はじめに
エロ動画を見るとき、セックス中の会話が好きなので、喘いでるだけのシーンは飛ばしてしまう。
その手間を省きたいなと思ったので、色々やってみる
このシリーズ一貫した目的は「あえぎ声」と「セックス中の会話」を分離することとする。
人工知能でなんとかなりませんか?
GPU そんなに良いの持ってないし、 Cloud で train したいが、めんどくさいので
まずは tensorflow hub にある学習済みの YAMNet で試してみよう
これ使う
雑にコードをコピペしてくる
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import csv
import scipy.signal
import matplotlib.pyplot as plt
from scipy.io import wavfile
# モデルのロード
model = hub.load('https://tfhub.dev/google/yamnet/1')
# CSV からクラス名を持ってくる
def class_names_from_csv(class_map_csv_text):
class_names = []
with tf.io.gfile.GFile(class_map_csv_text) as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
class_names.append(row['display_name'])
return class_names
class_map_path = model.class_map_path().numpy()
class_names = class_names_from_csv(class_map_path)
# Sample rate 変更
def ensure_sample_rate(original_sample_rate, waveform,
desired_sample_rate=16000):
if original_sample_rate != desired_sample_rate:
desired_length = int(round(float(len(waveform)) /
original_sample_rate * desired_sample_rate))
waveform = scipy.signal.resample(waveform, desired_length)
return desired_sample_rate, waveform
# input ファイルの読みこみ
wav_file_name = 'input.wav'
sample_rate, wav_data = wavfile.read(wav_file_name, 'rb')
sample_rate, wav_data = ensure_sample_rate(sample_rate, wav_data)
# 音声ファイルの情報を表示
duration = len(wav_data)/sample_rate
print(f'Sample rate: {sample_rate} Hz')
print(f'Total duration: {duration:.2f}s')
print(f'Size of the input: {len(wav_data)}')
# int16 -> float (-1.0 ~ 1.0)
waveform = wav_data / tf.int16.max
# モデルを実行
scores, embeddings, spectrogram = model(waveform)
# 全体でメインとなる
scores_np = scores.numpy()
spectrogram_np = spectrogram.numpy()
infered_class = class_names[scores_np.mean(axis=0).argmax()]
print(f'The main sound is: {infered_class}')
# グラフを書く
plt.figure(figsize=(10, 6))
# Plot the waveform.
plt.subplot(3, 1, 1)
plt.plot(waveform)
plt.xlim([0, len(waveform)])
# Plot the log-mel spectrogram (returned by the model).
plt.subplot(3, 1, 2)
plt.imshow(spectrogram_np.T, aspect='auto', interpolation='nearest', origin='lower')
# Plot and label the model output scores for the top-scoring classes.
mean_scores = np.mean(scores, axis=0)
top_n = 10
top_class_indices = np.argsort(mean_scores)[::-1][:top_n]
plt.subplot(3, 1, 3)
plt.imshow(scores_np[:, top_class_indices].T, aspect='auto', interpolation='nearest', cmap='gray_r')
# patch_padding = (PATCH_WINDOW_SECONDS / 2) / PATCH_HOP_SECONDS
# values from the model documentation
patch_padding = (0.025 / 2) / 0.01
plt.xlim([-patch_padding-0.5, scores.shape[0] + patch_padding-0.5])
# Label the top_N classes.
yticks = range(0, top_n, 1)
plt.yticks(yticks, [class_names[top_class_indices[x]] for x in yticks])
_ = plt.ylim(-0.5 + np.array([top_n, 0]))
plt.savefig("output.jpg")
ちょっとコードリーディング
Python も tensorflow もあんまり自信ないので、コードリーディングメモ
閉じる必要があるリソースを開くときはこうするらしい
with tf.io.gfile.GFile(class_map_csv_text) as csvfile:
Tensorflow hub で読み込まれたモデルから取得した値は全部 Tensor として返されるので、 class_map_path() も Tensor(, shape=(), dtype=string) な値として返されている。その Tensor のラップを外すために numpy を呼んでいる
class_map_path = model.class_map_path().numpy()
waveform は波形情報を持った配列なので len で長さを求めることができて original と desired の比で変更後の長さを求めて、 scipy.signal.resample で長さを変えることができる
desired_length = int(round(float(len(waveform)) /
original_sample_rate * desired_sample_rate))
waveform = scipy.signal.resample(waveform, desired_length)
wav_data の長さを sample rate で割れば再生時間がわかる
duration = len(wav_data)/sample_rate
wav_data は int16 の配列なので、 -1.0 から 1.0 の配列に変える
waveform = wav_data / tf.int16.max
セックス中の会話とあえぎ声の違い
セックス中の会話は、 Speech, とか Speech, kid speaking とか
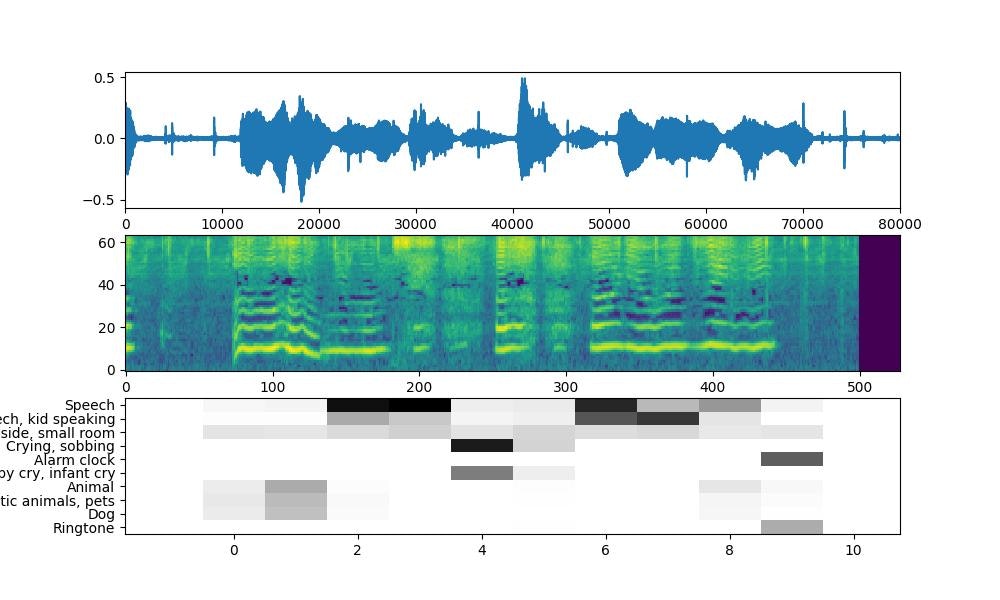
あえぎ声は、 Hiccup, Wail, Gasp とか
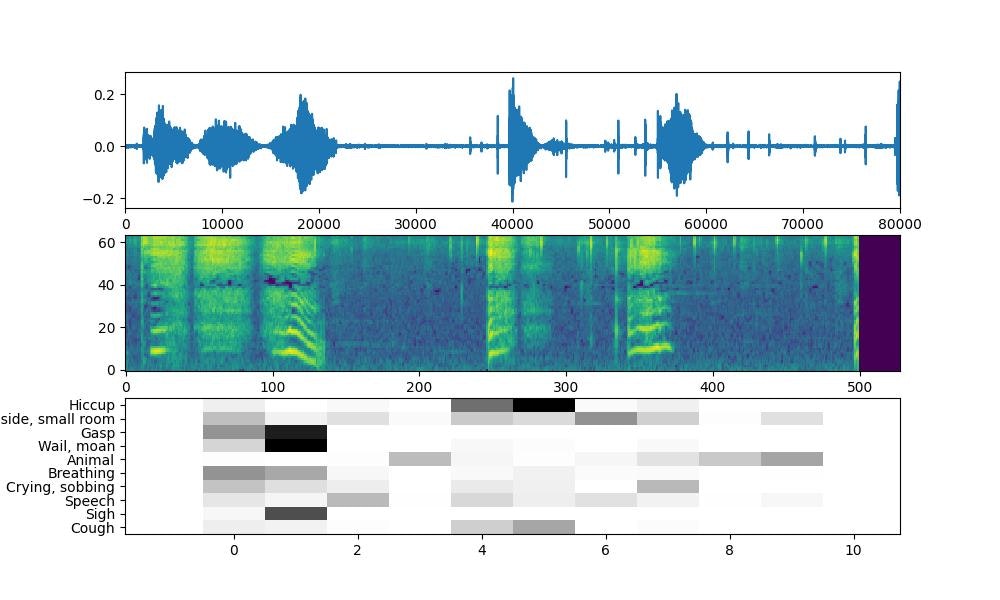
なんかいけそうな気がする〜。もうちょっといろんな動画を分析してみて、エロ動画に出がちなクラスを集めてみて、そこから学習データ作っていこう
なんか
久しぶりに匿名でブログ書くと楽しい。名前が出てると、どうしてもちゃんと書かなきゃって思ってしんどくなるけど、こうやって何も気にしなくて書くのは楽しいね
動画ファイルから細かい音声ファイルに分割する
ffmpeg を python から読み込む一番簡単な方法はなんだろう
これが良さそう
以下のようにして、動画を分割できる
import sys
import ffmpeg
assert len(sys.argv) == 2
video_file = sys.argv[1]
# 動画の尺を求める
video_data = ffmpeg.probe(video_file)
video_duration = int(max([float(stream['duration']) for stream in video_data['streams']]))
assert video_duration > 0
# 20 秒ごとに 16000 Hz 1 Channel の wav ファイルに分割
chunk_duration = 20
for chunk_start in range(0, video_duration, chunk_duration):
input = ffmpeg.input(video_file)
output = ffmpeg.output(input.audio, f'chunk-{chunk_start:06}.wav', ss=chunk_start, t=chunk_duration, ar=16000, ac=1)
ffmpeg.run(output)
動画の分析結果を字幕ファイル化する
import sys
import ffmpeg
import csv
from scipy.io import wavfile
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import os
import datetime
assert len(sys.argv) == 2
video_file = sys.argv[1]
# 動画の尺を求める
video_data = ffmpeg.probe(video_file)
video_duration = int(max([float(stream['duration']) for stream in video_data['streams']]))
assert video_duration > 0
# Tensorflow hub から YMANet の学習済みモデルをロード
model = hub.load('https://tfhub.dev/google/yamnet/1')
# クラス名を取得
def class_names_from_csv(class_map_csv_text):
class_names = []
with tf.io.gfile.GFile(class_map_csv_text) as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
class_names.append(row['display_name'])
return class_names
class_map_path = model.class_map_path().numpy()
class_names = class_names_from_csv(class_map_path)
# SRT format
subtitle_content = ''
start_time = datetime.datetime.now()
# 2 秒ごとに処理
chunk_duration = 2
index = 0
for chunk_start in range(0, video_duration, chunk_duration):
# 音声を抽出
chunk_file = f'chunk-{chunk_start:06}.wav'
input = ffmpeg.input(video_file)
output = ffmpeg.output(input.audio, chunk_file, ss=chunk_start, t=chunk_duration, ar=16000, ac=1)
ffmpeg.run(output, overwrite_output=True, quiet=True)
try:
# 音声を読み込み読み込み
sample_rate, wav_data = wavfile.read(chunk_file, 'rb')
assert sample_rate == 16000
waveform = wav_data / tf.int16.max # -1.0 ~ 1.0 に正規化
# 分類の実行
scores, embeddings, spectrogram = model(waveform)
# score の平均を求める
scores_np = scores.numpy()
score_count = len(scores_np)
mean_scores = scores_np.mean(axis=0)
# クラスランキング
sorted_class_name_score_pairs = sorted(zip(class_names, mean_scores), key=lambda pair: pair[1], reverse=True)
inferred_class_name = sorted_class_name_score_pairs[0][0]
# 字幕ファイルのコンテンツを作る
subtitle_content += f'{index + 1}\n'
subtitle_content += f'{datetime.timedelta(seconds=chunk_start)},000 --> {datetime.timedelta(seconds=chunk_start + chunk_duration)},000\n'
for class_name, score in sorted_class_name_score_pairs[0:5]:
subtitle_content += f'{class_name} ({int(score * 100)}%)\n'
subtitle_content += f'\n'
finally:
os.remove(chunk_file)
# 進捗の表示
execution_time = datetime.datetime.now() - start_time
execution_sec = execution_time.total_seconds()
remaining_sec = execution_sec / (chunk_start + chunk_duration) * video_duration - execution_sec
print(f'current_position={chunk_start} ({str(datetime.timedelta(seconds=chunk_start))}), video_duration={video_duration}, execution_sec={execution_sec}, remaining_sec={remaining_sec}, inferred_class={inferred_class_name}')
index += 1
# 字幕ファイルの書き出し
with open('subtitles.srt', 'w') as subtitle_file:
subtitle_file.write(subtitle_content)
こんな感じで、どのシーンがどう分析されてるか動画を再生しながら確認できる

で、いろんな動画のシーンで分類を試してみた
すると大体こんな感じだった
環境音系
- Silence
- Inside, small room
- Inside, large room or hall
雑音系
- Drawer open or close
- Tap
- Bouncing
- Door
- Sliding door
- Writing
- Snort
- Squeak
- Breathing
スパンキング
- Hands
- Finger snapping
確実に喋ってる
- Speech
喋ってる可能性がある
- Child speech, kid speaking
- Crying, sobbing
- Baby cry, infant cry
- Baby laughter
- Babbling
- Laughter
- Whimper
- Singing
- Child singing
- Belly laugh
- Giggle
あえぎ
- Animal
- Dog
- Cat
- Domestic animals, pets
- Livestock, farm animals, working animals
- Pant
- Goat
- Hiccup
- Wail, moan
電マ
- Electric shaver, electric razor
- Electric toothbrush
- Buzz
次回は
この知見を使って、転移学習用のデータを作って行きたい