先月、Googleが開発した人工知能ライブラリTensorFlowをオープンソースした訳ですが、一つの特徴としてはGPUを使って処理もできる、とのことです。少しだけ調べたところGPUの利用はLinuxのみだが、GPUの計算を使ってみたいとのことでAWSでの利用を試してみました。
TensorFlowとは?
TensorFlowの主要な一つのユースケースはディープラーニング/ニューラルネットワークの実装ですが、その使い方もできれば、もっと一般的にデータフローグラフで表現可能な計算に何でも使えるものです。あらかじめデータフローグラフとして構成することにより、複数のデバイスによる並列計算、GPUを使った処理の高速化等が可能のようです。
TensorFlowをGPUで動かしたい理由
最近どこかで読んだがディープラーニング系の処理やBitcoinマイニングでも、GPUを使うと効率的なようです。GPUはALU(演算論理ユニット)をCPUより何倍も持っており、大量の演算を並列でできるようにデザインされているからです。
GPUを名前の通り「Graphics Processing Unit」にあるよう、グラフィックスを描画するため本来出来ているものだが、より一般的な用途にも使うケースが増えている... 「GPGPU」=「General-Purpose computing on Graphics Processing Units」。また、GPGPUをサポートするために、グラフィックのためのAPI (例:OpenGL等) とは別のプログラミングモデルやAPIが最近用意されています。TensorFlowはGPUメーカーNVidiaが作った「CUDA」(Common Unified Device Architecture)と「cuDNN」(CUDA Deep Neural Networkライブラリ)を使ってGPUの計算ができるようです。
GPUを使って早くなったら確かに役に立ちそうです。ローカルマシン(Late 2013のiMac)でTensorFlowをDockerイメージでインストールして、MNISTのサンプルを実行したところ、トレーニングに52分もかかりました。この処理が早くなると便利そうです。
AWSのGPUを試そう
GPU対応は便利そうですが、Linux(でかつ適切なグラフィックカードがあることも条件)のみなので、HWがない!この際、AWSが便利です。
- AWS: LinuxのGPUインスタンス
AWSのGPUインスタンスは使ったことがないが、使ってみるのに良い機会です。
TensorFlowをAWSのGPUインスタンスで動かす方法
こうした際、ステップ1はやはり「tensorflow aws gpu」をGoogleで検索しますね。
したら、一つ目出てきたこのQuoraのスレッドとからこのGithubのスレッド、現段階ではかなり面倒な印象を受けました。TensorFlowはCUDA Compute 3.5または5.2のサポートを必要としているが、AWSのGPUインスタンスがCUDA Compute 3.0といったことでパッチが必要、CUDAとcuDNNのライブラリバージョンの調整等も難しいようです。(まだ、少し早いですね...)
なお、もう少し探したら、以下のErik Bernhardssonの投稿をみて、喜びました:
- Erik Bernhardsson Installing TensorFlow on AWS
どうやらNVidiaドライバー、細かい設定とソフトウェアのインストールがかなりの手間... 5時間もかかったそうですが、AMIを用意してくれています:
AMIの作成手順もありました:
ということで早速インスタンスを立ち上げました。アドバイスの通り g2.2xlarge インスタンスを選択:
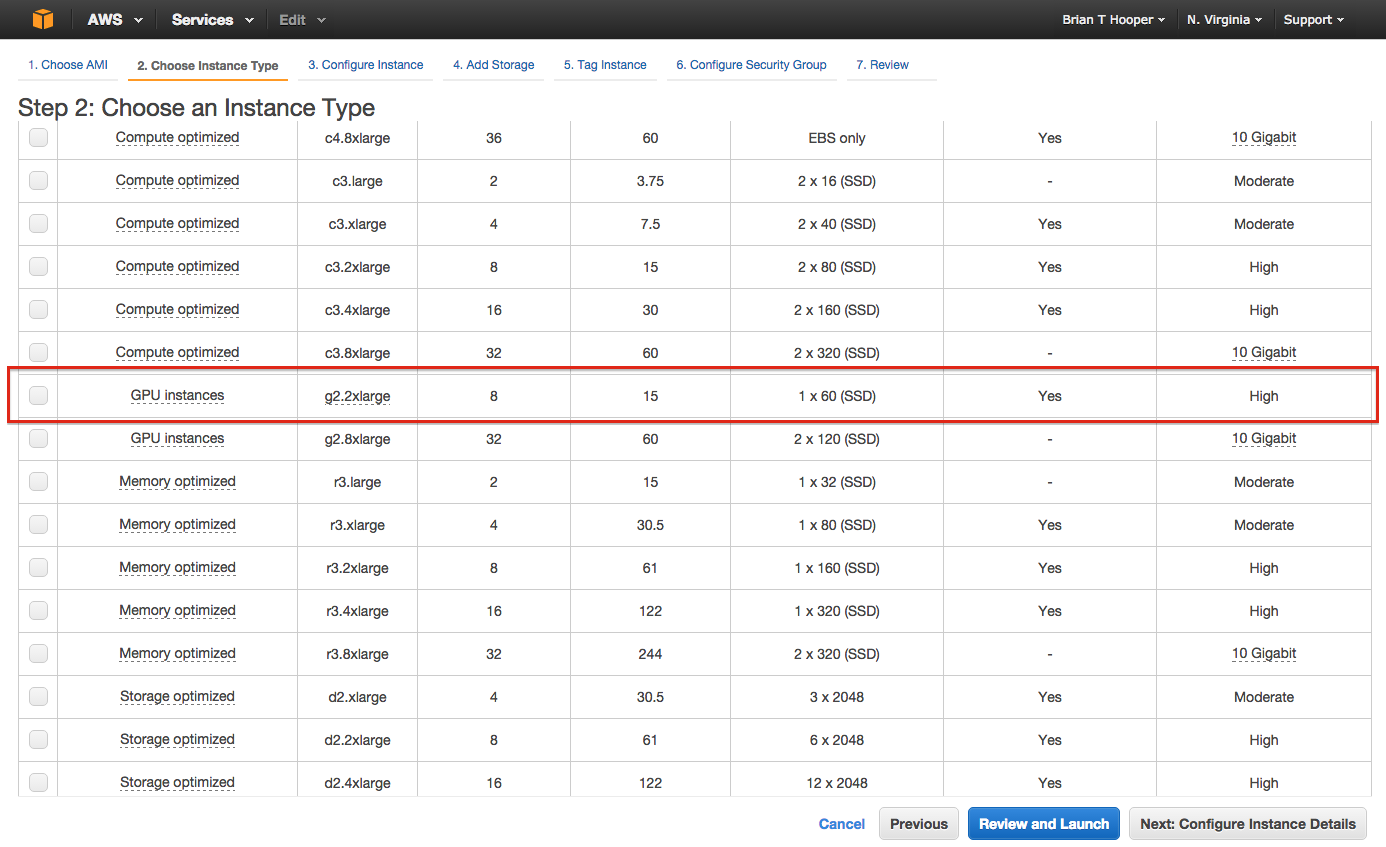
後いうことがあるとすれば、スポットインスタンスにすると安い、とのことですが確かに10分の1ぐらいでしたので、同様に試すならおすすめします。
インスタンスが立ち上がったら、sshで入り、TensorFlowの「Download and Setup」に進み、以下のテストコードを実行してみました:
$ python
Python 2.7.6 (default, Jun 22 2015, 17:58:13)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, TensorFlow!')
>>> sess = tf.Session()
>>> print sess.run(hello)
Hello, TensorFlow!
>>> a = tf.constant(10)
>>> b = tf.constant(32)
>>> print sess.run(a + b)
42
>>>
So far so good. 次に「Run a TensorFlow demo model」ということで:
$ python /usr/local/lib/python2.7/dist-packages/tensorflow/models/image/mnist/convolutional.py
Succesfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Succesfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Succesfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Succesfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
I tensorflow/core/common_runtime/local_device.cc:25] Local device intra op parallelism threads: 8
I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:888] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
I tensorflow/core/common_runtime/gpu/gpu_init.cc:88] Found device 0 with properties:
name: GRID K520
major: 3 minor: 0 memoryClockRate (GHz) 0.797
pciBusID 0000:00:03.0
Total memory: 4.00GiB
Free memory: 3.95GiB
I tensorflow/core/common_runtime/gpu/gpu_init.cc:112] DMA: 0
I tensorflow/core/common_runtime/gpu/gpu_init.cc:122] 0: Y
I tensorflow/core/common_runtime/gpu/gpu_device.cc:644] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GRID K520, pci bus id: 0000:00:03.0)
I tensorflow/core/common_runtime/gpu/gpu_region_allocator.cc:47] Setting region size to 3927400448
I tensorflow/core/common_runtime/direct_session.cc:45] Direct session inter op parallelism threads: 8
Initialized!
Epoch 0.00
Minibatch loss: 12.054, learning rate: 0.010000
Minibatch error: 90.6%
Validation error: 84.6%
Epoch 0.12
Minibatch loss: 3.288, learning rate: 0.010000
Minibatch error: 6.2%
Validation error: 7.1%
Epoch 0.23
...
[and so on...]
GPU関連のログ出力から認識がうまく行き、トレーニングバッチのスピードも早いので良い感じで進んでいたが、最後に
[output omitted]
...
W tensorflow/core/common_runtime/gpu/gpu_region_allocator.cc:89] Out of GPU memory, see memory state dump above
W tensorflow/core/kernels/conv_ops.cc:262] Resource exhausted: OOM when allocating tensor with shapedim { size: 10000 } dim { size: 32 } dim { size: 32 } dim { size: 1 }
W tensorflow/core/common_runtime/executor.cc:1027] 0x67d4d60 Compute status: Resource exhausted: OOM when allocating tensor with shapedim { size: 10000 } dim { size: 32 } dim { size: 32 } dim { size: 1 }
[[Node: Conv2D_4 = Conv2D[T=DT_FLOAT, padding="SAME", strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/gpu:0"](Const_1, Variable)]]
W tensorflow/core/common_runtime/executor.cc:1027] 0x67d4990 Compute status: Resource exhausted: OOM when allocating tensor with shapedim { size: 10000 } dim { size: 32 } dim { size: 32 } dim { size: 1 }
[[Node: Conv2D_4 = Conv2D[T=DT_FLOAT, padding="SAME", strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/gpu:0"](Const_1, Variable)]]
[[Node: Softmax_2/_47 = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/cpu:0", send_device="/job:localhost/replica:0/task:0/gpu:0", send_device_incarnation=1, tensor_name="edge_735_Softmax_2", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/cpu:0"]()]]
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tensorflow/models/image/mnist/convolutional.py", line 275, in <module>
tf.app.run()
...
[etc.]
とGPUがOut of memoryになり、異常終了しました。
調べたら、これは最後のテストの時で生じた問題だったが(このスレッドにより)、最新版ではメモリアロケータの改善("BFC"アロケータをデフォルトに)により解消されたので、結論としてはTensorFlowの最新版に更新すれば良い、という対応が可能です。
やや面倒くさいことに、AMIイメージにはtensorflowとbazel (TensorFlowをビルドするために使う、Googleがオープンソースしたビルドツール)のソースが残っていなかったので、tensorflowを更新するために、ErikさんのAMI構築スクリプトの後半部分を再実行、つまり:
# Install Bazel
mkdir /tmp/work
cd /tmp/work
git clone https://github.com/bazelbuild/bazel.git
cd bazel
git checkout tags/0.1.0
./compile.sh
sudo cp output/bazel /usr/bin
# Install TensorFlow
cd /tmp/work
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64"
export CUDA_HOME=/usr/local/cuda
git clone --recurse-submodules https://github.com/tensorflow/tensorflow
cd tensorflow
# CUDA Compute 3.0 is why TF_UNOFFICIAL_SETTING is needed.
TF_UNOFFICIAL_SETTING=1 ./configure
bazel build -c opt --config=cuda //tensorflow/cc:tutorials_example_trainer
# Build Python package
# Note: you have to specify --config=cuda here - this is not mentioned in the official docs
# https://github.com/tensorflow/tensorflow/issues/25#issuecomment-156173717
bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
sudo pip install /tmp/tensorflow_pkg/tensorflow-0.5.0-cp27-none-linux_x86_64.whl
コンパイル時に警告が結構たくさん出力されますが、全部終わったら、BFCアロケータがデフォルトになっており、セットアップ手順のconvolutional.pyが最後のテストまでも終わります:
$ time python convolutional.py
Extracting data/train-images-idx3-ubyte.gz
Extracting data/train-labels-idx1-ubyte.gz
Extracting data/t10k-images-idx3-ubyte.gz
Extracting data/t10k-labels-idx1-ubyte.gz
I tensorflow/core/common_runtime/local_device.cc:40] Local device intra op parallelism threads: 8
I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:903] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
I tensorflow/core/common_runtime/gpu/gpu_init.cc:103] Found device 0 with properties:
name: GRID K520
major: 3 minor: 0 memoryClockRate (GHz) 0.797
pciBusID 0000:00:03.0
Total memory: 4.00GiB
Free memory: 3.95GiB
I tensorflow/core/common_runtime/gpu/gpu_init.cc:127] DMA: 0
I tensorflow/core/common_runtime/gpu/gpu_init.cc:137] 0: Y
I tensorflow/core/common_runtime/gpu/gpu_device.cc:703] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GRID K520, pci bus id: 0000:00:03.0)
I tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:42] Allocating 3.66GiB bytes.
[more memory allocation logs]
I tensorflow/core/common_runtime/direct_session.cc:60] Direct session inter op parallelism threads: 8
Initialized!
Epoch 0.00
Minibatch loss: 12.054, learning rate: 0.010000
Minibatch error: 90.6%
Validation error: 84.6%
[output omitted]
Minibatch loss: 1.600, learning rate: 0.006302
Minibatch error: 0.0%
Validation error: 0.8%
Test error: 0.8%
It works! では、次にどうしましょう?(今日は、out of time...)
まとめ
TensorFlowはまだオープンソースしてから時間がまだ立っていないため、まだ使えるためには(私は)ちょっとハードルありましたが、早いペースで改善されていることもわかります。AWSのGPUで動かしたい方がいれば、いまのところベストな方法は:
- ErikさんのAMIをベースにし
- 必要に応じて(Bazelも入れて)TensorFlowの最新ソースを利用する
がよさそうです。
今回TensorFlowを使って何かを構築するまでの時間はなく、さわりだけで終わってしまったが、GPUのクラウド利用、CUDA、TensorFlow以外のディープラーニングフレームワークを調べるきっかけとなったのはよかったです。特に、今後もっと調べたいと思った技術/トピックとしては:
- Theano - TensorFlowより前からあるディープラーニングライブラリ、おそらく考え方が似ていると思われる
- Keras - TensorFlowまたはTheanoの上にのせられる、よりハイレベルなディープラーニングフレームワーク
- Torch - このフレームワークもよく話に出てくる
学びたいこといっぱいありますね。
アップデート
他にTensorFlowの最新版を簡単に使いたい方もいるかも知れないので(分散処理が可能になったらだいぶ魅力はあがると思う)、今回の投稿のAMIを公開しました。ubuntuとしてログインしたら、bazel, tensorflow もホームディレクトリにおいてあります。