概要
Optunaはベイズ最適化を利用した最適化ライブラリで、
その性能とAPIの使い勝手の高さから、機械学習のパラメータチューニング等でよく利用されています。
このOptuna、以下の現象に困った経験のある方も多いかと思います。
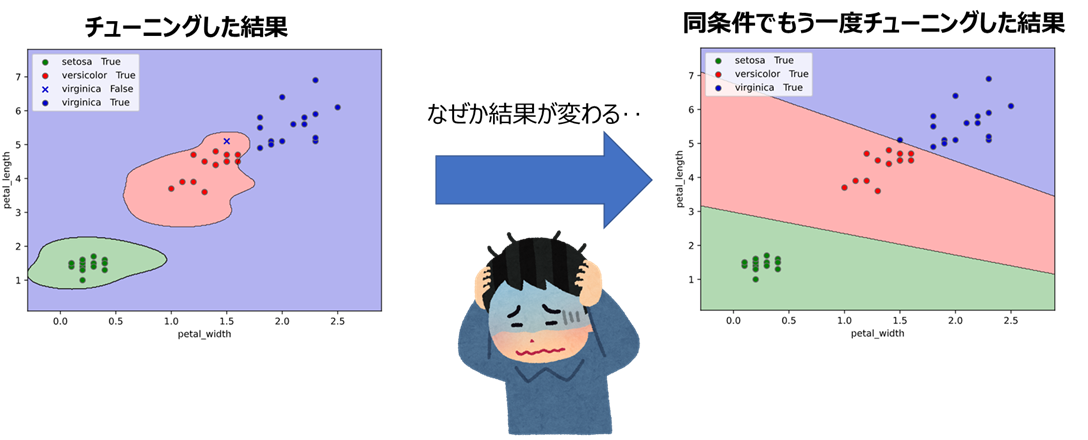
そう、繰り返すと結果が変わってしまうことです!
繰り返しても同じ結果とするためには、乱数シードを固定する必要があります。
本記事ではその方法を解説します
なぜ結果が変わる?
Optunaでは最適化の過程で乱数を利用しており、
回ごとに乱数がランダムに変わるので、最適化の結果も変わってしまいます。
生成される乱数の値を回によらず同じとするためには、乱数シードを固定する必要があります。
乱数シードの固定方法
以下のように、
・create_studyメソッド実行時の引数"sampler"にサンプラーを指定
・サンプラーの"seed"引数に、乱数シード(42がよく使われる)を指定
すれば乱数シードが固定され、繰り返しても同じ結果となることが保証されます。
import optuna
import seaborn as sns
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
iris = sns.load_dataset('iris')
model=SVC()
X = iris[['petal_width', 'petal_length']].values
y = iris['species'].values
# 最適化の目的関数
def objective(trial):
params = {
"gamma": trial.suggest_float("gamma", 0.001, 100, log=True),
"C": trial.suggest_float("C", 0.001, 100, log=True)
}
model.set_params(**params)
scores = cross_val_score(model, X, y, cv=5,
scoring='accuracy', n_jobs=-1)
return scores.mean()
# create_studyメソッドの引数"sampler"にサンプラーと乱数シード42を指定
study = optuna.create_study(direction="maximize",
sampler=optuna.samplers.TPESampler(seed=42))
study.optimize(objective, n_trials=40)
なお指定するサンプラーですが、公式ドキュメントを見ると
・目的変数が1次元のとき:"optuna.samplers.TPESampler"
・目的変数が2次元以上のとき:"optuna.samplers.NSGAIISampler"
をデフォルトのサンプラーとして利用するようです。
特にサンプラーの種類をデフォルトから変える気がなければ、上記のサンプラーを"sampler"引数に指定すれば良いです。
注意:optuna.samplers.RandomSamplerを指定したとき
ネットを見ると、
「ランダムシードを固定するにはサンプラーoptuna.samplers.RandomSamplerの引数にseedを指定すれば良い」
という記事がいくつか見付かりましたが、
試してみたところ、下図のようにランダムサーチが実行されている可能性が高そうです
・irisデータでSVMのパラメータをOptunaでチューニングしたときの結果
(色が濃いほどスコアが良い)
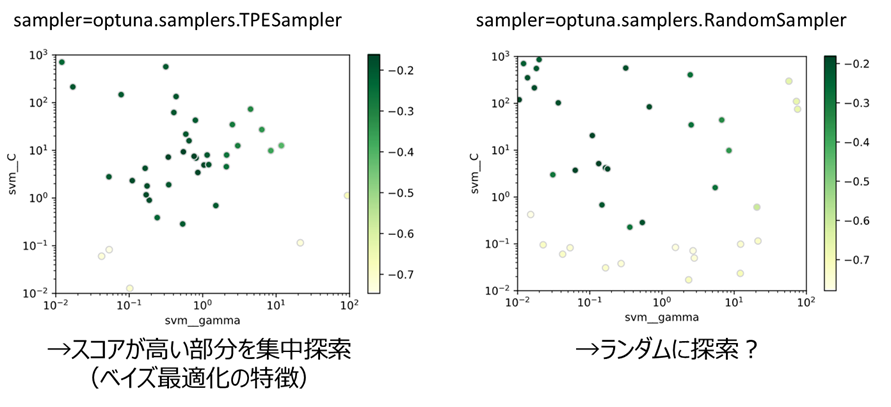
少なくともRandomSamplerを指定した場合はベイズ最適化とは思えない探索をしていそうなので、TPESamplerを指定した方が良いかと思います。