株式会社ヒトクセの開発合宿に参加させて頂きました!
フルスピードの鈴木です!
ちなみに自分のキャッチコピーがフルスピードという訳ではなく、
会社名がフルスピードなので、ご注意ください(笑)
もちろん、名前に恥じぬよう全速力で日々、開発しております!
まあ、冗談はこのくらいにして、株式会社ヒトクセというリッチ広告などの
サービスを扱っている会社の開発合宿に参加させて頂いたので、
レポートを書きたいと思います!
- 株式会社ヒトクセ
会社HP: http://hitokuse.com/
技術ブログ: http://hitokuse.com/blog/?p=581
##合宿の特徴
ヒトクセの開発合宿の特徴は下記の3つです。
-
特定のテーマなし!
-> 運営側から特定のテーマを押し付けることはありません。日頃、まとまった時間が無いと挑戦できない自分のテーマに取り組むことができます。 -
外部の方の参加も可能!
-> ヒトクセ社員でなくても参加できます!様々なバックグラウンドのエンジニアが様々な技術を試すので、一緒に開発しているだけでも勉強になります。 -
チームを組める!
-> 参加者の中でまだ開発するものを決めていない人は、他の人のプロジェクトにチームとして参加することもできます。普段とは異なるメンバーと協働できるので勉強になります。
ちなみに参加者は合計15名、そのうちヒトクセ社員は7名。他社エンジニアや学生エンジニアが8名と、ついに外部参加者の方が多数派になりました!
##今回の開催場所
山喜旅館

出典: http://www.ito-yamaki.jp/
開催場所は伊東の「山喜旅館」。開発合宿プランを有する数少ない旅館です。
新宿から電車で約3時間。交通費が往復3,000円+宿泊費14,000円(2泊)、
合計17,000円という超リーズナブルなお値段です。
##合宿のスケジュール
-
1日目
・LT
– AWS Rekognition
– AWS Athena
– TypeScript
・各自開発 -
2日目
・各自開発
・成果発表&投票
・懇親会 -
3日目
・自由行動
- 合宿の様子

私が開発した内容
今回、私は個人的に開発したいものがあったので、個人で
サービスを作成しました!
内容としては、Googleの検索順位を調べ、SEOの強さを独自の基準で評価する分析ツールを作成しました。
###使用した技術
PHP,JavaScript,Juman++,d3.js,JQuery,SimpleHTMLDOMParserなどです。
###仕組み

1.SimpleHTMLDOMParserでGoogleに検索をかけて、DOMを取得する。
※ソースは一部、抜粋
<?php
require_once('./GoogleSearch.php');
header('Content-Type: application/json');
$query = $_POST['query'];
$data = [];
$googleSearch = new GoogleSearch();
$keyword = $query['keyword'];
$searchCount = $query['searchCount'];
$data = $googleSearch->search($keyword,$searchCount);
echo json_encode($data);
<?php
require_once '../simple_html_dom.php';
require_once './GoogleAnalysisKeyword.php';
/**
* Google検索を行うクラス
*
*/
class GoogleSearch
{
/**
* 検索を実行する
*
* @param $keyword
* @param $area
* @param $searchCount
* @return $resultCount
*/
public function search($keyword,$area,$searchCount)
{
//文字化け対策
mb_language('Japanese');
//検索アドレスと件数の指定
$url = 'http://www.google.co.jp/search?num='.$searchCount.'&ie=UTF-8&q=' . urlencode($keyword);
//URLからDOMを取得
$html = file_get_html($url);
//検索結果件数を取得
$resultCount = $html->find('div[id=resultStats]');
return $resultCount;
}
下記のソースの部分でDOM要素を取得し、その中から$html->find('html要素名')
を指定する事で、自分が取得したい対象のDOM要素を指定する事ができます。
//URLからDOMを取得
$html = file_get_html($url);
//検索結果件数を取得
$resultCount = $html->find('div[id=resultStats]');
2.取得したDOMのコンテンツ内容をJuman++に渡して、形態素解析を行い、名詞だけ抽出し、出現回数をカウントする。
- 補足
juman++ で「けんさくえんじんぐーぐる」などで解析した場合、このような出力結果が返ってきます。
詳しくは http://qiita.com/riverwell/items/438e88427363511e9f28
参照。
けんさくえんじんぐーぐる
けんさく けんさく けんさく 名詞 6 サ変名詞 2 * 0 * 0 "代表表記:検索/けんさく カテゴリ:抽象物 ドメイン:家庭・暮らし"
@ けんさく けんさく けんさく 名詞 6 サ変名詞 2 * 0 * 0 "代表表記:建策/けんさく カテゴリ:抽象物"
えんじん えんじん えんじん 名詞 6 普通名詞 1 * 0 * 0 "代表表記:円陣/えんじん カテゴリ:形・模様"
ぐーぐる ぐぐる ぐぐる 名詞 6 普通名詞 1 * 0 * 0 "自動獲得:Wikipedia Wikipediaリダイレクト:Google 非標準表記"
EOS
// DOMの中からbody要素を取得
$body = $html->find("body");
$googleAnalysisKeyword = new GoogleAnalysisKeyword();
if (!empty($body)) {
$wordList = $googleAnalysisKeyword->analysisKeyword($body[0]->plaintext);
return $wordList;
}
<?php
class GoogleAnalysisKeyword
{
public function analysisKeyword($bodyKeywordData)
{
// Juman++の形態素解析を実行する
$outputs = array_reverse(preg_split("/EOS|\n/u", shell_exec(sprintf('echo %s | /usr/local/bin/juman', escapeshellarg($bodyKeywordData)))));
// 名詞を抽出
$meisiList = []; //名詞配列
foreach ($outputs as $output) {
if (preg_match('/名詞/', $output)) {
$chars = preg_split('/ /', $output, -1, PREG_SPLIT_OFFSET_CAPTURE);
$meisiList[] = $chars[0][0];
}
}
$word_list = [];
$word_list_index = [];
foreach ($meisiList as $meisi) {
$key = array_search($meisi, $word_list_index);
if ($key === false) {// 新出
if($meisi=='@'){
continue;
}
$word_list[] = ['count' => 1, 'word' => $meisi];
$word_list_index[] = $meisi;
} else {// 既出
$word_list[$key]['count'] = $word_list[$key]['count'] + 1;
}
}
unset($word_list_index);
arsort($word_list);
return $word_list;
}
}
3.Jsonに変換してjs側に渡す。
<?php
require_once('./GoogleSearch.php');
header('Content-Type: application/json');
$query = $_POST['query'];
$data = [];
$googleSearch = new GoogleSearch();
$keyword = $query['keyword'];
$searchCount = $query['searchCount'];
$data = $googleSearch->search($keyword,$searchCount);
echo json_encode($data);
4.js側で受け取ったJsonデータを元にd3.jsで名詞のリストを可視化する。
※今回はキーワード「東京」で検索にひっかかったサイトの情報を解析した例。
- d3.js 参考URL
https://d3js.org/
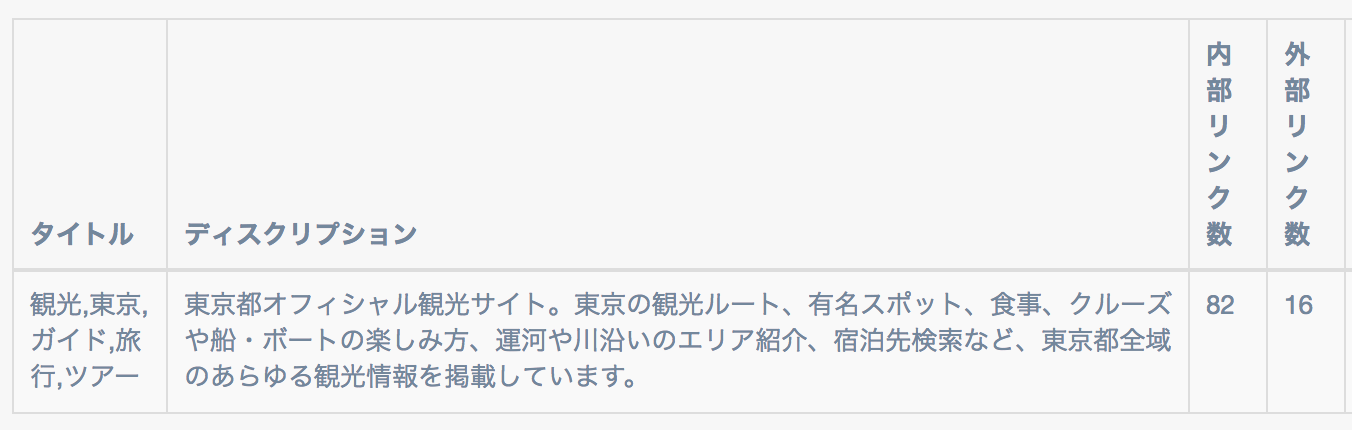

こんな感じで名詞の出現頻度に基づいて、可視化する事ができました。
また、その他の情報も正規表現などを使って抽出しました。
- 成果発表の様子

##合宿に参加してみた所感
以前から、エンジニアをやっていると、自分で外に出て行かないと、
全然、情報が入ってこないなと思っていました。
他社の開発合宿に行く事によって、自分の実力や自分の働いている会社で
使っている技術はちゃんと最適化されているのか?もっと、最新の技術を使えば効率化できるのではないか?など、いろいろ学べる点があるなと思いました。
今後も自分の働いている会社に固執する事なく、積極的にハッカソンや開発合宿に
参加していこうと思います!!