macOSでSikulix+OCR動作(ver2.0.4対応)
■はじめに
オープンソースのRPAツール、Sikulix。
Javaで開発されていますが、RPAのフローはPython(ただしver2系)で書くことができます。
ネットなどではWindowsで動作させる情報が多いですが、Javaなので環境さえ用意すればmacでも動きます。
また、現在(2021/02/23現在)ダウンロードできる最新バージョンは2.0.4ですが、以前の1.1.4での情報がまだまだ多いですし、macOSでバージョン2.0.4+ORC動作の情報はまだまだ見つかりません。
そこで、macOS+ver2.0.4+OCRが動作した環境構築の記録を上げます。何かのお役に立てば(^^)
このRPAの導入のきっかけは、会社で使っているWindowsPCで楽をする作業の簡略化を行うためなのですが、自宅ではmacをメインに使っているので、自宅のmacでも環境構築と動作検証をするためにmac環境での構築を始めました。楽をするためなら仕事の持ち帰りも徹夜もいとわないのがSEという職種です。
構築にあたっては、Windows環境での説明ですが『さわって学べるSikuliX Pythonで作るRPA』(大澤 文孝著)がきっかけと主な参照元になっています。AmazonのKindle Unlimitedで読むことができます。
環境
macOS:10.13.6(使っているアプリの都合でまだ10.13です。多分10.15とかでも同じだと思います)
■下ごしらえ 〜sikulixのインストール〜
JREが必要になります。"JRE"で検索すると、Suicaのポイントページがでてきてしまうので、以下のリンクを参照して下さい。
ここを参照してJavaをダウンロードしてインストールして下さい。
https://www.java.com/ja/download/help/mac_install.html
sikulixのダウンロード
1.1.4系の情報がいろいろありますが、2021年2月現在ダウンロードできる最新バージョンは2.0.4です。
※画像キャプチャーを取らず進めたので、インストールの手順はテキストで。
まず、以下のサイトから必要となる、
・Sikulix IDE
・Jython
の2つをダウンロードします
※今回はJython(Python)で使用することを前提としています。
SikuliXダウンロードサイト
https://raiman.github.io/SikuliX1/downloads.html
ここから、SikulixのIDE
「Download the ready to use sikulix.jar (SikuliX IDE)」と書かれているとこの「sikulixide-2.0.4.jar」をダウンロードします。
Jythonはこちら
「The Jython interpreter 2.7.1 for python scripting (the default)」の
「jython-standalone-2.7.1.jar」をダウンロード。
sikulixのインストール(配置)
ダウンロードしたものを適当なフォルダに入れて(Applications」フォルダに「Sikulix」というフォルダを作っていれる、とか)、「sikulixide-2.0.4.jar」をダブルクリックします。
すると「jython-standalone-2.7.1.jar」が別のフォルダに移動します。
~/Library/Application Support/Sikulixが初期設定や拡張機能が格納される場所で、jythonのファイルはExtensionの中に移動します。
再度、sikulixide-2.0.4.jarをダブルクリックすると、Sikulixが起動します。
多分、セキュリティーがどうのこうのというメッセージが出てくると思いますが、「システム環境設定」の「セキュリティとプライバシー」をいじってなんとかできます。ググってみてください(てきとーだな。私)
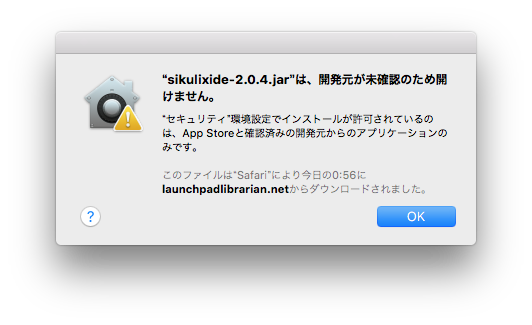
sikulixの初期設定(mac向け)
ここで、動作確認としてポップアップメッセージを表示させるコードを書いて実行すると、こんなエラーが出ます。
「javax.script.ScriptException: ReferenceError: "[メソッドとか]" is not defined in nashorn:mozilla_compat.js at line number [エラーが発生している行番号]」
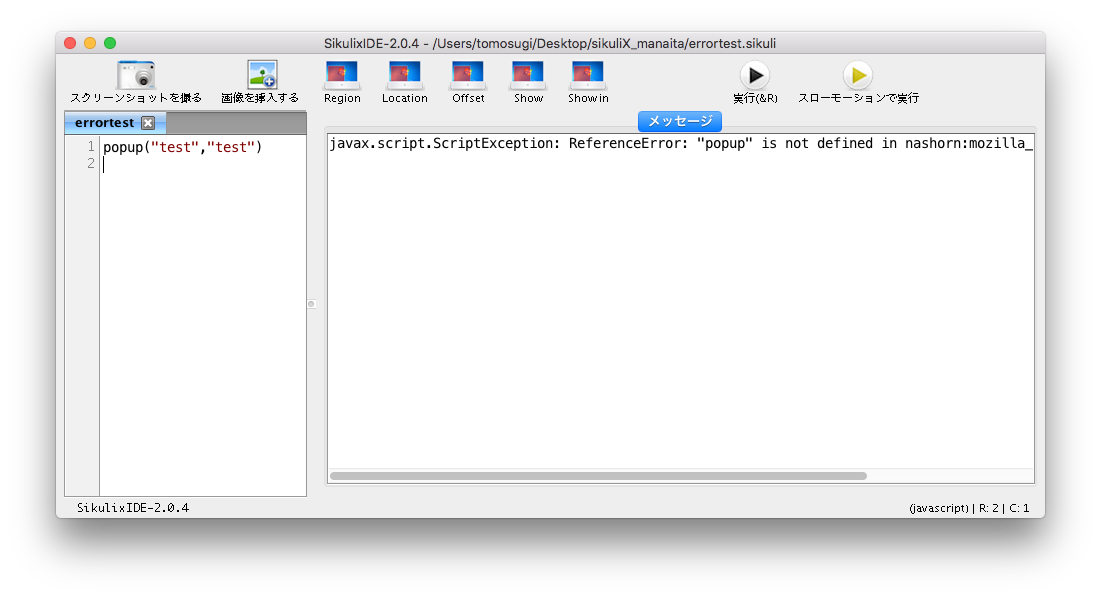
macで初めて実行すると、デフォルトのコード記述がJavascriptになっているので、Pythonでコードを書いて実行するとエラーが出ます。
Windowsでは出なかったエラーです。WindowsではデフォルトはPython(jython)のようです。なのでこういうエラーは出ませんでした。
一度実行してエラーが出てしまうと、このコードは修正できない(多分あるけど新規ファイルを作って貼り直したほうが早い)ので、以下の手順で記述するプログラムをPythonに指定します。
「ファイル」から「新規作成」(Command+N)で「無題」の新規ファイルを作成します。
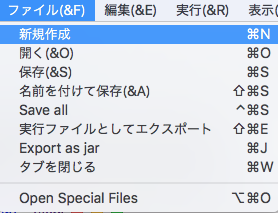
コード欄のタブ「無題」のところを右クリックして「Set Type」を選択。
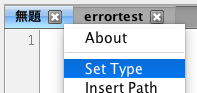
「Jython」を選択して「OK」をクリック。
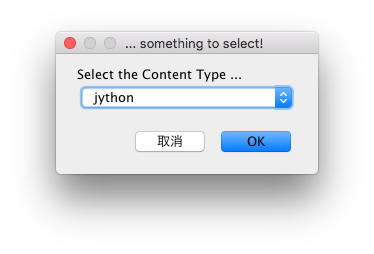
これでコードを書いてファイルを保存して「実行」をクリック。
(日本語を含んだ文字列を表示させる場合、u"日本語"と表記する必要があります)
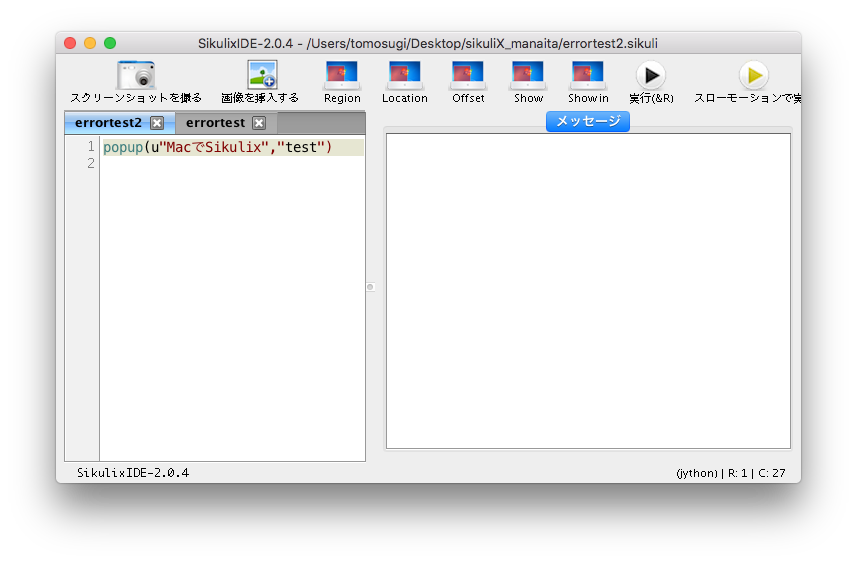
この設定は一度行えば、次回から作成するファイルに反映されます。
これでMacでもSikulixが動きました!
けど、全然Sikulixらしい動作確認じゃないな。こりゃ。
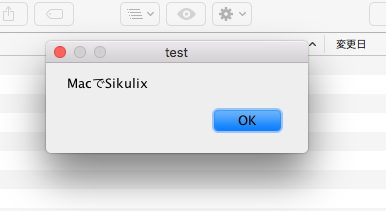
このJavaのjarファイル、Dockに登録できないので、デスクトップとかにエイリアスを置いて起動させます。
■OCRの日本語対応
**注意!
Home brewが使える環境を用意しておいて下さい。以下のtesseractのインストールに必要です。
このまま範囲を指定してOCRを実行するコードを実行してもエラーが出て動きません。
(すいません。キャプチャーとかエラーログを取り忘れました)
まず、ここの情報を見ると、、、
https://sikulix-2014.readthedocs.io/en/latest/news.html
New or revised in version 2.0.2
Text and OCR features are now implemented using the Java library Tess4J (current latest version based on Tesseract 4.x).
と、sikulix2.0.2では、Tesseract 4.xを使っていると書いてあります。確か、デフォルトで入っているtesseractはver2.0。
(ただし、もしかしたら、tesseractを入れ替えなくても、この後に説明するbrewでtesseractを入れれば動作するかもしれません。以下の手順でtesseractの4.0.0を入れてもエラーが出たので、brewでtesseractをインストールしたので問題の切り分けをしてない。。。なので、tessaractのファイルを入れ替えなくても動く、かもしれません)
tesseractの言語ファイルのダウンロード
(もしかしたら、デフォルトのtesseractのファイルでも動くかもしれません。後述するbrewでtesseractのインストールを先に行って、それでもOCRが動作しないようであれば、各言語ファイルを入れ替えたほうがいいかもしれません)
gitのtesseractのページからダウンロードします
まずここにアクセス。
https://github.com/tesseract-ocr/tessdoc
リンク「tessdata_best」をクリック。
「jpn.traneddata」をクリック。

「master」ボタン>「Tags」タブ>4.0.0をクリック(4.1.0でもいいです)
「Download」をクリック
ダウンロードしたファイルはこちらになります。
同様の手順でeng.traineddataもダウンロードしておきます
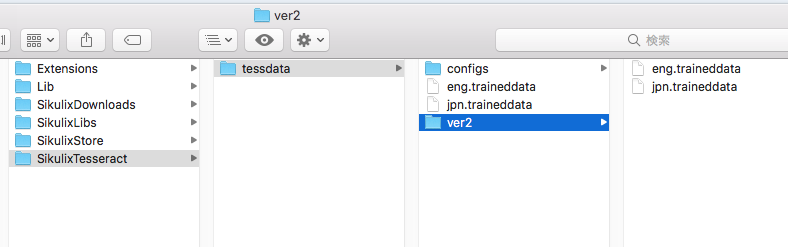
ダウンロードしたファイルは以下のディレクトリ
~/Library/Application Support/Sikulix/SikulixTesseract/tessdataの中に入れます。
ただし、ver2のデータがあるので、別フォルダを作ってしまってから移動させました。
■brewでtesseractをインストール
これで動くと思ったら、、、怒られた。。。
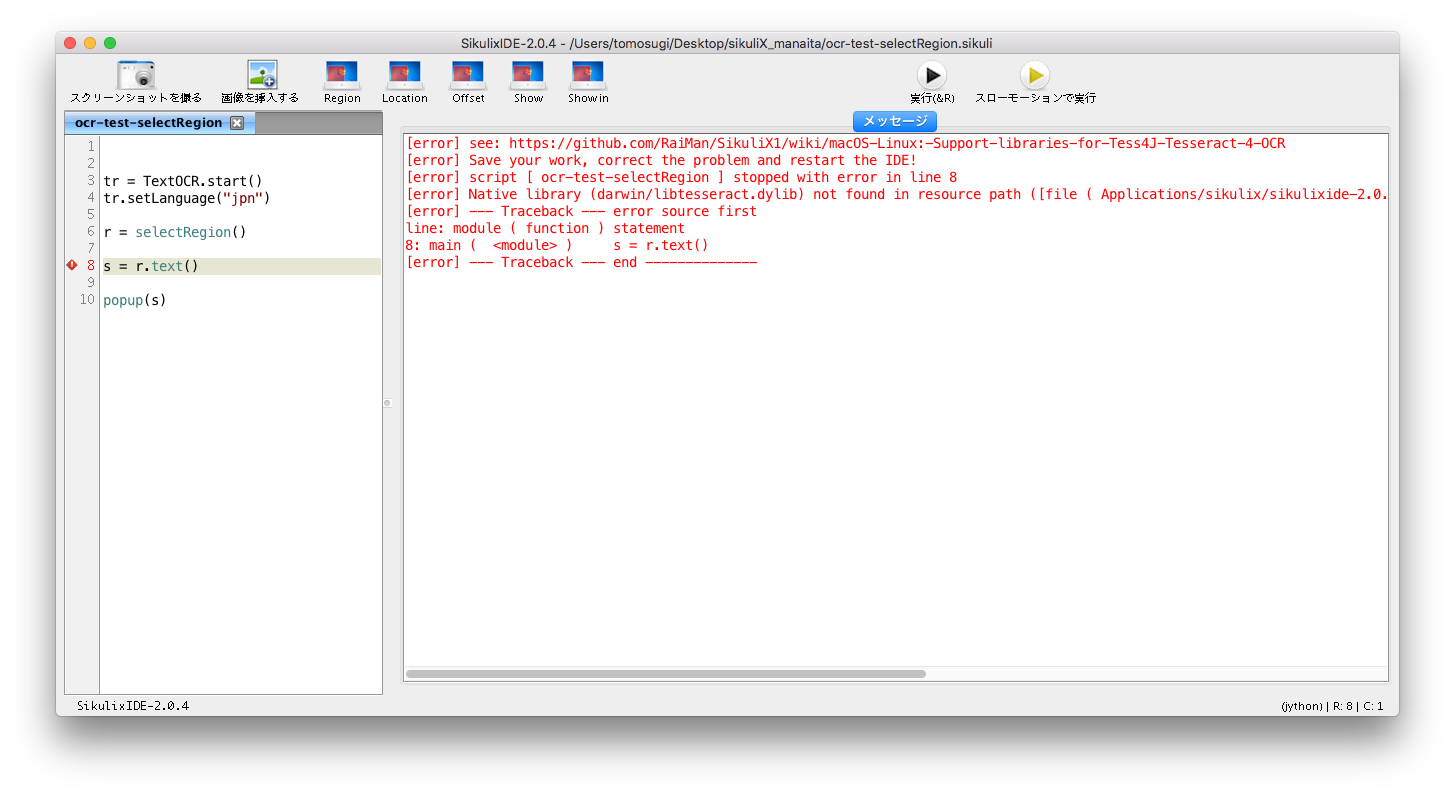
エラーメッセージに表示されたリンク先を見ると、brewでtesserctを入れとけと書いてあったので、入れます。
https://github.com/RaiMan/SikuliX1/wiki/macOS-Linux:-Support-libraries-for-Tess4J-Tesseract-4-OCR
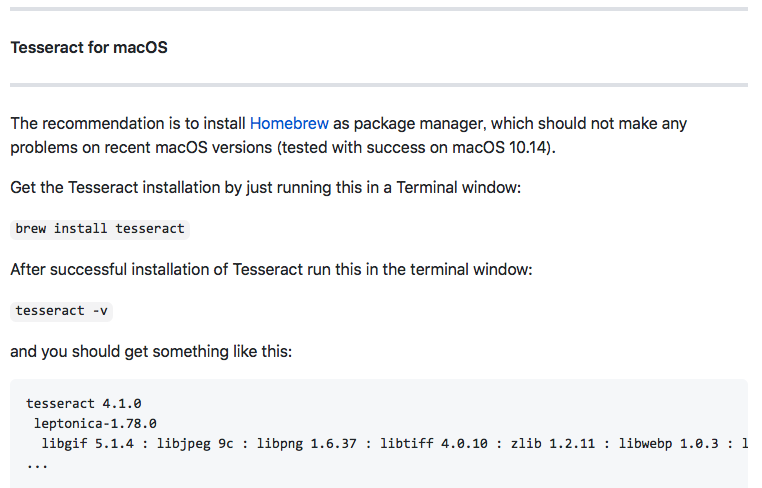
おなじみのbrewで入れます。「brew install tesseract」で一発インストール。依存関係とかも解決してくれるのでらくちんです。
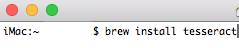
10.13使ってるの!と言われました。古いバージョンはサポートしないですって。
ごちゃごちゃ言われましたが、とにかくインストールしてくれます。
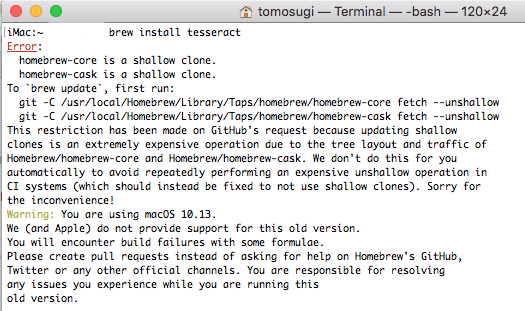
どうやらengとかosdとかsnum以外の言語ファイルはbrewで入れろ、とありますが、今回はSikulixで使うので、brewで入れたものが動作するか分からず。それでbrewでは入れていません。

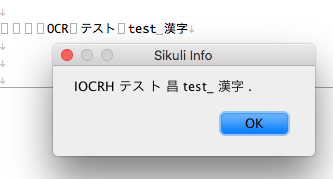
一応入ったことだし、これでもう一度Sikulixを起動し直して、先ほどの範囲指定で日本語を認識させるコードを実行してみます。
認識率が非常に微妙で怪レい日本话ですが、一応"OCR"は動作してくれました。
まぁ、動いた、と。動かない高機能な環境より、低機能でも動く環境が正義。
■OCRでの認識テスト
こんなファイルを作ってみました。一番下の行、10ptではなく16ptですね。
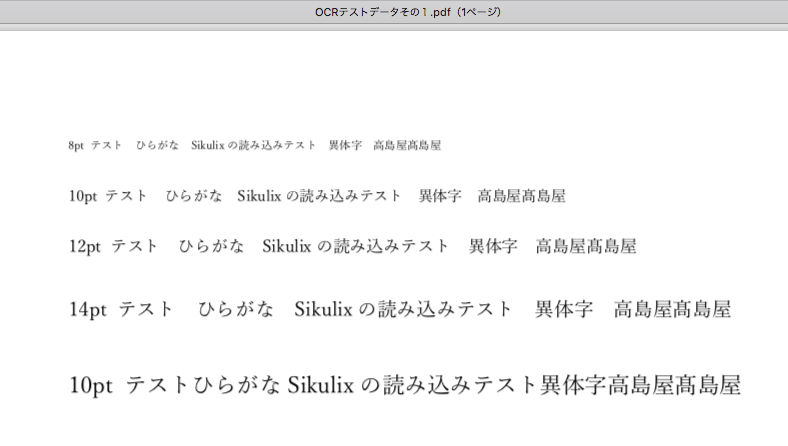
8ptでもこれだけ読んでくれました。意外と頑張ってくれます。
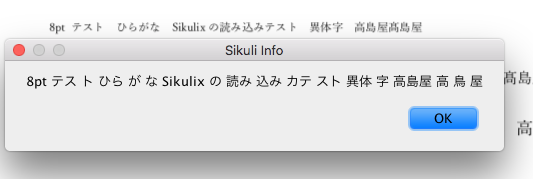
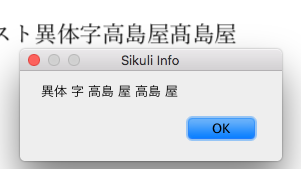
16ptの異体字を認識させてみましたが、さすがに「はしごだか」の**「髙」は普通の「高」**で認識しました。ま、「高」と出てきてくれればいいです。
冒頭にも書きましたが、この本、
『さわって学べるSikuliX Pythonで作るRPA』がとても参考になりました。
Amazon Unlimitedなら無償で読めます(一応読めば出版社と作家さんに一定額が入ります)
https://www.amazon.co.jp/dp/B07WC9KYSB/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1