はじめに
概要
AzureのFormRecognizerで非定型文書から超お手軽にテーブルデータを抽出出来ました。
非定型文書のOCRにお悩みの方にはとてもおススメの機能です。
実際の事例も交えながら紹介したいと思います。
この記事の想定読者
非定型文書のOCRにお困りの方
AzureのFormRecognizerに興味のある方
本記事のゴール
マイクロソフトが提供するfott(Form OCR Testing Tool)を使用して、非定型文書からテーブルデータを抽出できるようになることを本記事のゴールとします。
Azure Form Recognizerとは
Azure Form Recognizerは、ドキュメントデータからテキストデータ、テーブル情報、キーと値のペアなどを抽出することが出来るAzure Applied AI Servicesの一つです。
詳しく知りたい方はこちらを参照ください。
Azure Form Recognizerは3つの機能があります。(2021/06/06時点)
本記事では、No.1のレイアウトAPIを使用したテーブルデータの抽出をご紹介します。

想定ユースケース(こんなことで困っていませんか?)
文書データのOCRによるデータをご検討中のお客様から、非定型文書に関するご相談を多く頂きます。
一見定型文書の様に見える納品書や請求書でも、記載されている商品の数が違ったり、紙データをスキャンした際に少しズレたりすると、市販のOCRソフトでは途端に認識精度が落ちてしまいます。
例えば以下の様なケースです。
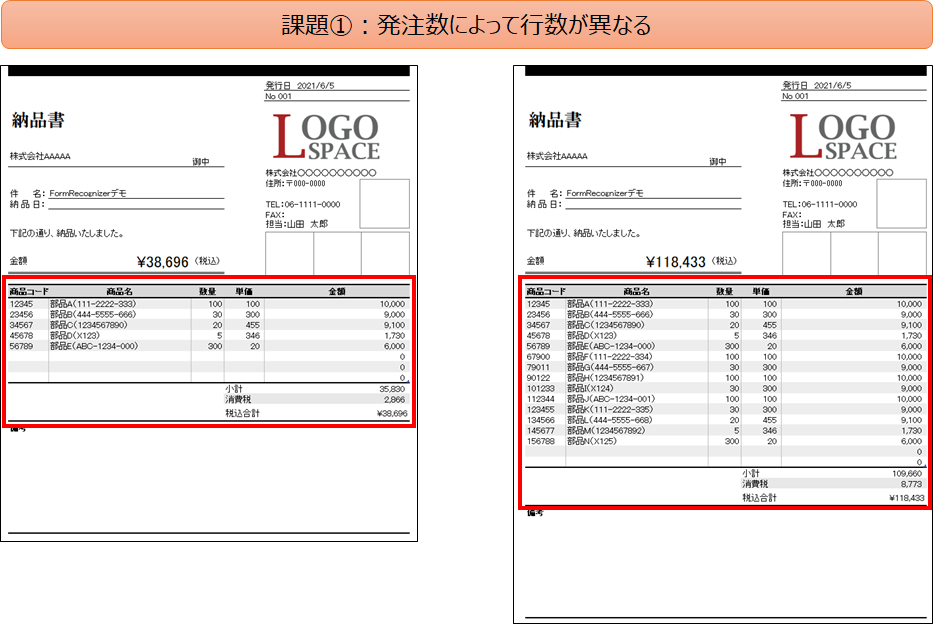
発注数によってテーブルの行数が異なるケース
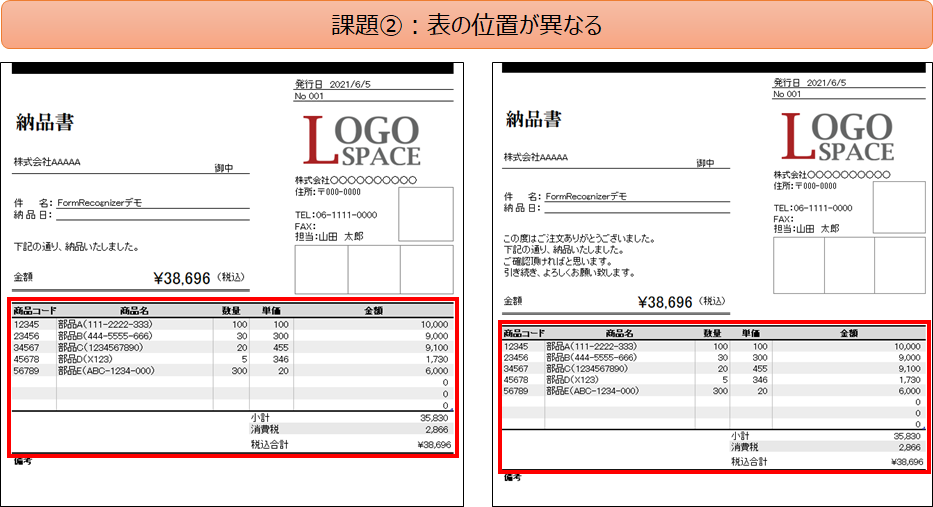
テーブルの位置が微妙に異なるケース
スキャンに失敗して傾いているケース

これらの想定ユースケースにおいて、Azure Form Recognizerでテーブル情報を正しくデータとして抽出出来るかどうか検証しました。
機能検証にあたって実施したこと
実際にAzure Form Recognizerを試してみたい人向けの内容です。
検証結果事例を確認されたい方はForm Recognizer検証結果へ進んでください。
作業①:(Azure)リソースグループの作成
AzureにCognitive Sereviceのリソースを作成し、Form Recognizerが実施できる環境を整備します。
[1] 任意のリソースグループを作成します。
必要な情報を入力の上、[確認および作成]ボタンを選択してリソースグループを作成します。
[2] Azure Portalの全てのサービスからCognitive Serviceを検索し、Cognitive Serviceリソースを作成します。
[3] Cognitive Serviceリソースを追加しようとするとMarketplaceからさらにサービスの選択を要求されます。今回はForm Recognizerリソースを作成します。
[4] [1]で作成したリソースグループを紐づけ、その他必要な情報を入力してForm Recognizerリソースを作成します。

[5] 作成したComputer Visionリソースのキーとエンドポイントから、キー1、エンドポイントを控えておきます。
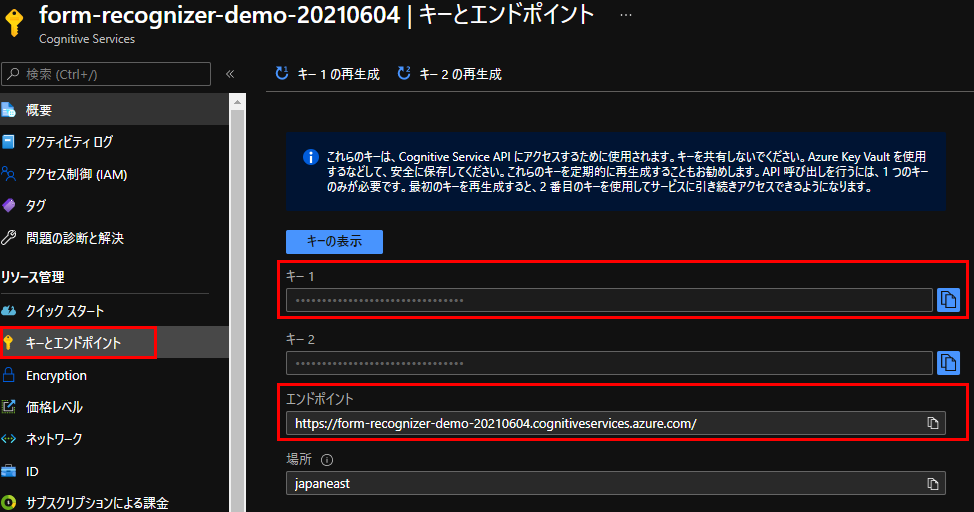
Azureの準備はこれで完了です。
作業②:fottでForm Recognizerを実行する
作業①で作成したリソースを使用して、fott(Form OCR Testing Tool)で検証用データからテーブルデータを抽出してcsvファイルでダウンロードします。
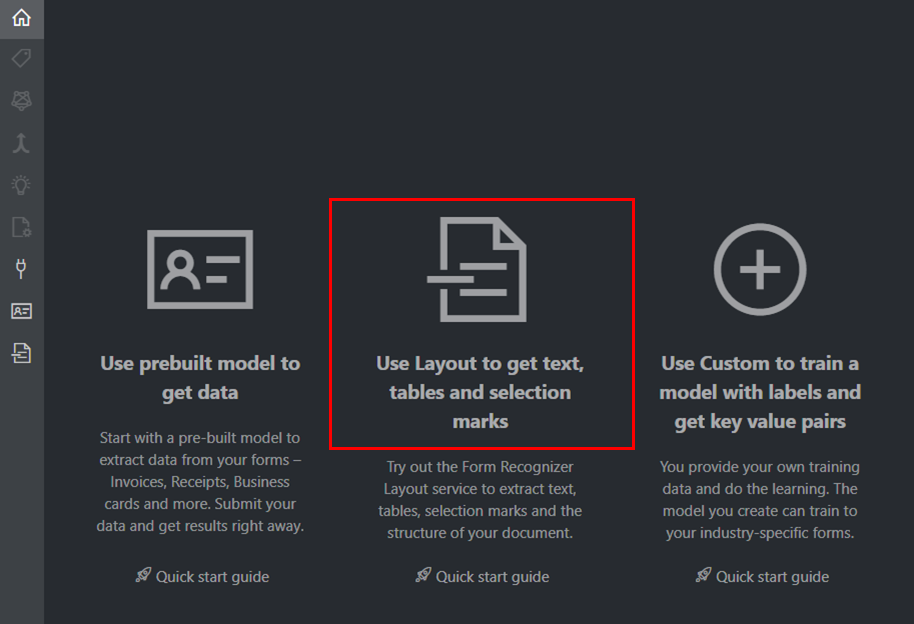
[1]fottへアクセスし、Use Layout to get text, tables and selection marksをクリックします。
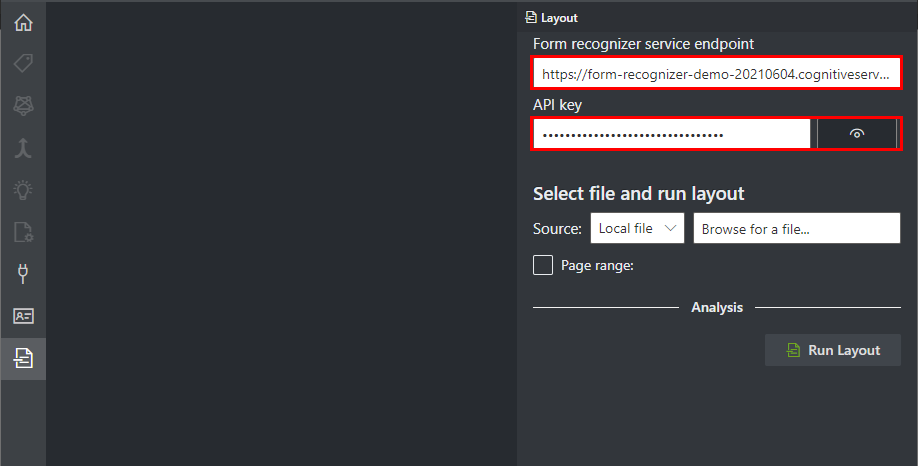
[2]作業①で控えておいたエンドポイントとキー1をそれぞれ入力します。
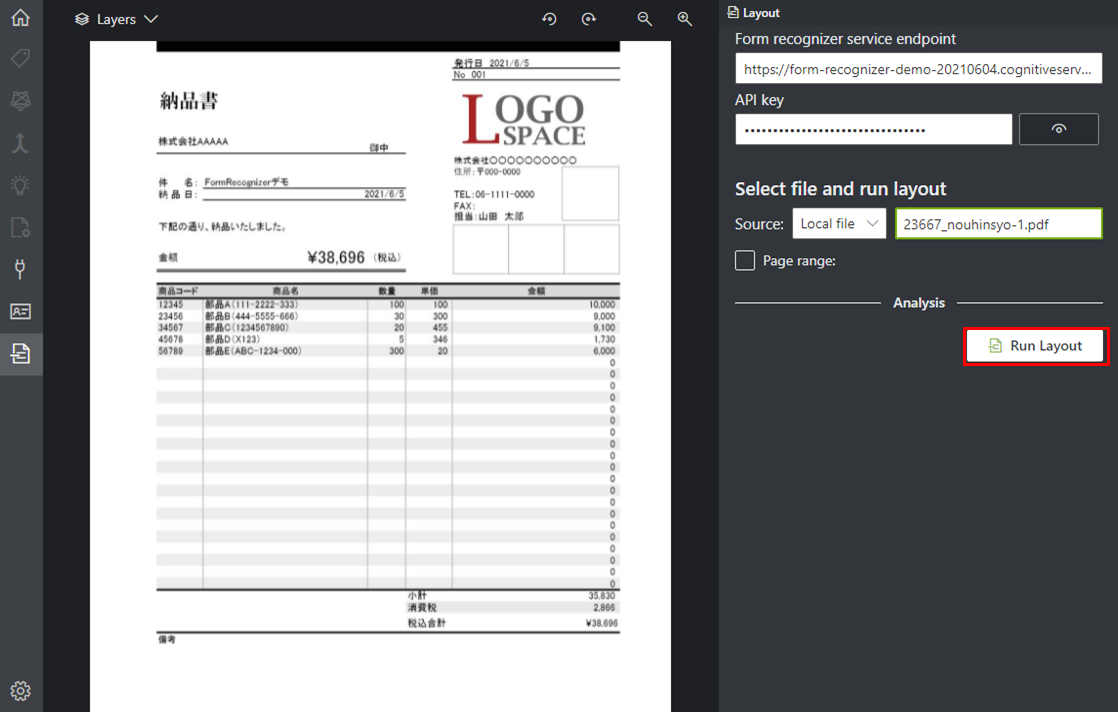
[3]テーブルデータを読み取りたいファイルを指定し、Run Layoutをクリックします。
[4]TableをクリックするとテーブルデータをCSVファイルで取得できます。
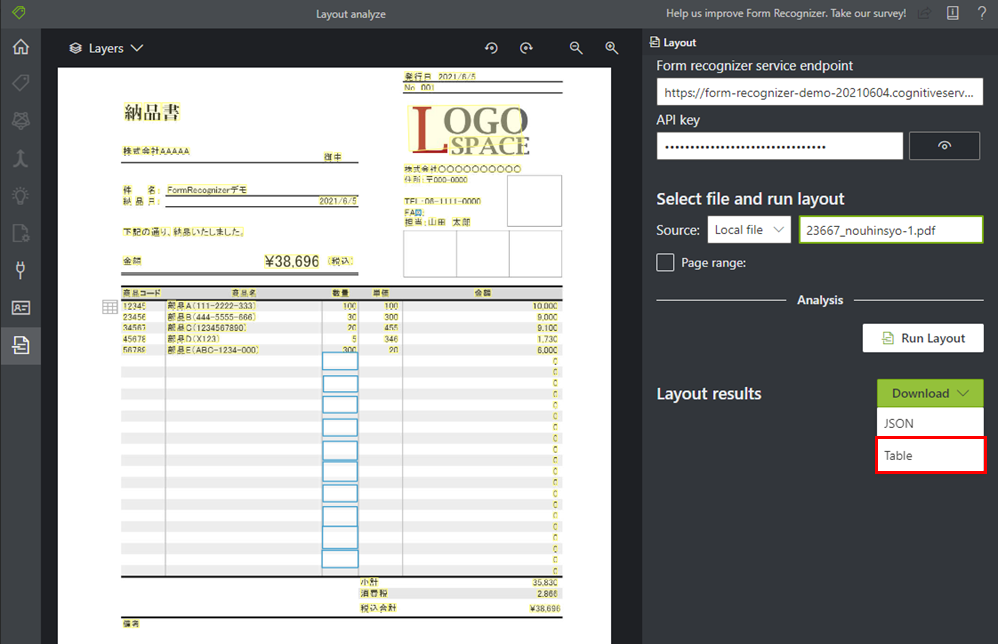
JSONをクリックすると、テーブルデータやそのほかのテキストデータがJSON形式でダウンロードできます。
また、テーブルデータの抽出結果は、以下の手順でfott上で確認することが出来ます。
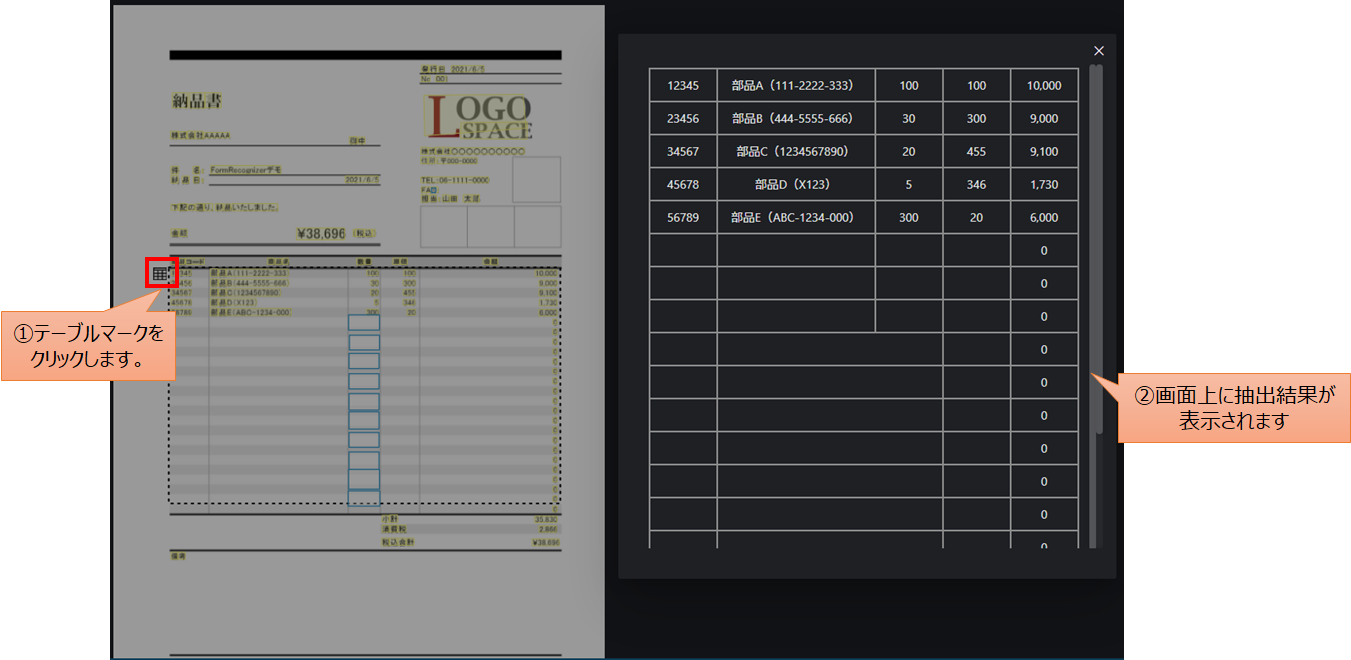
Form Recognizer検証結果
検証データ
今回の検証ではこちらのデータ(全5データ)を使用しました。
想定ユースケースで提示した事例を網羅したデータをそれぞれ自作し、テーブルデータが正しく抽出が出来るかどうかを検証しました。
実施結果
以下が検証サマリです。
これらを実例を挙げながら紹介していきます。
| No. | 概要 |
|---|---|
| 1 | テーブルデータの抽出はどのデータでも正しく出来ている |
| 2 | テーブルの位置によらず正しくテーブルデータの抽出が出来ている |
| 3 | 傾いたデータでも問題なくテーブルデータの抽出が出来ている |
| 4 | テーブルが抽出されない場合がある |
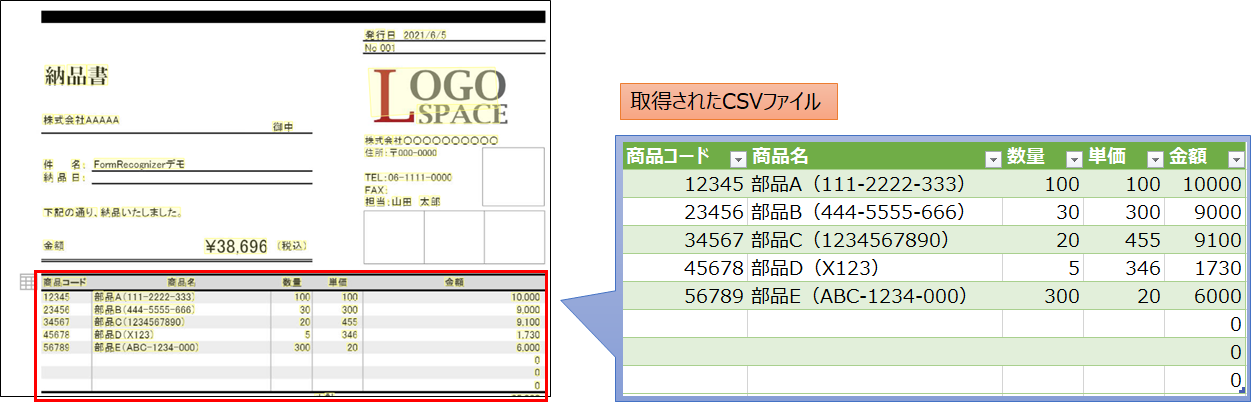
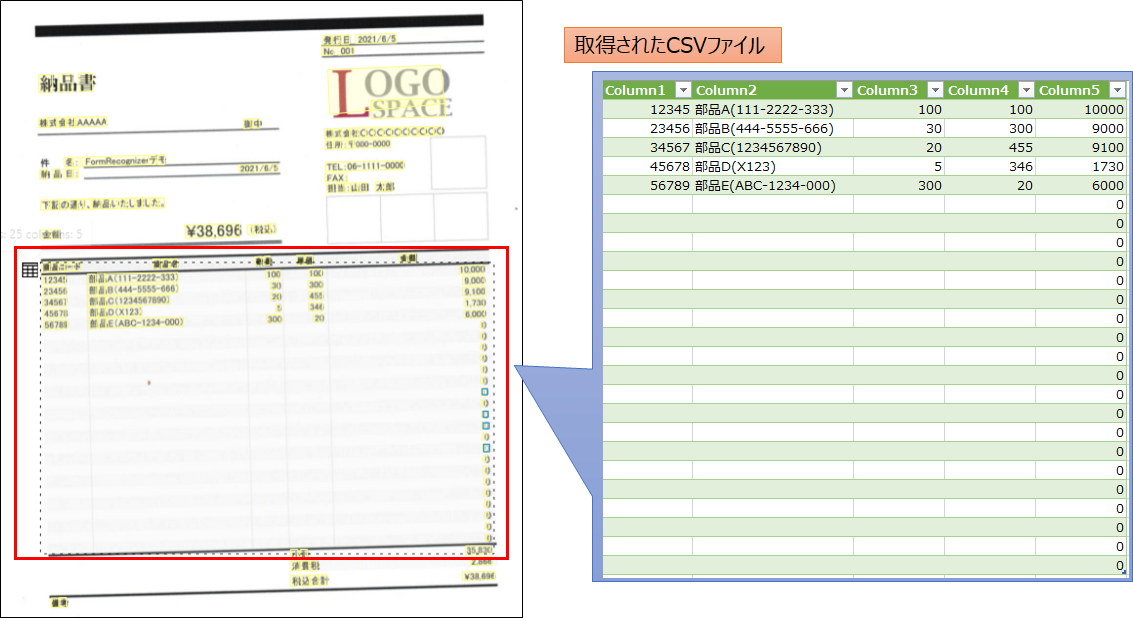
1. テーブルデータの抽出はどのデータでも正しく出来ている
以下はテーブル抽出結果の一例です。
どのデータにおいても、基本的にテーブルの情報を正しく抽出出来ていることを確認しました。
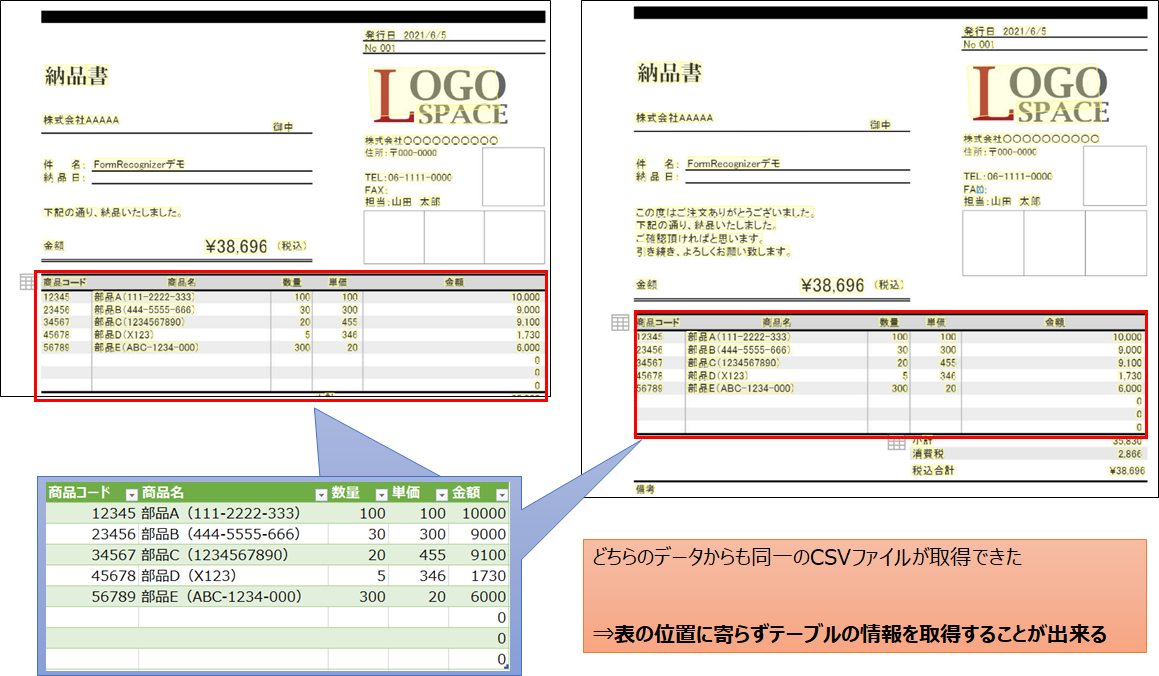
2. テーブルの位置によらず正しくテーブルデータの抽出が出来ている
以下は、文書中で、表の位置が微妙にずれているデータの比較結果です。
どちらのデータからも同じテーブル情報を抽出することが出来ました。
市販のOCRソフトではこの様なケースでは精度が落ちがちですが、Azure Form Recognizerでは精度よく情報が抽出出来ていることが分かります。
3. 傾いたデータでも問題なくテーブルデータの抽出が出来ている
スキャンに失敗して傾いたデータでも、問題なくテーブル情報が抽出出来ています。
ヘッダーが認識できていないのが惜しいですが、テーブル内の各情報は問題なく取得出来ています。
テーブル自体が傾いているので難しいかなと思いましたが、これは素晴らしいですね。
4. テーブルが抽出されない場合がある
データによって、テーブルが抽出されない場合がありました。

FormRecognizer_demo1.pdfでは「商品コード~金額」のテーブルデータしか抽出出来ていませんが、FormRecognizer_demo2.pdfの方では、「小計、消費税、税込み金額」の部分もテーブルデータとして抽出されています。
この様にデータによって抽出結果が変わることがあるので、Azure Form Recognizerの利用を検討される場合は、お手持ちのデータでどの様な結果になるかをある程度検証された方が良いかと思います。
まとめ
今回は、Azure Form RecognizerのレイアウトAPI機能で、非定型文書のテーブルデータを抽出できるか検証してみました。
表の位置によらず抽出可能で、傾いていても問題なく抽出でき、個人的にはとても良い機能だと思いました。
学習済みAIモデルを使用する為、学習のデータの準備作業やAIモデルの学習等が必要なく実施できる点はとても魅力です。
また、fottの様なGUIツールも用意されており、抽出結果をすぐに確認出来る点も素晴らしいと思います。
※REST APIが用意されているので、GUIによる操作なしに抽出結果(JsonもしくはCSV)を取得することも可能です。
今回のデータでは見られませんでしたが、テーブル情報を誤認識した場合(数量や単価の数を間違える等)に値を修正する様なGUIはないので、実業務で使用する場合は別途画面等の開発は必要になりますが、顧客の要望に合わせて必要な機能に絞って開発することでコスト最適化を図れるという意味では非常に良いサービスではないでしょうか。
今回はForm RecognizerのレイアウトAPI機能についてご紹介しました。
もし学習用のデータが大量にある場合は、カスタムモデル機能を使用してAIモデルを作成すれば「キーと値のペア」が取得できるのでさらにおススメです。
次回はカスタムモデルについて紹介したいと思います。