はじめに
今更SQLと題して、SQLの現場ノウハウを記載するシリーズ。(続けていきたいという意志を込めて。。)
SQLは習熟しており、所謂、「枯れた」プログラムに分類されると思います。
ところが、基礎的な使い方は載っているものの
現場で使うノウハウは散らばっており、初学者の障壁になっていると感じる部分も多々あります。
そういった障壁をなくせたらいいなと思ったので、これまで培ってきたSQLのノウハウをまとめてようと思います。
今回はSQL作成時の考え方とそれに基づいた書き順をご紹介します。
対象者
- テーブル結合があるSQLに自信がない方
- SQL中のデータがどうなっているかイメージしたい方
書き順 ズバリ答え
これが答えです。
FROM
→WHERE
→JOIN
→ON
→(JOINしたテーブルに対するWHERE)
→GROUP BY
→HAVING
→SELECT
→ORDER BY
お気づきでしょうか?SELECTってめっちゃ後ろなんです。
この順番は実際にデータに対する以下のアプローチに沿って記載していく順番になるので、考えも整理しやすいです。
・欲しいデータ(登場人物)とその関係を書く(FROM→WHERE→JOIN→ON→WHERE)。
・必要な粒度にそろえて(GROUP BY)、さらに絞り込む(HAVING)。
・欲しいデータが欲しい粒度で揃ったので、漸くSELECT句でほしい項目だけ指定する。
記載順に沿ったデータイメージ
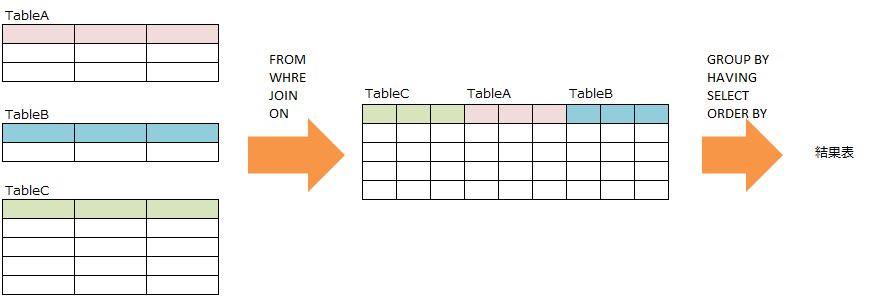
詳しく見ていきましょう。
Lesson: テーブル結合
お題1
ある一日の販売情報が見たい。
何がいつ、何個売れたかが見たい。
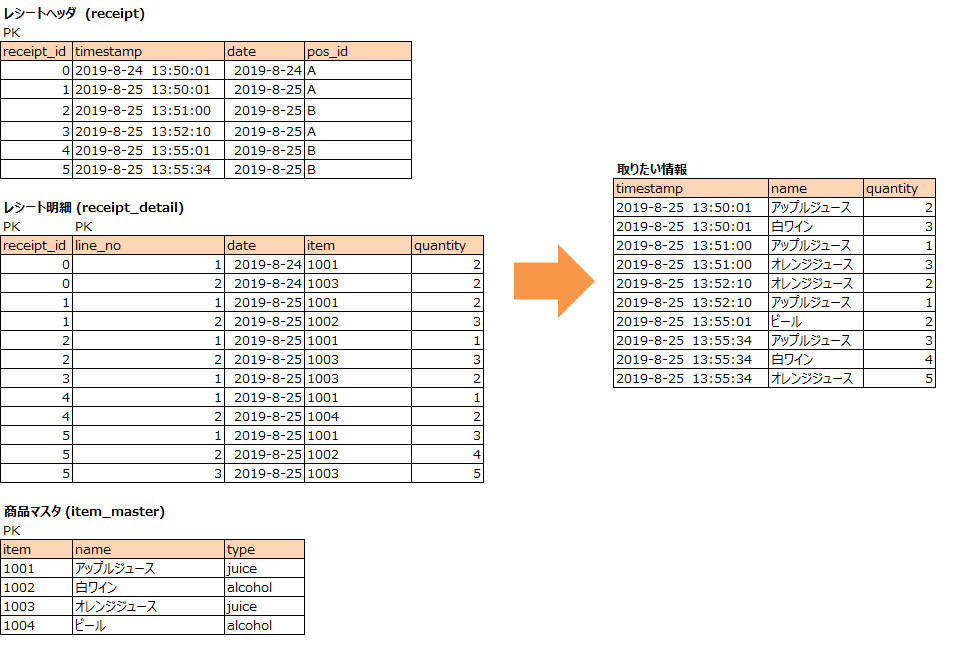
(ここで手が止まる人が本記事の対象者です。このお題のSQLを息するように書ける人は本記事の対象外です。)
考え方
1. 最初に読み込むテーブルを決める
1つのテーブルを他テーブルでどんどん肉付けしていくことを考えます。
最終結果のデータ粒度と同じデータ粒度のものがあれば、そのテーブルを使うのがよいでしょう。
ということで、まずはここまで書けます。
SELECT
*
FROM
receipt_detail dtl
WHERE
dtl.date = '2019-08-25'/*request.date*/
;
SELECTは先に適当にSELECT * で書いておきます(書いたほうがSQLエディタツール的に色々都合がいいため)。
最後にちゃんとしたものに変えていきます。、
ここまで書いて一度SQLを実行して、欲しい粒度の欲しい範囲のデータが取れているか確認するとよいでしょう2。
2. テーブルを結合していく
テーブルを結合していきます。
このとき注意すべき最大のポイントは結合でデータが膨れないかです。
特殊な要件3がない限り、主キー(Primary Key/PK)かユニークキー(Unique Key/UK)を使って結合します。
SELECT
*
FROM
receipt_detail dtl
INNER JOIN
receipt rpt
ON
rpt.receipt_id = dtl.receipt_id
INNER JOIN
item_master itm
ON
itm.item = dtl.item
WHERE
dtl.date = '2019-08-25'/*request.date*/
;
ここまででSQLの骨格ができました。最後にSELECT句を手入れして完成です。
※ON句の条件式はJOINで指定したテーブルを左辺にするのが好みです。
dtl.receipt_id = rpt.receipt_idではなくrpt.receipt_id = dtl.receipt_id。
ONで指定するのはJOINするテーブルに対する条件なので。
ということで、↓のSQLで完成です。
SELECT
rpt.timestamp
, itm.name
, dtl.quantity
FROM
receipt_detail dtl
INNER JOIN
receipt rpt
ON
rpt.receipt_id = dtl.receipt_id
INNER JOIN
item_master itm
ON
itm.item = dtl.item
WHERE
dtl.date = '2019-08-25'/*request.date*/
;
Q: どの項目で結合すればよいかわかりません。結合条件ってどうやって決めればいいですか。
ある程度使える回答
A. 次の2つの条件を満たす項目を探しましょう。該当するものがあれば8割方その項目です。
- 結合したいテーブル同士で名前が同じ項目。
- どちらかのテーブルの主キーになっている項目。
名前が同じ項目がなければ、聞くほうがいいと思います。
聞く前に推測してもいいとは思いますが(例えば hogehoge_itemのように接頭辞がついているかもしれません。)。
…まったく予測できない名前で結合するようなものだったら、テーブル設計イケてないなぁと思いましょう。
ちゃんとした回答
A. テーブルの関係が記載されたERD(Entity Relationship Diagram)を見ましょう。
そこには各テーブルの関係性が載ってます4。これをみて、各テーブルが何とつながっているかを見るようにしましょう5。
ERDのドキュメントがなかったとしても、テーブル構造からこのERDをイメージすることができます。
お題のERD
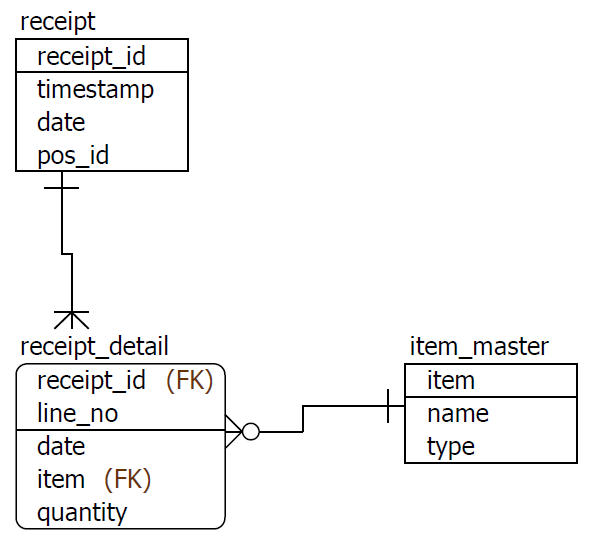
※RDB(Relational Database)はその名の通り、関係(Relation)が命です。
その関係性を記載したERDはRDBにとってめちゃくちゃ重要なドキュメントです。
最初は難しいかもしれませんが、可能な限りERDは意識してSQLを書いていきましょう。
結合できた!その先
GROUP BYやHAVINGはLessonのようにかき集めてきたデータをSELECTの直前に集計するだけです。
上記のLessonに書いたものが基本形にして最も重要です(なので記載は割愛。。)。
まとめ
1. SQLの書き順
・欲しいデータ(登場人物)とその関係を書く(FROM→WHERE→JOIN→ON→WHERE)。
・必要な粒度にそろえて(GROUP BY)、さらに絞り込む(HAVING)。
・欲しいデータが欲しい粒度で揃ったので、漸くSELECT句でほしい項目だけ指定する。
2. 大事な考え方
・1つのテーブルを他テーブルでどんどん肉付けしていく。
・結合でデータが膨れないか。
これさえ覚えれば色んな問題にアプローチできるようになると思います。
また、テーブルデザインのパターンやそれに応じたSELECTクエリのパターンも存在します。
そちらも追って紹介したいと思います。
使用したデータ
/* PostgreSQL */
CREATE TABLE receipt (
receipt_id numeric(3)
, timestamp timestamp
, date date
, pos_id varchar(3)
, CONSTRAINT pk_receipt PRIMARY KEY(receipt_id)
);
CREATE TABLE receipt_detail (
receipt_id numeric(3)
, line_no numeric(3)
, date date
, item varchar(4)
, quantity numeric(3)
, CONSTRAINT pk_receipt_detail PRIMARY KEY(receipt_id, line_no)
);
CREATE TABLE item_master (
item varchar(4)
, name varchar(100)
, type varchar(25)
, CONSTRAINT pk_item_master PRIMARY KEY(item)
);
INSERT INTO receipt
VALUES
(0,'2019-8-24 13:50:01','2019-8-24','A')
,(1,'2019-8-25 13:50:01','2019-8-25','A')
,(2,'2019-8-25 13:51:00','2019-8-25','B')
,(3,'2019-8-25 13:52:10','2019-8-25','A')
,(4,'2019-8-25 13:55:01','2019-8-25','B')
,(5,'2019-8-25 13:55:34','2019-8-25','B')
;
INSERT INTO receipt_detail
VALUES
(0,1,'2019-8-24','1001',2)
,(0,2,'2019-8-24','1003',2)
,(1,1,'2019-8-25','1001',2)
,(1,2,'2019-8-25','1002',3)
,(2,1,'2019-8-25','1001',1)
,(2,2,'2019-8-25','1003',3)
,(3,1,'2019-8-25','1003',2)
,(4,1,'2019-8-25','1001',1)
,(4,2,'2019-8-25','1004',2)
,(5,1,'2019-8-25','1001',3)
,(5,2,'2019-8-25','1002',4)
,(5,3,'2019-8-25','1003',5)
;
INSERT INTO item_master
VALUES
('1001','アップルジュース','juice')
,('1002','白ワイン','alcohol')
,('1003','オレンジジュース','juice')
,('1004','ビール','alcohol')
;
おまけ
今更SQLシリーズ
その他
技術ブログ:システム開発で得たRedis利用ノウハウ
-
予約語を項目名に使っちゃってますが、みなさんはテーブルのカラム名に予約語は使わないようにしましょうね(timestamp, date)。 ↩
-
件数が多いテーブルについては次のオプションをつけて取得件数を制限しておいたほうがよいです。
LIMIT 100 /* PostgreSQL */rownum < 100 /*ORACLE*/SELECT TOP 100 ... /*SQL Server*/↩ -
特殊な要件は設計を知ってるか・知らないかのレベルになるため、ドキュメントとして書かれているか、直接話がなければわからない部分です。気になる点が見つかったら、設計者(もしくはデータ抽出依頼者)に確認しましょう。 ↩
-
マスタとのリレーションは自明で冗長にもなるので、省略しているドキュメントもあります。 ↩
-
ERDよりも、外部キー(Forign Key/FK)を結合条件として使うことが確実な方法です。しかし、外部キー制約は面倒な面もあるため、大規模なシステムだとその制約を使わないことが多いです(参照データがあるレコードは消せない&参照元にデータがないと登録できない→テスト時のちょっとしたデータ変更がすぐにできない。テーブルデータを洗い替えるDELETE-INSERTができない)。このため、本記事ではERDで関係を見ることを推奨しています。 ↩