はじめに
watsonx Code Assistant をモデル指定で稼働する以下の記事を参照させていただき、
以前検証した以下の記事の内容を合わせて、
watsonx code assistant を IBM Power RHEL9.4 サーバーで ollama + granite3.1-dense:8b での稼働を確認しました。
LLM のモデルは、2024/12 リリースの IBM Granite 3.1 "granite3.1-dense:8b" を使用します。
環境
-
HW: IBM Power S1022
LPAR リソース:CPU 3 core, Memory 32 GB で検証
今回はインターネット接続環境を使用しています。 -
RHEL 9.4 server (ppc64le)
-
ollama : 次のコンテナ・イメージを使用 -> quay.io/mgiessing/ollama
-
LLM model : granite3.1-dense:8b -> https://ollama.com/library/granite3.1-dense
--
- Local PC (Mac) + VSCode + watsonx Code Assistant(拡張機能)
以下のようなイメージで、Local PC の VSCode + watsonx Code Assistant から Power10 RHELサーバー(LPAR) の ollama + granite と接続しています。
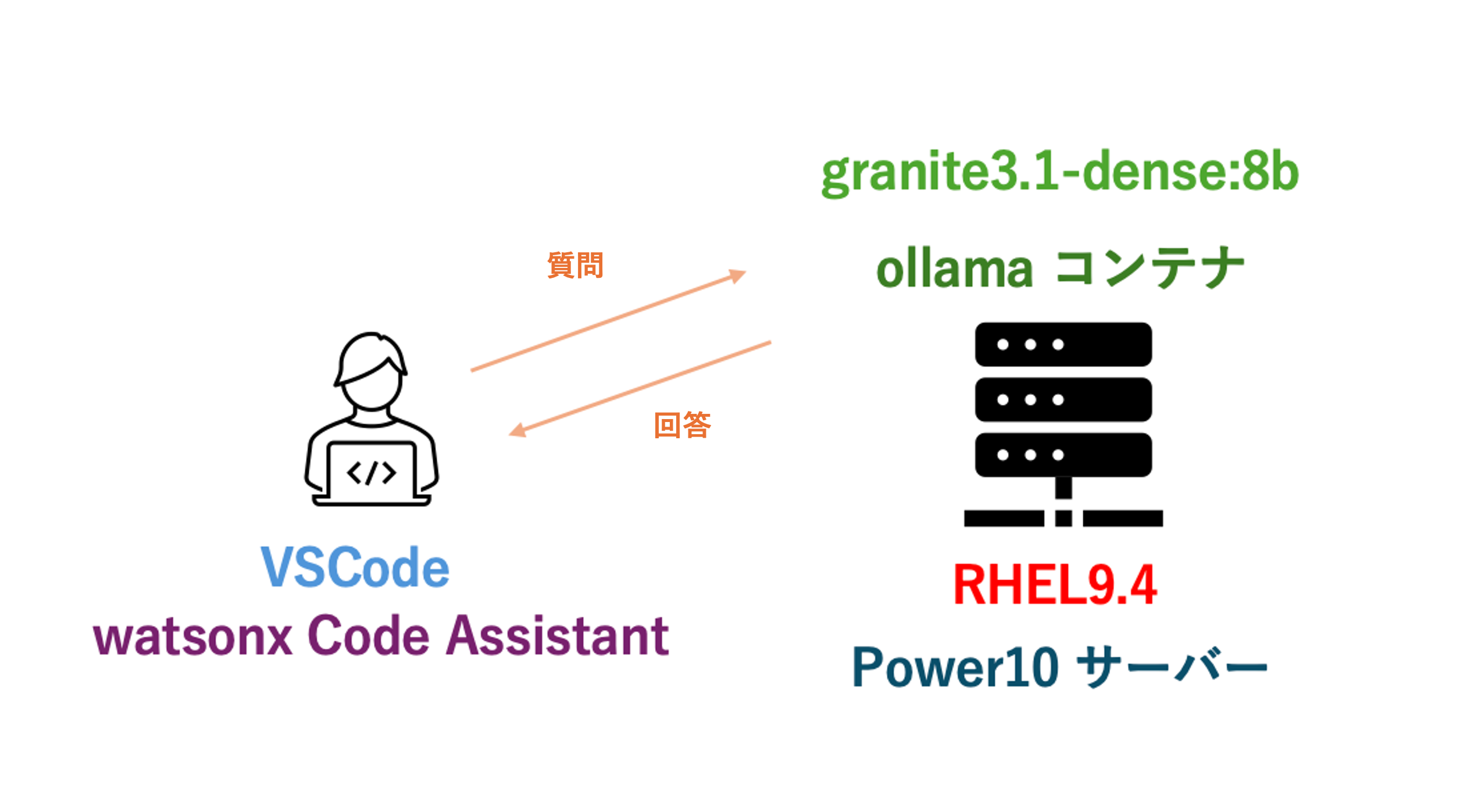
Power10 上の RHEL の ollama 環境設定
- ollama コンテナを pull
# podman run -d --privileged -v ollama:/root/.ollama -p 6443:11434 --name ollama quay.io/mgiessing/ollama:v0.3.14
Trying to pull quay.io/mgiessing/ollama:v0.3.14...
Getting image source signatures
Copying blob a26f98920ed2 done |
Copying blob a181ccbec46a done |
Copying blob c1b3fd6d67e8 done |
Copying blob ee70963c9454 done |
Copying config 175cf51aaf done |
Writing manifest to image destination
2f52c47bcd37e5f0de03c627fed614da5aea8ab0aecf0ec9bc0c270af3751d87
Tips : PowerVS 外部接続では 6443 ポートが任意使用可能であるため、ホスト側のポートを 6443 で指定しています。
PowerVS : ネットワーク・セキュリティー
https://cloud.ibm.com/docs/power-iaas?topic=power-iaas-network-security&locale=ja
ポート 6443 も、多様な用途のために開いています。
- コンテナ稼働確認
# podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2f52c47bcd37 quay.io/mgiessing/ollama:v0.3.14 serve 14 seconds ago Up 14 seconds 0.0.0.0:6443->11434/tcp ollama
- ollama コンテナにログイン
# podman exec -it ollama /bin/bash
[root@2f52c47bcd37 /]#
- model の確認
[root@2f52c47bcd37 /]# ollama list
NAME ID SIZE MODIFIED
-> まだ何のモデルもpull していない状態です。
- model の pull と 実行
# ollama run granite3.1-dense:8b
pulling manifest
pulling 0a922eb99317... 100% ▕████████████████████████████████████▏ 4.9 GB
pulling f7b956e70ca3... 100% ▕████████████████████████████████████▏ 69 B
pulling f76a906816c4... 100% ▕████████████████████████████████████▏ 1.4 KB
pulling 492069a62c25... 100% ▕████████████████████████████████████▏ 11 KB
pulling e026ee8ed889... 100% ▕████████████████████████████████████▏ 491 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
プロンプトが表示され、ollama 上で granite3.1-dense:8b が稼働するようになりました。
ここで ollama とモデルが稼働したので、外からアクセスできるかを確認します。
Webブラウザで "http://(ollama稼働のサーバーIPアドレス):6443" にアクセスします。

接続できると、"ollama is running" の表示が確認できます。
外部接続の可能も確認できました。
VSCode の watsonx Code Assistant で ollama API ホストの設定
VSCode 上で watsonx Code Assistant の 拡張機能設定を行います。
参照させていただいた手順(再掲):
VSCode の設定画面を開きます
-> 左下の歯車マークで設定を選択

watson を検索
-> watsonx Code Assistant で以下の箇所を設定します
・Wca: Backend Provider (ollama)
・Wca > Local: Api Host (作成した ollama サーバーのIPアドレス:6443ポートを指定)
・Wca > Local: Chat Model (granite3.1-dense:8b)
・Wca > Local: Code Gen Model (granite3.1-dense:8b)

稼働確認
- 赤枠部分の watsonx Code Assistant の Chat セッションを開きます。

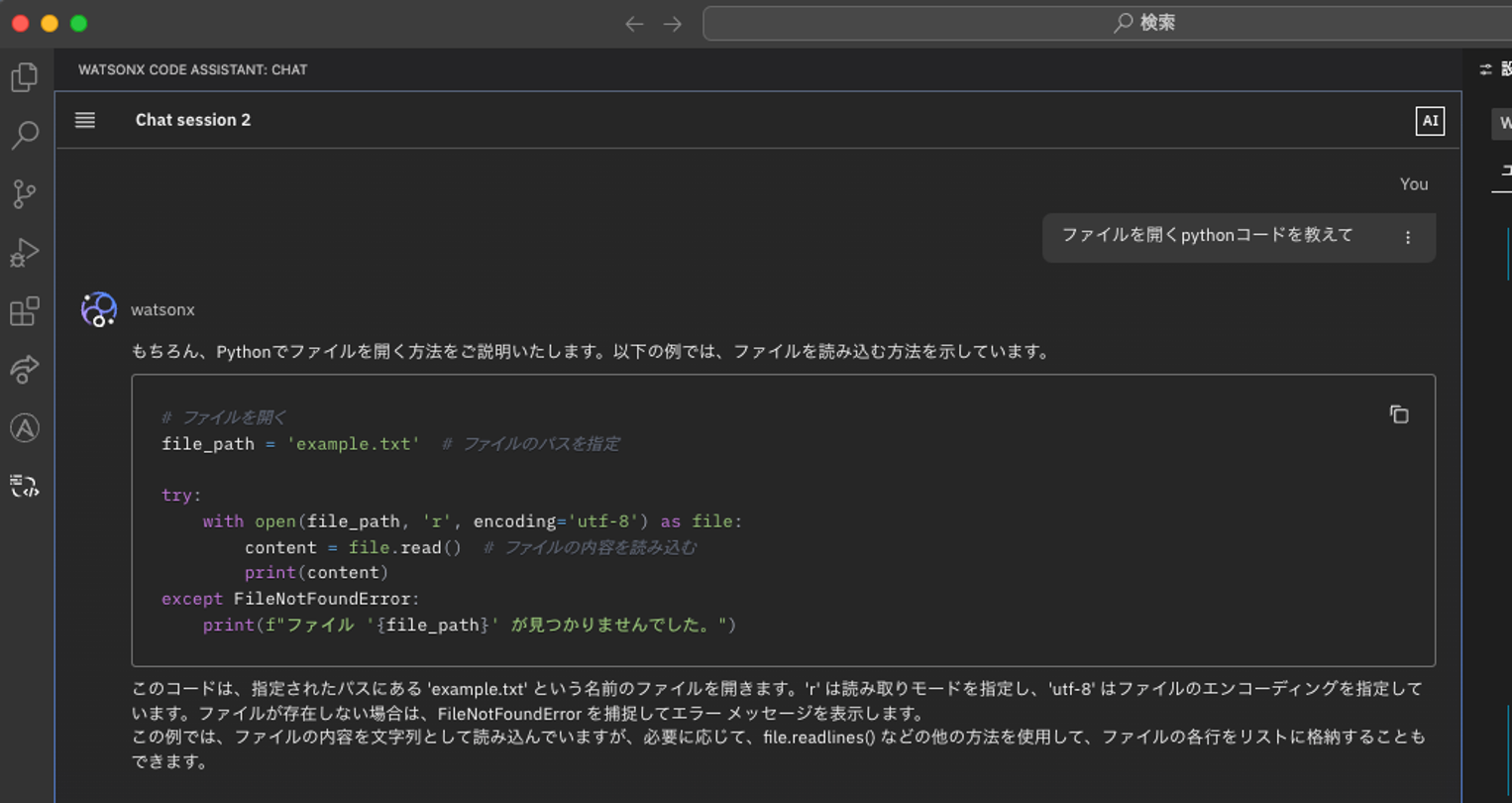
質問します。
"ファイルを開く python コードを教えて" と聞いてみました。
少し時間はかかりましたが、(数十秒~1分?) 答えが返って来ました。
回答を書き始めたら速い印象です。
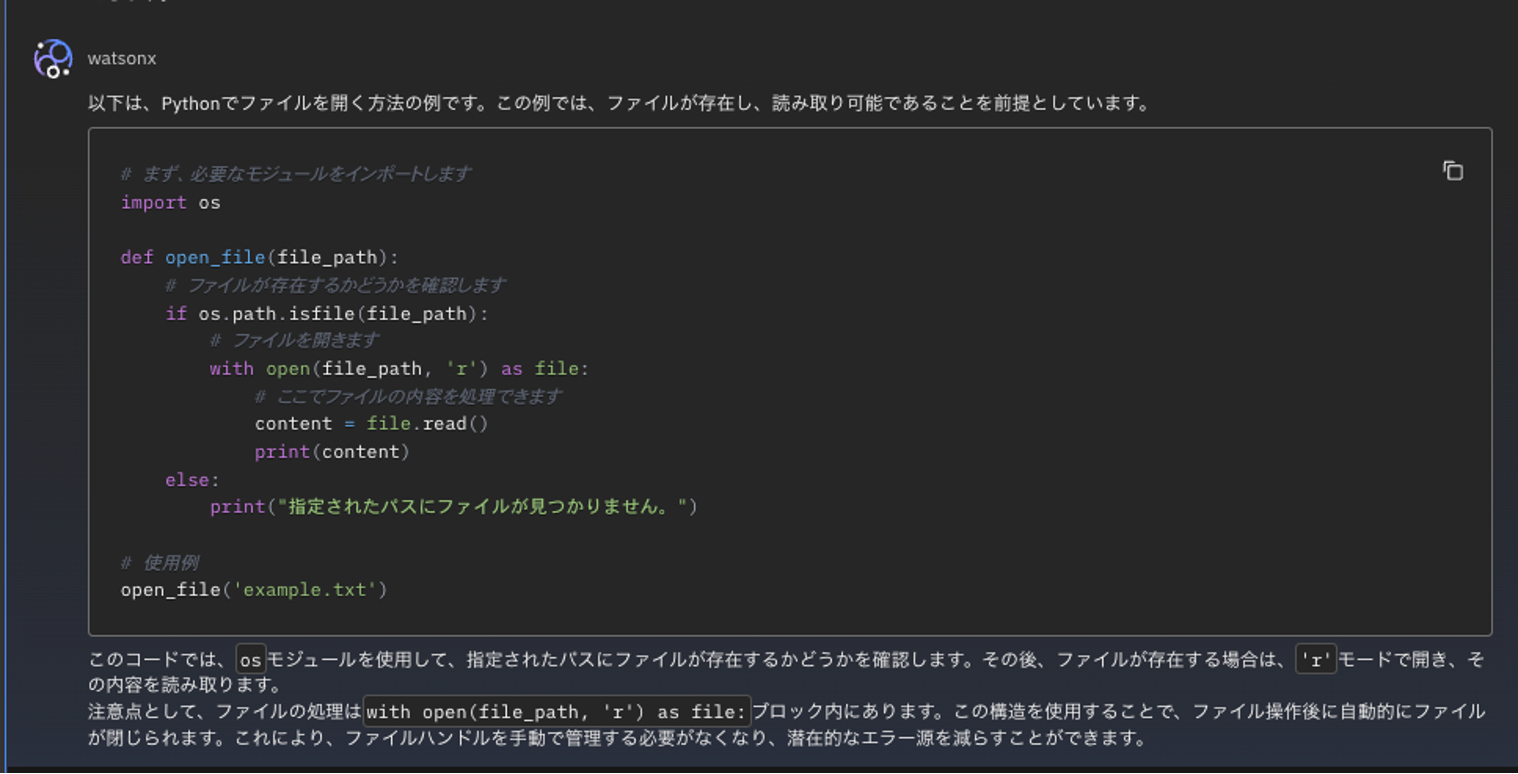
同じような回答ですが、追加で答えてくれました。(つまりユーザーの1 回の質問で WCA/ollama/granite側から2 回の回答がありました)
今回はインターネット接続環境で作成しましたが、Power環境は一般的にはClosed 環境が多いので、インターネット非接続のPower環境内にLLM 稼働サーバー作成できるように今後、手順を確認予定です。
おわりに
-
Power 上で簡単に ollama 環境を構築して、LLM を稼働することができています。
-
CPU、メモリーリソースがどの程度必要なのかは、(時間があれば)調査できればと思います。
-
最近は ollama 互換の UI やサービスが増えてきているようなので、Local の ollama サーバーでLLMモデルを稼働させておけば他のサービスとの接続にも使用できそうです。
以上です。