最終更新
2021/11/24
本質的な内容は変化していないものの,最新の研究動向に対して本記事で取り上げた論文はかなり古くなっているので注意してください.
本記事より良くまとめられているオープンアクセスの日本語文献があるので,そちらを参照するほうがよいと思います.
-
深層学習技術のセキュリティ課題についてはこちら
森川 郁也(富士通株式会社), "機械学習セキュリティ研究のフロンティア"
電子情報通信学会 基礎・境界ソサイエティ Fundamentals Review, Vol.15 No.1, 2021
https://www.jstage.jst.go.jp/article/essfr/15/1/15_37/_article/-char/ja -
深層学習技術のハードウェアセキュリティ課題についてはこちら
吉田 康太, 藤野 毅(立命館大学), "エッジAIデバイスのハードウェアセキュリティ"
電子情報通信学会 基礎・境界ソサイエティ Fundamentals Review, Vol.15 No.2, 2021
https://www.jstage.jst.go.jp/article/essfr/15/2/15_88/_article/-char/ja
2020/07/29
Model inversion attack, Model poisoning attackの文献を追加
モチベーション
近年の機械学習技術の精度向上はめざましく,中でも深層学習技術(deep neural network: DNN)は特に大きな成果を挙げている.DNNの社会実装も進んでおり,非常に広範な応用が期待される.一方で,一般的なプログラムとは実装方法が異なるがゆえのセキュリティ課題がいくつも提唱されており,その対策が急務である.本記事では,DNNのセキュリティ課題について,できる限り正確かつ網羅するようまとめる.
前提知識
一般的なDNNの訓練及び推論に関する基礎知識
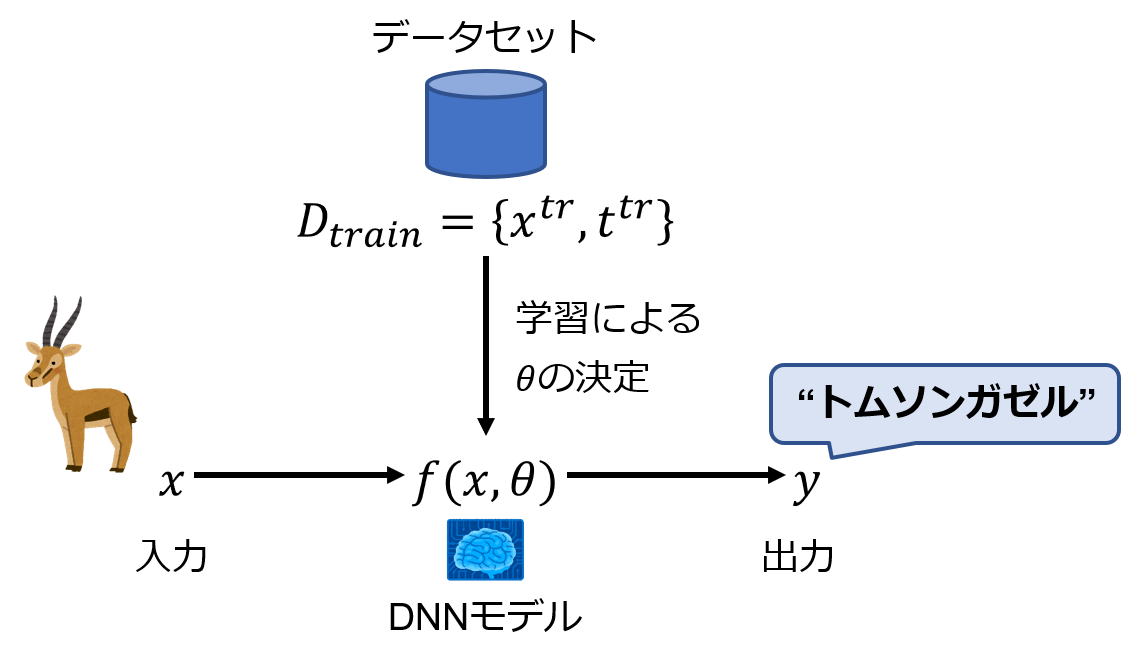
DNNとその周辺の定義
-
$x$
DNNへの入力 -
$y$
DNNの出力 -
$t$
DNN訓練時の教師データ -
$\theta$
DNNのパラメータ(重み,バイアス等) -
$f(x, \theta)$
DNNモデルとその構造.入力$x$とパラメータ$\theta$を受け取り,出力$y$を計算する.
$y = f(x, \theta)$ -
$D$
DNNモデルの学習・検証に用いるデータセット
ここで,DNNの訓練から推論までを図にまとめると以下のようになる.
訓練用パラメータ,検証ステップ等は簡略化のため省いている.
脅威
セキュリティ目標による分類
-
機密性 (データの窃取)
入力($x$), 出力($y$),訓練データ($D_{train}$),DNNモデル($f, \theta$)の窃取 -
完全性 (データの改ざん)
入力($x$), 出力($y$),訓練データ($D_{train}$),DNNモデル($f, \theta$)の改ざん
攻撃名称による分類
-
Model inversion attack (モデル反転攻撃) 【機密性】
訓練データ($D_{train}$)の窃取によるプライバシー情報の暴露 -
Model extraction attack (モデル抽出攻撃) 【機密性】
DNNモデル($f, \theta$)窃取による知的財産の侵害及び他の攻撃への応用 -
Adversarial examples (敵対的サンプル(生成攻撃)) / Model evasion attack (モデル回避攻撃) 【完全性】
入力($x$)の改ざんによって出力($y$)を誤った値へ誘導 -
Model poisoning attack (モデルポイズニング攻撃) 【完全性】
訓練データ($D_{train}$)の改ざんによって出力($y$)を誤った値へ誘導

各攻撃の詳細
各攻撃について,代表的な論文や事例を挙げつつ簡単に紹介する.
攻撃や論文の詳細な紹介は時間があれば後日まとめる.
Model inversion attack
目的
訓練データ($D_{train}$)の窃取
攻撃者は,ある特定のラベルに対する分類確率が最大になるような入力を生成する.攻撃者はそのラベルに分類される入力がどのようなものかを知らないが,この攻撃によってそれを知ることができる.
例えば,顔認証システムを仮定する.学習済みモデル($f$,$\theta$)は,顔写真($x$)を入力すると,それが誰かを分類($y=f(x, \theta)$)することができる.ここで,攻撃者はターゲットの名前(クラス$y'$)のみを知っており,その顔は知らないとする.攻撃者は適当な入力を元にターゲットクラス($y'$)に高い確信度で分類される入力($x'$)を探索する.この時,$x'$はDNNモデル($f$,$\theta$)が学習した,そのラベルに対する教師データを代表しており,ターゲットの顔の特徴を得ることができる.(下図参照)
このような攻撃は,学習済みモデルから訓練データ中に含まれるプライバシーや機密に関わる情報を暴露することになる.
 (上図は論文[Fredrikson 2015]より引用)
(上図は論文[Fredrikson 2015]より引用)
仮定
- 攻撃者は,学習データセット($D_{train}$)を知らない.
- 攻撃者は,$x$を自由に操作でき,その時の出力$y$を入手できる.
- 攻撃者に学習済みモデル$f$, $\theta$が既知とする環境における攻撃をWhite-box攻撃と呼ぶ.
- White-box攻撃に対して,攻撃者が$f$, $\theta$についての知識を持たないという環境における攻撃をBlack-box攻撃と呼ぶ.
代表的な論文
- Matt Fredrikson, et al., "Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures", CCS'15, 2015
- Samyadeep Basu, et al., "Membership Model Inversion Attacks for Deep Networks", arXiv:1910.04257, 2019
- Ziqi Yang, et al., "Neural Network Inversion in Adversarial Setting via Background Knowledge Alignment", CCS'19, 2019
Model extraction attack
目的
学習済みDNNモデル($f, \theta$)の窃取
この攻撃は,ソフトウェアをターゲットとした攻撃と,ハードウェアをターゲットとした攻撃の2つに大別できる.
ソフトウェアをターゲットとした攻撃
学習済みDNNモデルはクラウドサーバなどに設置された機械学習サービスとして提供されていると仮定する.攻撃者は,正規のAPIを通じてクエリ(入力$x$)から応答(出力$y$)を得る.代表的な手法では,攻撃者はDNNの蒸留のように,大量の$x$をターゲットモデル($f$,$\theta$)に入力し,その時の出力$y$を得る.これを訓練データセットとして,攻撃者の手元にある代替モデルを訓練し,ターゲットモデルと同等の精度を持つ代替モデル($f'$,$\theta'$)を得る.
この時,対象の機械学習サービスの課金モデルにもよるが,攻撃者はターゲットモデル($f$,$\theta$)よりも十分に少ないコストで代替モデル($f'$,$\theta'$)を得ることができる.
仮定
- 攻撃者は,学習済みDNNモデル($f$,$\theta$)を知らない.
- 攻撃者は,$x$を自由に操作でき,その時の出力$y$を入手できる.
代表的な論文
- Florian Tramèr, et al., "Stealing Machine Learning Models via Prediction APIs", arXiv:1609.02943, 2016
- Seong Joon Oh, et al., "Towards Reverse-Engineering Black-Box Neural Networks", arXiv:1711.01768, 2017
- Yi Shi, et al., "How to steal a machine learning classifier with deep learning", HST, 2017
- Mika Juuti, et al., "PRADA: Protecting against DNN Model Stealing Attacks", arXiv:1805.02628, 2018
- Binghui Wang, et al., "Stealing Hyperparameters in Machine Learning", arXiv:1802.05351, 2018
- Tatsuya Takemura, et al., "Model Extraction Attacks against Recurrent Neural Networks", arXiv:2002.00123, 2020
(大阪大学の藤原先生の研究室の論文) - Tribhuvanesh Orekondy, et al., "Knockoff Nets: Stealing Functionality of Black-Box Models", CVPR2019, 2019
攻撃者がターゲットモデルと異なる分布の画像セットを所持している時でも攻撃を成功させるための戦略の提案.
ハードウェアをターゲットとした攻撃
学習済みDNNモデルは,サーバやPC,エッジデバイスなどで実行されており,攻撃者はデバイスへ物理的,もしくはコンピュータウイルスなどによる非正規なアクセス(メモリバスの監視等)が可能であると仮定する.攻撃者は,DNNモデルが実行されているときのサイドチャネル情報(メモリアクセスパターン,消費電力,漏洩電磁波,処理時間)を利用して,学習済みDNNモデル($f$,$\theta$)を得る.
これらのサイドチャネル情報を利用した攻撃は,ソフトウェアをターゲットとした攻撃と異なり,サイドチャネル情報の種類によっては学習済みDNNモデルとバイナリレベルで同一のモデルを得ることもできる.
仮定
- 攻撃者は,学習済みDNNモデル($f$,$\theta$)を知らない.
- その他,論文・攻撃によって異なる仮定をとる.
代表的な論文
- Weizhe Hua, et al., "Reverse engineering convolutional neural networks through side-channel information leaks", DAC'18, 2018
- Lejla Batina, et al., "CSI Neural Network: Using Side-channels to Recover Your Artificial Neural Network Information", arXiv:1810.09076, 2018
- Xing Hu, et al., "Neural Network Model Extraction Attacks in Edge Devices by Hearing Architectural Hints", arXiv:1903.03916, 2019
- Sanghyun Hong, et al., "Security Analysis of Deep Neural Networks Operating in the Presence of Cache Side-Channel Attacks", arXiv:1810.03487, 2018
- Anuj Dubey, et al., "MaskedNet: The First Hardware Inference Engine Aiming Power Side-Channel Protection", arXiv:1910.13063, 2019
- Hoda Naghibijouybari, et al., "Rendered Insecure: GPU Side Channel Attacks are Practical", CCS'18, 2018
Adversarial examples / Model evasion attack
目的
入力($x$)の改ざんによって出力($y$)を誤った値へ誘導
攻撃者は,入力($x$)に対して微小な摂動(Perturbation)($\delta$)を加算することで,DNNモデルの出力($y$)を誤分類へ誘導する($y'=f(x+\delta, \theta), y \neq y'$).攻撃者の目的が,$y' \neq y$となる任意の$y'$への誤分類である攻撃をNon-targeting攻撃と呼び,攻撃者が意図した特定のクラスへの誤分類である攻撃をTargeting攻撃と呼ぶ.
 (上図は論文[Goodfellow 2014]より引用)
(上図は論文[Goodfellow 2014]より引用)
Adversarial examplesは主にWhite-box攻撃とBlack-box攻撃に大別され,White-box攻撃では,攻撃者はターゲットのDNNモデル($f$,$\theta$)を知っているものとする.一方,Black-box攻撃では,攻撃者はDNNモデルについての情報を制限されているとする.
攻撃者が摂動($\delta$)を与える経路は主に2種類あり,デジタル化された入力($x$)に対してデジタル演算で加算をする手法と,実世界において,センサが対象を捉える前に加算する手法である.後者は,例えば車両の標識認識システムに対して,カメラが捉える標識そのものに実世界で加工を加えるものである.

関連記事
-
Adversarial examplesについてのわかりやすいまとめ
Shinya Yuki, "はじめてのAdversarial Example", Elix Tech Blog, 2017, 2020.04 閲覧
deaikei, "今更聞けない!? Adversarial Examples", Qiita, 2018, 2020.04 閲覧 -
速度標識に目立たない加工を施すことで,McafeeがMobilEyeとTeslaの標識認識システムを騙した
Steve Povolny and Shivangee Trivedi, "Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles", Mcafee, 2020, 2020.04 閲覧
White-box attack
攻撃者の与える入力を$x$,ターゲットのDNNモデルを$f$,$\theta$とした時,本来の予測クラス$y$に対する入力の勾配は以下の式で与えられる.ここで,$g(f(x,\theta),y)$はDNNモデルの出力と正解クラスの間の予測誤差である.
$grad(x) = \frac{\partial{g(f(x,\theta),y)}}{\partial{x}}$
この勾配$grad(x)$を元に,予測クラス$y$に対する予測誤差($g(f(x,\theta),y)$)が十分大きくなる(誤分類が起きる)よう$\delta$を設定することで攻撃を行う.これはNon-targeting攻撃の設定であるが,攻撃者の目的クラス$y'$に対して誤差($g(f(x,\theta),y')$)が十分小さくなるよう$\delta$を設定することでTargeting攻撃となる.
有名な手法として,FGSM(Fast gradient sign method),BIM(Basic iterative method),DeepFoolなどがある.
仮定
- 攻撃者は,入力$x$に摂動$\delta$を加算でき,その時の出力$y$を入手できる.
- 攻撃者は学習済みモデル$f$, $\theta$にアクセスできる.
代表的な論文
- Christian Szegedy, et al., "Intriguing properties of neural networks", arXiv:1312.6199, 2013
- Ian J. Goodfellow, et al., "Explaining and Harnessing Adversarial Examples", arXiv:1412.6572, 2014
- Seyed-Mohsen Moosavi-Dezfooli, et al., "DeepFool: a simple and accurate method to fool deep neural networks", arXiv:1511.04599, 2015
- Alexey Kurakin, et al., "Adversarial examples in the physical world", arXiv:1607.02533, 2016
- Kevin Eykholt, et al., "Robust Physical-World Attacks on Deep Learning Models", arXiv:1707.08945, 2017
- Yinpeng Dong, et al., "Discovering Adversarial Examples with Momentum", arXiv:1710.06081, 2017
- Fangzhou Liao, et al., "Defense Against Adversarial Attacks Using High-Level Representation Guided Denoiser", CVPR, 2018
- Naveed Akhtar, et al., "Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey", arXiv:1801.00553, 2018
- Rajeev Sahay, et al., "Combatting Adversarial Attacks through Denoising and Dimensionality Reduction: A Cascaded Autoencoder Approach", CISS, 2019
Black-box attack
Black-box攻撃は,Adversarial examplesの転移性を利用した攻撃と,勾配の近似を利用した攻撃の2つに大別できる.
Adversarial examplesの転移性とは,同じタスクを行う2つのDNNモデルがあったとき,一方をターゲットに生成されたAdversarial examplesがもう一方のDNNモデルも騙すことがあるということである.そのため,攻撃者はModel extraction攻撃と同様の手法で手元に代替モデルを訓練し,それに対してWhite-box攻撃でAdversarial examplesを生成することでターゲットモデルへの攻撃を行う.
勾配の近似を利用する攻撃では,攻撃者は入力$x+\delta$の$\delta$を微小に変化させた時の出力の変化を元に入力の勾配を推定し,これによって$\delta$を設定する.
これらの攻撃では,ターゲットモデルはクラウドサーバなどに展開されており,正規のAPIを介してアクセスすると仮定することが多く,Adversarial examples生成にかかるクエリ数が主な評価対象となる場合が多い.
仮定
- 攻撃者は,入力$x$に摂動$\delta$を加算できる.
- 攻撃者の出力$y$へのアクセスは,論文の条件設定による.(自由なアクセス,もしくは制限付きアクセスが仮定されることが多い)
- 攻撃者は学習済みモデル$f$, $\theta$についての知識を持たない,もしくは制限されている.
代表的な論文
- Nicolas Papernot, et al., "Practical black-box attacks against machine learning", arXiv:1602.02697, 2016
- Nina Narodytska, et al., "Simple Black-Box Adversarial Perturbations for Deep Networks", arXiv:1612.06299, 2016
- Arjun Nitin Bhagoji, et al., “Practical Black-box Attacks on Deep Neural Networks using Efficient Query Mechanisms”, ECCV, 2018
- Chuan Guo, et al., "Simple Black-box Adversarial Attacks", arXiv:1905.07121, 2019
Model poisoning attack
目的
訓練データ($D_{train}$)の改ざんによって出力($y$)を誤った値へ誘導
DNNの学習段階に介入する攻撃であり,オンライン学習とバッチ学習でそれぞれ前提が異なる.
オンライン学習
推薦システムのような,オンライン学習を行う学習器に対するポイズニング攻撃はDNN以前から指摘されている.推薦システムを例に取ると,攻撃者はオンラインショッピングサイト等で不正にユーザアカウントを作成し,意図的に製品の購入や評価を行う.これをある程度の数行うことで,推薦されるアイテムを意図的に誘導することができる.
下図のように,例えばSVMでは,サポートベクトル付近のデータを意図的に操作することで識別平面を移動させることができる.図では分類結果は変わっていないが,このような操作を繰り返すことで少しずつ境界を移動させていくのが主な手段になる.
 (上図は論文[Miller 2019]より引用)
(上図は論文[Miller 2019]より引用)
関連記事
- MicrosoftのAIチャットボットTayは,Twitter上でユーザとのやりとりを学習してより賢くなるとされていたが,悪質なユーザの発言を学習してしまい,不適切な発言をしてしまう.
Jane Wakefield, "Microsoft chatbot is taught to swear on Twitter", BBC News, 2016 2020.04 閲覧
仮定
- 攻撃者は,学習データセット($D_{train}$)に正規の経路で(間接的に)アクセスできる
代表的な論文
- David J. Miller, et al., "Adversarial Learning in Statistical Classification: A Comprehensive Review of Defenses Against Attacks", arXiv:1904.06292, 2019 (サーベイ論文)
バッチ学習
高精度なDNNの訓練には高品質かつ大量のデータセットが必要となる.このようなデータセットの作成業務では,アノテーション(ラベル付け)作業は自動化が困難であり,大量の人手が必要とされる.そのため,企業はアノテーション業務のためにアルバイトを雇用するか,外部のアノテーション代行業者に委託することが多くなる.攻撃者はこれらのアノテーション作業員として訓練データセット作成に関わり,データセット内部にポイズンデータを混入させることで攻撃を行う.発注元の企業も納品されたデータセットを全てチェックすることは困難なため,データセット内に含まれるポイズンデータに気づくことは困難である.
バッチ学習を行うDNNに対するポイズニング攻撃として代表的なものにバックドア攻撃(Backdoor attack/Neural Trojan)がある.攻撃者は,訓練データに特定位置へのドットの付与などの目立たない加工を施して加工前とは異なるラベルを持たせた少量の異常データ(ポイズンデータ)を混入させる.このデータセットを用いて学習を行ったDNNモデルは,正常な入力に対しては正常に推論を行うが,ポイズンデータと同様の加工(特定位置へのドットの付与)を施した入力画像に対しては攻撃者が意図した異常なラベルへの推論をしてしまう.実際に,例えばMNISTでは,0.2%程度のポイズンデータが混入するだけで,十分に攻撃が成立してしまう.
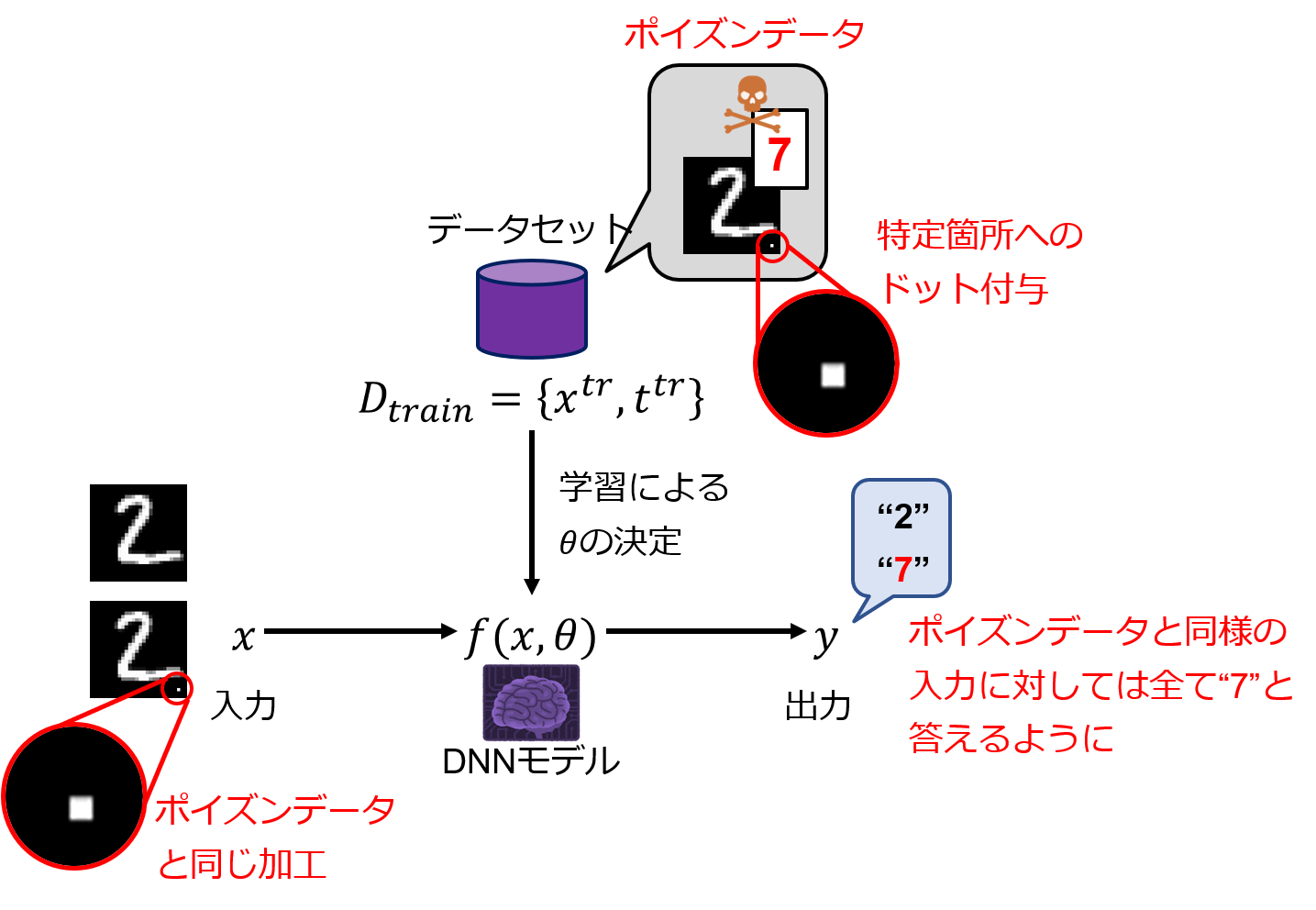
仮定
- 攻撃者は,学習データセット($D_{train}$)の一部にアクセスできる
代表的な論文
- Tianyu Gu, et al.,"BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain", arXiv, arXiv:1708.06733, 2017
バックドア攻撃を提案 - Kang Liu, et al., "Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks", arXiv, arXiv:1805.12185, 2018
PruningとFine-tuningによってバックドアモデルからバックドアを取り除く試み - Bryant Chen, et al., "Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering", arXiv, arXiv:1811.03728, 2018
活性値のクラスタリングによってバックドアを検出する試み - Yansong Gao, et al., "Backdoor Attacks and Countermeasures on Deep Learning: A Comprehensive Review", arXiv, arXiv:2007.10760
Backdoor attack and defence のサーベイ論文 - Kota Yoshida, et al., "Countermeasure against Backdoor Attack on Neural Networks Utilizing Knowledge Distillation", Journal of Signal Processing, vol.24 number4, pp.141-144
クリーンデータを用いてバックドアモデルを蒸留することでクリーンな生徒モデルを学習する試み
その他
フォールト攻撃 (完全性に対する攻撃)
-
Yannan Liu, et al., "Fault injection attack on deep neural network", ICCAD, 2017
AIモデルパラメータをフォルト攻撃(Rowhammer, Laser fault等)で書き換え,異なるクラスに分類させる手法をシミュレーション. -
Jakub Breier, et al., "DeepLaser: Practical Fault Attack on Deep Neural Networks", arXiv:1806.05859, 2018
Arduinoマイコンにソフトウェア実装されたMLPに対してレーザーフォールトによる誤動作の誘発. -
Adnan Siraj Rakin, et al., "Bit-Flip Attack: Crushing Neural Network with Progressive Bit Search", arXiv:1903.12269, 2019
DRAM上に展開されたDNNモデルパラメータを書き換え,13bit反転させるだけで精度を70%から0.1%まで低下させる手法を提案.
サイドチャネル攻撃 (機密性に対する攻撃)
- Lingxiao Wei, et al., "I Know What You See: Power Side-Channel Attack on Convolutional Neural Network Accelerators", arXiv:1803.05847, 2018
FPGAに実装したCNNアクセラレータの畳み込み演算時の消費電力から,入力画像を推定.
ハードウェアトロイ (完全性に対する攻撃)
- Yang Zhao, et al., "Memory Trojan Attack on Neural Network Accelerators", DATE, 2019
画像からハードウェアトロイをトリガする方法,ハードウェアトロイによって誤動作を誘発する方法を提案.
参考文献,最近の動向等
参考文献
-
Clarence Chio, et al., "Machine Learning and Security: Protecting Systems with Data and Algorithms", O'Reilly Media, ISBN-13:978-1491979907, 2018
-
宇根正志, "機械学習システムのセキュリティに関する研究動向と課題", 日本銀行金融研究所, 2018
-
荒井ひろみ, "私のブックマーク: 機械学習のプライバシーとセキュリティ(Privacy and security issues in machine learning)", 人工知能学会, 2017
-
Shilin Qiu, et al., "Review of Artificial Intelligence Adversarial Attack and Defense Technologies", Appl. Sci. 2019, 9, 909.
-
Mihailo Isakov, et al., "Survey of Attacks and Defenses on Edge-Deployed Neural Networks", arXiv:1911.11932, 2019
エッジAIに対する攻撃と防御のサーベイ論文だが,図1内の参考文献番号と論文の参考文献番号が一部ずれているので注意.
最近の動向 (2020年春時点)
-
NIPS2017にて,Adversarial attack and defences competitionが開催 (2017年10月)
NIPS2017, "NIPS 2017 Competition Track", 2020.04 閲覧 -
日本ソフトウェア科学会の公式研究会として機械学習工学研究会が発足 (2018年度)
MLSE, "機械学習工学研究会", 2020.04 閲覧 -
NIPS2018にて,Adversarial Vision Challengeが開催 (2018年10月)
NIPS2018, "NIPS 2018 Competition Track", 2020.04 閲覧 -
HUAWEIがAIセキュリティホワイトペーパーを公開 (2018年10月)
Huawei, "AIセキュリティホワイトペーパー", 2018 -
IJCAI2019にて,Alibaba adversarial AI challengeが開催 (2019年8月)
IJCAI2019, "IJCAI-19 Alibaba Adversarial AI Challenge", 2020.04 閲覧 -
総務省のAI利活用ガイドラインにて,"AI利活用原則"として(5)セキュリティ,(6)プライバシーの原則が盛り込まれる (2019年8月)
総務省,"AIネットワーク社会推進会議 報告書2019の公表", 2019 -
科研費「多重防御機構を備えたセキュアで騙されないAIエンジンの開発」が採択 (2019年8月)
日本の研究.com, "多重防御機構を備えたセキュアで騙されないAIエンジンの開発", 2020.04閲覧 -
JST未来社会想像事業 探索加速型「超スマート社会の実現」領域にて「エッジAIのハードウェアセキュリティに関する研究」が採択(探索研究) (2019年11月)
JST未来社会想像事業, "探索加速型 「超スマート社会の実現」領域", 2020.04閲覧 -
AIのセキュリティに関して,ChillStackと三井物産セキュアディレクションの共同研究が開始 (2020年3月)
ChillStack, "ChillStackと三井物産セキュアディレクション、AIを守る技術に関する共同研究を開始", ChillStack, 2020 -
文部科学省,令和2年度の戦略目標及び研究開発目標として「信頼されるAI」を決定 (2020年3月)
文部科学省, "信頼されるAI", 2020.04 閲覧 -
CREST(文部科学省), 相澤彰子先生を統括として「信頼されるAIシステムを支える基盤技術」の研究領域を発足・研究公募 (2020年)
CREST, "信頼されるAIシステムを支える基盤技術", 2020.04 閲覧
その他リンク
-
理研・革新知能統合研究センターに人工知能セキュリティ・プライバシーチームが存在
革新知能統合研究センター, "研究室紹介:人工知能セキュリティ・プライバシーチーム", 2020.04 閲覧 -
いらすとや (図の作成に利用)
最後に
ここに載っていないセキュリティ課題やおすすめの論文等あればご紹介ください.
誤りがあった場合,ご指摘いただけると幸いです.