はじめに
概要
昨年主要なパブリッククラウドであるAzure,GCP,AWSのOCRサービスの比較記事を書きましたが、クラウドの世界は進化が早いですね。
2021年にそれぞれのサービスでアップデートがありましたので、改めて比較してみたいと思います。
以下の前回の比較記事です。
実は今回、マイクロソフトから最新のAPIのプライベートプレビュー版を入手しました。
プライベートプレビュー版なのでバージョンアップ内容の詳細は控えますが、日本語手書き文字の認識精度が猛烈に向上しています。
(2022/05/02 追記)
2022年2月にパブリックプレビューに移行しました。
バージョンアップ内容の詳細はこちらをご確認ください。
この記事の想定読者
クラウドが提供するOCR機能に興味のある方
どのクラウドサービスを導入しようか迷われている方
各社サービスの機能比較
Azure/GCP/AWSが提供するOCRサービスの比較を一覧表にまとめました。
※2022/1/9時点で最新のバージョンを使用して検証しています。Azureはプライベートプレビュー版
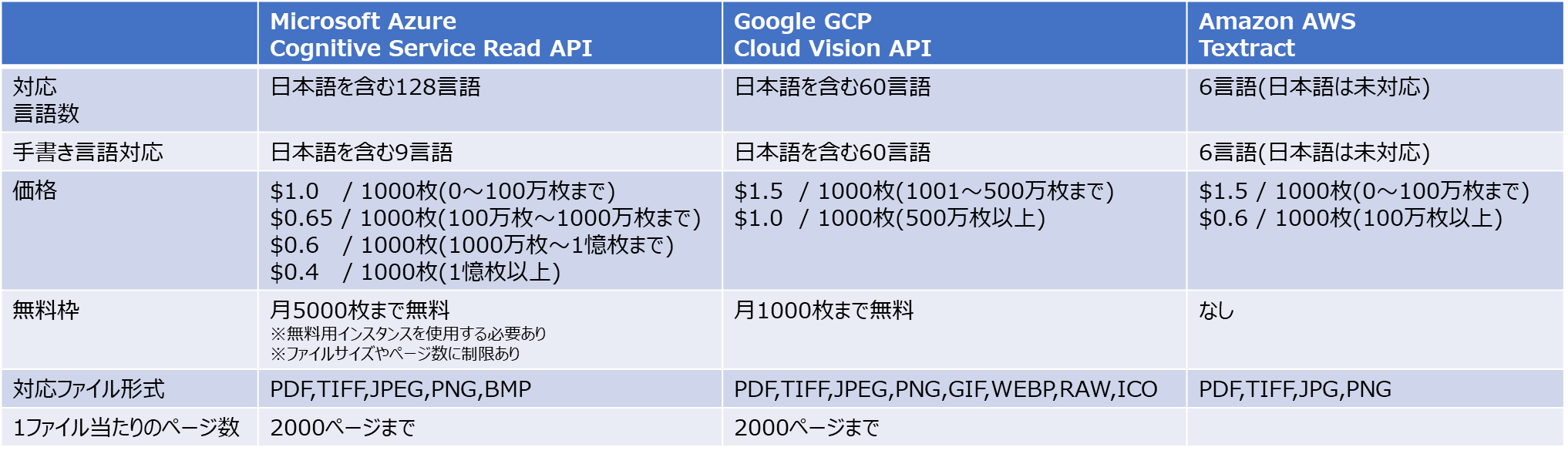
対応言語数、価格ではAzureがリードしています。
特に対応言語数に関しては2021年から比べて大きく他社をリードしていますね。
手書きに関しては、GCPは60言語全てで対応しています。後述しますが、認識精度に関してはAzureの方が良い結果でした。
対応ファイル数はGCPが多く対応していますが、マイクロソフトも実用上問題ないレベルでカバー出来ているかなと思います。
AWSは他と比べて全体的に機能が弱いなという印象です。(2021年から変化なし)
ここからは、実際のデータを使って、OCRの認識精度や機能について詳細に比較していきたいと思います。
AWSのOCR機能は昨年から引き続き日本語未対応とのことで、比較対象外とします。
認識精度
精度検証データ
精度検証用のデータとして以下のPDFデータを使用しました。
前回比較した際のデータに、日本語や英語の手書き文字を加えてみました。
実データはこちらです。

IPAで公開されている情報システム・モデル取引・契約書のテンプレートを基に作成した自作データです。
総文字数は1236文字で、言語は日本語、英語が含まれています。また、文章だけでなく表形式の記述が含まれている点が特徴です。
印刷文字と手書き文字の内訳は以下の通りです。
| 印刷文字 | 手書き文字 |
|---|---|
| 1095文字 | 141文字 |
精度検証結果
今回も「文字認識率」と「ノイズ数」の2つの視点から精度評価を実施しました。
各精度指標の定義は以下の通りです。
| 精度指標 | 定義 |
|---|---|
| 文字認識率(%) | 正しく認識された文字数 / 検証画像の総文字数 * 100 |
| ノイズ数 | 検証データに含まれない文字を文字として認識した数 |
検証の結果、今回の検証データでは精度はAzureの方が良い結果となりました。
ドキュメント全体の認識精度
| Azure | GCP | |
|---|---|---|
| 文字認識率 | 99.75% | 98.62% |
| ノイズ数 | 1文字 | 17文字 |
文字認識率に関してはどちらもかなり高精度で、実用上はどちらでも問題ないレベルかと思います。
一方で気になるのはノイズです。
Azureはノイズが入ることなくほぼ完璧にOCR出来ているのに対して、GCPはノイズが多く入っています。
文字認識に関してはどちらも高精度に認識できている為、よりノイズが少ないAzureの方が実用的な気がします。
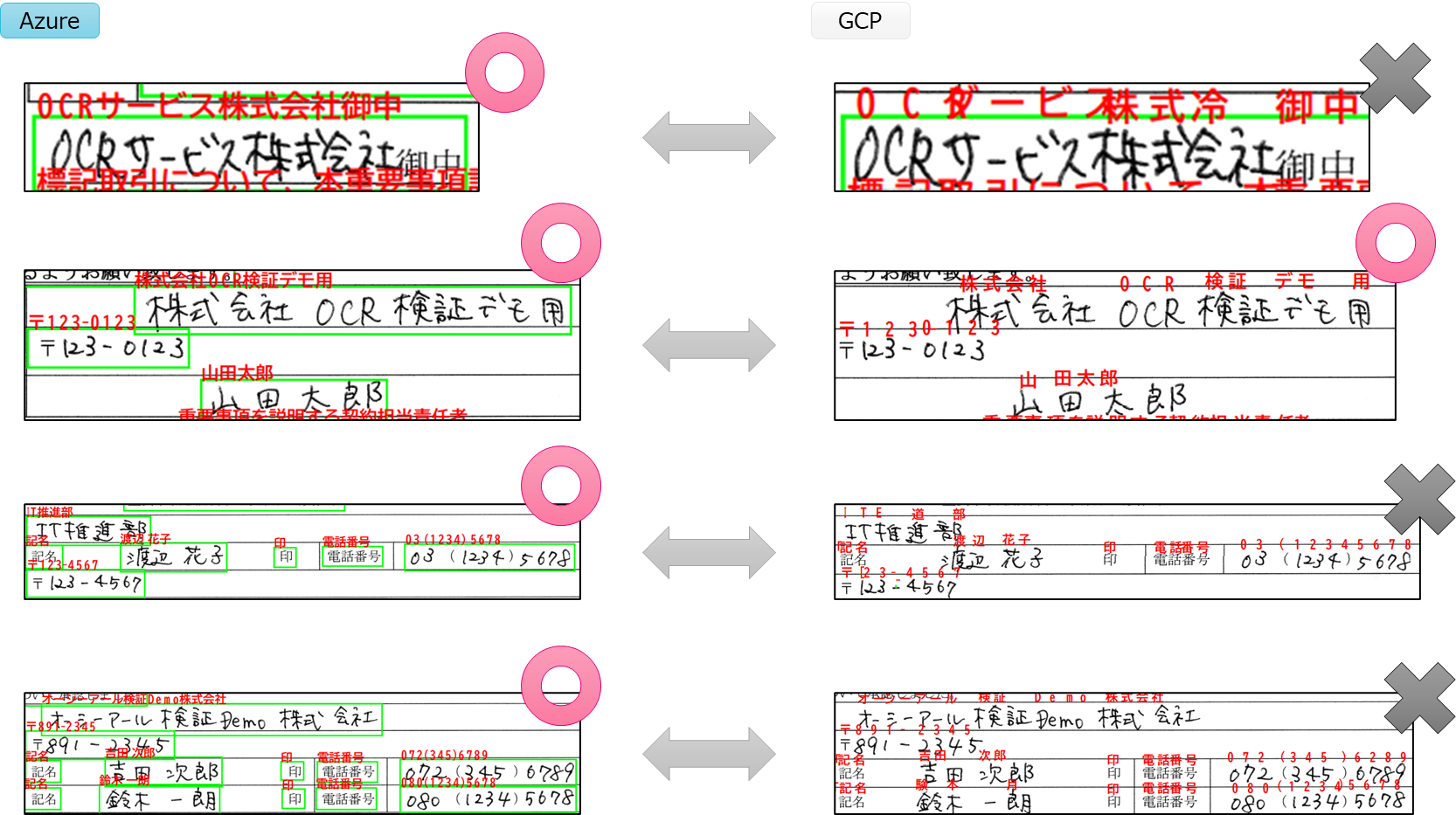
手書き文字の認識精度
今回の検証データでは、新たに手書き文字を追加したので、手書き部分のみ抜粋して認識精度を比較してみました。
| Azure | GCP | |
|---|---|---|
| 文字認識率 | 100.0% | 88.65% |
| ノイズ数 | 0文字 | 1文字 |
Azureはまさかの完全一致という結果になりました。
もちろん今回の検証データでの結果なので、どのデータでも100%の精度で認識できるわけではありませんが、これは驚きです。
GCPも88%と高い認識率でしたが、Azureと比較すると物足りない結果となりました。
会社名や氏名で誤認識が多かったのが少し残念でした。
以下で、具体的な事例をいくつか紹介したいと思います。
文字誤認識の例
まずはAzureのOCR機能(Read API)の誤認識の例です。
ベンダとOCRしてほしいところをペン"グ"とOCRしています。

次にGCPのOCR機能(Vision API)の誤認識の例です。
OCRサービス株式会社としてほしいところをOCR"ダ"ービス株式"冷"とOCRしています。

他にも、IT推進部としてほしいところがIT "E 道部"となっていたり、鈴木一朗としてほしいところが"験本月"となっていたりしました。

GCPは日本語の手書きに対応している割に、Azureに比べて手書きの認識精度があまり良くないように感じました。
ノイズの例
まずはAzureのOCR機能(Read API)のノイズの例です。
以下の赤丸の部分が、ピリオドとしてOCRされています。

データをスキャンした際に付着したゴミと思われます、、、。
正直ノイズとしてカウントするか迷いましたが、実用上はこの様なデータも存在すると思いますので厳密にカウントしました。
次にGCPのOCR機能(Vision API)のノイズの例を2つ紹介します。
1つ目ですが、準委任の準の前に「が認識されています。
前回の精度検証時に引き続き、表形式になっているところでこのパターンが多くみられました。表を構成する格子を誤認識しているようです。
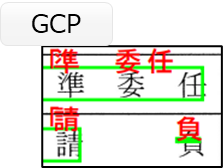
続いて2つ目です。誤認識とノイズの複合的なパターンです。
少し説明が難しいのですが、住所、代表者氏名とOCRしてほしいところを、所、代表者氏名、住一代とOCRしてしまっています。

代に関しては2回OCRされています。また、住所とOCRしてほしいところが所しかOCRされていません。
頑健性
スキャンに失敗して傾いたようなデータに対しては、前回検証時から変わりなくAzure、GCPどちらも問題なく検出できています。
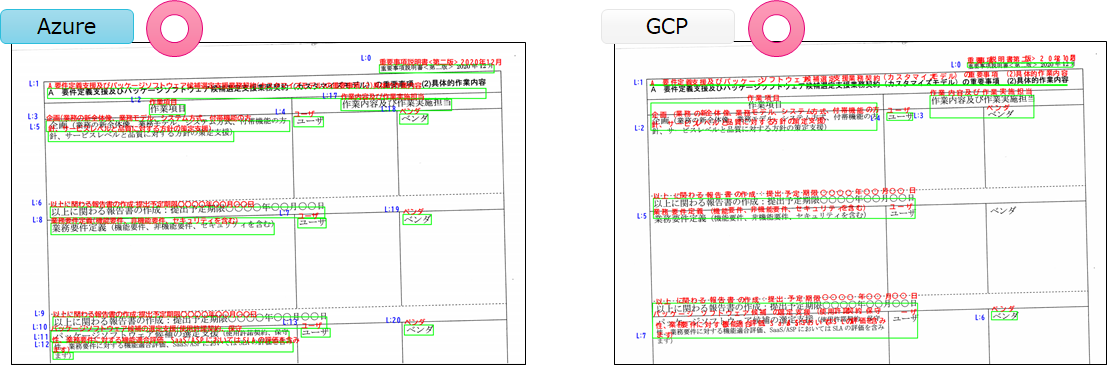
自然な読み取り順序
段組みデータに対しても前回検証時から変わりなく、Azureは自然な読み取り順序でOCR出来ていますがGCPは対応出来ていませんでした。
青色の番号がOCRの出力順です。

AzureのOCR機能(Read API)は、段組みデータの左半分をOCRした後に右半分をOCRしています。
GCPのOCR機能(Vision API)は、段組みデータに対応できておらず、左上から右下方向にZ型でOCRを実施しています。
手書き文字対応
日本企業においてOCRを業務で使用する際に、日本語手書き文字の認識精度は重要なファクターだと感じましたので、この軸でも今回比較したいと思います。
今回検証をしてみて、手書き文字の認識精度の関しては、Azureの方が断然良いと感じました。
Azureは今回のプライベートプレビュー版で手書き文字の認識精度が猛烈に向上しているので、今後のバージョンアップにかなり期待して頂いて良いと思います。
まとめ
今回は、2022年の最新バージョンで、Azure/GCP/AWSのOCRサービスについて比較してみました。
各社のサービスで2021年にアップデートはされていましたが、AzureのOCR機能(Read API)が猛烈に強化されている印象です。
ノイズの少なさを含めた認識精度、コスト、対応言語の多さなど、OCRサービスにおいてはAzureが大きくリードしているのではと面ます。
OCRサービスをご検討の方は、まずAzureのOCR機能(Read API)を試して頂くのが良いのではないでしょうか。