はじめに
概要
Azure Cognitive ServiceのOCR機能(Read API v3.2)が日本語に対応したので使ってみました。
非常に精度良く日本語がOCR出来ているので、実際のOCR結果を交えながら紹介したいと思います。
日本語のOCRでお困りの方(特に精度)は是非一度使ってみて頂きたいおススメの機能です。
この記事の想定読者
AzureのOCR機能に興味のある方
現在ご利用されているOCR機能に不満や課題をお持ちの方
機能検証にあたって実施したこと
実際にOCR処理を実施してみたい人向けの内容です。
OCRの検証結果事例を確認されたい方はOCR検証結果へ進んでください。
実行環境の構築
今回は以下の様な構成を作成し、OCR機能の検証を実施しました。
OCR機能のREST APIを実行端末側(オンプレPC側)で呼び出してOCR結果を取得するだけのシンプルな構成にしました。
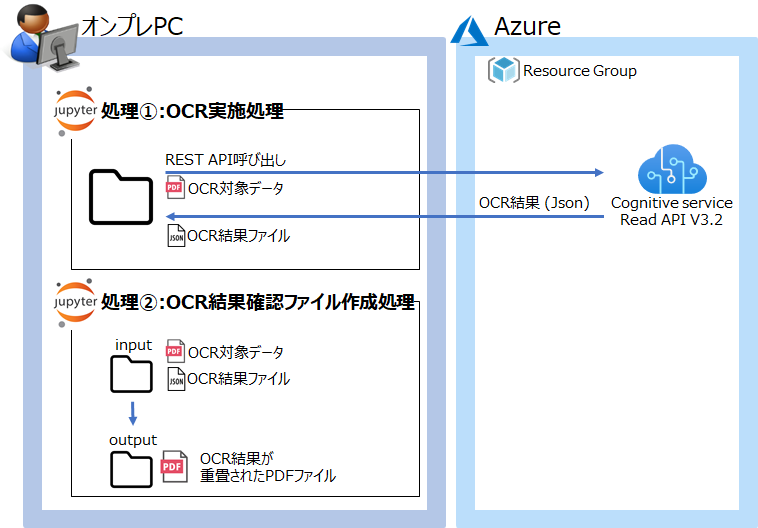
実行環境の構築においては、大きく3つの作業を実施しています。
それぞれ簡単に説明していきたいと思います。
作業①:(Azure)OCR実行用リソースグループの作成
AzureにCognitive Sereviceのリソースを作成し、OCR処理が実施できる環境を整備します。
[1] 任意のリソースグループを作成します。
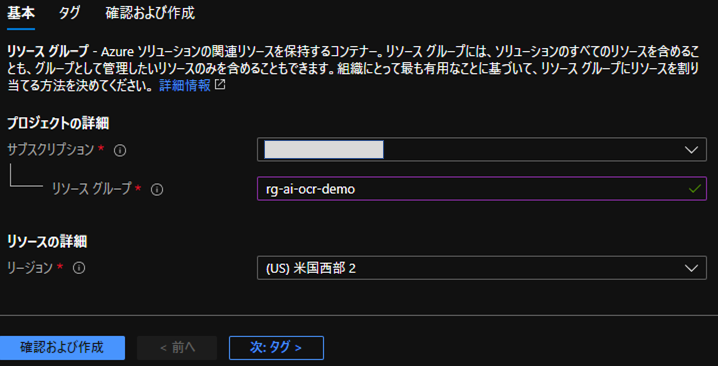
必要な情報を入力の上、[確認および作成]ボタンを選択してリソースグループを作成します。
[2] Azure Portalの全てのサービスからCognitive Serviceを検索し、Cognitive Serviceリソースを作成します。
[3] Cognitive Serviceリソースを追加しようとするとMarketplaceからさらにサービスの選択を要求されます。今回はComputer Visionリソースを作成します。
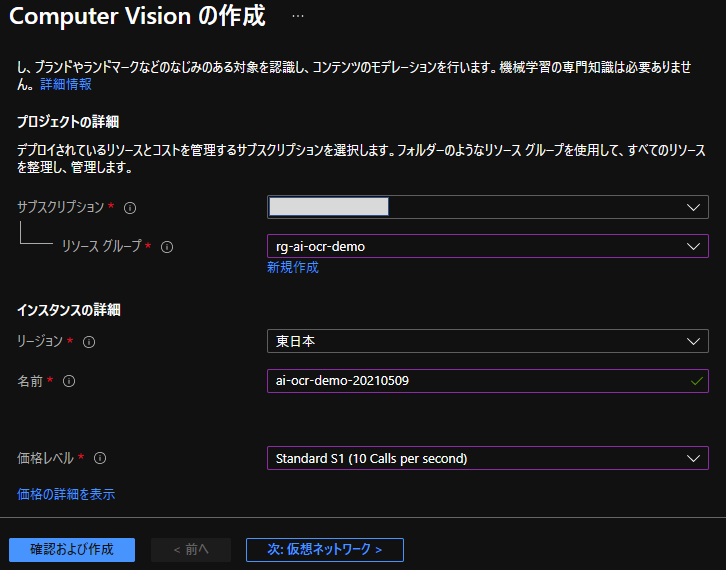
[4] [1]で作成したリソースグループを紐づけ、その他必要な情報を入力してComputer Visionリソースを作成します。
[5] 作成したComputer Visionリソースのキーとエンドポイントから、キー1、エンドポイントを控えておきます。
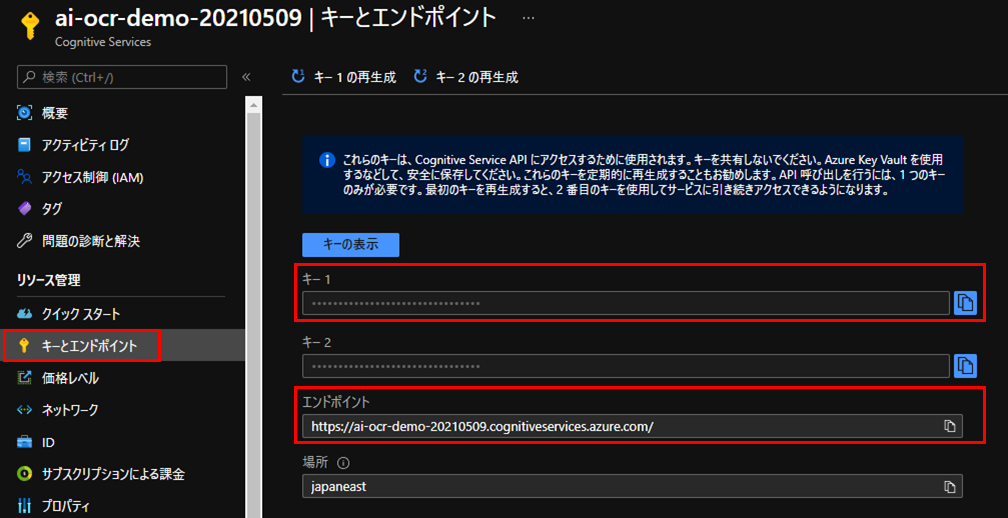
Azureの準備はこれで完了です。
作業②:OCR実施処理スクリプトの作成
OCRを実行するスクリプトを作成します。
スクリプトの流れは以下です。
[1] 各種変数の設定します。
[2] Read APIを呼び出す関数、OCR結果を取得する関数を定義します。
[3] OCR処理を実施し、結果を取得します。
※自然な読み取り順序となるオプションの設定が漏れていたのでソースを一部変更しました。2021/5/15
まず、各種変数を定義します。
# OCR対象のファイル名を定義します
FILE_NAME = r"D:\\ocr\\OCR_sample_data.pdf"
# Computer Visionリソースのサブスクリプションキー、エンドポイント設定
# サブスクリプションキーとエンドポイントは、リソースグループ作成時に控えておいたキー1,エンドポイントを入力します。
SUBSCRIPTION_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxx"
ENDPOINT ="https://ai-ocr-demo-20210509.cognitiveservices.azure.com/"
# ホストを設定
host = ENDPOINT.split("/")[2]
# vision-v3.2のread機能のURLを設定
text_recognition_url = (ENDPOINT + "vision/v3.2/read/analyze")
# 読み取り用のヘッダー作成
read_headers = {
# サブスクリプションキーの設定
"Ocp-Apim-Subscription-Key":SUBSCRIPTION_KEY,
# bodyの形式を指定、json=URL/octet-stream=バイナリデータ
"Content-Type":"application/octet-stream"
}
# 結果取得用のヘッダー作成
result_headers = {
# サブスクリプションキーの設定
"Ocp-Apim-Subscription-Key":SUBSCRIPTION_KEY,
}
次に、Read APIを呼び出す関数、OCR結果を取得する関数を定義します。
import http.client, urllib.request, urllib.parse
import urllib.error, base64
import ast
# Read APIを呼ぶ関数
def call_read_api(host, text_recognition_url, body, params, read_headers):
# Read APIの呼び出し
try:
conn = http.client.HTTPSConnection(host)
# 読み取りリクエスト
conn.request(
method = "POST",
url = text_recognition_url + "?%s" % params,
body = body,
headers = read_headers,
)
# 読み取りレスポンス
read_response = conn.getresponse()
print(read_response.status)
# レスポンスの中から読み取りのOperation-Location URLを取得
OL_url = read_response.headers["Operation-Location"]
conn.close()
print("read_request:SUCCESS")
except Exception as e:
print("[ErrNo {0}]{1}".format(e.errno,e.strerror))
return OL_url
# OCR結果を取得する関数
def call_get_read_result_api(host, file_name, OL_url, result_headers):
result_dict = {}
# Read結果取得
try:
conn = http.client.HTTPSConnection(host)
# 読み取り完了/失敗時にFalseになるフラグ
poll = True
while(poll):
if (OL_url == None):
print(file_name + ":None Operation-Location")
break
# 読み取り結果取得
conn.request(
method = "GET",
url = OL_url,
headers = result_headers,
)
result_response = conn.getresponse()
result_str = result_response.read().decode()
result_dict = ast.literal_eval(result_str)
if ("analyzeResult" in result_dict):
poll = False
print("get_result:SUCCESS")
elif ("status" in result_dict and
result_dict["status"] == "failed"):
poll = False
print("get_result:FAILD")
else:
time.sleep(10)
conn.close()
except Exception as e:
print("[ErrNo {0}] {1}".format(e.errno,e.strerror))
return result_dict
これらの変数、関数を使用して、OCRを実行する処理を実装します。
import time
import json
import urllib.parse
# body作成
body = open(FILE_NAME,"rb").read()
# パラメータの指定
# 自然な読み取り順序で出力できるオプションを追加
params = urllib.parse.urlencode({
# Request parameters
'readingOrder': 'natural',
})
# readAPIを呼んでOperation Location URLを取得
OL_url = call_read_api(host, text_recognition_url, body, params, read_headers)
print(OL_url)
# 処理待ち10秒
time.sleep(10)
# Read結果取得
result_dict = call_get_read_result_api(host, FILE_NAME, OL_url, result_headers)
# OCR結果を保存
output_json_file = r"D:\\ocr\\OCR_sample_data.json"
with open(output_json_file,"w",encoding = encoding) as f:
json.dump(result_dict,f, indent = 3, ensure_ascii = False)
作業③:OCR結果確認用ファイル作成スクリプトの作成
Read APIを用いたOCR処理だけであれば作業②までで完了ですが、このままではOCR結果がちょっと確認しづらいです。
その為、OCR処理対象のデータに、OCR結果を重ね合わせる処理を実装します。
スクリプトの流れは以下です。
[1] 各種変数の設定します。
[2] PDFファイルの特定ページのイメージとOCR結果を基に、OCR結果を重畳したイメージを作成する関数を定義します。
[3] PDFファイルのページ数分、[2]で定義した関数を回し、PDFファイルとして保存します。
まず、各種変数を定義します。
# OCR結果を重ねる処理に必要なファイルは以下の2つです
PDF_FILE = r"D:\\ocr\\OCR_sample_data.pdf"
OCR_RESULT_FILE = r"D:\\ocr\\OCR_sample_data.json"
# 文字コードの指定
encoding = "utf_8_sig"
# フォントを指定
font_name = "HeiseiKakuGo-W5"
次に、PDFファイルの特定ページのイメージとOCR結果を基に、OCR結果を重畳したイメージを作成する関数を定義します。
import json
from pdfrw import PdfReader, PdfWriter
from pdfrw.buildxobj import pagexobj
from pdfrw.toreportlab import makerl
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.cidfonts import UnicodeCIDFont
from reportlab.lib.units import inch
from reportlab.lib.pagesizes import A4, portrait
# 1ページ分のPDFを作成する関数
def make_page(writer, font_name, pdf_page, data_page):
# 中間生成物ファイル名
tmp_file = r"D:\\ocr\\work.pdf"
# OCR結果のjsonデータからページサイズを取得
page_width = data_page["width"]
page_height = data_page["height"]
pagesize = (page_width * inch, page_height * inch)
# ここで定義したpdfにOCR結果を重畳して、tmp_fileに保存する
pdf = canvas.Canvas(tmp_file, pagesize = pagesize)
# 既存のPDFページをオブジェクト化
pp = pagexobj(pdf_page)
pdf.doForm(makerl(pdf,pp))
# フォント設定
pdfmetrics.registerFont(UnicodeCIDFont(font_name))
pdf.setFont(font_name, 8)
# テキスト書き込み
for line_num, line in enumerate(data_page["lines"]):
# テキスト始点座標
(pos_x,pos_y) = (line["boundingBox"][6], line["boundingBox"][7])
# テキストボックスサイズ
box_width = line["boundingBox"][2]-line["boundingBox"][0]
box_height = line["boundingBox"][7]-line["boundingBox"][1]
# 色指定
pdf.setFillColorRGB(1,1,1,0)
pdf.setStrokeColorRGB(1,0,0,1)
# テキストボックス描画
pdf.setStrokeColorRGB(0,1,0,1)
pdf.rect(
pos_x * inch,
(page_height - pos_y) * inch,
box_width * inch,
box_height * inch,
stroke = 1,
fill = 1
)
pdf.setFillColorRGB(0,0,1,1)
# テキスト番号表示
pdf.drawString(
(pos_x - 0.3) * inch, # ここでx方向の位置を調整する
(page_height - pos_y + 0.2) * inch, # ここでy方向の位置を調整する
"L:" + str(line_num)
)
# テキスト
text = line["text"]
pdf.setFillColorRGB(1,0,0,1)
# テキストを描画する
pdf.drawString(
pos_x * inch, # ここでx方向の位置を調整する
(page_height - pos_y + box_height) * inch, # ここでy方向の位置を調整する
text
)
pdf.showPage()
pdf.save()
# 中間生成のPDFファイルを読み込む
with open(tmp_file, mode="rb") as f:
pdf_reader = PdfReader(f)
# 中間生成PDFをwriterに取り込む
writer.addPage(pdf_reader.pages[0])
これらの変数、関数を使用して、複数ページで構成されているPDFファイルに対して、OCR結果を重畳する処理を実施します。
# 出力ファイル名を定義
PDF_FILE_WITH_OCR_RESULT = r"D:\\ocr\\OCR_sample_data_mapping.pdf"
# OCR結果ファイル(json)をロードする
with open(OCR_RESULT_FILE,"r",encoding = encoding) as f:
data_dict = json.load(f)
# pdfwriter定義
pdf_writer = PdfWriter()
# OCR対象となったPDFファイルを読み込む
input_pdf_pages = PdfReader(PDF_FILE, decompress = False).pages
# ファイルのページ分処理を回す
for page_num,data_page in enumerate(data_dict["analyzeResult"]["readResults"]):
# 所定のページのpdf情報を取得する
pdf_page = input_pdf_pages[page_num]
# 1ページ毎にOCRの結果が重畳されたPDFデータを作成してpdf_writerに書き込む
make_page(pdf_writer, font_name, pdf_page, data_page)
# OCR結果が重畳されたPDFデータをファイル化する
with open(PDF_FILE_WITH_OCR_RESULT, mode="wb") as f:
pdf_writer.write(f)
スクリプトを実行すると、以下の様にOCR結果が元データに重畳された結果確認用データが出力されます。

緑色の枠は文字列の抽出領域を表し、赤文字は領域内のOCR結果を表しています。
また、青文字の「L:X」はOCRの出力順を表します。
この例では、まず「重要事項説明書<第二版>2020年12月」が出力され、次に「重要事項説明書」「本件システムの名称」の順にOCR結果が出力されていることが分かります。
OCR検証結果
検証データ
今回の検証では、こちらのデータ(自作)を使用しました。
IPAで公開されている情報システム・モデル取引・契約書のテンプレート「<重要事項説明書(第二版追補版付属)>」から一部抜粋、変更して自作したデータです。
以下の様な特徴を持ったデータです。
| No. | データの特徴 |
|---|---|
| 1 | 日本語、英語が混在している |
| 2 | 表形式の情報が含まれている |
| 3 | 段組みの記載がある |
| 4 | スキャンに失敗し、文書が一部傾いている |
これらがどのようにOCRされるかを見ていきたいと思います。
OCR検証結果サマリ
OCRの検証結果サマリです。
これらを実例を挙げながら紹介していきます。
| No. | 概要 |
|---|---|
| 1 | 日本語のOCRはぼぼ完璧に出来ている |
| 2 | 傾いたデータでも問題なくOCRが出来ている |
| 3 | 縦書きの文字も認識可能 |
| 4 | 段組みデータが自然な順序で出力可能 |
| 5 | 文字の間隔が離れていると別の文字として認識される |
1. 日本語のOCRはぼぼ完璧に出来ている
少し見づらいですが、確認する限りほぼ完璧にOCR出来ています。
結果を一部抜粋して載せましたが他の個所でも同等の精度でOCR出来ており、精度は非常に高いことを確認しました。
最下行(L:8)を見てもわかるように「保守性、Saas/ASPにおいては~」など日本語と英語が混在していても問題ありません。
またOCRの出力順も上から下へ意図通りに出力されています。

1点気を付けるべきは、OCRで出力される結果が1行1出力となっている点です。
緑の枠で一つの出力になるので、例えば下2行の文章で「使用許諾契約」という単語が行を分かれて記載されている場合、
「使」と「用許諾契約」という別々の単語として出力されます。
ただ、今回のデータでは出力順も上から下に意図通り出力されているので、この文字列を出力順に繋げてしまえば解決できそうです。
2. 傾いたデータでも問題なくOCRが出来ている
契約書のデータ等をスキャンした際に、少し傾いてしまったりすることは多々あるかと思います。
この様なデータではOCRの精度は下がりがちですが、AzureのRead APIでは問題なくOCR出力できていることを確認しました。
これだけでも試してみる価値は十分にあるのではないかと思います。

3. 縦書きの文字も認識可能
日本語の契約書など、表形式のフォーマットが含まれる文書には縦書きの文字含まれることがあります。
今回の検証データでは、この縦書きの文字も認識出来ました。
下図の左側面部「契約の表示」が一つの文字列としてOCR出来ていることが分かります。

4. 段組みデータも自然な順序で出力可能
契約書などでよく見られますが、1枚のページの中で段組みになっている文書があります。
Read API v3.2の新機能として、段組みが自然な順序でOCRされるようになっています。
詳しくはこちらを参照ください。
公式にはラテン語のみとなっていますが、日本語の段組みでデータでどの様になるかを検証しました。
非公式にはなりますが、日本語でも問題なく段組みデータが自然な順序で出力出来ました。
少し見づらいですが、青色の数字の順番にご注目下さい。
2段組みの文書の左側を順にOCRした後に、右側をOCRしていることが分かります。

これは素晴らしいですね。
5. 文字の間隔が離れていると別の文字として認識される
こちらは仕方ない部分もありますが、日本語の表形式のデータなどでは表の項目名がセル内で等間隔になるように、文字の間隔があいてしまう場合があります。
この様の場合、下図の様に「会社名」「住所」など、一つの単語ととして認識されてほしい単語が別の単語として認識される場合がありました。

まとめ
今回は、Azure Cognitive ServiceのOCR機能(Read API v3.2)がどの程度日本語に対応できるかを検証してみました。
OCRの精度や段組みの対応、傾き等に対する頑健性など非常に高品質な機能であることが確認できました。
ちなみに2021年4月に一般提供が開始(General Availability)されており、品質も担保されたサービスとなっております。
今回は価格については触れませんでしたが、1ページ当たり0.x円(従量課金制でOCR処理枚数によって変化する)と、他社製品に比べて驚異的な低コストで高精度なOCRが実現できます。
他のOCR製品と比べてGUIは持っていないので、実業務で使用する場合には必要に応じてGUIを開発する必要がありますが、顧客の要望に合わせて必要な機能に絞って開発することでコスト最適化を図れるという意味では非常に良いサービスではないでしょうか。
また、表形式のデータ等にOCRに関しては、Read APIによるOCRよりもForm RecognizerのLayout APIの方が向いていると思います。
次回はこの辺りのサービスについて検証してみたいと思います。