背景
画像系の機械学習エンジニアとしてはいまさらながらなのですが、
以下の書籍を用いてVisiontransformerの理論と実装について、学びなおししています。
読み進めていると、第二章のInput layerの説明のところが目に留まりました。
PyTorchで用意されている畳み込み層nn.Conv2dを使えば、
「パッチへの分割」と「埋め込み」が1行でまとめてできるためです。
(中略)
この解説でわかりにくい場合は、実際に画像と畳み込みのカーネルを絵に描き、
カーネルサイズおよびストライドをバッチサイズにした際の
畳み込みの挙動を図示すると理解しやすくなります。
文字を見た瞬間だけだと理解しきれず、実装を見てもイメージできなかったので、
本に進められるがままに、図解して理解してみることにしました。
前提条件
以下のConv2dでパッチ分割と、埋め込みをすることを考えたい。
img_size = 81 # (3, 81, 81)
in_channel = 3
emb_dim = 128
patch_size_row = 3 # pathc num: 3 * 3 = 9
patch_size = img_size // patch_size_row # 27
self.patch_embed = nn.Conv2d(
in_channels=in_channel,
out_channels=emb_dim,
kernel_size=patch_size,
stride=patch_size,
)
図解してみた
まず最初の畳み込みは、緑の部分が対象になる。
3 x 27 x 27のブロックを畳み込む。
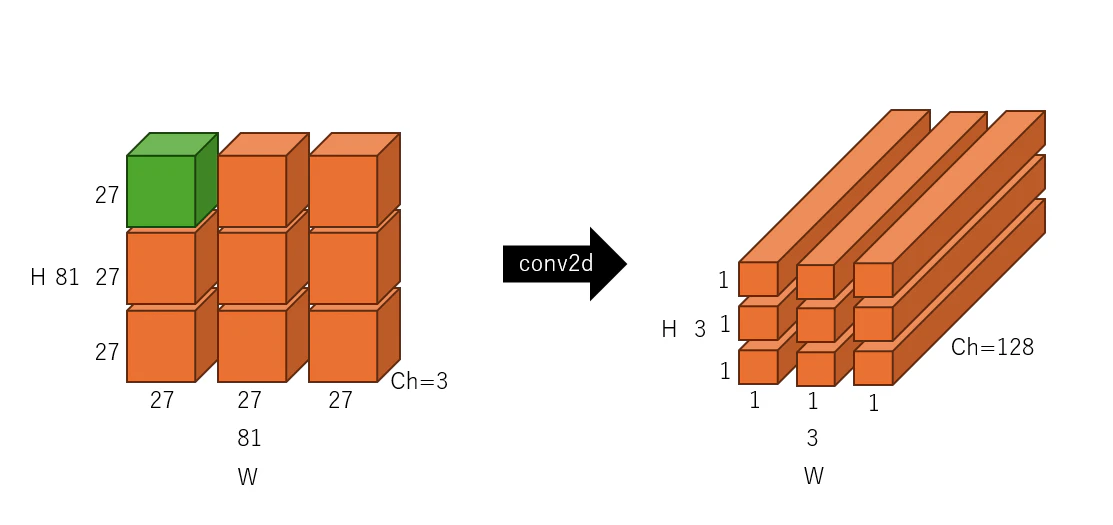
アウトプットとしては以下のような図の対応関係になり、
128 x 1 x 1の出力が出てくる。

次はストライドが27なので、分割された次のブロック、つまり下図の青色が対象になる。
出力は同等で、今後は同じようなことを繰り返していくだけ。
パッチ画像のサイズ = ストライドのサイズ、とすることによって、パッチ画像ブロックごとに畳み込みをすることができ、結果埋め込みまでを1つの関数でやりきれる、というわけである。

まとめ
図示してみると、すんなり理解することができました。
参考