aptpod Advent Calendar 2018 の15日目です
概要
AWS re:Invent 2018で発表されたAmazon Elastic InferenceをAmazon EC2インスタンスドキュメンテーション用Amazon Elastic Inferenceの資料通りに動かしてみた結果です
背景
業務で機械学習にGPUを使用する際は(7日目の記事でご紹介した)JupyterHub (on Docker) を中心に利用し、学習したモデルを利用する際は(GPUが必要なものもCPUだけで足りるものもだいたい同じ手順でデプロイできるように)推論を行うPythonコードを(Nvidia) Docker上で動作させるような構成で管理していました
ただ
- CPU: 推論速度がデータの流量を捌ききれずパンクしてしまうことがある
- GPU: 調整なしだと1つのPythonプログラムがGPUまるまる1枚を確保してしまうなど、リソースの無駄が起こりうる
と、調整/管理が地味に面倒だなーと思っていたところで「任意のEC2インスタンスに推論用のGPU?銀の弾丸では??」なサービスが発表されたので試してみました
手順
Working with Amazon EI - Amazon Elastic Compute Cloud内の手順を上から順にポチポチしました
(以下は雑な日本語訳がほとんどと若干の補足くらいですので、ぜひ本家のドキュメントもご参照ください![]() )
)
Amazon EI用のセキュリティグループの作成
https://console.aws.amazon.com/vpc/ 内の「セキュリティグループ」のパネルから、Inbound Rules / Outbound Rules共に、
- ポート: 443
- プロトコル: HTTPS
- ソース/宛先: 任意の場所
の値を設定した、使用するVPCと紐づくセキュリティグループを作成します
(必要に応じてソース/宛先は絞ってください)
Amazon EI用のVPCエンドポイントの作成
https://console.aws.amazon.com/vpc/ 内の「エンドポイント」のパネルから、
-
「エンドポイントの作成」ボタンを選択
-
「サービスカテゴリ」内の「サービスを名前で検索」を選択
-
「サービス名」に
com.amazonaws.ap-northeast-1.elastic-inference.runtimeを入力して「検証」を選択 -
-
「VPC」と「サブネット」にそれぞれ使用するものを選択
-
「プライベート DNS 名を有効にする」をチェック
-
「セキュリティグループ」に先ほど作成した Amazon EI用のセキュリティグループを選択
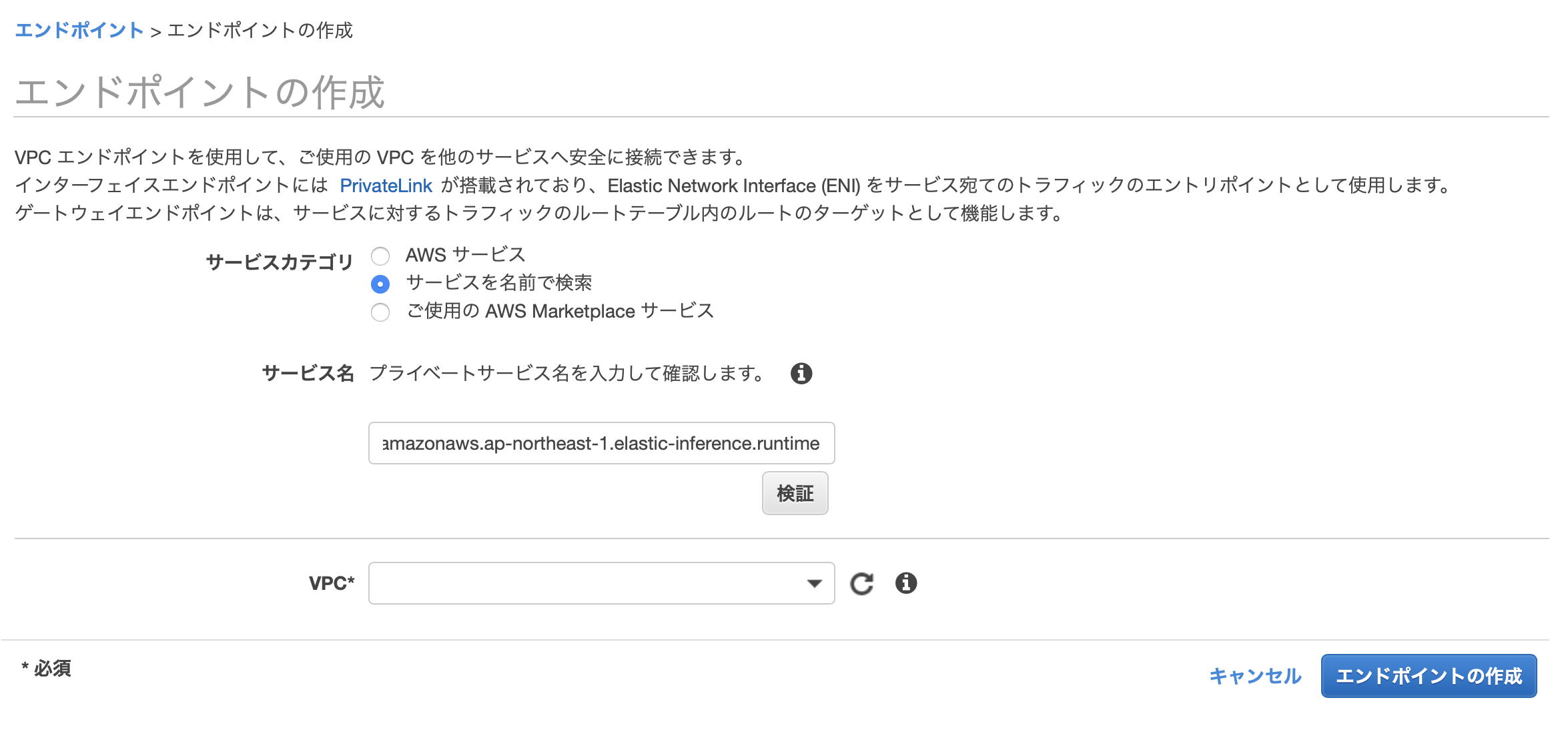
の手順でVPCエンドポイントを作成します
Amazon EIを使用するためのIAM Roleの作成
IAM Policyの作成
https://console.aws.amazon.com/iam/ 内の「ポリシー」のパネルから「ポリシーの作成」を選択し、以下の内容を ec2-role-trust-policy.json などの名前で保存します
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "elastic-inference:Connect",
"Resource": "*"
}
]
}
IAM Roleの作成
https://console.aws.amazon.com/iam/ 内の「ロール」のパネルから「ロールの作成」を選択し、
- 以下の内容を選択
- 信頼されたエンティティの種類を選択:AWS サービス
- このロールを使用するサービスを選択:EC2
- 先ほど作成した(
ec2-role-trust-policy.jsonなどの名前の)ポリシーを選択 - (タグはよしなに記入)
- ロール名を記入し保存
の手順でロールを作成します
EC2 with Amazon EIのインスタンスの作成
https://console.aws.amazon.com/ec2/ 内から「インスタンスの作成」を選択し、
- 「Deep Learning AMI (Amazon Linux) Version 20.0」を選択
- インスタンスタイプを適宜選択(お試しには
c5とかでよいのではないかと思います) - 「インスタンスの詳細の設定」から以下を中心に適宜選択
- IAMロール:先ほど作成したもの
- Elastic Inference:Add an Elastic Inference acceleratorにチェック
- Type:適宜選択(とりあえず
eia1.mediumでよいのではないかと思います)
- Type:適宜選択(とりあえず
- 残りは通常のEC2インスタンスを立てるときと同様に設定
の手順でインスタンスを生成します
Amazon EI TensorFlow Servingの利用
インスタンスに接続し、ドキュメントに記載の手順通りにTensorFlow Serving用の準備をします
[ec2-user@ip-xxx ~]$ curl -O https://s3-us-west-2.amazonaws.com/aws-tf-serving-ei-example/inception.zip
[ec2-user@ip-xxx ~]$ unzip inception.zip
[ec2-user@ip-xxx ~]$ curl -O https://upload.wikimedia.org/wikipedia/commons/b/b5/Siberian_Husky_bi-eyed_Flickr.jpg
[ec2-user@ip-xxx ~]$ AmazonEI_TensorFlow_Serving_v1.11_v1 --model_name=inception --model_base_path=/home/ec2-user/SERVING_INCEPTION/SERVING_INCEPTION --port=9000
(略)
Using Amazon Elastic Inference Client Library Version: 1.2.8
Number of Elastic Inference Accelerators Available: 1
Elastic Inference Accelerator ID: eia-b8bf2717bfb54be1b41f66de711c67fa
Elastic Inference Accelerator Type: eia1.medium
(略)
2018-12-14 15:16:08.629584: I tensorflow_serving/model_servers/server.cc:283] Running gRPC ModelServer at 0.0.0.0:9000 ...
こんな感じにフォアグラウンドでTensorFlow Servingが動き始めますので、もう一つ別の窓を準備し、TensorFlow Servingに推論させるようなコードを実行します
[ec2-user@ip-xxx ~]$ cat inception_client.py
from __future__ import print_function
import grpc
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
tf.app.flags.DEFINE_string('server', 'localhost:9000',
'PredictionService host:port')
tf.app.flags.DEFINE_string('image', '', 'path to image in JPEG format')
FLAGS = tf.app.flags.FLAGS
def main(_):
channel = grpc.insecure_channel(FLAGS.server)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
# Send request
with open(FLAGS.image, 'rb') as f:
# See prediction_service.proto for gRPC request/response details.
data = f.read()
request = predict_pb2.PredictRequest()
request.model_spec.name = 'inception'
request.model_spec.signature_name = 'predict_images'
request.inputs['images'].CopyFrom(
tf.contrib.util.make_tensor_proto(data, shape=[1]))
result = stub.Predict(request, 10.0) # 10 secs timeout
print(result)
print("Inception Client Passed")
if __name__ == '__main__':
tf.app.run()
[ec2-user@ip-xxx ~]$ python inception_client.py --server=localhost:9000 --image Siberian_Husky_bi-eyed_Flickr.jpg
Traceback (most recent call last):
File "inception_client.py", line 3, in <module>
import grpc
ModuleNotFoundError: No module named 'grpc'
grpcモジュールがないよエラーが出てしまいましたが、そういえばインスタンスへのアクセス時に以下のような内容が出力されてました
=============================================================================
__| __|_ )
_| ( / Deep Learning AMI (Amazon Linux) Version 20.0
___|\___|___|
=============================================================================
Please use one of the following commands to start the required environment with the framework of your choice:
for MXNet(+Keras2) with Python3 (CUDA 9.0 and Intel MKL-DNN) _____________________________________ source activate mxnet_p36
for MXNet(+Keras2) with Python2 (CUDA 9.0 and Intel MKL-DNN) _____________________________________ source activate mxnet_p27
for MXNet(+Amazon Elastic Inference) with Python3 _______________________________________ source activate amazonei_mxnet_p36
for MXNet(+Amazon Elastic Inference) with Python2 _______________________________________ source activate amazonei_mxnet_p27
for TensorFlow(+Keras2) with Python3 (CUDA 9.0 and Intel MKL-DNN) ___________________________ source activate tensorflow_p36
for TensorFlow(+Keras2) with Python2 (CUDA 9.0 and Intel MKL-DNN) ___________________________ source activate tensorflow_p27
for Tensorflow(+Amazon Elastic Inference) with Python2 _____________________________ source activate amazonei_tensorflow_p27
for Theano(+Keras2) with Python3 (CUDA 9.0) _____________________________________________________ source activate theano_p36
for Theano(+Keras2) with Python2 (CUDA 9.0) _____________________________________________________ source activate theano_p27
for PyTorch with Python3 (CUDA 10.0 and Intel MKL) _____________________________________________ source activate pytorch_p36
for PyTorch with Python2 (CUDA 10.0 and Intel MKL) _____________________________________________ source activate pytorch_p27
for CNTK(+Keras2) with Python3 (CUDA 9.0 and Intel MKL-DNN) _______________________________________ source activate cntk_p36
for CNTK(+Keras2) with Python2 (CUDA 9.0 and Intel MKL-DNN) _______________________________________ source activate cntk_p27
for Caffe2 with Python2 (CUDA 9.0) ______________________________________________________________ source activate caffe2_p27
for Caffe with Python2 (CUDA 8.0) ________________________________________________________________ source activate caffe_p27
for Caffe with Python3 (CUDA 8.0) ________________________________________________________________ source activate caffe_p35
for Chainer with Python2 (CUDA 9.0 and Intel iDeep) ____________________________________________ source activate chainer_p27
for Chainer with Python3 (CUDA 9.0 and Intel iDeep) ____________________________________________ source activate chainer_p36
for base Python2 (CUDA 9.0) ________________________________________________________________________ source activate python2
for base Python3 (CUDA 9.0) ________________________________________________________________________ source activate python3
Official Conda User Guide: https://conda.io/docs/user-guide/index.html
AWS Deep Learning AMI Homepage: https://aws.amazon.com/machine-learning/amis/
Developer Guide and Release Notes: https://docs.aws.amazon.com/dlami/latest/devguide/what-is-dlami.html
Support: https://forums.aws.amazon.com/forum.jspa?forumID=263
For a fully managed experience, check out Amazon SageMaker at https://aws.amazon.com/sagemaker
=============================================================================
ということで言われた通りの環境をアクティベートして再度試します
[ec2-user@ip-xxx ~]$ source activate amazonei_tensorflow_p27
(amazonei_tensorflow_p27) [ec2-user@ip-xxx ~]$ python --version
Python 2.7.15 :: Anaconda custom (64-bit)
(amazonei_tensorflow_p27) [ec2-user@ip-xxx ~]$ python inception_client.py --server=localhost:9000 --image Siberian_Husky_bi-eyed_Flickr.jpg
outputs {
key: "classes"
value {
dtype: DT_STRING
tensor_shape {
dim {
size: 1
}
dim {
size: 5
}
}
string_val: "Eskimo dog, husky"
string_val: "Siberian husky"
string_val: "malamute, malemute, Alaskan malamute"
string_val: "white wolf, Arctic wolf, Canis lupus tundrarum"
string_val: "timber wolf, grey wolf, gray wolf, Canis lupus"
}
}
outputs {
key: "scores"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
dim {
size: 5
}
}
float_val: 8.89673233032
float_val: 8.72353553772
float_val: 4.88978672028
float_val: 3.06171226501
float_val: 2.88761281967
}
}
model_spec {
name: "inception"
version {
value: 1
}
signature_name: "predict_images"
}
Inception Client Passed
無事動きました![]()
結果
- 無事Amazon Elastic Inferenceを用いてTensorFlow Servingを動かすことができました
- SageMakerからElastic Inferenceを使用する例は公式のNotebookが明瞭かと思います
- エンドポイントのコンフィグに1項目(
'AcceleratorType': 'ml.eia1.large',)足すだけですね
- エンドポイントのコンフィグに1項目(
- SageMakerからElastic Inferenceを使用する例は公式のNotebookが明瞭かと思います
- 「Dockerを使っている今の構造のまま幸せになれる」わけではなかったです
- GPUの素性も
nvidiaではなくAmazon.com, Inc.としっかり書いてありましたlspci | grep VGA → 00:03.0 VGA compatible controller: Amazon.com, Inc. Device 1111
- TensorFlow Serving(やAmazon SageMakerなど)を推論に使う構成も検討・試行していたので、もちろんこちらを採用するケースでは大変幸せになれそうです
- GPUの素性も
- 過去にMXNet(やONNX)を使ったことがなかったので、そちらのサンプルは試せてません
- (コードを流し読みする限り)コードの中でより明示的にEIを利用できる感があったので、どなたか詳しい方が記事書かれないかなと期待しています