再帰関数ってコーディングするとなんかかっこよくないですか?
実はSQLでも再帰があります。
今日は再帰クエリをご紹介します。
※少なくとも以下のRDBMSの最新バージョンは再帰クエリに対応しています。
PostgreSQL, Oracle, SQL Server, MySQL(8.0~), SQLite
※この記事で記載するSQLはすべてPostgreSQLで動くものです。
再帰クエリとは
百聞は一見に如かず。
まずはデータ準備
--ファイルか、フォルダの情報を格納するテーブル
CREATE TABLE object_tree (
id numeric(10)
, name varchar(25)
, is_directory boolean
, parent_id numeric(10)
, CONSTRAINT pk_object_tree PRIMARY KEY (id)
);
--データ投入
INSERT INTO object_tree (id, name, is_directory, parent_id)
VALUES
(1, 'root', true, null)
, (2, 'sub1', true, 1)
, (3, 'file1.txt', false, 1)
, (4, 'sub2', true, 1)
, (5, 'sub3', true, 1)
, (6, 'sub1a', true, 2)
, (7, 'sub1b', true, 2)
, (8, 'sub2a', true, 4)
, (9, 'sub3a', true, 5)
, (10, 'file2.txt', false, 8)
;
そして、再帰クエリでデータ取得
下のようにパスの構造がわからなかったデータ構造から、
「何階層目にあるか」と「絶対パス」が明らかになりました。

--PoestgreSQLの場合
WITH RECURSIVE rec AS (
-- 再帰のスタート地点
SELECT
ot.id AS id
, ot.name AS name
, ot.is_directory AS is_directory
, ot.parent_id AS parent_id
, 1 AS layer
, '/' || ot.name AS full_path
FROM
object_tree AS ot
WHERE
ot.parent_id IS NULL --一番上の階層を取得する条件
UNION ALL
-- 再帰でグルグル増えていく箇所
SELECT
ot.id AS id
, ot.name AS name
, ot.is_directory AS is_directory
, ot.parent_id AS parent_id
, rec.layer+1 AS layer
, rec.full_path || '/' || ot.name AS full_path
FROM
rec -- 自分自身のWITH句にobject_treeをくっつける
INNER JOIN
object_tree AS ot
ON
ot.parent_id = rec.id
)
SELECT
*
FROM
rec
できましたね。
RECURSIVEのキーワードがいらないなど、RDBMSにより書き方の差は若干ありますが、ほぼ上記のように書けばよいです。
このときにlayer(階層)や、絶対パス(full_path)などのデータを作るとその後の参照に役立ちます。
再帰クエリのイメージを図解してくれてる方 がいます。これでイメージできるかと。
めでたしめでたし。
…ではなく、ここから、この再帰クエリの使いどころをご説明します。
使いどころ
その前に(ナイーブツリーの話)
上記元データとして使用した object_tree のように、自分の親のレコードIDを持つタイプのデータ構造を「自己参照型テーブル構造」だとか「ナイーブツリー」と呼ばれます。この「ナイーブツリー」は [SQLアンチパターン] (https://www.amazon.co.jp/SQL%E3%82%A2%E3%83%B3%E3%83%81%E3%83%91%E3%82%BF%E3%83%BC%E3%83%B3-Bill-Karwin/dp/4873115892) の一つとして有名です。
ナイーブツリーは更新は楽というメリットよりも、デメリットが大きいということでアンチパターンとされています。
-
ナイーブツリーのメリット
- **【UPDATE, INSERTが楽】**フォルダの追加や、フォルダ配下のものの移動が楽。
-
ナイーブツリーのデメリット
- **【SELECTが大変】**どこまでも深くできるため、すべての子階層を取得するために、どれだけ結合したらいいかわからない。
- **【DELETEが大変】**ノードを削除(フォルダを削除)する場合、その子階層の特定に数回クエリを投げなきゃダメ。
この、ナイーブツリーというSQLアンチパターンの解決方法として、経路列挙モデル、入れ子集合モデル、閉包テーブルモデルなどあります。
※各モデルの説明は こちらの説明 が非常にわかりやすいです。
ただこの解決方法は、データ構造が直感的でなかったり、UPDATE, INSERTが複雑だったりで、単純にメリットだけあるわけではありません。
そこで再帰クエリ!
今回紹介している再帰クエリ、これはナイーブツリーから経路列挙モデルに変換する手法として使えます。
**「ナイーブツリーでデータ更新し、参照は再帰クエリの経路列挙モデルでやる」**というのが私のおすすめです。
ただし!
- 再帰クエリは、データ参照するためのハードルが上がります。
クエリを書くのめんどくさいです。 - 毎回参照のたびにDBに再帰処理させるのも気が引けます。
DBに申し訳ない気がします。
なので!
再帰クエリの結果はテーブル(もしくはマテリアライズドビュー)に格納して、簡単に参照することを推奨します。
つまり私は、**「ナイーブツリーと経路列挙モデルの2テーブルを持つ」**ことがいいと思います。
更新はナイーブツリーモデル、参照は経路列挙モデルが担当します。
ナイーブツリーのテーブル更新後、続けて経路列挙モデルのテーブルを全DELETE/INSERTします。
※経路列挙モデルのテーブルはVIEWで作り、DELETE/INSERT自体不要にするのもよいと思います。そこは各自柔軟に解釈ください。
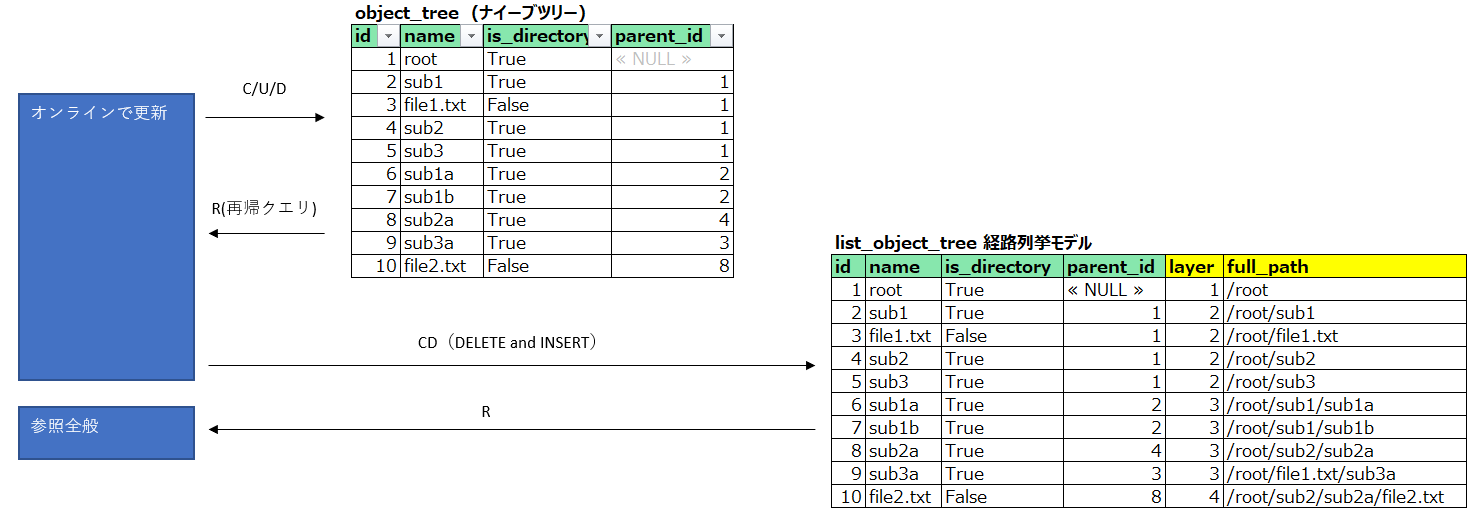
これで、「更新が楽なナイーブツリー」と「参照が楽な経路列挙」の各モデルの長所を生かせました。
ここからは、CRUDのケース別のクエリサンプルをご紹介します。
※list_object_treeのDDLとDELETE/INSERTのクエリは末尾に記載します。
-- ノード(フォルダorファイル)を追加(sub1の下に追加)
INSERT INTO object_tree (id, name, is_directory, parent_id) VALUES
(99, 'hoge.txt', false, 2)
;
-- sub2とその配下をsub3配下に移動
UPDATE object_tree
SET
parent_id = 5
WHERE
id = 4
;
-- sub2の名称をsub3xに変更
UPDATE object_tree
SET
name = 'sub3x'
WHERE
id = 4
;
--sub1とその配下をすべて削除
-- -- 1. まず配下を削除
DELETE
FROM object_tree
WHERE
id IN (
SELECT childs.id
FROM
list_object_tree target
INNER JOIN
list_object_tree childs
ON
childs.full_path LIKE target.full_path||'/%'
WHERE
target.id = 2 --sub1のID
)
;
-- -- 2. 次にsub1を削除
DELETE
FROM object_tree
WHERE id = 2
;
--sub3とその配下の取得(fullpath指定)
SELECT * FROM list_object_tree lot WHERE lot.full_path = '/root/sub3'
UNION ALL
SELECT * FROM list_object_tree lot WHERE lot.full_path LIKE '/root/sub3/%'
ORDER BY
full_path
;
--sub3とその配下の取得(id指定)
SELECT * FROM list_object_tree WHERE id = 5 --sub3のID
UNION ALL
SELECT childs.*
FROM
list_object_tree target
INNER JOIN
list_object_tree childs
ON
childs.full_path LIKE target.full_path||'/%'
WHERE
target.id = 5 --sub3のID
ORDER BY
full_path
;
-- 最下層のみ取得
SELECT
*
FROM
list_object_tree term
WHERE
NOT EXISTS (
-- 親IDとして登録されているレコードを除く
SELECT 'X' FROM list_object_tree parent
WHERE
term.id = parent.parent_id
)
ORDER BY
term.full_path
;
適用しやすいデータモデル
今回推奨のナイーブと経路列挙の二重持ちですが、「1テーブルのときよりデータ量が2倍」、「DB更新で毎回DELETE/INSERTをする」というのが気になるかと思います。
そうです。若干利用に制限があります。
この二重持ちデータモデルは「データ量が限られており」、「更新頻度が低いエンティティ」に有効です。
具体的には、以下のようなマスタデータのエンティティとよくマッチします。
- 組織(部署)マスタ
- 組織(上司、部下)マスタ
- ファイル、フォルダ階層マスタ
- 商品分類マスタ
上記のようなエンティティモデルを設計する際はぜひご検討ください。
まとめ
- 再帰クエリというものがある。再帰クエリ使用時に階層番号や絶対パスをSELECT項目で作ると便利。
- 再帰クエリは組織やフォルダ階層などの「自己参照型のテーブル」に利用できる。
- 再帰クエリは毎回書くのはややこしいからテーブルにデータを持っておくと便利(使いやすいデータ構造になる)。
- ナイーブツリーの構造は再帰クエリがあるからそこまでアンチパターンとは(私は)思わない。
APPENDIX
参考資料
- [書籍:SQLアンチパターン] (https://www.amazon.co.jp/SQL%E3%82%A2%E3%83%B3%E3%83%81%E3%83%91%E3%82%BF%E3%83%BC%E3%83%B3-Bill-Karwin/dp/4873115892)
- 再帰SQL -図解-
- ナイーブツリーの説明
list_object_tree のDDLとDELETE/INSERTのクエリ
CREATE TABLE list_object_tree (
id numeric(10)
, name varchar(25)
, is_directory boolean
, parent_id numeric(10)
, layer numeric(3)
, full_path text
, CONSTRAINT pk_list_object_tree PRIMARY KEY (id)
, CONSTRAINT uk_list_object_tree UNIQUE (full_path) --絶対パスが被ることがないよう設定。
);
--DELETE
DELETE FROM list_object_tree;
--再帰クエリでINSERT
WITH RECURSIVE rec AS (
-- 再帰のスタート地点
SELECT
ot.id AS id
, ot.name AS name
, ot.is_directory AS is_directory
, ot.parent_id AS parent_id
, 1 AS layer
, '/' || ot.name || AS full_path
FROM
object_tree AS ot
WHERE
ot.parent_id IS NULL --一番上の改装
UNION ALL
-- 再帰でグルグル増えていく箇所
SELECT
ot.id AS id
, ot.name AS name
, ot.is_directory AS is_directory
, ot.parent_id AS parent_id
, rec.layer+1 AS layer
, rec.full_path || '/' || ot.name AS full_path
FROM
rec -- 自分自身のWITH句にobject_treeをくっつける
INNER JOIN
object_tree AS ot
ON
ot.parent_id = rec.id
)
INSERT INTO list_object_tree
SELECT
*
FROM
rec
;