概要
- 目的:教育資料を自由に検索・活用できるチャットボットを自作し、資料探索のハードルを下げる
- 技術:RAG (PDF検索+LLM) + FastAPI + Streamlit で構築。教育データを題材に実装。
- 学び:既存資料の“構造化されていない表形式”がRAG実装で障壁となることを発見し、前処理パイプラインの必要性を確認。
1.はじめに
最近、私の職場で 校内サーバーにある資料をAIに質問できるチャットボットが導入されました。
文章を入力すると、AIが過去資料を検索して答えてくれるという仕組みで、
「うわ、これめっちゃ便利!どうやって作ってるんだろ?」
「自分でも作ってみたい!」
と強い刺激を受けました。
チャットボットに「あなたはどうやって作られているの?」と聞いても、答えは返ってきませんでした。
そこで、「調べるより作ったほうが早い」と思い立ち、生成AI周りの構築に挑戦しました。
この記事が、「自分もRAGやってみようかな」という方の背中を押せたら嬉しいです!
コード:
2.作ったもの
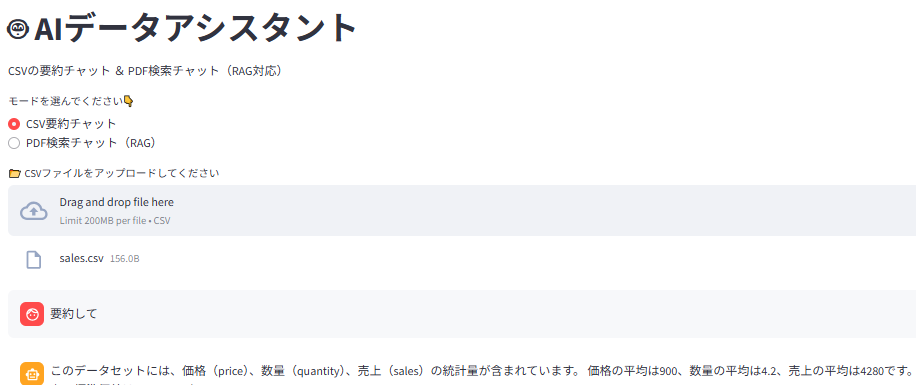
① CSV要約チャット:CSVファイルを投げて「平均出して」「ランキング作って」と質問できる Streamlit + OpenAI
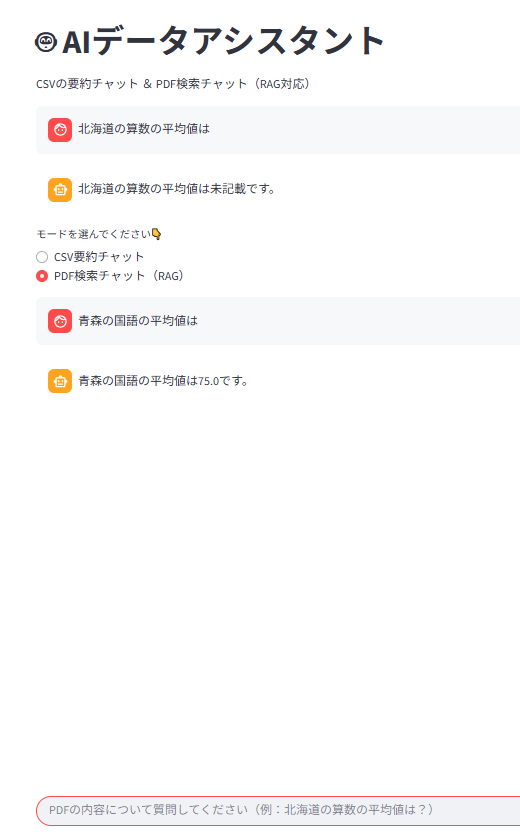
② PDF検索チャット(RAG):ローカルにPDFを読み込ませて、質問すると該当箇所を検索+LLMが回答 FastAPI + LangChain + FAISS + Streamlit
3.システムの全体像(アーキテクチャ)
4.PDF検索
職場では校内サーバーの資料を使っていますが、今回は公開されている
文部科学省の「全国学力・学習状況調査」の結果PDFを題材にしました。
ただし、PDFの内容がほぼ全部「表形式」だったため……数値+枠線が含まれている
行と列の意味が構造として失われてしまう
5.作ってみてわかった「うまくいった点・難しかった点」
・CSV要約チャットはとても実用的で、簡易データ分析に使える
・表形式PDFをそのままRAGに突っ込むのは厳しい(構造が潰れる)
→ 対処案PDF→HTML変換などで表ごと抽出すべき
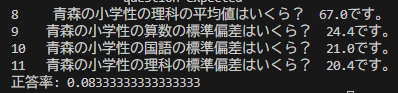
・ 評価方法 expected in answer で部分一致判定 → ざっくり精度チェック
6.今後やってみたいこと
・クラウドでの生成AI周り、機械学習の活用、Azure / GCPにデプロイ
・MLflowで回答の記録・評価を自動化
・表形式PDF向けの前処理パイプライン作り
7.「機械学習エンジニアに必要な視点」
私はこれまで「モデルの勉強=機械学習エンジニアの道」だと思っていました。
しかし今回、
モデルを動かす前の「データの流れ」や
サービスとして使えるようにする「仕組みの設計」こそ重要
だと強く感じました。
今後の施策
今後はこのチャットボットの構成を教育プラットフォームと連携し、教師・生徒双方の“資料検索時間”を削減するサービスに展開したいと考えています。
クラウド(GCP/Azure)へのデプロイ、MLflowによる評価ログの可視化、自動化されたモニタリング設計も検討中です。