概要
- 資格取得は通過点。理論を「実務・分析・可視化」に繋げることが重要。
- 本記事では、教育関連公開データを使い、カイ二乗検定をPythonで実践しました。
- 次ステップとして、回帰分析・因果推論・モデル実装を視野に入れています。
1.はじめに
統計検定準1級を約1ヵ月半の学習期間で、最優秀成績で取得しました。

統計検定の勉強を通じて、統計学の奥深さや面白さを再認識しています。しかし、ただテキストを読み、問題を解くだけでは、せっかくの知識を実務で活かすのは難しいと感じていました。そこで、 この記事では 「資格取得は目的ではなく、実務で使えるスキルを身につけるための通過点」 と捉え、統計検定準1級で学んだ知識をPythonを使って実践的にアウトプットし、理解を深める方法を紹介します。
2.座学で得た知識を「使える」スキルに変えるには?
多くの資格試験の学習では、知識のインプットが中心となります。統計検定も同様で、さまざまな検定手法やモデルの理論を学びます。
実際のデータ分析では、どの手法を用いるべきか、まず自分で仮説を立て、それを検証する必要があります。この「理論と実践のギャップ」を埋めるために、実際に手を動かしてデータを分析することが非常に重要だと思っています。
今回は、「Student Performance in Exams」 というデータセットを使って、カイ二乗検定を実践的に行ってみました。
3.カイ二乗検定をPythonで実装してみよう
まずは、分析のテーマを決めます。今回は
「生徒のランチ(lunch)の種類と、保護者の学歴(parental level of education)には偏りがあるのか?」
という疑問をカイ二乗検定で検証してみます。
データの準備と可視化
まず、Kaggleからデータセットをダウンロードし、Looker Studioを使って可視化してみます。このステップは、データの全体像を把握し、分析の切り口を見つけるのに役立ちます。可視化することで、「ランチの種類(standard vs. free/reduced)」と「保護者の学歴」の間に何かしらの関係があるように見えるかもしれません。

可視化したデータをCSV形式でエクスポートし、Pythonで扱えるようにします。
ファイル名をlunch_education_data.csvとします。
Pythonでの実装
Pythonのpandasとscipyライブラリを使って、カイ二乗検定を実行します。
import pandas as pd
from scipy.stats import chi2_contingency
CSVファイルを読み込む
df = pd.read_csv('lunch_education_data.csv')
df
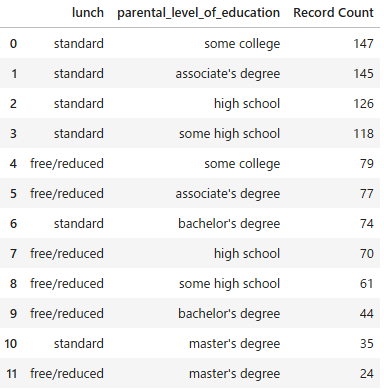
分割表(クロス集計表)を作成
contingency_table = df.pivot_table(
index='lunch',
columns='parental_level_of_education',
values='Record Count'
)
contingency_table

カイ二乗検定を実行
帰無仮説:ランチの種類と保護者の学歴には関連がない。
対立仮説:ランチの種類と保護者の学歴には関連がある。
chi2, p_value, dof, expected_freq = chi2_contingency(contingency_table)
# 結果の表示と解釈
print("\n--- カイ二乗検定の結果 ---")
print(f"カイ二乗統計量: {chi2:.4f}")
print(f"p値: {p_value:.4f}")
print(f"自由度: {dof}")
alpha = 0.05
print("\n--- 検定結果の評価 ---")
if p_value < alpha:
print(f"p値({p_value:.4f})は有意水準({alpha})より小さいです。")
print("したがって、帰無仮説を棄却します。")
print("昼食の種類と保護者の学歴の間には統計的に有意な関連性があると言えます。")
else:
print(f"p値({p_value:.4f})は有意水準({alpha})より大きいです。")
print("したがって、帰無仮説を採択します。")
print("昼食の種類と保護者の学歴の間には統計的に有意な関連性がないと言えます。")
結果の解釈
コードを実行すると、以下のような結果が出力されます。

カイ二乗統計量: 1.1113...
p値: 0.9531...
自由度: 5
今回のp値は約0.9531でした。一般的に使われる有意水準5%(=0.05)と比較すると、p値は0.05より大きいため、帰無仮説を棄却できません。
この結果から、「ランチの種類」と「保護者の学歴」には統計的に有意な関連があるとは言えない、という結論になります。もしp値が0.05を下回っていれば、「両者には何らかの関連がある」と判断できました。
このように、理論を 「どういったデータに、どういう風に使われるのか」 という形で実践することで、単なる知識としてではなく、スキルとして定着させることができます。
4.まとめ:実践こそが学びを深める鍵
統計検定準1級の学習は、実務でデータサイエンスに取り組むための強固な土台を築いてくれます。しかし、その知識を本当に自分のものにするには、 「理論→実践→考察」 というサイクルを繰り返すことが不可欠です。
今回はカイ二乗検定を例に挙げましたが、t検定や分散分析、回帰分析など、統計検定で学んだ様々な手法を、様々なデータセットで試していきます。
資格の学習経験を基盤に、今後は教育データ分析を「ユーザー価値の創出」や「プロダクト実装」に結びつけるフェーズへ進みたいと考えています。
資格取得は決してゴールではありません。今回の記事が、皆さんのデータ分析スキルをさらに高めるきっかけとなれば幸いです。一緒に楽しみながら、統計学の世界を深めていきましょう!