葉の予測値の絶対値が大きすぎると、その木が訓練データに過度に適合してしまう可能性があるため、この値を大きくすることで過剰な修正を防ぎます。
reg_alpha(alpha)
reg_lambda(lambda)と同様に葉の予測値が大きくなりすぎないように抑える強さを示す値です。異なる点として、reg_alpha(alpha)はL1正則化の強さを表す値です。L2正則化は葉の予測値がゼロに近づくにつれて抑える力が弱まりますが、L1正則化は大きさに関わらず常に一定の力でゼロ方向に押しつぶします。そのため、影響の小さい葉の修正量をゼロにしやすくする効果があります。
reg_lambdaとreg_alphaはどちらも過学習を抑えるパラメータですが、一般的にはreg_lambdaを調整するケースが多いです。reg_alphaはKaggleなどのコンペティションで精度を限界まで追い込む際に併用されることがあります。
subsample
各決定木を作成するときに、訓練データのうち何割を使用するかを指定する値です。値を小さくすると、各木が異なるデータで学習するため過学習を抑えやすくなります。一方で、小さくしすぎると情報量が不足して性能が低下することがあるため、必要に応じて木の数(n_estimators)などを調整します。
colsample_bytree
各決定木を作成するときに、特徴量カラムのうち何割を使用するかを指定する値です。値を小さくすると、各木が異なる特徴量で学習するため多様性が生まれ、過学習を抑えやすくなります。一方で、小さくしすぎると各木で利用できる特徴量が制限され、予測性能の低下やアンダーフィットを招く場合があります。
colsample_bylevel(各深さごと)・colsample_bynode(各ノードごと)でさらに細かくサンプリングを制御することもできます。これらは累積的に作用するため、例えば3つすべてを0.8にした場合、実際に使われる特徴量は 0.8 × 0.8 × 0.8 = 約50% まで絞られます。基本的にはcolsample_bytreeのみ調整するのが無難です。
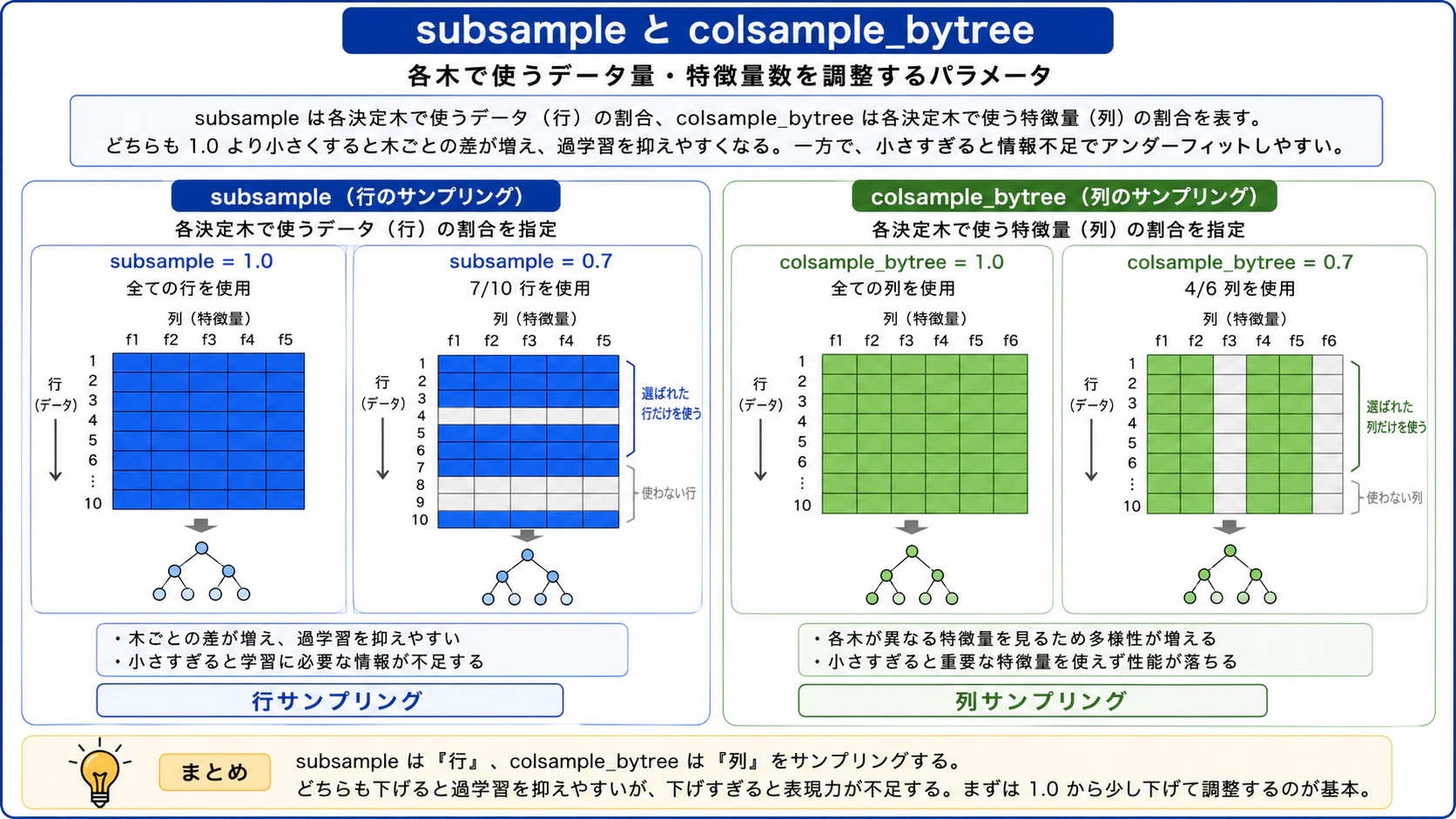
図8: subsampleとcolsample_bytreeのイメージ図
early_stopping_rounds
評価指標が指定した木の本数の間改善しなければ学習を打ち切るパラメータです。無駄な学習を防ぎ、過学習を抑える効果があります。
知っておくと良いパラメータ
| パラメータ | デフォルト | 説明 |
|---|---|---|
gamma(min_split_loss) |
0 |
分割に必要な最低限の損失改善量 |
scale_pos_weight |
1 |
正例の重みを調整(負例数 / 正例数が目安) |
booster |
gbtree |
dart(ドロップアウト付き)やgblinear(線形モデル)に切り替えられる |
tree_method |
auto |
木の構築アルゴリズム。histが現在の推奨。exactは小データ向け |
monotone_constraints |
— | 単調性を強制:1=増加 / -1=減少 / 0=制約なし |
quantile_alpha |
— | 分位点回帰の目標分位点(例:0.9で90パーセンタイルを予測) |
gamma(min_split_loss)
分割によって改善される損失がgamma以上の場合にのみ分割が行われます。ほとんど損失が改善しない分割を防ぐことで、過学習を抑える効果があります。
scale_pos_weight
正例(少数クラス)のデータに対してペナルティを何倍に拡大するかを指定します。不均衡データで正例を見逃しやすい場合に、負例数 / 正例数 を目安に設定します。
booster
dartを指定することで決定木をランダムのドロップアウトさせます。gblinearは決定木ではなく、線形モデルをブースティングして学習します。gblinearはほぼ使うことはなく、dartは過学習が気になる時に稀に使われるようです。
dartの時に、以下のパラメータを追加で設定できます。
-
rate_drop: ドロップアウト率 -
skip_drop: ドロップをスキップする確率 -
one_drop:1にすると毎回最低1本ドロップする
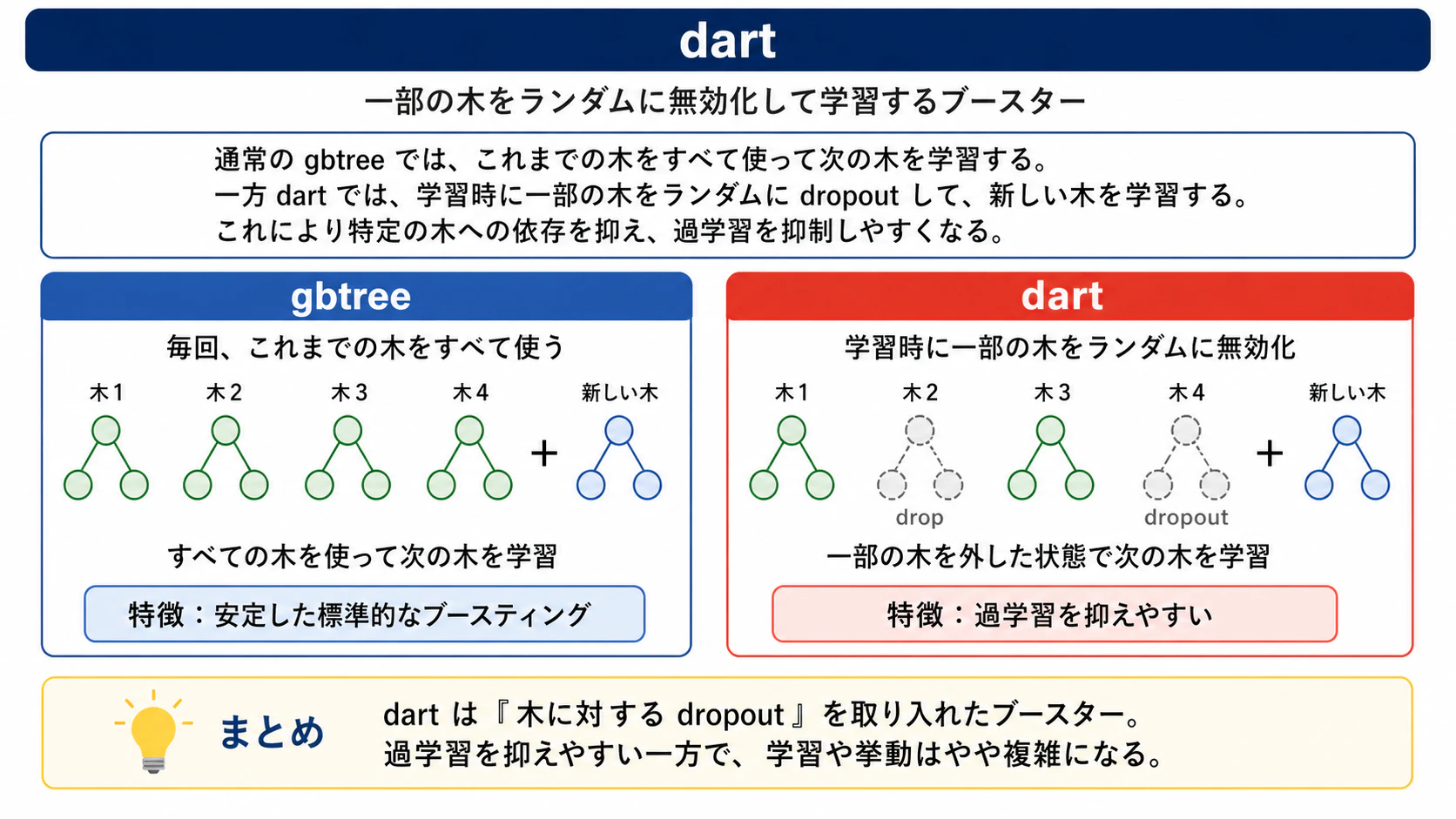
図9: booster=dartの場合のイメージ図
tree_method
決定木の分岐点、つまり「どの特徴量のどの値で分割すると一番良いか」の探し方を指定します。基本的にはhistを使うのが一般的ですが、データ数が少ない場合はexactも選択肢になります。
2つの違いを年齢(1〜100)を例に示します。
-
hist: 0-20, 21-40, 41-60, 61-80, 81-100 のようにビンに区切り、境界値だけを候補にする -
exact: 1, 2, 3, ... 100 の全値を候補にする
データ数が多い場合、histは高速で、かつ細かな分岐点の違いが予測精度にほとんど影響しないため、基本的にhistで十分な精度が出ます。現在のautoは実質的にhistとして扱われます。
histの時に、どのくらい細かくビンに区切るかをmax_binで指定することができます。デフォルト値は256です。
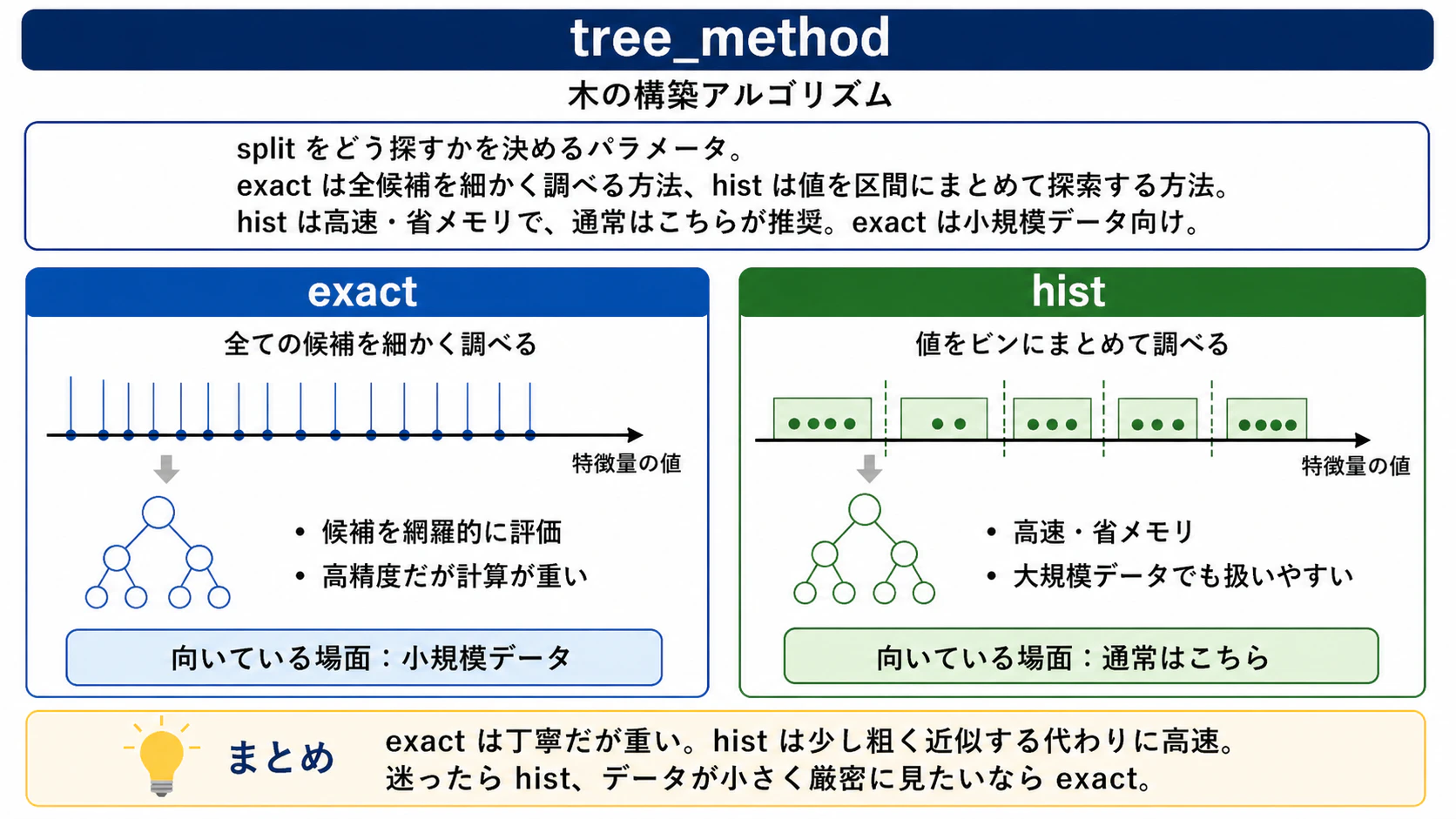
図10: tree_method=histとexactの場合のイメージ図
monotone_constraints
特徴量と予測値の関係性を強制するパラメータです。「年齢が上がるほど保険料が高くなる」というような業務上のルールがある場合、モデルがそれに反する予測をしないように制約をかけられます。精度よりも解釈性・納得感が求められる金融・医療分野などで使われることがあるようです。
quantile_alpha
通常の回帰は「平均的な値」を予測しますが、分位点回帰は「この値以下になる確率がα%」という値を予測します。
例えば需要予測でquantile_alphaを使うと、以下のようなシナリオ別の予測が得られます。
-
quantile_alpha=0.1(ほぼ最悪ケース):予測した需要量を下回る確率は10%しかない -
quantile_alpha=0.9(ほぼ最良ケース):予測した需要量を下回る確率は90%である
このように、単一の予測値ではなくシナリオを想定して予測に幅を持たせたい場合に使用されます。
LightGBMのハイパーパラメータ
XGBoostとほぼ同じ意味のものは説明を省略します。
まず押さえたいパラメータ
| パラメータ | デフォルト | 説明 |
|---|---|---|
objective |
regression |
解くタスクの種類。回帰なら regression、二値分類なら binary、多クラスなら multiclass
|
n_estimators(num_iterations) |
100 |
作成する木の本数 |
learning_rate |
0.1 |
学習率 |
num_leaves |
31 |
1本の木の最大葉数 |
metric |
タスクに応じて自動設定 | 評価指標。例:rmse、auc、binary_logloss
|
learning_rate
値の意味はXGBoostと同様ですが、デフォルト値は0.1と小さめに設定されています(XGBoostは0.3)。これはLightGBMが損失を最も減らす葉を優先的に分割する葉優先(leaf-wise)方式を採用しているためと考えられます。この方式は木が深くなりやすく過学習に陥りやすい傾向があるため、デフォルトの学習率を小さくすることでバランスを取っています。
num_leaves
決定木の最大の葉の数を指定します。XGBoostでは木の最大の深さ(max_depth)で木構造に制約をかけていましたが、LightGBMはleaf-wise方式のため、深さで制約をかけると早い段階で上限に達してしまう可能性があります。そのため、LightGBMでは葉の数で制約をかける方式を採用しています。XGBoostのmax_depthと同様の役割を持つ、非常に重要なパラメータの一つです。
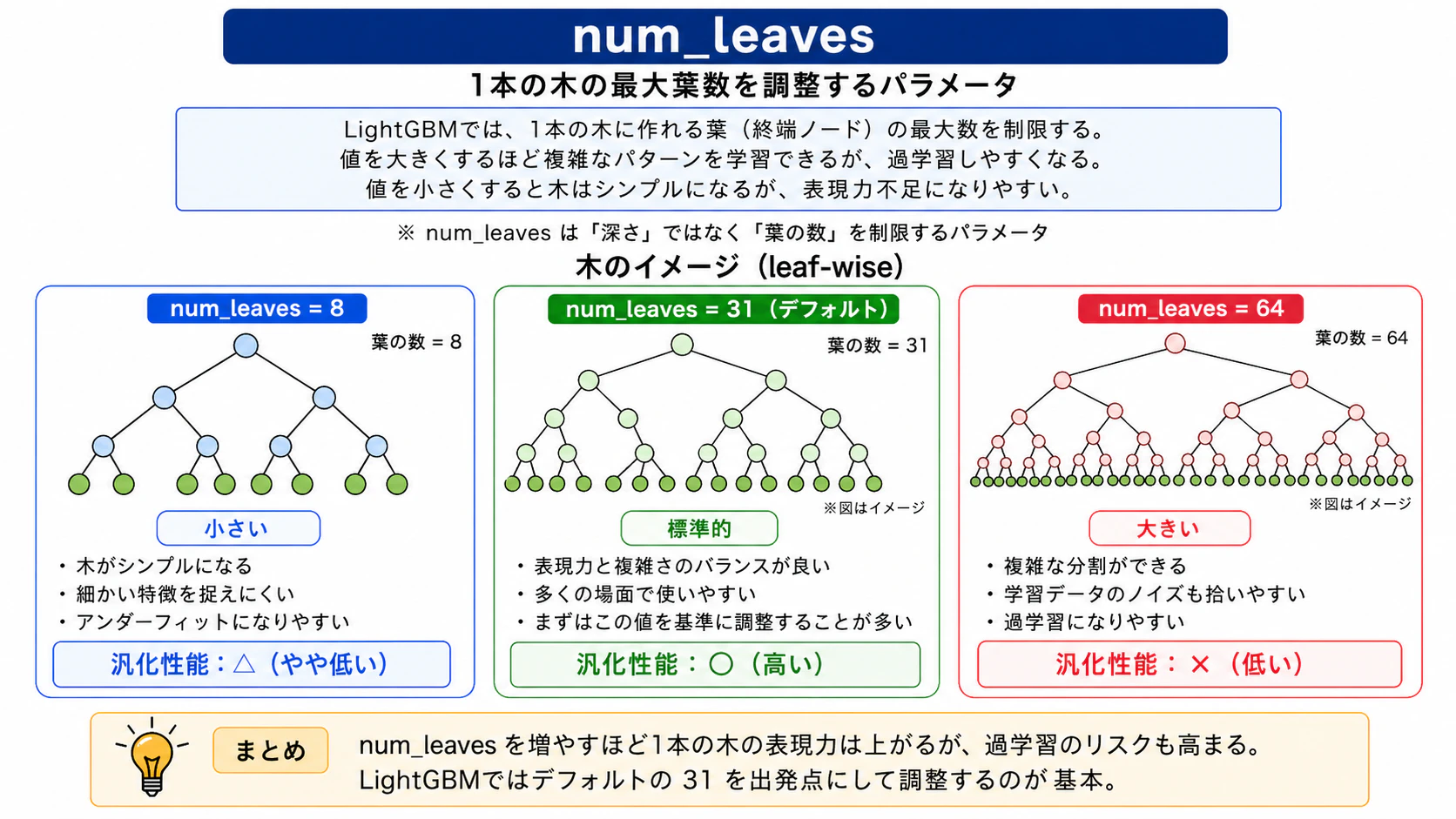
図11: num_leavesのイメージ図
よく使うパラメータ
| パラメータ | デフォルト | 説明 |
|---|---|---|
max_depth |
-1 |
木の最大深さ(-1で制限なし) |
min_child_samples(min_data_in_leaf) |
20 |
葉に必要な最小データ数。大きくすると過学習抑制 |
reg_alpha(lambda_l1) |
0.0 |
L1正則化の強さ |
reg_lambda(lambda_l2) |
0.0 |
L2正則化の強さ |
subsample(bagging_fraction) |
1.0 |
各反復で使うデータの割合。subsample_freqも一緒に設定する必要あり |
subsample_freq(bagging_freq) |
0 |
サンプリングの頻度(0で無効) |
colsample_bytree(feature_fraction) |
1.0 |
各反復で使う特徴量の割合 |
early_stopping_round |
0 |
評価指標が改善しなければ何ラウンドで打ち切るか(0で無効) |
is_unbalance |
false |
正例・負例の比率に応じて重みを自動調整 |
scale_pos_weight |
1.0 |
正例の重みを手動で指定(負例数 / 正例数が目安) |
num_class |
1 |
objective = multiclass のときのクラス数 |
categorical_feature |
"" |
カテゴリ変数として扱う列の指定。One-hotエンコード不要 |
max_depth
XGBoostと同じ意味を持つパラメータですが、LightGBMのデフォルト値は-1(制限なし)であり、葉の数(num_leaves)で木構造に制約をかけています。しかし、leaf-wise方式は最も損失が減る葉を優先して分割するため、特定の枝だけが深くなりやすく、過学習が起きてしまう場合があります。そのため、num_leavesに加えてmax_depthを指定することがあります。
min_child_samples(min_data_in_leaf)
XGBoostにもmin_child_weightとしてほぼ同様のパラメータがありますが、XGBoostのデフォルトが1なのに対してLightGBMでは20に設定されており、より過学習を強く抑制するようになっていることがわかります。
subsample(bagging_fraction),subsample_freq(bagging_freq)
XGBoostにもあったsubsampleですが、LightGBMではこれを有効化するにはsubsample_freqを1以上に設定する必要があります。この値はsubsampleで指定した割合のデータをどのくらいの頻度でサンプリングするかを表しており、例えば1の場合は毎回サンプリング、5の場合は5回ごとに新たにサンプリングして同じデータを5反復使用する、という挙動になります。
is_unbalance
trueにした場合、各クラスのデータ量から自動で重みを計算して不均衡を補正してくれます。手動で重みを指定したい場合はscale_pos_weightを使用します。
categorical_feature
都道府県や血液型などのカテゴリ変数を指定することで、LightGBMが内部で最適な分割方法を探してくれます。
通常のエンコーディングには以下の問題があります。
- One-hot : 「東京か否か」のように1対1の比較しかできない
- ラベルエンコーディング : 「東京(0) < 大阪(1)」のように意味のない大小関係で分割してしまう
categorical_featureに指定した場合、「{東京, 埼玉, 千葉, 神奈川} vs それ以外」のように複数のカテゴリをまとめた最適なグループで分割できるため、より本質的な分割が可能になります。
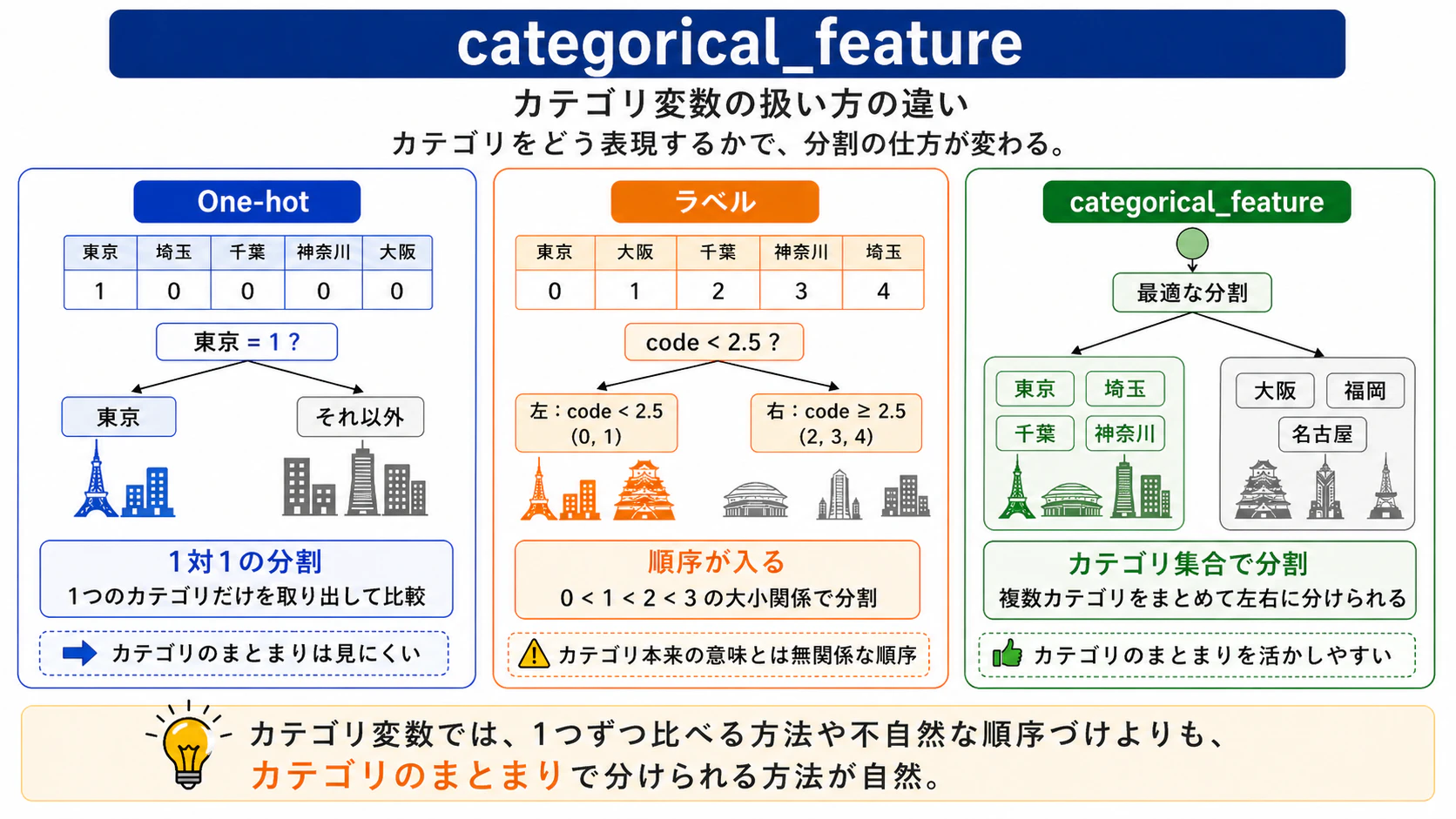
図12: categorical_featureのイメージ図
知っておくと良いパラメータ
| パラメータ | デフォルト | 説明 |
|---|---|---|
boosting_type(boosting) |
gbdt |
dart(ドロップアウト付き)や rf(ランダムフォレスト)に切り替えられる |
data_sample_strategy |
bagging |
gossに設定するとGOSSサンプリングが有効になる |
max_bin |
255 |
特徴量を何段階のビンに丸めるか。大きいと精度↑・速度↓ |
monotone_constraints |
None |
単調性を強制:1=増加 / -1=減少 / 0=制約なし |
data_sample_strategy
学習時のデータサンプリング方法を指定します。gossに設定すると、各サンプルの勾配(残差)を計算し、勾配が大きいデータ(モデルがうまく予測できていないデータ)を優先的に学習に使用します。全データを使わずに精度を保てるため、学習の効率化につながります。
gossの時に、以下のパラメータを追加で設定できるようになります。
-
top_rate: 勾配が大きい順の上位何割のデータを使用するか -
other_rate:top_rateで選ばれなかったデータのうち何割を使用するか
まとめ
記事を書きながら図を作る中で、普段何気なく使っているパラメータでも意外と理解が曖昧なものが多いことに気付かされました。ハイパーパラメータチューニングは重要である一方、あまり時間をかけたくない作業でもあります。だからこそ、それぞれのパラメータの意味をしっかり理解しておくことが、効率的なチューニングへの近道だと思います。
今後も「普段使っているけど、そう言えばこれって何だっけ?」と思えるようなトピックを取り上げていきたいと思っています。
本記事内のハイパーパラメータ説明図の作成には、OpenAI の gpt-image-2 を使用しました。