パーティショニングとは
論理的に1つの大きなテーブルを、物理的に小さなパーティションに分けることです。
分割には「テーブル間の分割」と「ノード間の分割」があるそうですが、今回テーブル間の分割について勉強をしたかったので、こちらについてまとめます。
テーブル間の分割
アプリケーション側からは一つに見えるテーブルから、トリガを使用して各子テーブル(パーティション)へデータを格納します。
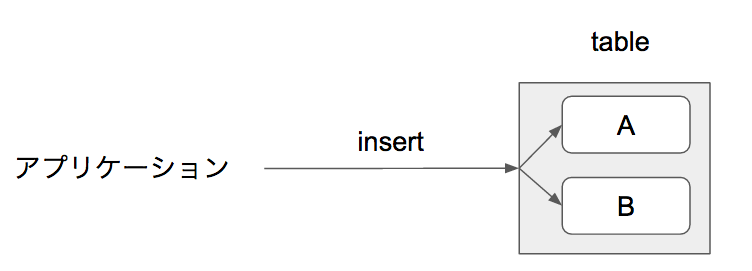
メリット
・分割されていることにより検索対象が絞り込まれ、処理効率が上がる
・パーティションをまとめて削除できる(drop table)
・キャッシュを有効活用できる
デメリット
・親テーブルへのインサートをトリガを使用して子テーブルへ振り分けるため、インサートの性能が悪くなる
分割方法
分割の方法には「水平分割」と「垂直分割」の2つがあります。
-
水平分割
テーブルの各行をそれぞれのパーティションへ分散させる方法です。
ユーザーの住所でそれぞれの都道府県のパーティションへ分割したり、作成された月ごとに分割したりします。 -
垂直分割
テーブルの一部だけをパーティションへ抜き出す方法です。
利用頻度の低い列や非常に桁数の多い列だけを抜き出します。
分割基準
分割する際にどのように分割するかを判断するために分割キーを使用する音ですが、その分割の基準として「レンジ分割」「リスト分割」「ハッシュ分割」の3種類があります。
- レンジ分割
分割キーの値が範囲内にあるかどうかで分割します。 - リスト分割
分割キーの値がリスト内に存在するかどうかで分割します。 - ハッシュ分割
ハッシュ関数の値によってパーティションに含めるかどうかを決定します。
実際にやってみる
今回は下記のドキュメントを参考に行ってみます。
https://www.postgresql.jp/document/9.4/html/ddl-partitioning.html
テーブルを作成する
まずはマスタテーブルを作成する(親テーブル)
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
);
それぞれのパーティションを作成する(子テーブル)
今回はそれぞれの月に対してパーティションを作成します。(ドキュメントと少し変更しています)
CREATE TABLE measurement_y2016m12 (
CHECK ( logdate >= DATE '2016-12-01' AND logdate < DATE '2017-01-01' )
) INHERITS (measurement);
CREATE TABLE measurement_y2016m11 (
CHECK ( logdate >= DATE '2016-11-01' AND logdate < DATE '2016-12-01' )
) INHERITS (measurement);
CREATE TABLE measurement_y2016m10 (
CHECK ( logdate >= DATE '2016-10-01' AND logdate < DATE '2016-11-01' )
) INHERITS (measurement);
今回作成したテーブルはmeasurement(マスタテーブル)を継承しているため、構造は同じになっています。
また、各テーブルにCHECK〜で日付の制約を行っています。
設定を変える
インデックスをつける
CREATE INDEX measurement_y2016m12_logdate ON measurement_y2016m12 (logdate);
CREATE INDEX measurement_y2016m11_logdate ON measurement_y2016m11 (logdate);
CREATE INDEX measurement_y2016m10_logdate ON measurement_y2016m10 (logdate);
関数を作成してトリガを設定する
一番新しい月のパーティションへデータを入れたい場合にはこのように設定します。
--関数の作成
CREATE OR REPLACE FUNCTION measurement_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO measurement_y2016m12 VALUES (NEW.*);
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
-- トリガの作成
CREATE TRIGGER insert_measurement_trigger
BEFORE INSERT ON measurement
FOR EACH ROW EXECUTE PROCEDURE measurement_insert_trigger();
データを扱う
トリガを設定してある12月のデータをインサートする
INSERT INTO measurement(city_id, logdate, peaktemp, unitsales) VALUES(1, '2016-12-01', 20, 1000);
-- INSERT 0 0
SELECT * FROM measurement;
SELECT * FROM measurement_y2016m12;
インサートが0になっているが、これは内部的に元のインサートをキャンセルして、パーティションに別のインサートを行っているため、表示が0になっているらしい。
セレクトはどちらでもできたので、うまくトリガで振り分けが行われています。
トリガを設定していないデータをインサートする
今回はまだ12月分のデータが入ってくることしか想定されていません。
そこに11月のデータを入れたらどうなるのでしょうか。
INSERT INTO measurement(city_id, logdate, peaktemp, unitsales) VALUES(1, '2016-11-01', 20, 1000);
ERROR: new row for relation "measurement_y2016m12" violates check constraint "measurement_y2016m12_logdate_check"
DETAIL: Failing row contains (1, 2016-11-01, 20, 1000).
CONTEXT: SQL statement "INSERT INTO measurement_y2016m12 VALUES (NEW.*)"
PL/pgSQL function measurement_insert_trigger() line 3 at SQL statement
案の定エラーになってしまいました。
11月のデータも12月のテーブルへ割り振られ、チェックでかけた制約により弾かれているようです。
パーティショニングを設定するときには、どのようなデータが入ってくるのか注意しないといけないですね。
まとめ
設定自体はドキュメントを参考にするととてもわかりやすいと思います。
ただ、どの程度処理効率が向上したのかを計測しておいたほうがよさそうです。