はじめに
今更SQLと題して、SQLの現場ノウハウを記載するシリーズ。(続けていきたいという意志を込めて。。)
SQLは習熟しており、所謂、「枯れた」プログラムに分類されると思います。
ところが、基礎的な使い方は載っているものの
現場で使うノウハウは散らばっており、初学者の障壁になっていると感じる部分も多々あります。
そういった障壁をなくせたらいいなと思ったので、これまで培ってきたSQLのノウハウをまとめてようと思います。。
今回は分析関数の中で、特に業務システムで使えるものをピックアップしてみました。
他にもこんな使い方もあるよーなどのコメント大歓迎です。是非教えてください。
書いてないこと
- どんな分析関数があるか(分析関数の一覧とか)
書いてること
- 分析関数ユースケース
分析関数とは
ざっくり
GROUP BY的なことを行数を集約せずにできたりします。
集計関数と分析関数の違いなどの、分かりやすいイメージは こちらの記事 に記載があります。
使いどころ
- SELECTした各行とは別の行が関係する値を表示したい場合
分析関数動作確認済のRDBMS
- ORACLE
- SQL Server
- PostgreSQL
- (多分MySQLも)
目次
- SUM~合計、累積、構成比、累積比~
- ROW_NUMBER, RANK, DENSE_RANK~ルール絞る、おてがる分散番号~
- LAG, LEAD~履歴データから変更前データ取得~
- まとめ
SUM ~合計、累積、構成比、累積比~
お題
販売トランから時間帯別に以下のように販売数量を計算することができたとします。
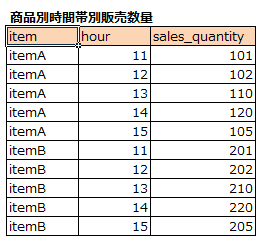
上司にこれを見せたところ、次の要望が。
「どの時間帯の売上が一日の何割を占めているか知りたい。1日の売上のうち、5割占めるのがいつまでか、8割占めるのがいつかを知りたい」
・・・
・・・
・・・
うりゃ!!
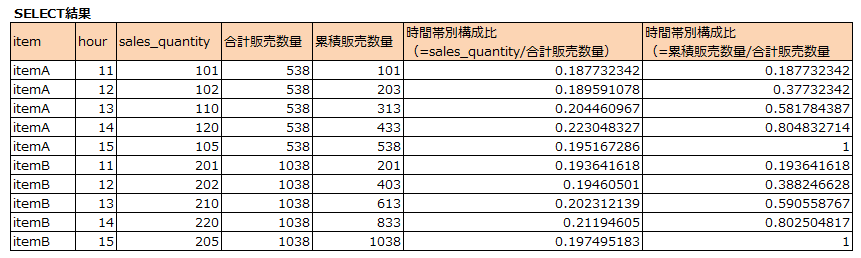
これで、時間帯別の売上構成比がわかりましたね。また、itemA, itemBともに1日の販売数量のうち、13時に5割を、14時に8割を超えることもわかりました。
クエリ
SELECT
s.item
, s.hour
, s.sales_quantity
, SUM(s.sales_quantity) OVER (PARTITION BY s.item) AS "合計販売数量"
, SUM(s.sales_quantity) OVER (PARTITION BY s.item ORDER BY s.hour) AS "累積販売数量"
, CASE SUM(s.sales_quantity) OVER (PARTITION BY s.item) WHEN 0 THEN 0 --0除算考慮
ELSE
s.sales_quantity
/ SUM(s.sales_quantity) OVER (PARTITION BY s.item)
END AS "時間帯別構成比(=sales_quantity/合計販売数量)"
, CASE SUM(s.sales_quantity) OVER (PARTITION BY s.item) WHEN 0 THEN 0 --0除算考慮
ELSE
SUM(s.sales_quantity) OVER (PARTITION BY s.item ORDER BY s.hour)
/ SUM(s.sales_quantity) OVER (PARTITION BY s.item)
END AS "時間帯別構成比(=累積販売数量/合計販売数量)"
FROM
sample s
解説
SUM(s.sales_quantity) OVER (PARTITION BY s.item) はitem項目で区切って、その範囲でsales_quantityをSUMするという分析関数。これで各行に合計値をセットできます。
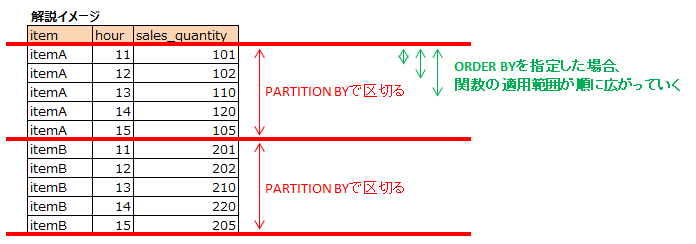
SUM(s.sales_quantity) OVER (PARTITION BY s.item ORDER BY s.hour) はitem項目で区切って、その範囲でhourでORDER BYします。そのうえで sales_quantityをSUMするという分析関数です。ORDER BYを加えるとSUMの範囲が順に広がるため1、このように累積和を求めることができます。
後は、合計値と時間帯別販売数量で構成比を、合計値と累積和で累積比を出せばよいです。
使用したデータ
/* PostgreSQL */
CREATE TABLE sample (item varchar(5), hour varchar(2), sales_quantity numeric(5) , CONSTRAINT pk_samle PRIMARY KEY (item, hour));
INSERT INTO sample
VALUES
('itemA','11',101)
,('itemA','12',102)
,('itemA','13',110)
,('itemA','14',120)
,('itemA','15',105)
,('itemB','11',201)
,('itemB','12',202)
,('itemB','13',210)
,('itemB','14',220)
,('itemB','15',205)
;
ROW_NUMBER, RANK, DENSE_RANK~ルールで絞る、おてがる分散番号~
お題1
荷物のヘッダには中に入っている荷物のうち、一番値段が高いものをセットしたい。
(荷物のヘッダは荷物の箱単位。荷物の箱明細は箱の中に入っている商品単位)
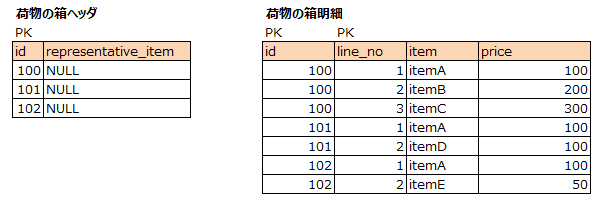
・・・
・・・
こうして→こうだ!(この結果を使ってUPDATEだ!)

クエリ
SELECT
ivw.id
, ivw.line_no
, ivw.item
, ivw.price
FROM
( SELECT
dtl.id
, dtl.line_no
, dtl.item
, dtl.price
, ROW_NUMBER() OVER(PARTITION BY id ORDER BY dtl.price DESC) AS row_no
FROM
baggage_detail dtl
) ivw
WHERE
ivw.row_no = 1
;
解説
ROW_NUMBER() OVER(PARTITION BY id ORDER BY dtl.price DESC) はid項目で区切って、その範囲でpriceの降順に並べ、番号を振っていくという分析関数です。これで振った番号を絞り込むことで、目的のものに絞り込めます。一番を決めて、その一番に絞り込むという手法。RANKやDENSE_RANKでも使えますが、こちらの2ファンクションの場合、ORDER BYの指定が甘いと同率1位が存在することになり1行に絞り込めない場合があります(今回のAとDの場合)。この場合UPDATEが失敗することがあります。(更新する値を一つに絞り込めない=RDBの思想に反するためエラーにするという挙動)
ROW_NUMBERだと必ず1から順に番号が振られます。
一意に絞り込むためには、お題にはないですがORDER BY にdtl.line_noを足すという隠れ仕様を追加するのも一つです。
こうすればRANKやDENSE_RANKでも同率1位がなくなります。
ですが、上記のような確認がいちいち必要になるのでROW_NUMBERの使用をお勧めします。
お題2
ROW_NUMBERは行番号付けれるということで以下のように並列処理の対象に分散させるような使い方もできます。
クエリ
SELECT
dtl.id
, dtl.line_no
, dtl.item
, dtl.price
, ROW_NUMBER() OVER() % 4 AS parallel
FROM
baggage_detail dtl
結果と解説
parallel に行番号を4で割った余りを出すようにしたので、この番号に基づいて4つにデータを投げ分けれます。
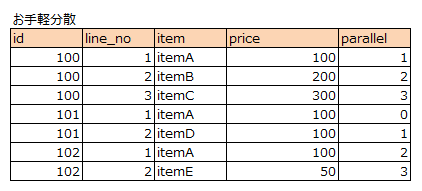
使用したデータ
/* PostgreSQL */
CREATE TABLE baggage (id numeric(5), representative_item varchar(5), CONSTRAINT pk_baggage PRIMARY KEY (id));
CREATE TABLE baggage_detail (id numeric(5), line_no numeric(4), item varchar(5), price numeric(6), CONSTRAINT pk_baggage_detail PRIMARY KEY (id, line_no));
INSERT INTO baggage
VALUES
(100,NULL)
,(101,NULL)
,(102,NULL)
;
INSERT INTO baggage_detail
VALUES
(100,1, 'itemA', 100)
,(100,2, 'itemB', 200)
,(100,3, 'itemC', 300)
,(101,1, 'itemA', 100)
,(101,2, 'itemD', 100)
,(102,1, 'itemA', 100)
,(102,2, 'itemE', 50)
;
LAG, LEAD~履歴データから変更前データ取得~
お題
価格変更履歴を変更前、変更後の形で知りたいなー。
・・・
・・・
・・・
こうだ!!
クエリ
SELECT
ph.item
, ph.history
, ph.price
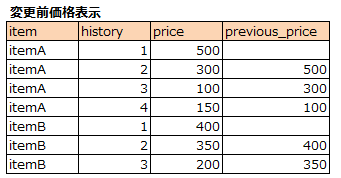
, LAG(ph.price) OVER( PARTITION BY item ORDER BY history ASC) AS previous_price
FROM
item_price_history ph
解説
LAGは一つ手前の行の値を取得できます。(LEADはその逆で一つ先の行の値)
LAG(ph.price) OVER( PARTITION BY item ORDER BY history ASC) を使えば、itemで区切って、historyで並べて、LAGで一つ手前に並んだ行の値を取ってこれます。
使用したデータ
/* PostgreSQL */
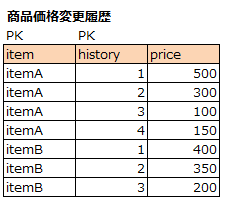
CREATE TABLE item_price_history (item varchar(5), history numeric(3), price numeric(6), CONSTRAINT pk_item_price_history PRIMARY KEY (item, history));
INSERT INTO item_price_history
VALUES
('itemA', 1, 500)
,('itemA', 2, 300)
,('itemA', 3, 100)
,('itemA', 4, 150)
,('itemB', 1, 400)
,('itemB', 2, 350)
,('itemB', 3, 200)
;
まとめ
以上です。
なかには、SQLでここまでやる?とか、そもそもテーブル設計が。。。なんて思う例もあるかもしれません。
でも現場のシステムってそういうのがあったりするのです。
テーブル設計を工夫してシンプルにデータ取得できるのが一番だと思います。
また、SQLからデータ取得後に受けてのプログラムでデータを加工するのも解の一つです。
SQLで対応する場合の案として考えて頂ければ嬉しいです。
参考
おまけ
会社でRedisの技術ブログ書いたら、かなり好評でした。
RDBと同じようにつかったらエライことになりそうな部分やその対策を記載してます。
もしよければこちらも見てもらえると嬉しいです。
技術ブログ:システム開発で得たRedis利用ノウハウ
-
RANGE BETWEEN ...を使用することで参照範囲を変更することも可能です。例:OVER(PARTITION BY ... ORDER BY ... RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)と記載すれば参照範囲はパーティション内の全範囲となります。こちらがわかりやすい ↩