IoTとクラウド障害
IoT関係サービスはクラウド上にシステムが構築されている事が多く、
11月25日のAWS障害では、NatureRemoやSwitchBotなどのIoTサービスが軒並み停止してしまいました。
我が家もNatureRemoが完全停止し、「アレクサ電気消して!」を連呼しても電気が消えず、センサデータ取得システムでもRemoのデータが取得できなくなる等、なかなかのダメージを受けてしまいました‥
このような障害は早く気づくほどダメージを最小限に抑えられるので、
この機に以前から作りかけだった、稼働管理システムを作成してみました。
AWS障害時のデータに本システムを適用したところ、しっかり障害を自動検知&メール送信することができました!

本記事はRaspberryPiでの運用を前提にしておりますが、考え方自体は、あらゆるIoT製品に応用できるかと思います。
どう稼働を管理する?
下記の手順で管理すべき項目を明確化します(要件定義)
・管理対象のシステムを把握
・管理システムの位置づけを定義
・管理項目を具体化
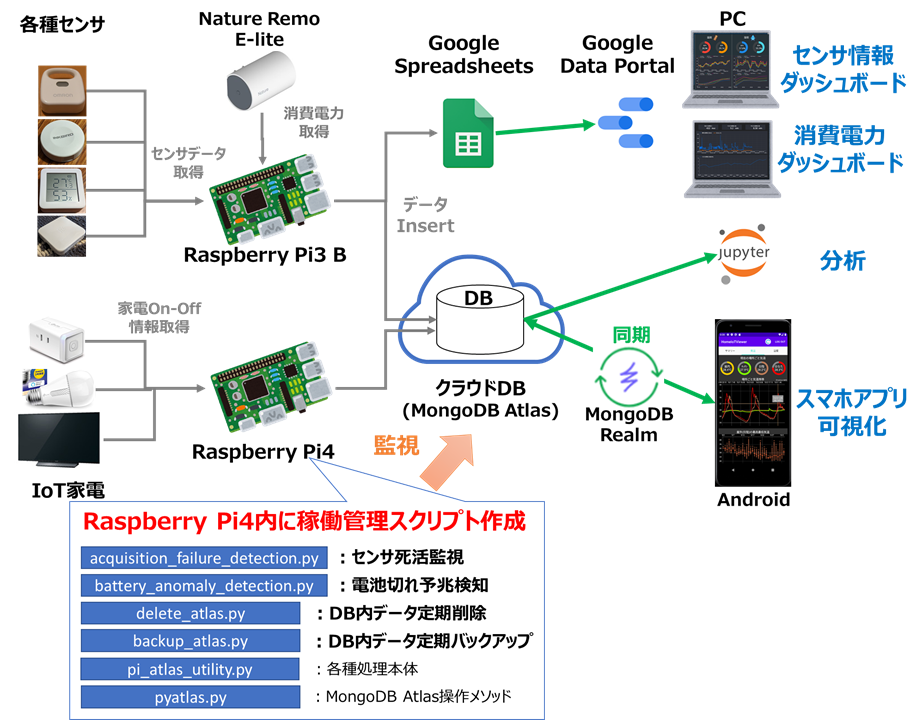
管理対象のシステム
わが家では下図のようなIoTシステムを構築しており、各種センサやIoT家電からのデータをクラウドDB(MongoDB Atlas)に集約しています。
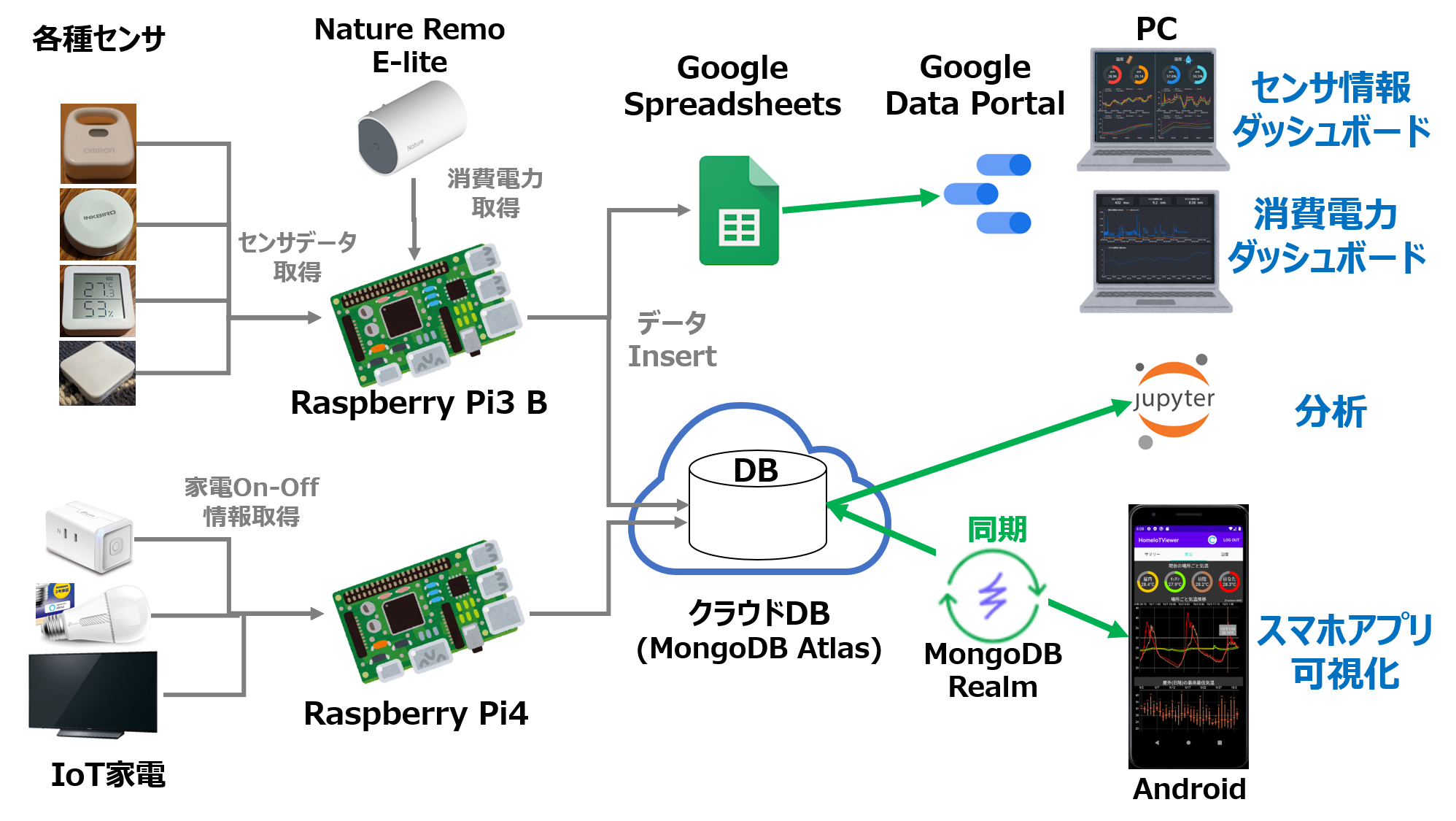
システム内各機能の詳細
各部の動作に関しては別途記事を作成しているので、下記リンクを参照ください
・センサデータ取得とセンサ情報ダッシュボード
・クラウドDBとスマホアプリ
・消費電力取得
・家電On-Off情報取得
管理システムの位置づけ
各エッジ(センサ、家電等)で取得したデータはクラウドDBに集約されるので、クラウドDB上に取得したデータが存在するかでエッジの稼働を判定します。
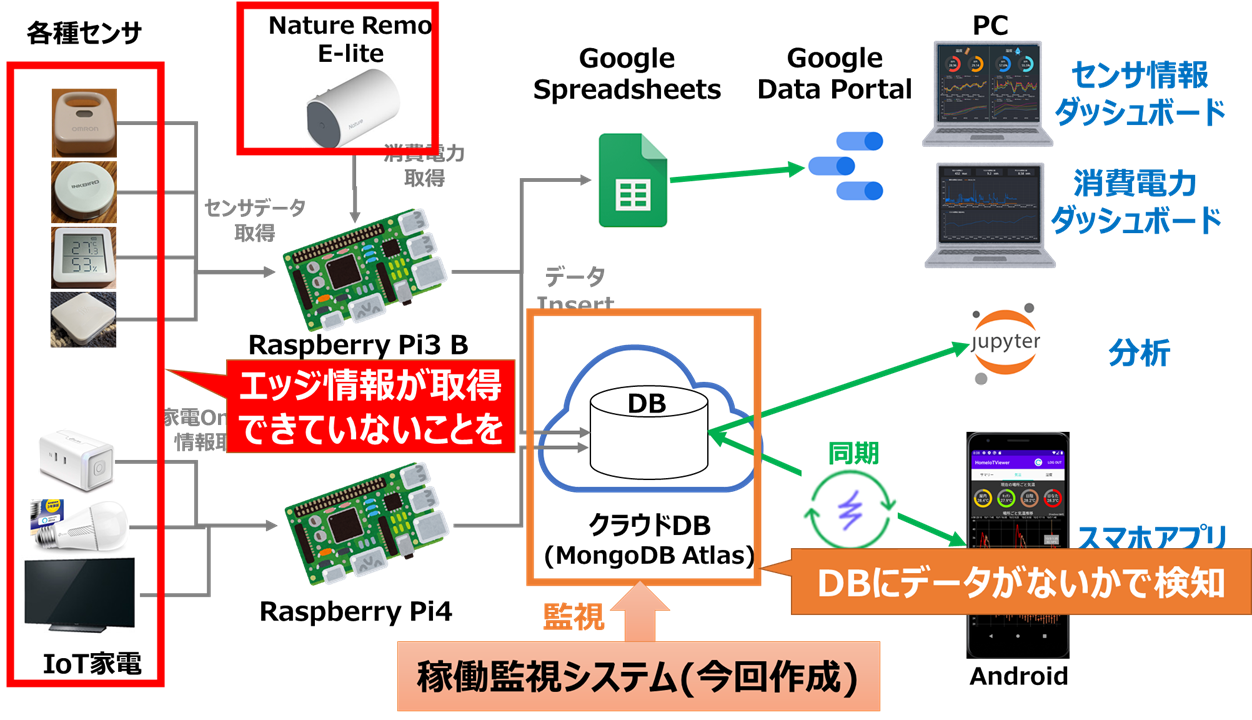
途中のRaspberryPiや通信経路が故障する場合もありますが、その場合接続されたセンサ全てのデータがクラウド上にアップロードされないので、ここからRaspberryPiの死活を判断することもできます。
また、RaspberryPi上で障害を検知しただけでは管理者(私)に何の情報も伝わらないので、
障害検知時はメールで通知する
という機能も追加します。
これでスマホさえ持っていれば、障害発生に気づくことができますね!
管理項目を具体化
どのような項目を管理・監視の対象とするか明確化します
管理項目の決め方
IT業界では、システムの評価指標として、「RAS」(あるいはこれを拡張したRASIS)と呼ばれる下記3指標がよく使われています。
信頼性(Reliability):故障の起きにくさ(平均故障間隔MTBFに依存)
可用性(Availability):稼働率の高さ(平均故障間隔MTBF&平均修復時間MTTRに依存)
保守性(Serviceability):メンテナンスの容易さ
この中で稼働管理により主に改善できるのは、可用性となります。
「早く気づいて早く直すことで、平均修復時間MTTRを短くする」
といったイメージです。
そこで、IoTシステムの**「障害に早く気付く」という観点で、管理項目を選定しました。
理想は「発生前に気付いて直す」**ことなので、これにつながる項目も追加します。
選定した管理項目
1. 死活監視:データがアップロードされていないことを検知&メール通知し、障害に早く気づく
2. 電池切れ予兆検知:電池切れの予兆を検知&メール通知し、発生前に気づく
3. データ定期削除:DB内の古いデータを定期的に削除し、容量オーバーによる障害発生を防ぐ
4. データ定期バックアップ:上記削除される前にデータをローカルにバックアップする
詳細は次章で解説します
(3,4はMTTRよりMTBFに効く項目ですが、継続稼働に必要な機能と考え追加しております)
設計と実装
上記管理項目を実現するためのシステムを、設計・実装します
各管理項目の実施法設計
1. 死活監視
普通「死活監視」といえば、pingを送って応答を見る、という方法が定番ですが、
IoTにおいては応答よりもデータを取得できている事が重要なので、
クラウドDB上に、該当センサのデータがアップロードされているか確認
という方法をとります。
具体的には
「DB上に過去30分以内の該当センサのデータが1個も存在しない場合、異常と判定しメール通知する」という処理を、1時間ごとに定期実行する
という処理を実装します。
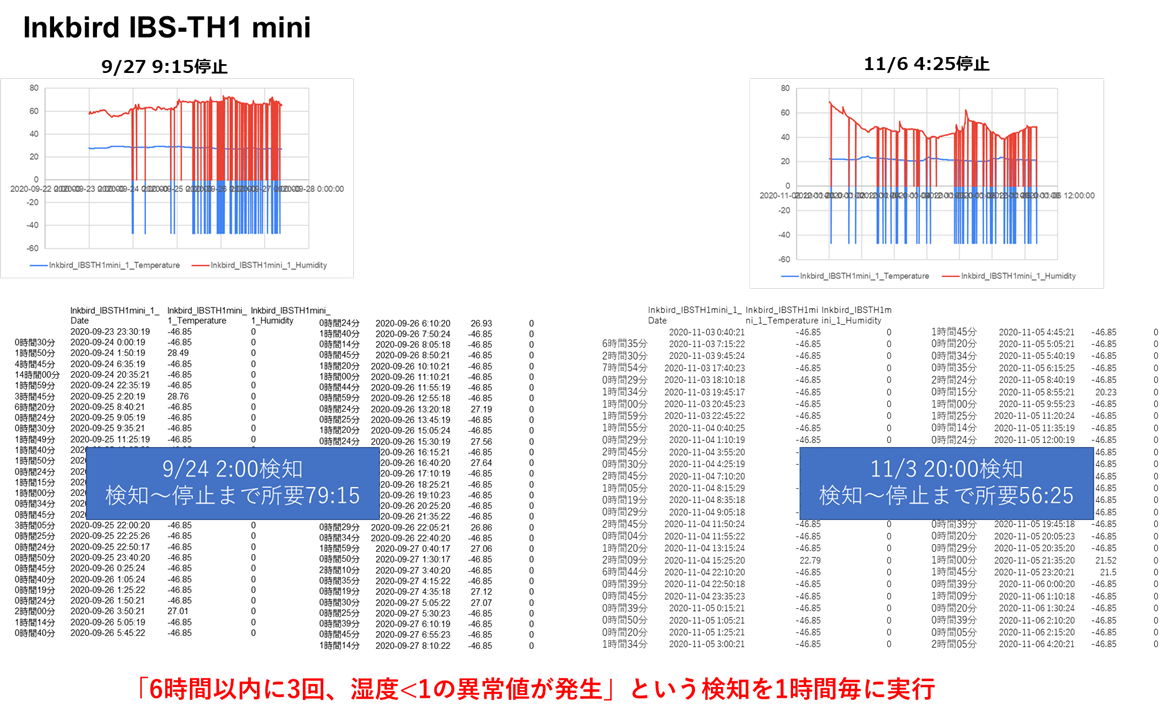
2. 電池切れ予兆検知
過去の記事で触れましたが、使用している一部のセンサ(IBS-TH1miniおよびOmron BAG型)は、電池切れの数日前から異常値を吐き出す性質があります。
今回はこの性質を利用して、電池切れを事前に検知する仕組みを構築します。
それぞれのセンサの過去の電池切れ直前データを分析し、下記のアルゴリズムで検知することとしました
IBS-TH1 mini
Omron BAG型
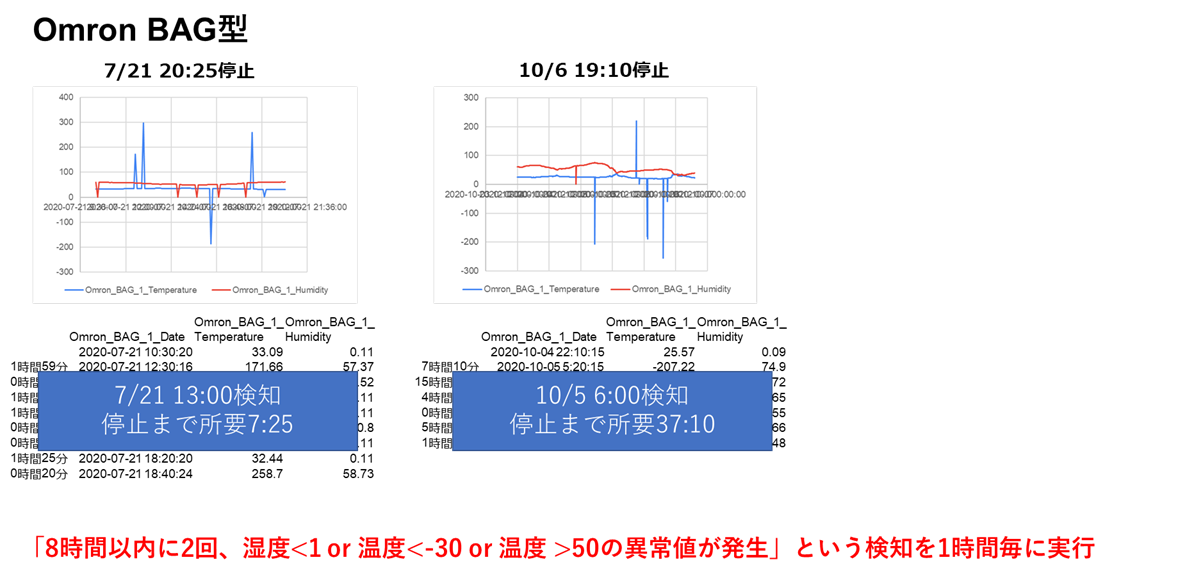
本システムでは、
「上記アルゴリズムで異常値を検知した場合、電池切れ予兆と判定しメール通知する」という処理を、1時間ごとに実行する
という処理を実装します。
3. データ定期削除
使用しているクラウドDB(MongoDB Atlas)には無料枠の上限容量500MBが定められており、
無対策では半年ほどでこの上限に達してシステムが停止してしまいます。
このようなデータ容量オーバーによるシステム障害は、クラウドに限らずありがち(そして忘れた頃に発生するのでたちが悪い)なパターンのため、
古いデータを定期的に自動削除する
という機能を実現したいです。
クラウドDBと同期しているスマホアプリは最新1ヵ月分のデータのみ使用するので、少し余裕を見て
「DB内の40日以上前のデータを削除する」という処理を、3日ごとに定期実行する
という処理を実装します。
4. データ定期バックアップ
「3.データ定期削除」でDB上から削除されたデータは、何もしなければ永久に失われてしまいます。
そこで、こうなる前に定期的にDB上のデータをローカルにバックアップし、データが残るようにします。
具体的には、
「DB内の前月1ヵ月分のデータをRaspberryPi上のストレージにCSV保存する」という処理を、毎月1,4,7日に実行する
という処理を実装します。
(3回実行しているのは、何らかの理由で1回目のバックアップに失敗したときの予備です)
実装
上記1~4の機能を実現するため、RaspberryPi内に下図のようなスクリプトを作成しました。
スクリプト構成
下記のスクリプトおよび設定ファイルからなります
acquisition_failure_detection.py:1. 死活監視
battery_anomaly_detection.py:2. 電池切れ予兆検知
delete_atlas.py:3. データ定期削除
backup_atlas.py:4. データ定期バックアップ
pi_atlas_utility.py:上記1~4の処理本体を記述
pyatlas.py:MongoDB Atlasでよく使う機能をメソッド化し、集めたクラス
config.ini:稼働管理システム全体の設定ファイル
acquisition_detection_list.csv:「1.死活監視」のセンサごと設定保持用ファイル
battery_detection_list.csv:「2.電池切れ予兆検知」のセンサごと設定保持用ファイル
上記スクリプトはGitHubにもアップロードしています。
各スクリプトの詳細は後述します
acquisition_failure_detection.py
「1.死活監視」のスクリプト本体です。
処理の中身はpi_atlas_utility.pyに全て記述しており、それをただ呼び出すだけです
from pi_atlas_utility import PiAtlasUtility
if __name__ == '__main__':
pi_atlas_utility = PiAtlasUtility()
pi_atlas_utility.run('Acquisition')
battery_anomaly_detection.py
「2.電池切れ予兆検知」のスクリプト本体です。
処理の中身はpi_atlas_utility.pyに全て記述しており、それをただ呼び出すだけです
from pi_atlas_utility import PiAtlasUtility
if __name__ == '__main__':
pi_atlas_utility = PiAtlasUtility()
pi_atlas_utility.run('Battery')
delete_atlas.py
「3.データ定期削除」のスクリプト本体です。
処理の中身はpi_atlas_utility.pyに全て記述しており、それをただ呼び出すだけです
from pi_atlas_utility import PiAtlasUtility
if __name__ == '__main__':
pi_atlas_utility = PiAtlasUtility()
pi_atlas_utility.run('Delete')
backup_atlas.py
「4.データ定期バックアップ」のスクリプト本体です。
処理の中身はpi_atlas_utility.pyに全て記述しており、それをただ呼び出すだけです
from pi_atlas_utility import PiAtlasUtility
if __name__ == '__main__':
pi_atlas_utility = PiAtlasUtility()
pi_atlas_utility.run('Backup')
pi_atlas_utility.py
上記1~4の中身を記述したクラスです。
1~4の処理には共通している部分が多いため、これらをまとめてクラス化しました。
詳細は省きますが、各メソッドはそれぞれ下記のような機能を持ちます
run():メイン処理(上記1~4のスクリプトから処理名process_nameを指定して呼び出す)
_ run_process():上記1~4の分岐判定を行い、DBのコレクションごとに実行するメソッド
_ acquisition_anomaly_detection():「1.死活監視アルゴリズム」を実行するメソッド
_ battery_anomaly_detection():「2.電池切れ予兆検知アルゴリズム」を実行するメソッド
_ send_email():1,2で障害検知時に結果をメール送信するメソッド(参考)
_ make_detection_log():検知ログを作成するメソッド
_ confirm_mail_sent():規定時間以内にメールが送られたか確認するメソッド
※_make_detection_log()および_confirm_mail_sent()ですが、検知は1時間に1度実施されるので、検知の度にメールが送信されてしまうとメールの件数が増えて情報過多となってしまうため、メールの最短送信間隔(設定ファイルで指定)を制御するために設けたメソッドとなります。
(検知ログを見て最短送信間隔以内にメールが送信されていないか確認)
from pyatlas import AtlasClient
from datetime import datetime, timedelta
import configparser
import pandas as pd
import numpy as np
import logging
from pit import Pit
import ast
import os
import csv
from email import message
import smtplib
# 処理名一覧
BACKUP_PROCESS_NAME = 'Backup'
DELETE_PROCESS_NAME = 'Delete'
BATTERY_PROCESS_NAME = 'Battery'
ACQUISITION_PROCESS_NAME = 'Acquisition'
PROCESS_NAME_LIST = [BACKUP_PROCESS_NAME, DELETE_PROCESS_NAME, BATTERY_PROCESS_NAME, ACQUISITION_PROCESS_NAME]
MAIL_PROCESS_NAMES = [BATTERY_PROCESS_NAME, ACQUISITION_PROCESS_NAME]#検知ログ作成&メール送信対象処理
class PiAtlasUtility():
#初期化
def __init__(self, masterdate = datetime.today()):
self.masterdate = masterdate # 処理開始時刻
self.backup_dir = None # バックアップ処理時の、バックアップ先ディレクトリ
self.process_name = None # 実行する処理の名前
self.delete_day = None # 削除処理時、この日時よりも前のデータを削除する
self.battery_collection_name = None # 電池切れ予兆検知対象のコレクション名
self.battery_detection_list = None # 電池切れ予兆検知対象のセンサリスト
self.acquisition_detection_list = None # センサ未取得検知対象のセンサリスト
self.detection_output = None # 検知ログの出力先
self.mail_period = None # メール送信最短間隔
self.smtp_host = None #メールホスト
self.smtp_port = None # メールポート
self.from_email = None # 送信元メールアドレス
self.to_email = None # 送信先メールアドレス
self.username = None # メールユーザ名
self.password = None # メールパスワード
#電池切れ予兆検知
def _battery_anomaly_detection(self, atlasclient, collection_name):
#予兆検知デバイスリストを走査
for device in self.battery_detection_list.itertuples():
#判定対象列名
colname1 = f"no{format(device.No,'02d')}_{device.ColName1}"
colname2 = f"no{format(device.No,'02d')}_{device.ColName2}"
proj = {"Date_Master":1, colname1:1, colname2:1}
#現在時刻からPeriod時間前以降の判定対象列データを取得
startdate = self.masterdate - timedelta(hours=device.Period)
flt = {"Date_Master":{"$gte":startdate}}
df = atlasclient.get_collection_to_df(collection_name, filter=flt, projection=proj)
#判定対象列1,2に関して、閾値上下限のいずれかをオーバーしたデータを取得
if colname1 in df.columns:
if colname2 in df.columns:
df_anomaly = df[(df[colname1] < device.LowerThreshold1) | (df[colname1] > device.UpperThreshold1) | (df[colname2] < device.LowerThreshold2) | (df[colname2] > device.UpperThreshold2)]
else:
df_anomaly = df[(df[colname1] < device.LowerThreshold1) | (df[colname1] > device.UpperThreshold1)]
else:
if colname2 in df.columns:
df_anomaly = df[(df[colname2] < device.LowerThreshold2) | (df[colname2] > device.UpperThreshold2)]
else:
logging.warning(f'colname in battery_detection_list.csv is invalid [device {device.DeviceName}, date{str(self.masterdate)}]')
continue
#上下限オーバーしたデータ数がCount以上のとき、電池切れ予兆発生判定
if len(df_anomaly) >= device.Count:
#メールのタイトル
mail_title = f'BATTERY ANOMALY [{device.DeviceName}, {self.masterdate.strftime("%Y/%m/%d %H:%M:%S")}]'
logging.info(mail_title)
#メールの本文
mail_message = f'BATTERY ANOMALY DETECTION\n'\
f'device {device.DeviceName}\n'\
f'date {str(self.masterdate)}]'
mail_message = mail_message + '\n\n' + str(df_anomaly.drop(['_id'], axis=1).reset_index(drop=True))
#一定時間内にメール送信されたか確認し、Falseならメール送信+検知ログ書込、Trueなら検知ログ書込のみ実施
if self._confirm_mail_sent(device.DeviceName):
self._make_detection_log(device.DeviceName, False)
else:
self._make_detection_log(device.DeviceName, True)
self._send_email(mail_title, mail_message)
#センサ未取得検知
def _acquisition_anomaly_detection(self, atlasclient, collection_name):
#センサ未取得検知デバイスリストから
detection_list = self.acquisition_detection_list[self.acquisition_detection_list['CollectionName'] == collection_name]
#現在時刻からFailureMinuteの最大分前以降の判定対象列データを取得
max_failure_minutes = int(detection_list['FailureMinutes'].max())
startdate = self.masterdate - timedelta(minutes=max_failure_minutes)
flt = {"Date_Master":{"$gte":startdate}}
df = atlasclient.get_collection_to_df(collection_name, filter=flt)
#センサ未取得検知デバイスリストを走査
for device in detection_list.itertuples():
#判定対象列名
colname = f"no{format(device.No,'02d')}_{device.ColName}"
# 判定対象列が存在するとき、判定対象列の取得成功数をカウント
if colname in df.columns:
#FailureMinutes以降のデータのみ抽出
device_start = self.masterdate - timedelta(minutes=device.FailureMinutes)
df_device = df[df['Date_Master'] >= device_start][["Date_Master",colname]]
#取得成功数カウント
acquisition_num = df_device[colname].count()
# 判定対象列が存在しない時、取得成功数を0とする
else:
acquisition_num = 0
df_device = None
# 取得成功数=0のとき、
if acquisition_num == 0:
#メールのタイトル
mail_title = f'ACQUISITION FAILURE [{device.DeviceName}, {self.masterdate.strftime("%Y/%m/%d %H:%M:%S")}]'
logging.info(mail_title)
#メールの本文
mail_message = f'ACQUISITION FAILURE DETECTION\n'\
f'device {device.DeviceName}\n'\
f'date {str(self.masterdate)}]'
# 判定対象列が存在するとき、本文にDataFrame内容を記載
if colname in df.columns:
mail_message = mail_message + '\n\n' + str(df_device.reset_index(drop=True))
#一定時間内にメール送信されたか確認し、Falseならメール送信+検知ログ書込、Trueなら検知ログ書込のみ実施
if self._confirm_mail_sent(device.DeviceName):
self._make_detection_log(device.DeviceName, False)
else:
self._make_detection_log(device.DeviceName, True)
self._send_email(mail_title, mail_message)
# 検知ログの作成
def _make_detection_log(self, device_name, send_email):
#出力するデータ
output_dict = {'Date_Master':str(self.masterdate.strftime("%Y/%m/%d %H:%M:%S")),
'Device_Name': device_name,
'Send_Email': send_email}
#検知ログのパス
outpath = f'{self.detection_output}/{self.process_name}DetectionLog_{self.masterdate.year}.csv'
#検知ログ存在しないとき、新たに作成
if not os.path.exists(outpath):
with open(outpath, 'w', newline="") as f:
writer = csv.DictWriter(f, output_dict.keys())
writer.writeheader()
writer.writerow(output_dict)
#検知ログ存在するとき、1行追加
else:
with open(outpath, 'a', newline="") as f:
writer = csv.DictWriter(f, output_dict.keys())
writer.writerow(output_dict)
# 規定時間以内にメールが送られたか確認
def _confirm_mail_sent(self, device_name):
#検知ログのパス
detection_path = f'{self.detection_output}/{self.process_name}DetectionLog_{self.masterdate.year}.csv'
#検知ログ存在しないとき、false
if not os.path.exists(detection_path):
return False
#検知ログ存在するとき、規定時間以内にメールが送られたか確認
else:
df_detection = pd.read_csv(detection_path, parse_dates=['Date_Master'])
last_mail_date = df_detection[df_detection['Device_Name'] == device_name]['Date_Master'].max()
if last_mail_date > self.masterdate - timedelta(hours=self.mail_period):
return True
else:
return False
#メール送信(https://qiita.com/aj2727/items/81e5d67cbcbf7396e392)
def _send_email(self, mail_title, mail_message):
msg = message.EmailMessage()
msg.set_content(mail_message)
msg['Subject'] = mail_title
msg['From'] = self.from_email
msg['To'] = self.to_email
server = smtplib.SMTP(self.smtp_host, self.smtp_port)
server.ehlo()
server.starttls()
server.ehlo()
server.login(self.username, self.password)
server.send_message(msg)
server.quit()
#処理本体を実行
def _run_process(self, user_name, cluster_name, db_name, collection_name, retry):
pa = Pit.get('atlas')[':pa']
num = Pit.get('atlas')[':num']
pad = ''.join([chr(ord(a) + num + 5) for a in pa])
for i in range(retry):
try:
atlasclient = AtlasClient(user_name=user_name, cluster_name=cluster_name, db_name=db_name, password=pad)
#バックアップ処理
if self.process_name == BACKUP_PROCESS_NAME:
atlasclient.backup_previous_month(collection_name, "Date_Master", datetime.now(), self.backup_dir)
#一定日以上前のデータを削除
elif self.process_name == DELETE_PROCESS_NAME:
atlasclient.delete_previous_data(collection_name, "Date_Master", self.delete_day)
#電池切れ予兆検知(異常温湿度)
elif self.process_name == BATTERY_PROCESS_NAME and collection_name == self.battery_collection_name:
self._battery_anomaly_detection(atlasclient, collection_name)
#センサ未取得検知
elif self.process_name == ACQUISITION_PROCESS_NAME and collection_name in self.acquisition_detection_list['CollectionName'].unique().tolist():
self._acquisition_anomaly_detection(atlasclient, collection_name)
#処理成功をログ出力
logging.info(f'sucess to {self.process_name} DB [collection {collection_name}, date{str(self.masterdate)}')
#エラー出たらログ出力
except:
if i == retry - 1:
logging.error(f'cannot {self.process_name} DB [collection {collection_name}, date{str(self.masterdate)}, loop{str(i)}]')
else:
logging.warning(f'retry to {self.process_name} DB [collection {collection_name}, date{str(self.masterdate)}, loop{str(i)}]')
continue
else:
break
######処理実行######
def run(self, process_name):
#処理名を更新
self.process_name = process_name
#渡した処理名が一覧に含まれない場合、エラーを投げる
if process_name not in PROCESS_NAME_LIST:
raise ValueError('process_name is invalid')
#設定ファイル読込
cfg = configparser.ConfigParser()
cfg.read('./config.ini', encoding='utf-8')
backup_dirs = ast.literal_eval(cfg['Path']['BackupDirs'])
log_output = cfg['Path'][f'{self.process_name}LogOutput']
retry = int(cfg['Retry'][f'{self.process_name}Retry'])
user_name = cfg['DB']['UserName']
cluster_name = cfg['DB']['ClusterName']
db_name = cfg['DB']['DBName']
collection_names = ast.literal_eval(cfg['DB']['CollectionNames'])
self.battery_collection_name = cfg['DB']['BatteryCollectionName']
delete_days = ast.literal_eval(cfg['Date']['DeleteDays'])
#電池切れ予兆検知リスト読込
self.battery_detection_list = pd.read_csv('./battery_detection_list.csv')
#センサ未取得検知リスト読込
self.acquisition_detection_list = pd.read_csv('./acquisition_detection_list.csv')
#ログ出力ディレクトリ存在しなければ作成
if not os.path.exists(log_output):
os.makedirs(log_output)
#ログの初期化
logname = f"/Atlas{self.process_name}Log_{str(self.masterdate.strftime('%y%m%d'))}.log"
logging.basicConfig(filename=log_output + logname, level=logging.INFO)
#メール送信&検知ログ出力対象処理のとき
if self.process_name in MAIL_PROCESS_NAMES:
self.mail_period = int(cfg['Date'][f'{self.process_name}MailPeriod'])#メール送信最短間隔
self.smtp_host = cfg['Mail']['SmtpHost'] #メールホスト
self.smtp_port = int(cfg['Mail']['SmtpPort']) # メールポート
self.from_email = cfg['Mail']['FromEmail'] # 送信元メールアドレス
self.to_email = cfg['Mail']['ToEmail'] # 送信先メールアドレス
self.username = cfg['Mail']['UserName'] # メールユーザ名
self.password = cfg['Mail']['Password'] # メールパスワード
self.detection_output = cfg['Path'][f'{self.process_name}DetectionOutput']#検知ログ出力先
if not os.path.exists(self.detection_output): # 出力ディレクトリ存在しなければ作成
os.makedirs(self.detection_output)
#コレクション(テーブル)を走査
for k in collection_names.keys():
collection_name = collection_names[k]
try:
self.backup_dir = backup_dirs[k]
self.delete_day = delete_days[k]
except:
logging.error(f'keys in config.ini is invalid')
exit()
self._run_process(user_name, cluster_name, db_name, collection_name, retry)
pyatlas.py
MongoDB Atlasでよく使う機能をメソッド化し、集めたクラスです。
各メソッドの内容はコード中のコメントを参照ください(使用ライブラリpymongo参考)
import pymongo
import pandas as pd
from datetime import datetime, timedelta
from dateutil.relativedelta import relativedelta
class AtlasClient():
#初期化
def __init__(self, user_name, cluster_name, db_name, password):
self.user_name = user_name
self.db_name = db_name
self.password = password
self.client = pymongo.MongoClient(f"mongodb+srv://{user_name}:{password}@{cluster_name}.jipvx.mongodb.net/{db_name}?retryWrites=true&w=majority")
#コレクション内容を取得してpd.DataFrameに格納
#filter, projectionはこちら参照https://qiita.com/rsm223_rip/items/141eb146ad610215e5f7#%E6%A4%9C%E7%B4%A2%E6%96%B9%E6%B3%95
def get_collection_to_df(self, collection_name, filter=None, projection=None):
collection = self.client[self.db_name][collection_name]
cursor = collection.find(filter=filter, projection=projection)
df = pd.DataFrame(list(cursor))
return df
#前月データをCSV保存
def backup_previous_month(self, collection_name, date_column, ref_time, output_dir):
prev_month = ref_time - relativedelta(months=1)
startdate = prev_month.replace(day=1, hour=0, minute=0, second=0, microsecond=0)
enddate = ref_time.replace(day=1, hour=0, minute=0, second=0, microsecond=0)
flt = {date_column:{"$gte":startdate, "$lt":enddate}}
df = self.get_collection_to_df(collection_name, filter=flt)
df.to_csv(f'{output_dir}/{startdate.strftime("%Y%m")}.csv', index=False)
#コレクションを全て削除
def drop_collection(self, collection_name):
self.client[self.db_name][collection_name].remove()
#コレクションからフィルタ条件で削除
def delete_collection_data(self, collection_name, del_filter):
collection = self.client[self.db_name][collection_name]
collection.delete_many(del_filter)
#コレクションから一定日以上前のデータを削除
def delete_previous_data(self, collection_name, date_column, delete_days):
del_end = datetime.now() - timedelta(days=delete_days)
del_filter = {date_column:{"$lt":del_end}}
self.delete_collection_data(collection_name, del_filter)
config.ini
稼働管理システム全体の設定ファイルです。
各セクションで設定する内容を下記します。
[Path]セクション:バックアップ先(コレクション毎に連想配列で指定)、ログ出力先、検知結果の出力先等のディレクトリパスを指定する
[Retry]セクション:各処理失敗時のリトライ回数指定
[DB]セクション:クラウドDB(MongoDB Atlas)関係の情報を指定する
[Date]セクション:各種日数指定(DeleteDaysは何日前以前のデータを定期削除するか、BatteryMailPeriod およびAcquisitionMailPeriodはメール通知の最短送信間隔を何時間とするかを指定)
[Mail]セクション:メールアカウント関係の情報を指定する(参考)
[Path]
BackupDirs = {"Sensor":"/mnt/share/Data/Atlas_Backup/Sensor","Appliance":"/mnt/share/Data/Atlas_Backup/Appliance"}
BackupLogOutput = /mnt/share/Log/Atlas_Backup/
DeleteLogOutput = /mnt/share/Log/Atlas_Delete/
BatteryLogOutput = /mnt/share/Log/Battery_Anomaly/
AcquisitionLogOutput = /mnt/share/Log/Acquisition_Failure/
BatteryDetectionOutput = /mnt/share/Detection/Battery_Anomaly/
AcquisitionDetectionOutput = /mnt/share/Detection/Acquisition_Failure/
[Retry]
BackupRetry = 2
DeleteRetry = 2
BatteryRetry = 2
AcquisitionRetry = 2
[DB]
UserName = [MongoDB Atlasのユーザ名を記載]
ClusterName = [MongoDB Atlasのクラスタ名を記載]
DBName = [MongoDB AtlasのDB名を記載]
CollectionNames = {"Sensor":"sensors","Appliance":"appliances"}※[検知対象のコレクション名を連想配列で記載]
BatteryCollectionName = [電池切れ予兆検知対象のMongoDB Atlasのコレクション名を記載]
[Date]
DeleteDays = {"Sensor":40,"Appliance":40}
BatteryMailPeriod = 6
AcquisitionMailPeriod = 6
[Mail]
SmtpHost = [検知時のメール送信元のホストを記載]
SmtpPort = [メール送信元のポートを記載]
FromEmail = [メール送信元のアドレスを記載]
ToEmail = [検知時のメール送信先のアドレスを記載]
UserName = [メール送信元のユーザ名を記載]
Password = [メール送信元のパスワードを記載]
acquisition_detection_list.csv
「1.死活監視」のセンサごと設定を保持する設定ファイルです
各フィールドの内容を下記します。
CollectionName:監視対象のセンサデータがアップロードされるDBコレクション名
No:センサのID番号。センサデータ取得システムのDeviceList.csvのNoと対応
DeviceName:センサの名称。センサデータ取得システムのDeviceList.csvのDeviceNameと対応
FailureMinutes:ここで指定した直近FailureMinutes分間の対象センサデータがDBに存在しなかったとき、障害発生とみなす
ColName:センサデータが存在するかを判定するための列名(基本は"Temperature"=温度)
CollectionName,No,DeviceName,FailureMinutes,ColName
sensors,1,Nature_Remo_1,30,Temperature
sensors,2,Omron_USB_1,30,Temperature
sensors,3,Inkbird_IBSTH1_1,30,Temperature
sensors,4,Inkbird_IBSTH1_2,30,Temperature
sensors,5,Omron_USB_1,30,Temperature
sensors,6,Inkbird_IBSTH1mini_1,30,Temperature
sensors,7,SwitchBot_Thermo_1,30,Temperature
battery_detection_list.csv
「2.電池切れ予兆検知」のセンサごと設定を保持する設定ファイルです。
各フィールドの内容を下記します。
No:センサのID番号。センサデータ取得システムのDeviceList.csvのNoと対応
DeviceName:センサの名称。センサデータ取得システムのDeviceList.csvのDeviceNameと対応
Period:下記「電池切れ予兆検知のアルゴリズム」参照
Count:下記「電池切れ予兆検知のアルゴリズム」参照
ColName1:下記「電池切れ予兆検知のアルゴリズム」参照
LowerThreshold1:下記「電池切れ予兆検知のアルゴリズム」参照
UpperThreshold1:下記「電池切れ予兆検知のアルゴリズム」参照
ColName2:下記「電池切れ予兆検知のアルゴリズム」参照
LowerThreshold2:下記「電池切れ予兆検知のアルゴリズム」参照
UpperThreshold2:下記「電池切れ予兆検知のアルゴリズム」参照
※電池切れ予兆検知のアルゴリズム
該当センサにてPeriod時間以内にCount回以上
「ColName1<LowerThreshold1 or ColName1>UpperThreshold1 or ColName2<LowerThreshold2 or ColName2>UpperThreshold2」
を満たす異常値が発生した場合、電池切れ予兆検知したと判定
No,DeviceName,Period,Count,ColName1,LowerThreshold1,UpperThreshold1,ColName2,LowerThreshold2,UpperThreshold2
5,Omron_USB_1,8,2,Temperature,-30,50,Humidity,1,
6,Inkbird_IBSTH1mini_1,6,3,Humidity,1,,,,
cronによる定期実行
スクリプトは定期的に自動実行する必要がありますが、
RaspberryPiのようなUnix系OSにはcronという定期実行のための仕組みが準備されています。
今回はこのcronを使用して定期実行を実現します。
下記コマンドでcrontabを開きます
crontab -e
最下部に下記内容を追記します(元から設定されている定期実行が存在する場合、消さないよう注意してください)
2 0 1,4,7 * * cd /home/kenta/Programs/Pi_Atlas_Utility/; /usr/bin/python3 /home/kenta/Programs/Pi_Atlas_Utility/backup_atlas.py >/dev/null 2>&1
2 1 */3 * * cd /home/kenta/Programs/Pi_Atlas_Utility/; /usr/bin/python3 /home/kenta/Programs/Pi_Atlas_Utility/delete_atlas.py >/dev/null 2>&1
12 * * * * cd /home/kenta/Programs/Pi_Atlas_Utility/; /usr/bin/python3 /home/kenta/Programs/Pi_Atlas_Utility/acquisition_failure_detection.py >/dev/null 2>&1
7 * * * * cd /home/kenta/Programs/Pi_Atlas_Utility/; /usr/bin/python3 /home/kenta/Programs/Pi_Atlas_Utility/battery_anomaly_detection.py >/dev/null 2>&1
上記内容の意味は上から、
「backup_atlas.pyを毎月1,4,7日の0:02に実行」
「delete_atlas.pyを3日おきに1:02に実行」
「acquisition_failure_detection.pyを毎時12分に実行」
「battery_anomaly_detection.pyを毎時7分に実行」
となります。
上記crontabを保存し、
sudo /etc/init.d/cron start
で、cronによる定期実行がスタートします
以上で、RaspberryPiのIoT稼働管理システム構築が完了です!
障害が起きたらメール通知されるので、気づかぬ間にデータ取得が失敗している、という事態が防げますね!