0.目標
本記事では、スクレイピングで取得した不動産データをもとに、
QGIS と Python を使って「街区の雨水リスク」を解析する手法を紹介します。
地球温暖化による豪雨の増加を踏まえ、不動産評価に新しい視点を加える試みです。
不動産サイトを見るとき、つい「駅から何分」「家賃いくら」だけで判断しがちですが、実際の住みやすさってもっといろんな要素が絡んでいますよね。 たとえば地形とか、下水の状況とか、雨が降ったときの安全性とか…。 そういう“地味だけど大事な情報”をまとめて見られたら便利だなと思い、このプロジェクトを作りました。
徒歩分数から円バッファを作ったり、市町村丁目ポリゴンと交差する弧を取り出したり、DEMから断面地形を引っ張ってきたり、下水道台帳から管径を調べたり…。 いろんなデータを組み合わせて、 「この物件の家賃って、防災面もちゃんと考えてるのかな?」 ということを視覚化しました。
スクレイピング、空間解析、ラスタ解析、QGISのポップアップカスタムなど、幅広い内容ですが、できるだけ再現しやすい形でまとめています。
0-1. 環境
- windows10
- python 3.10
- QGIS 3.40
0-1.スクレイピングコード
私が学習していたサイト
Udemyの清水義孝先生
👌 超おススメです!
今回のスクレイピングコードです
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup
import pandas as pd
import time
import re
import math
# ChromeDriverのパス
# ←ご自身のパスに変更
CHROMEDRIVER_PATH = r"C:\Users\xxxx\Desktop\chromedriver-win64\chromedriver.exe"
# Seleniumのセットアップ
service = Service(CHROMEDRIVER_PATH)
options = webdriver.ChromeOptions()
options.add_argument("--headless") # 画面表示なしで実行
driver = webdriver.Chrome(service=service, options=options)
# SUUMOのURL(例:荻窪周辺)
url = "https://suumo.jp/kanto/"
driver.get(url)
time.sleep(3) # ページ読み込み待ち
# HTML取得 → BeautifulSoupで解析
soup = BeautifulSoup(driver.page_source, "html.parser")
driver.quit()
# 物件情報抽出
properties = soup.select("div.cassetteitem")
data = []
for prop in properties:
name = prop.select_one("div.cassetteitem_content-title")
rent = prop.select_one("span.cassetteitem_other-emphasis.ui-text--bold")
area = prop.select_one("span.cassetteitem_menseki")
walk_info = prop.find("div", class_="cassetteitem_detail-text")
address = prop.select_one("div.cassetteitem_content-body ul li.cassetteitem_detail-col1")
# 住所抽出
if address:
raw_address = address.text.strip()
print("住所:", raw_address)
match = re.search(r"東京都([^\d]+?[区市][^\d]+?\d{1,2})", raw_address)
city_block = match.group(1) if match else ""
else:
city_block = ""
# 単価計算(住所の有無に関係なく処理)
unit_price = None
try:
rent_val = float(re.sub(r"[^\d.]", "", rent.text)) * 10000 if rent else None
area_clean = area.text.replace("m", "m").replace("2", "2") if area else ""
area_match = re.search(r"([\d.]+)m2", area_clean) # ← バックスラッシュ不要
area_val = float(area_match.group(1)) if area_match else None
print("賃料:", rent_val, "面積:", area_val)
unit_price = math.floor(rent_val / area_val / 10) * 10 if rent_val and area_val else None
print("単価:", unit_price)
except Exception as e:
print("単価計算エラー:", e)
unit_price = None
# データ追加(必ず実行されるように)
data.append({
"S_NAME": city_block,
"name": name.text.strip() if name else "",
"rent": rent.text.strip() if rent else "",
"area": area.text.strip() if area else "",
"walk_info": walk_info.text.strip() if walk_info and "JR" in walk_info.text else "",
"単価": unit_price
})
# CSV保存
df = pd.DataFrame(data)
df.to_csv("suumo_data_analysis.csv", index=False, encoding="utf-8-sig")
※ urlはsuumoの公式ページです。コードをご利用の場合は自身
の希望をクリックしてそのurlを貼り付けて下さい。
1. コードの解説
1-1.コード全般
今回のスクレイピング処理は、特別難しいものではなく、比較的典型的な構成です。 ライブラリは BeautifulSoup(bs4) と Selenium を使用しています。
Selenium を使う理由は、私の環境では scrapy crawl よりもロボット対策を回避しやすかった という個人的な経験によるものです。
print() 関数はデバッグ用で、値の確認に使っています。
この記事では「物件一覧をすべて取得する」ことが目的ではなく、 1つの物件を多方面から可視化するための解析的プログラムを組む という学習的な側面を重視しています。
1-2. 物件の抽出
properties = soup.select("div.cassetteitem")
select() は CSS セレクタに一致する要素を リストで返す BeautifulSoup のメソッドです。
各物件は div.cassetteitem にまとまっているため、 properties の各要素(prop)は 1 物件分の情報を持っています。
prop.select_one("div.cassetteitem_content-title")
select_one() は一致した要素のうち 最初の1つだけ を返します。 見つからない場合は None が返るため、例外処理が不要で扱いやすいです。
1つの prop から取得できる主な情報は以下の通りです:
-
name(物件名)
-
rent(賃料)
-
area(専有面積)
-
walk_info(最寄り駅・徒歩分数)
1-3. 正規表現について(住所の抽出)
match = re.search(r"東京都([^\d]+?[区市][^\d]+?\d{1,2})", raw_address)
city_block = match.group(1) if match else ""
この正規表現は、
「東京都+区名+町名+○丁目」
までを抽出するためのものです。
ポイント:
([^\d]+?[区市]...) の括弧部分が 抽出対象(グループ1)
[^\d]+? は「数字以外の文字が1文字以上」
[区市] は「区 または 市」
\d{1,2} は「1〜2桁の数字(○丁目)」
1-4. 平米単価の計算
unit_price = math.floor(rent_val / area_val / 10) * 10 if rent_val and area_val else None
ここでは 三項演算子 を使って、
賃料と面積が取得できた場合のみ単価を計算しています。
-
賃料(万円)を円に変換
-
面積(m²)で割る
-
/10 して 10円未満を切り捨て
-
×10 して 10円単位の単価にする
例:
賃料:65,550円
面積:10m²
計算の流れ:
65550 / 10 = 6555
6555 / 10 = 655.5
math.floor → 655
655 × 10 = 6550円/m²
2 QGISの物件配置操作
😉初心者の方に
🍰今回の資料データ
2-1.レイヤパネルに必要なレイヤを配置する
1 . XYZタイル(Google Map)を追加
- 「XYZタイル」から Google Map を登録して背景地図として使用
2 .「XYZタイル」から Google Map を登録して背景地図として
使用 - 国土数値情報から行政区域データを取得し、レイヤとして読み込み
3 . e-Stat(小地域)から東京都データを取得 - 小地域データをダウンロードし、東京都の範囲をレイヤとして追加
4 . 中野区・杉並区・武蔵野市の町村丁目ポリゴンを追加
- e-Stat の「境界データ」「小地域」「国勢調査(町村丁目)」から取得
- ダウンロードした shp ファイルをレイヤパネルへ追加
- レイヤのソース変更は右クリックから可能
- 地物選択は「シングルクリックで地物選択」アイコンを使用
- shp ファイルは専用フォルダを作って整理しておくと管理しやすい
2-1. 駅ポイントの作成(吉祥寺〜中野)
Google Map を参考に、以下の駅をポイントで配置する:
吉祥寺
西荻窪
荻窪
阿佐ヶ谷
高円寺
中野
2-2. 駅ポイント用のシェープファイルを作成する
1 . 新規シェープファイルレイヤの作成
-
ツールバー →「新規シェープファイルレイヤ」
-
ファイル名:station_points.shp
-
ジオメトリ型:ポイント
-
CRS:EPSG:6668
-
2 . 属性テーブルの設定
-
「編集モード切替」
-
「新規フィールド」→ フィールド追加
-
フィールド名:駅名など
-
型:テキスト(string)
-
長さ:20〜30 文字程度
-
4 . 以下7~10までの作業イメージ図

5 . GeoPackage などへ保存
- イメージ図➀
- station_points属性テーブルから高円寺を選択、ブルーになる
- station_pointsレイヤをアクティブにしたまま
- プロセッシング->ツール->バッファ-
- 形式:GeoPackage または Shapefile
- CRS:EPSG:6677 を選択
6 . 西荻北5_720_circle ポリゴンを「円周ライン」に変換する
-
イメージ図 ➁
-
メニュー → ベクター → ジオメトリツール → 「ポリゴンを線に変換」
-
「入力レイヤ」に 西荻北5_720_circleを指定
-
「線レイヤ」を西荻北5_720_circle_lineとする
-
ポリゴンの外周がラインレイヤとして出力される
7 . 西荻北5_clp_6677(小区域)をクリップ用に抽出する
- イメージ図➂の黄色の図形
- 小区域(杉並区)のレイヤを選択
- 「シングルクリックで地物選択」アイコンで 西荻北5_clp_6677 を選択(黄色表示)
- ツールバーからベクタ → ジオプロセッシングツール → 切り抜く(clip)
- 入力レイヤとオーバーレイヤが西荻北5_clp_6677になっていることを確認し、「選択した地物のみ」にチェックを入れる
- レイヤを右クリック → エクスポート → 選択地物を保存
- これが 西荻北5_clip_6677 となる
8 . 円周ラインを町丁目ポリゴンでクリップする
- イメージ図➂黄色の下側にある薄い青線の弧
- 入力レイヤ:西荻北5_720_circle_line
- クリップレイヤ:西荻北5_clp_6677
- 結果:西荻北5_arc_clip(町丁目内に収まる弧だけが残る)
9 . QChainage で弧上に等間隔の点を配置する
- イメージ図➃を参照
- プラグイン → QChainage をインストール
- 距離:3m
- 入力:西荻北5_arc_clip
- 出力:chain_西荻北5_arc_clip(弧の上に 3m 間隔でポイントが生成される)
10 . 生成されたチェイン点の「中央の点」を物件位置とする
- イメージ図➃を参照
- chain_西荻北5_arc_clip の属性テーブルを開き
- 点の並び順の中央にあるポイントを 物件の立地点 として採用する
(suumoでは〇区△丁目までしか確認できない為)
レイヤパネルに必要なレイヤを配置した結果
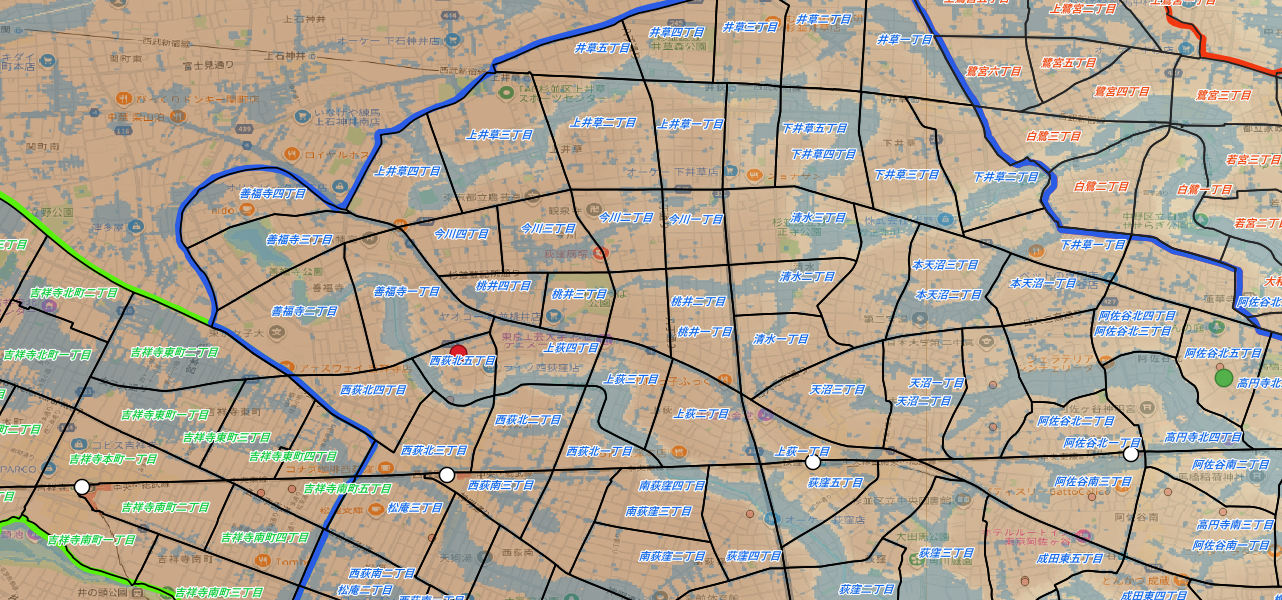
※赤いマークが今回ターゲットにしている物件です。
クリックして大きくして。
3. QGIS国土地理院から物件断面図とポップアップ操作
3-1. QGISのDEM解析と下水道台帳の確認
🍖初心者のための参考サイト
https://www.youtube.com/watch?v=r5rfcZOikUU
☕資料データ(国土地理院)
3-1-0. 国土地理院から数値標高モデル(DEM)を取得する
- 基盤地図情報サイトへ移動
- 標高データ(5m メッシュ)をダウンロード
- 断面作成のために QGIS へインポートする
- 操作手順
- 地図を「白地図 → 標準地図」に変更
- メッシュ種別:5m メッシュ
- 数値標高モデル:533944 / 533945 を選択
- 「追加」→ 画面右上「ダウンロード等」→「ダウンロードファイルリスト」から取得
3-1-1. QGISで DEM を読み込み、断面図を作成する
- 使用プラグイン
- Quick DEM for jp
- Profile Tool
- 手順
- QGIS → プラグイン →「Quick DEM for jp」をインストール
- アイコンをクリックし、ダウンロードした DEM(zip のまま)を指定
- 「Profile Tool」をインストール
- 西荻北5_720 の切り抜き結果(赤🔴)をターゲットにする
- DEM5A_533944 / DEM5A_533945 を Add Layer に追加
- 表示された断面図 グラフをスクリーンショットで保存

画像の見方:
クリックして拡大して下さい。
下部の方の赤い線で描かれたグラフがターゲットを北北東から
南南東に切断した地形断面図。
上部の地図では赤い線が引かれターゲット付近に小さな🔴見えます。
グラフにひかれた赤い縦線が🔴
付近の具体的断面図になります。
素晴らしい出来映え😍、また簡単に地形断面図が描けました!
3-2. 下水道台帳の確認
🍟資料データ
東京都下水道局:
- 住所検索から該当箇所の台帳を表示
- 必要な部分をスクリーンショットで保存
- ポイントレイヤ西荻北5_720_切り抜き結果の属性テーブルを表示
- 編集モードで新規
- 新規フィールド"下水道台帳"を作成
- データにプロジェクトに格納したスクリーンショットのpathを記述
😣 ごめんなさい。属性テーブルが文字化け、影響ないのでこのまま
進行。
3-3. QGISポップアップ(Tips)の設定
- 対象レイヤ:
- 西荻北5_720_切り抜き結果
- 手順
- レイヤを右クリック →「プロパティ」
- 右側メニューから 「表示名」 を選択
- 表示名を 「下水道」 に変更
- 「Tips を有効化」にチェック
- 下記 HTML を「地図の Tips」に貼り付ける
<h3 style="color: navy;">物件周辺情報と下水台帳</h3>
<p style="font-size: 1.1em; margin-bottom: 15px;">
<strong>賃料単価:</strong> ¥ [% "suumo_data_ハザード - コピー_単価" %] / m²<br>
<strong>面積:</strong> [% "suumo_data_ハザード - コピー_area" %]<br>
<strong>駅からの情報:</strong> [% "suumo_data_ハザード - コピー_walk_info" %]
</p>
<hr>
<div style="text-align: center; margin-top: 20px;">
<a href="[% 'file:///' || @project_folder || '/' || "下水道�" %]" target="_blank">
<img
src="[% 'file:///' || @project_folder || '/' || "下水道�" %]"
style="max-width: 100%; max-height: 400px;"
alt="下水道台帳画像"
/>
</a>
<p style="font-size: 0.9em; color: #666;">画像をクリックすると拡大表示されます</p>
</div>
この HTML は、QGIS の「地図の Tips」で
- 賃料単価
- 面積
- 駅からの徒歩情報
- 物件付近の地形断面図の画像
- 下水道台帳の画像
ただし、地形断面図と下水道台帳の画像は編集して統合
(power point使用)
をポップアップ表示するためのテンプレートです。
[% ... %] の部分は QGIS の式で、
属性値やプロジェクトフォルダ内の画像パスを動的に参照しています。
属性テーブルのフィールドデータを表示しているわけです!
✨結果:
地図上の🔴ターゲットにカーソルを合わせると

かつ、画像の上でマウスクリッククリックすると画像が拡大
します。
4.QGIS × 下水道台帳 × 集水面積から「限界降雨強度」を概算する(西荻北5-21 街区)
はじめに
本節では、QGIS と下水道台帳を組み合わせて、
街区単位の集水面積から「どの程度の雨で下水管が限界になるか」を概算する方法をまとめます。
実務レベルの精密設計ではありませんが、
「街区の雨水負担を GIS で可視化する」ための実用的な手順です。
今回の資料データ
有明漁民・市民ネットワーク
🟠 上記サイトマニングの公式がわかりやすい
4-1. 使用データと対象街区
🟨 対象:西荻北5-21 街区
ツールバー → ベクタ → ファイル名(ジオメトリ:ポリゴン
, CRS:6677) → 編集モード → ポリゴン新地物追加 → 枠線実行
結果
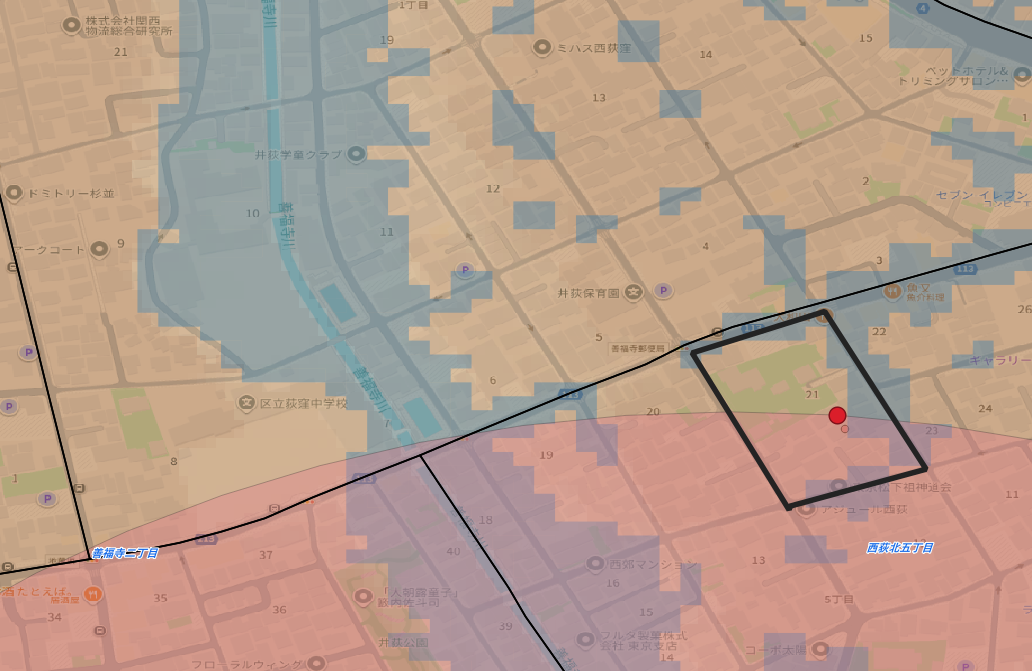
上記、黒太枠内の面積を求める
🟧下水道台帳から読み取った情報
-
全て 合流式
-
北側:φ40 cm → φ103 cm(鉄筋コンクリート)
-
南側:φ25 cm → φ40 cm → φ103 cm(陶管 → 鉄筋)
-
南側:φ25 cm → φ40 cm → φ103 cm(陶管 → 鉄筋)
-
街区を囲む雨水桝:12 箇所
4-2. QGIS で集水面積を求める
- ポリゴンレイヤを右クリック →「属性テーブル」
- フィールド計算機を開く
- 新規フィールド:area_m2
- 式:
$area
→ 今回の街区は 9008.051 m²
4-3. マニング式で下水管の最大流量を求める
マニング式は「水がどれくらいの速さで流れるか」を求める式で、
下水管の流量を概算する際に広く使われています。
❗ 以下はCopilotさんにお尋ねしました
下水管の流量は マニング式で求めます。
マニング式とは:
マニング式は、「水がどれくらいの速さで流れるか」を計算するための公式です。
マニング式はこういう形です:
v = (1/n)*R^(2/3)*S^(1/2)
Q = v*A
でも、式を覚える必要はありません。
それより大事なのは「意味」です。
-
勾配(S)=坂の角度
坂が急なら水は速く流れる
→ S が大きいと v(速さ)が大きくなる -
水力半径(R)=水の通り道の太さ
太い管ほど水が流れやすい
→ Rが大きいとvは大きくなる -
粗度係数(n)=内側のザラザラ度
ツルツル(コンクリート) → よく流れる → n が小さい
ザラザラ(陶管・古い管) → 流れにくい → n が大きい
→ n が大きいと v が小さくなる
🚰 つまりマニング式はこう言っている
水は、太くて、傾いていて、ツルツルした管ほど速く流れる。
これを数字で表すのがマニング式です。
📦 そして流量(Q)は「速さ × 面積」
流量(どれだけ水が流れるか)は、
𝑄 = 𝑣 × 𝐴
- v:水の速さ(マニング式で求める)
- A:管の断面積(円なら πD²/4)
4-3.下水道台帳からのデータ
v = (1/n)*R^(2/3)*S^(1/2)
Q = v*A
- 𝑛 = 0.013(コンクリート・陶管の代表値)
- 𝑆 = 1/200 (勾配が不明のため標準的な値を仮定)
- 管径(φ250)単位:mm
- 管径(φ400)単位:mm
- 合流式下水道
📦 結果(街区の限界降雨強度の概算)
-
φ25 cm 管の限界降雨強度:およそ 20 mm/h 前後
-
φ40 cm 管のみの場合:およそ 70 mm/h 程度まで耐えられるイメージ
4-5.重要な前提と限界
- 勾配・粗度・実際の管条件が分からないので、
これはあくまで「標準的条件を仮定した概算」です。 - 実務レベルの設計や評価では、
- 実際の勾配
- 管種(材質)
- 接続状況(他流域との合流)
- 設計降雨強度式(地域ごとの公式)
5. 付録 ターゲット物件2025時間最大降雨量の推測
ここでの資料データ
地域気象観測所一覧
5-0. 観測所の緯度,経度の取得
from operator import index
import requests
import pdfplumber
import pandas as pd
from io import BytesIO
url = "https://www.jma.go.jp/jma/kishou/know/amedas/ame_master.pdf"
response = requests.get(url)
response.raise_for_status()
pdf_bytes = BytesIO(response.content)
rows = []
with pdfplumber.open(pdf_bytes) as pdf:
page = pdf.pages[21]
tables = page.extract_tables()
if tables:
table = tables[0] # ★ p22 の正しいヘッダ+3行
for i in [0,6,8,9]:
rows.append(table[i])
df = pd.DataFrame(rows)
df.to_csv(
"練馬_府中_世田谷.csv",
index=False,
header=False,
encoding="utf-8-sig")
# 必要な列だけ抽出
df2 = df[[0,1,3,7,8,9,10]].copy()
# 列名をわかりやすく変更
df2.columns = [
"都道府県振興局",
"観測所番号",
"観測所名",
"緯度_度",
"緯度_分",
"経度_度",
"経度_分"
]
# 数値に変換(文字列 → float)
for col in ["緯度_度", "緯度_分","経度_度", "経度_分"]:
df2[col] = pd.to_numeric(df2[col], errors="coerce")
df2["lat"] = df2["緯度_度"] + df2["緯度_分"] / 60
df2["lon"] = df2["経度_度"] + df2["経度_分"] / 60
df2 = df2[["都道府県振興局", "観測所番号", "観測所名", "lat", "lon"]]
df2.to_csv("練馬_府中_世田谷観測地点.csv", index=False, encoding="utf-8-sig")
print(df2.to_string())
※ DataFrameやCSVに読み込まれた、一見数値に見えても
文字列の場合が多いので数値に変換。
十進法表示にしてQGISで扱いやすくする。
出力結果

5-1.ボロノイ多角による近傍観測所の決定
- ボロノイ多角形を使う背景
降雨データは観測所という地図上の「点」におけるデータです。しかし、実際には少し場所がずれれば雨の降り方も変わる。それでは、観測所で得られた「降り方(降雨データ)」は、地図上でのどのような範囲まで反映させたらよいのでしょう。ここでは、便宜上の設定として、ボロノイ分割を採用してみました。 - ここでQGISにlot, lat の数値からポイントレイヤとして
練馬、府中、世田谷の各観測所を配置 - ポイントレイヤをアクティブにする
- プロセッシング → ツールボックス → 検索"ボロノイ"
- 入力レイヤ: 観測所ポイントレイヤpath
- バッファ領域: 50.0000
- 実行

ボロノイ多角形で最寄り観測所を決定した結果。
赤:ターゲット物件、ピンク:観測所。練馬が最寄りと判定。
5-2 2025年時間最大降雨量
今回の資料データ
🎡 練馬区2025年の時間最大降雨量は

😲 午後3時の44mmです、 φ25cm管は内水氾濫の
可能性がゼロではない。
6. 結論
今回の物件は、街区を囲む下水管が陶管で、
埋設から長い時間が経過していること、
φ25 cm が街区の最小径であり、ここが全体の流量を制限するため、
限界降雨強度はこの管を基準に評価します。
一方で、交通利便性などのメリットも大きく、
不動産評価は「複数の視点を組み合わせて判断する」ことが重要だと感じました。
温暖化による降雨リスクを踏まえ、
賃貸・売買の不動産データを 従来より広い視点で解析的に取得することは、
今後ますます必要になると考えています。
Python と QGIS を活用することで、データの裏側にある“リスク”を
直感的に理解できるようになります。
読んでくださってありがとうございました。