目次
0:概要
1:WatsonQueryとRedshiftの接続
2:データ仮想化
3:仮想化データの確認
0:概要
WatsonQueryとRedshiftServerlessを接続し、Redshiftのテーブル※1を仮想化する方法を解説します。
※1:Redshift上にテーブルがある前提で解説を行います。
1:WatsonQuery(以降WQと省略)とRedshiftの接続
データ仮想化→データソース→接続の追加→新規接続をタップします。
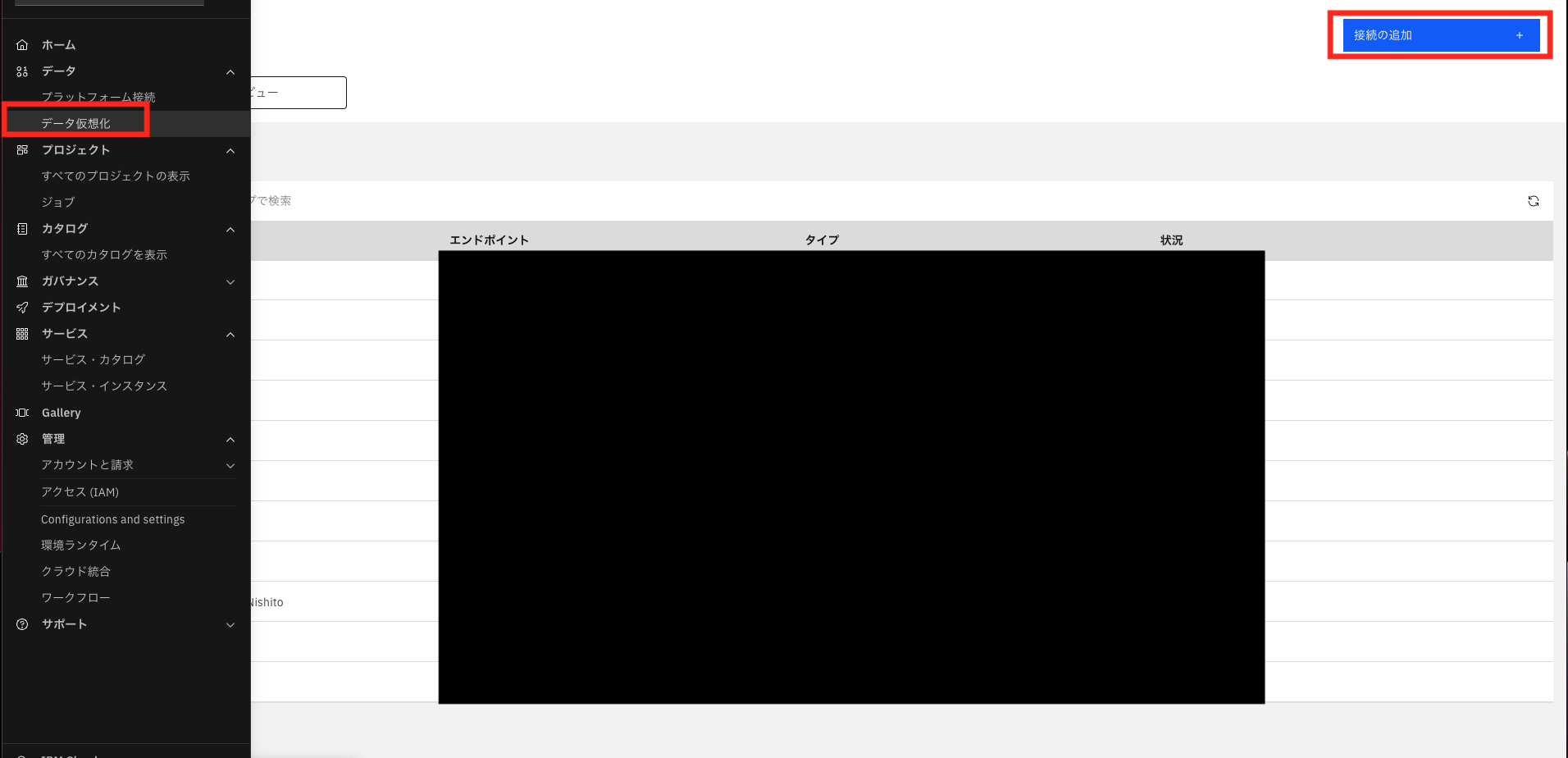
接続先として、AmazonRedshiftを選択します。
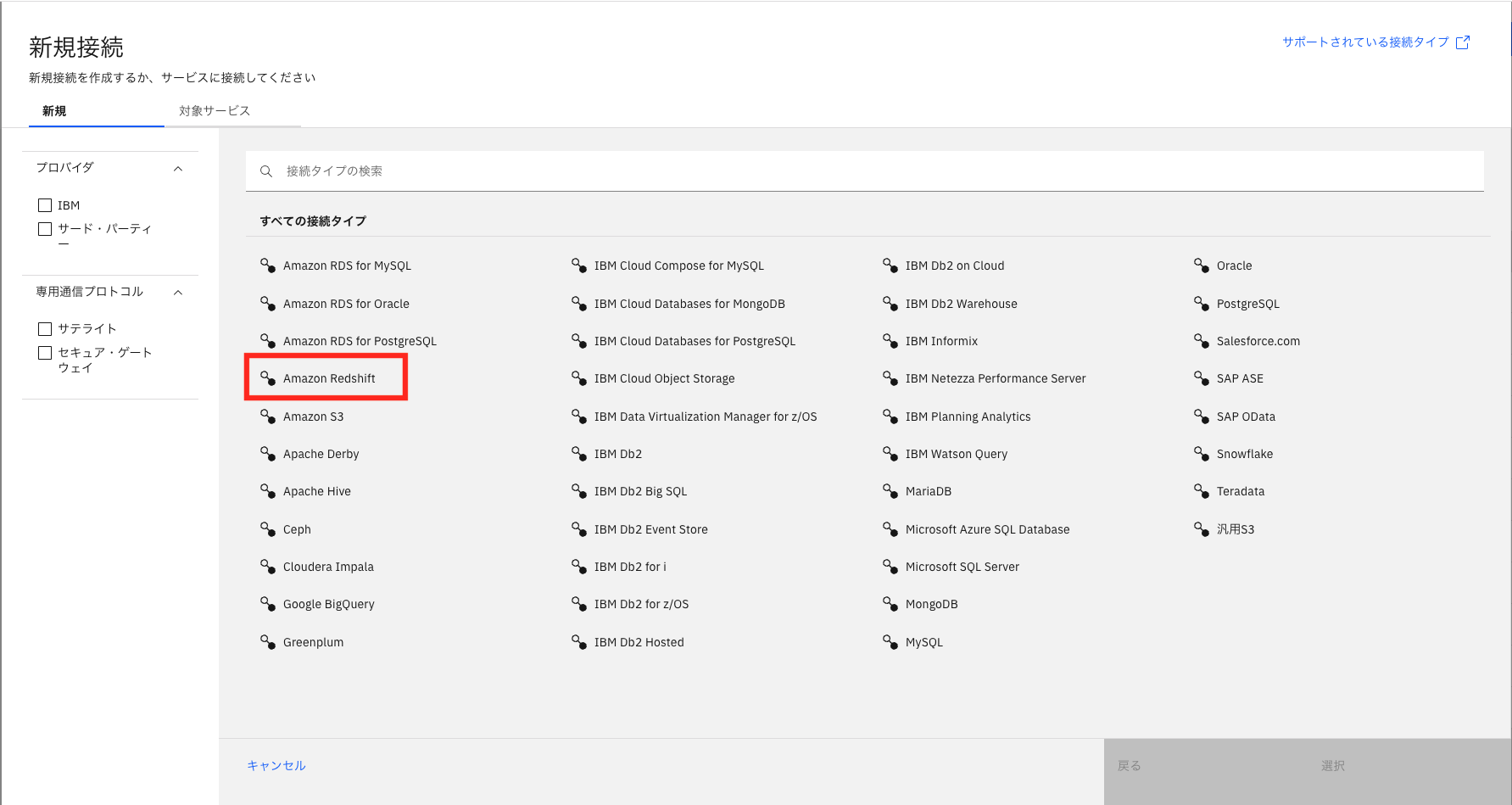
接続の編集にて、必要事項を記入します。
名前:demo_AWS_redshift(任意)
説明:Watson Query においてRedshiftのテーブルを仮想化する方法(任意)
データベース:demo(Redshift上のデータベース名)
ホスト名または IP アドレス:default.番号.ap-northeast-1.redshift-serverless.amazonaws.com(Redshift上のエンドポイント)
ポート:5439(Redshift上のデータベースポート番号)
ユーザー名:admin(AWSユーザーネーム)
パスワード:****(AWSパスワード)
接続テストが成功したら、作成をタップします。

データソースにAWS_Redshiftが追加されます。
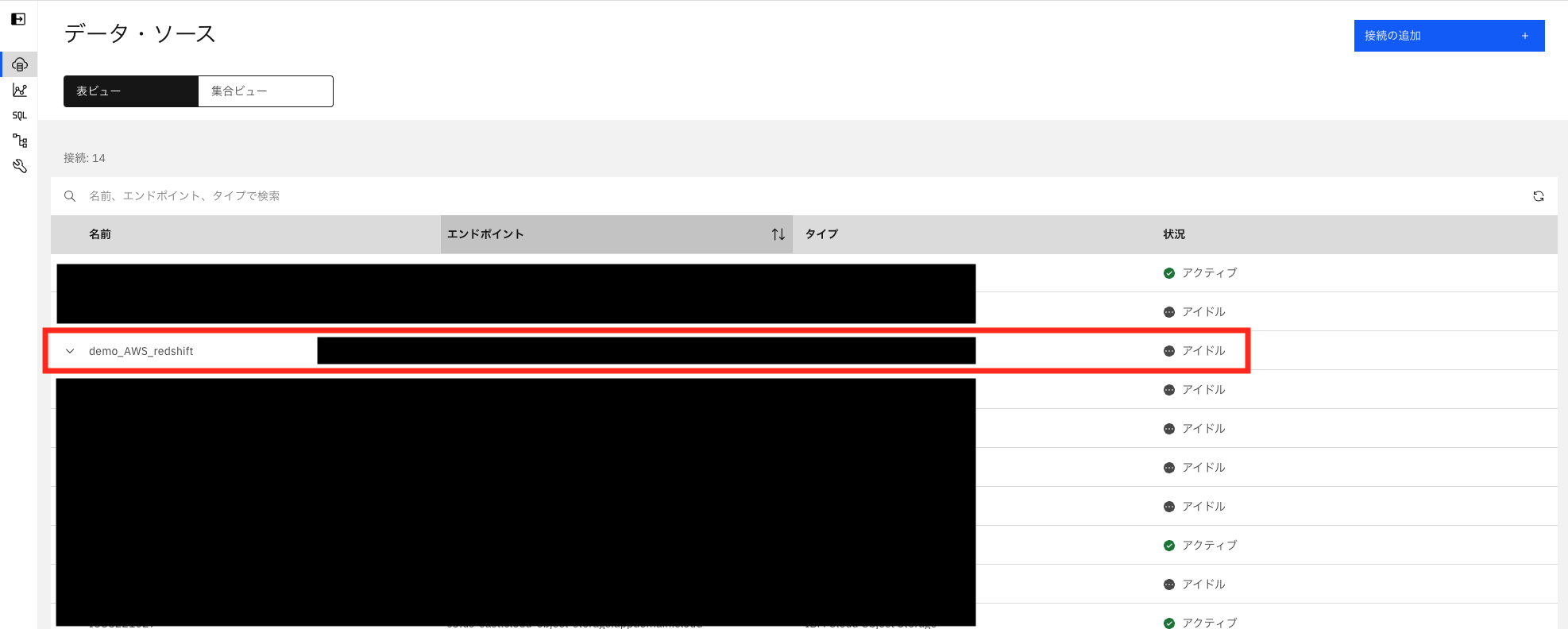
2:データ仮想化
2-1:仮想化準備
データ仮想化→仮想化へ移動します。
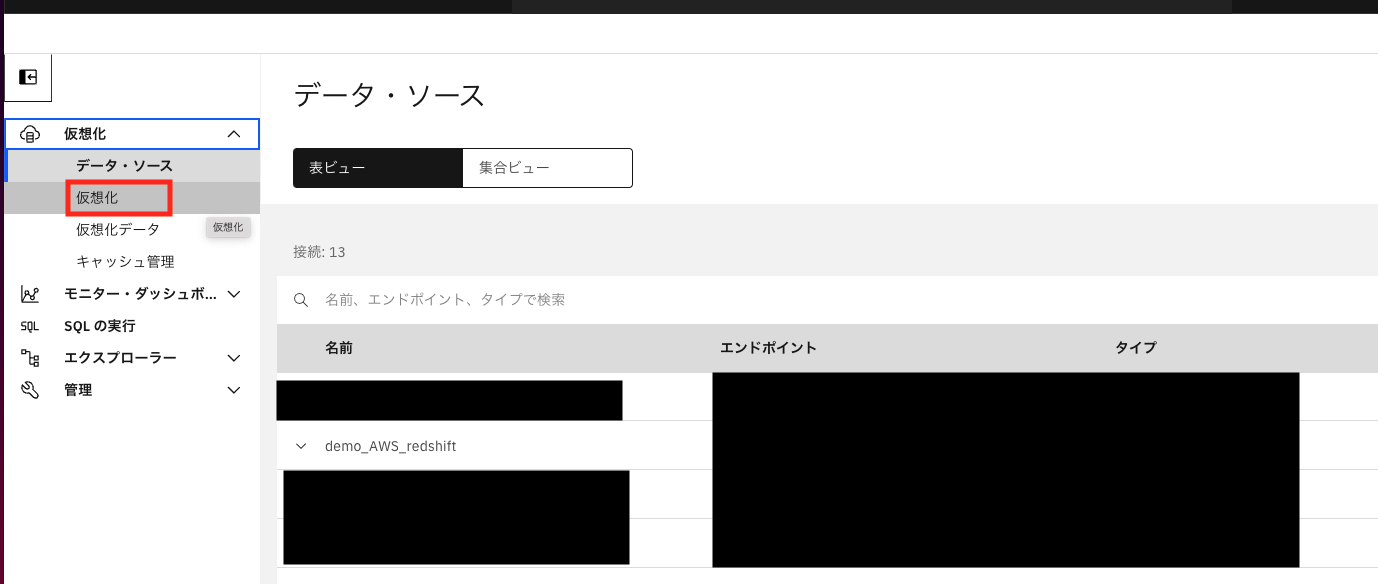
2-2:ロード
表の再ロードをタップします。

最新表示をタップします。

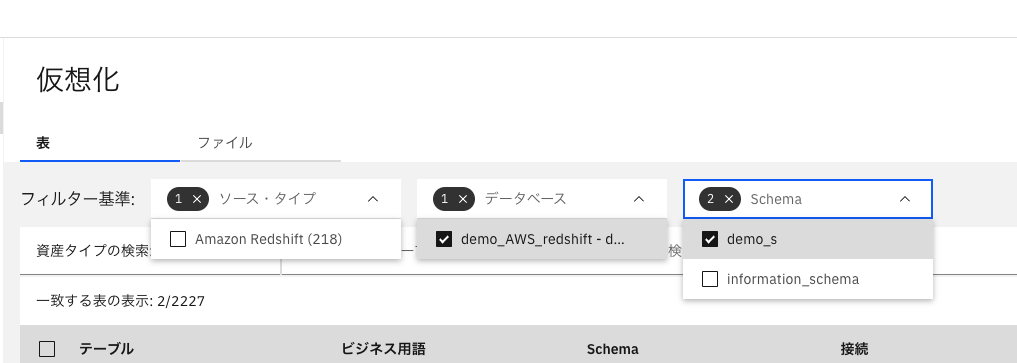
2-3:参照先の決定
ソース・タイプ:AmazonRedshift
データベース:demo_AWS_redshift(WQに接続した際に設定したデータベース名)
スキーマ:demo_s(仮想化するテーブルのスキーマ)
2-4:プレビュー
ビューマークをクリックすると、仮想化するテーブルをプレビューすることが可能です。


2-5:仮想化
仮想化するテーブルを選択して、カートに追加をタップします。

カートの表示をタップします。

必要に応じて列名を編集します。

仮想化をタップします。

仮想化が完了しました。

3:仮想化データの確認
仮想化→仮想化データに移動します。
仮想化データに先ほどのテーブルが追加されていることを確認しました。
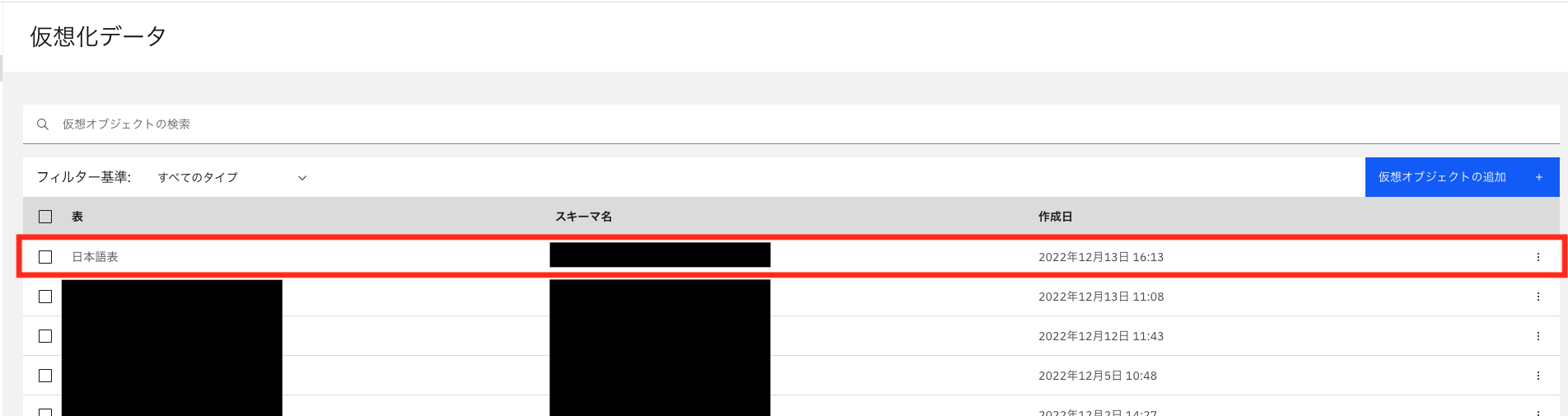
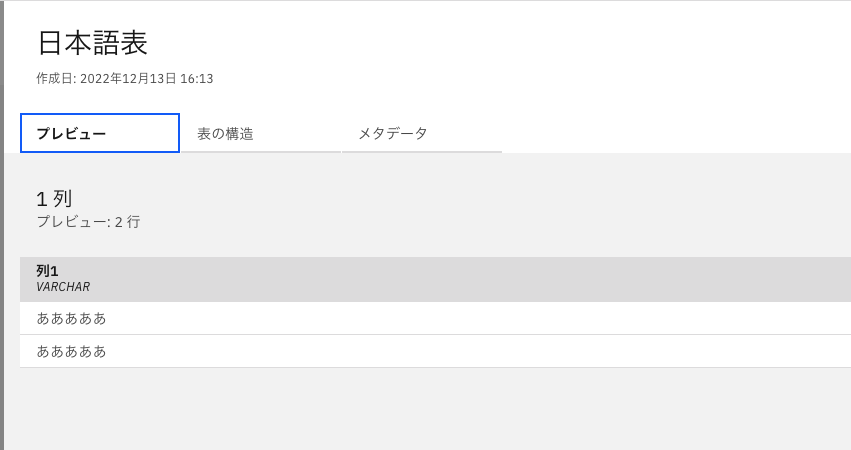
詳細の表示をタップします。

仮想化したテーブルの要素を確認することができました。
以上で、WatsonQueryにおいてRedshift Serverlessのデータを仮想化する方法の解説を終了します。