この記事は BrainPad AdventCalendar 2017 3日目の記事です。
本記事では、Google Cloud Platform(GCP)上に、jupyter notebook でアクセスできるOpenAIGym環境を作ります。
環境構築
GCPでjupyter notebook用のportを開け、インスタンスを作成
ネットワーキングサービスから、ファイアウォールルールを追加し、jupyter notebook 用のportを開けます。
インスタンスは ubuntu LTS 16.04 で作成しました。
仮想マシン上で環境構築
公式サイト https://gym.openai.com/docs/ と、
記事 https://qiita.com/mittyantest/items/2ea07b0f8d5976f29da9 を参考に、
最低限必要なものをインストールします。
sudo apt-get update
sudo apt-get upgrade -y
sudo apt-get install -y python3-pip \
python3-opengl \
xvfb \
cmake \
zlib1g-dev \
swig \
imagemagick \
mpich
pip3 install jupyter \
matplotlib \
mpi4py \
opencv-python
OpenAI Gym 最小構成のインストール
OpneAI Gym をまずは最小構成でインストールし、jupyter notebook から実行できるか確認します。
git clone https://github.com/openai/gym
cd gym
pip3 install -e . # minimal install
OpenAI Gym のゲーム画面を jupyter notebook から見れるようにするため、以下のようにして、Xvfbで仮想ディスプレイを設定し、jupyter notebookを起動します。
cd ~
nohup xvfb-run -s "-screen 0 1400x900x24" jupyter notebook --no-browser --ip=* &
サンプルコードが動くことを確認します。jupyter notebook 上で CartPole のアニメーションが表示されれば成功です。
import gym
from matplotlib import animation
from matplotlib import pyplot as plt
%matplotlib nbagg
env = gym.make('CartPole-v0')
# Run a demo of the environment
observation = env.reset()
cum_reward = 0
frames = []
for t in range(5000):
# Render into buffer.
frames.append(env.render(mode = 'rgb_array'))
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
break
env.render(close=True)
fig = plt.gcf()
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(fig, animate, frames = len(frames), interval=50)
anim
anim.save("CartPole-v0.gif", writer = 'imagemagick')
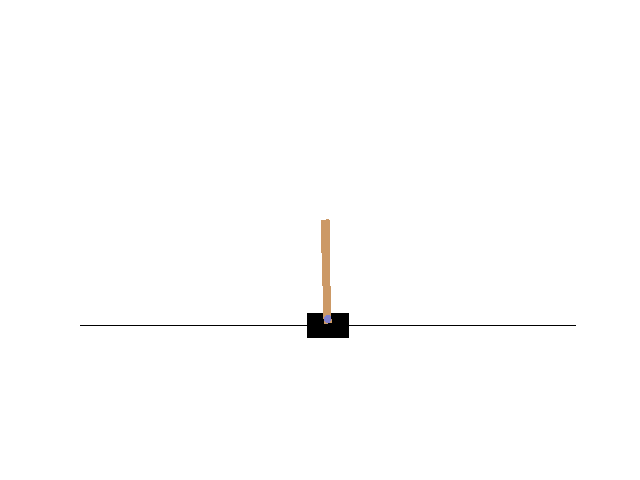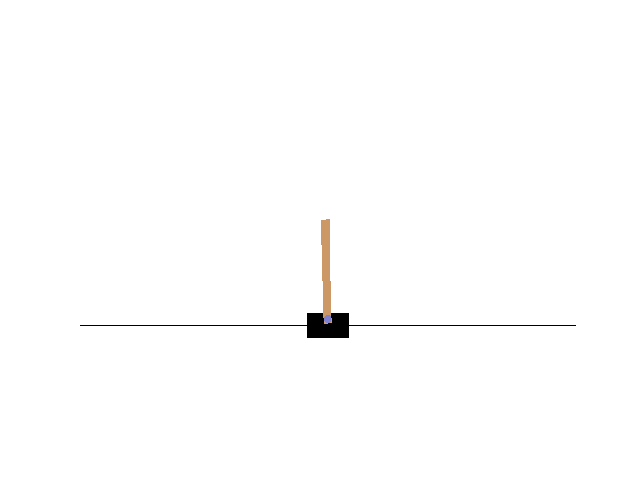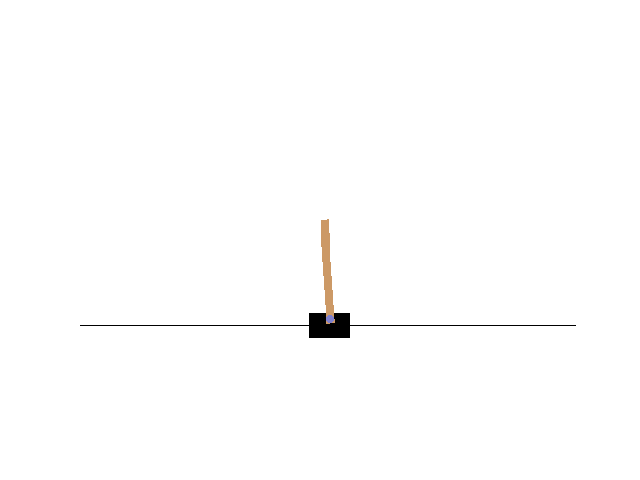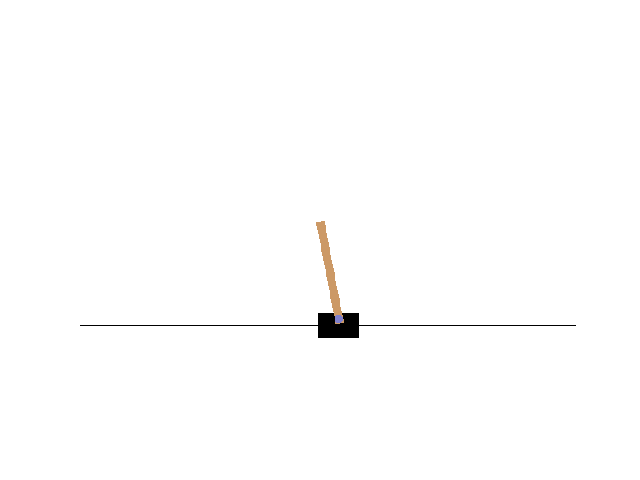
OpenAI Gym フルインストール
CartPole で成功したら、atari のゲームなどすべての環境をインストールします。
cd gym
pip3 install gym[all] .
cd ~
nohup xvfb-run -s "-screen 0 1400x900x24" jupyter notebook --no-browser --ip=* &
atariのゲームを動かしてみます。
インベーダーゲームのアニメーションが表示されれば成功です。
import gym
from matplotlib import animation
from matplotlib import pyplot as plt
%matplotlib nbagg
env = gym.make('SpaceInvaders-v0')
# Run a demo of the environment
observation = env.reset()
cum_reward = 0
frames = []
for t in range(5000):
# Render into buffer.
frames.append(env.render(mode = 'rgb_array'))
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
break
env.render(close=True)
fig = plt.gcf()
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(fig, animate, frames = len(frames), interval=50)
anim
anim.save("SpaceInvaders-v0.gif", writer = 'imagemagick')
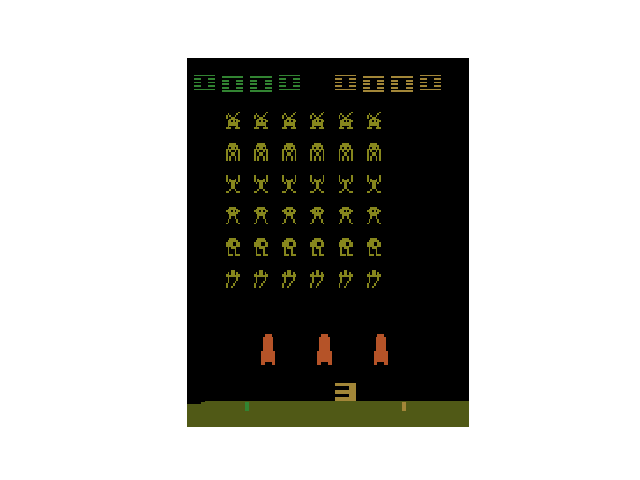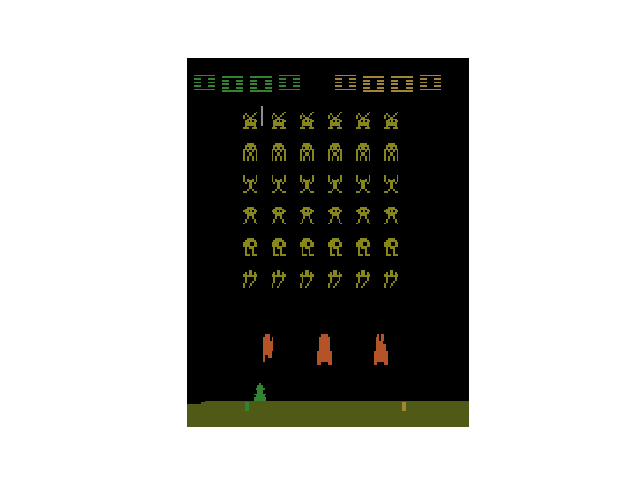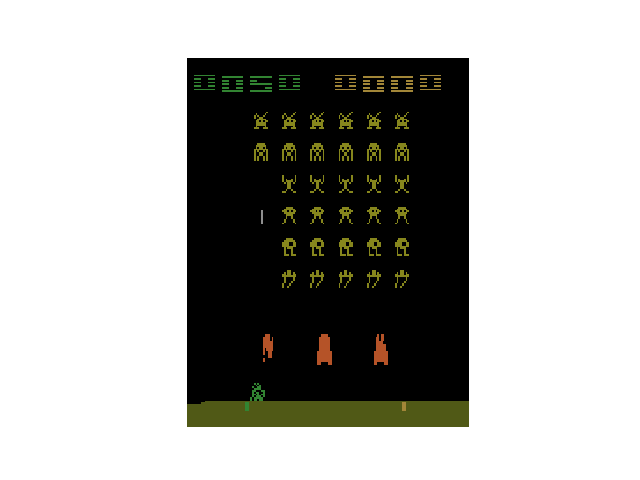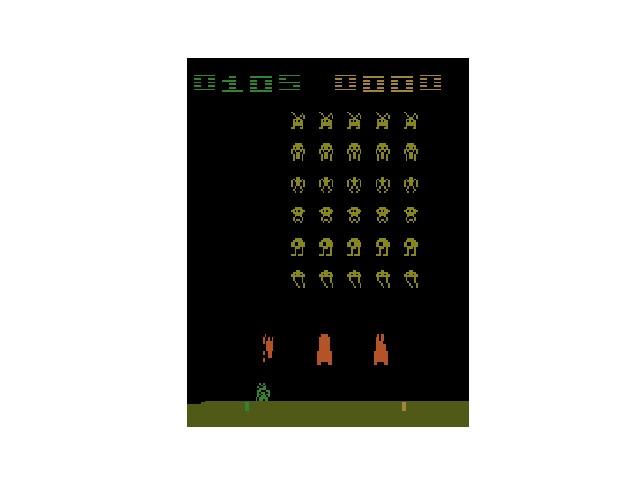
OpenAI Baselines の実行
OpenAI は強化学習のための環境だけでなく、アルゴリズムの tensorflow での実装を github で公開しています。今回はPPO1を実行してみます。
cd ~
git clone https://github.com/openai/baselines
cd baselines
pip3 install -e .
cd ~/baselines
mpirun -np 8 python3 -m baselines.ppo1.run_atari --seed=1234 --env=SpaceInv
adersNoFrameskip-v4
実行されましたが、数値情報が出力されるだけのため、モデルを保存して結果をレンダリングするためには、コードに手を入れる必要があります。
PPOのようなマルチスレッドの実装が github で公開されているのは大変参考になりますが、A2CとPPOでも実装が結構違うように見え、コード読み進めていたものの、 間に合わなかったので今回はここまで。
次は、OpenAIBaselinesのアルゴリズム実装について読み込んでいきたいです。