を素人が調べてやってみた。(諸々怒られたら消します)
パッケージのインストール
(簡単にいうと辞書のインストール(辞書というとわかりにくいかもしれないので、追記すると言語をソフトに覚えてねという感じで入れるようなものです。)
import requests
from bs4 import Beautiful Soup
import pandas as pd
import re
from time import sleep
import sys
import ME Cab
import numpy as np
from PIL import Image
from sklearn.feature_extraction.text import TfidfVectorizer
import matplotlib.pyplot as plt
%matplotlib inline
をします。
これは、5年前の記事でさらに環境が違うのでエラーがでます。時折AIに聞いたり調べたりして進めます。
環境まとめ
Windows11 Visual Studio Code
↓からダウンロードできます。
エラーが出たのといえば、
ME Cab
PIL
%matplotlib inline
でした。これはみたことのないパッケージだったので、調べると環境によるものでした。
pip list
で、今入ってるパッケージが確認できるのですが、それが古い場合はアップデートします。
pip install --upgrade
まず
PIL
ではなく、こちらがもう使われてないらしいので
pip install Pillow
でした。つまり、PTLの後継としてインストールするわけです。
%matplotlib inline
は、Jupyter環境でのみ使用可(Pythonファイルではエラー)なそうなので
修正後はこうなります。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
from time import sleep
import sys
import MeCab
import numpy as np
from PIL import Image
from sklearn.feature_extraction.text import TfidfVectorizer
import matplotlib.pyplot as plt
が、ここでもエラーが起きてしまっているので、なぜかと思います。
まぁ、全部AIに聞いたらできるんですが、それだと面白くないので。
最後の二行にエラーがでています。
で検索すると、どうやら画像認識とか
”機械学習ライブラリ”
らしいぞ。と思いました。
他にも面白そうな記事があるのでとりあえず、トップも貼っておきますね。
Package Version
beautifulsoup4 4.14.2
blinker 1.9.0
certifi 2025.10.5
charset-normalizer 3.4.4
click 8.2.1
colorama 0.4.6
Flask 3.1.1
idna 3.11
itsdangerous 2.2.0
Jinja2 3.1.6
MarkupSafe 3.0.2
mecab-python3 1.0.10
numpy 2.3.4
pandas 2.3.3
pillow 12.0.0
pip 25.3
python-dateutil 2.9.0.post0
pytz 2025.2
requests 2.32.5
six 1.17.0
soupsieve 2.8
typing_extensions 4.15.0
tzdata 2025.2
urllib3 2.5.0
Werkzeug 3.1.3
まぁ、この時点ではこの状態です。
pip install scikit-learn
pip install matplotlib
で消えたのでパッケージがまだインストールされていないのだとわかりました。
次は画像データの元となる歌詞のスクレイピングです。
https://www.uta-net.com/
ご利用ユーザーの責務及び禁止事項
以下の行為またはこれに該当する恐れのある行為は一切禁止させていただいております。
1
このウェブサイトの全内容又はその一部について、歌ネットに無断で複製、改変、編集、アップロード、提示、送信、頒布、販売、スクレイピングなど、その他これに類する行為を行う行為
とあるのでやめておいて別なところをさがしましょう。
でこちらにしました。スクレイピングで検索しましたがでてきませんでしたね。(怒られたら消しますね。めっちゃ広告でてきますね。これ。めっちゃ重いわけですわ。)
検索してポチポチしてみた結果何も出てこないので、AIに聞いてみてhtmlを見た感これでは動かないっぽいので、次に行きます。
from None ImportError: lxml.html.clean module is now a separate project lxml_html_clean. Install lxml[html_clean] or lxml_html_clean directly.
というエラーが出たのでAIに聞きました。どうやら
”Python 3.13+最新の lxml では、requests_html がまだ追従できていないために起こっています。”
とのことです。
"requests_html → pyppeteer → Googleの古いChromiumスナップショットURL
を使ってダウンロードしようとしているが、
そのURL(1181205ビルド)がもう 削除済み or 移動済み だからです。"
だそうです。
でもエラーなのでなんで??とAIに聞きました。
するとこれかもしれないそうです。
これはまたいろいろでてきましたね。
AIに聞いてみたら”いいデバッグです”からの
見つかった曲数: 52
title link
0 蒼い薔薇 https://utaten.com/lyric/jb20901148/
1 日本誕生 https://utaten.com/lyric/jb20901144/
2 世界一 https://utaten.com/lyric/jb20611007/
3 卒業哀歌 https://utaten.com/lyric/jb20611008/
4 Hi-Fi https://utaten.com/lyric/jb20611001/
...
何これしらんってなりました。
そろそろBANされても怖いので。そろそろ終わりたいんですが…
できないね。構造が変わっているらしいんですがコードを見ると、そこまで複雑ではなさそうなんですがね。ふむう。と思い、曲のリンクを送ってみたら
import requests
from bs4 import BeautifulSoup
import pandas as pd
from time import sleep
def get_song_links(artist_id):
"""
アーティストページから全曲リンクを収集
"""
base = f"https://utaten.com/artist/lyric/{artist_id}/?p="
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
songs = []
for page in range(1, 6): # 1〜5ページ分だけ試す(曲が多ければ調整)
url = base + str(page)
print(f"Fetching list page: {url}")
res = requests.get(url, headers=headers)
if res.status_code != 200:
print("❌ Failed to get:", url)
break
soup = BeautifulSoup(res.text, "html.parser")
links = soup.select("a[href^='/lyric/']")
if not links:
print(" → No song links found.")
break
for a in links:
href = a.get("href")
text = a.get_text(strip=True)
if href and "/lyric/" in href:
songs.append({
"title": text,
"url": "https://utaten.com" + href
})
sleep(1)
print(f"✅ Collected {len(songs)} songs.")
return songs
def get_lyrics(url):
"""
歌詞ページから本文を抽出
"""
headers = {"User-Agent": "Mozilla/5.0"}
res = requests.get(url, headers=headers)
if res.status_code != 200:
return ""
soup = BeautifulSoup(res.text, "html.parser")
body = soup.find("div", class_="lyricBody")
if not body:
return ""
return body.get_text("\n", strip=True)
# ===== 実行部分 =====
artist_id = "453" # ← T.M.Revolution
songs = get_song_links(artist_id)
data = []
for s in songs:
print("Getting:", s["title"])
lyric = get_lyrics(s["url"])
data.append({"Title": s["title"], "URL": s["url"], "Lyrics": lyric})
sleep(1)
df = pd.DataFrame(data)
df.to_csv("lyrics_〇.csv", index=False, encoding="utf-8-sig")
print("✅ 完了! lyrics_〇.csv に保存しました。")
Fetching list page: https://utaten.com/artist/lyric/453/?p=1
Fetching list page: https://utaten.com/artist/lyric/453/?p=2
Fetching list page: https://utaten.com/artist/lyric/453/?p=3
Fetching list page: https://utaten.com/artist/lyric/453/?p=4
Fetching list page: https://utaten.com/artist/lyric/453/?p=5
✅ Collected 1210 songs.
がでてきたので、目的としては達成できた感があります。AIは二転三転しますし、複雑なコードを書きがちです。
時間はかかりますがこれの方が確実に目的を達成できます。
CSVはできたのですが、ドライブにあげたところ確認ができませんね。
ぼすけて
ってなったわけですが、まぁ、とりあえず、すすめましょうか。
これを後、TNNKとabhingdonboysschoolまでやらないといけない。
とりあえず次です。
import pandas as pd
import re
# 読み込み
df = pd.read_csv("lyrics_〇.csv")
# 不要な空白を整形
def clean_spaces(text):
if pd.isna(text):
return text
text = re.sub(r'\s+', ' ', text) # 連続空白を1つに
text = re.sub(r' +', ' ', text) # 全角スペースも1つに
text = text.strip() # 前後の空白を削除
return text
# 歌詞カラム(Lyrics)を整形
df['Lyrics'] = df['Lyrics'].apply(clean_spaces)
# 新しいファイルとして保存
df.to_csv("lyrics_〇_clean.csv", index=False, encoding='utf-8-sig')
print("✅ lyrics_〇_clean.csv に保存しました。")
空白整形してと言ったらこんなコードを作ってくれました。珍しく気が利くな、別に整形してもよかったんやぞ。(はらへりになってきた)
import re
import pandas as pd
# 元CSVを読み込む
df = pd.read_csv("lyrics_〇.csv")
def clean_lyrics(text):
if pd.isna(text):
return text
# ふりがな形式「夏 なつ」「宝物 ほんもの」を削除
text = re.sub(r'([一-龥々〆ヵヶ]+)\s+[ぁ-んァ-ンー]+', r'\1', text)
# ローマ字形式「夏 natsu」「恋 koi」などを削除
text = re.sub(r'([一-龥々〆ヵヶぁ-んァ-ンー]+)\s+[a-zA-Z]+', r'\1', text)
# 重複削除(2回同じ文があるパターンも一応対応)
text = re.sub(r'(.*?)\1+', r'\1', text)
# 全角スペース・余分な空白削除
text = re.sub(r'\s+', ' ', text).strip()
text = text.replace(' ', ' ')
return text
# 歌詞列(例:"Lyrics" カラム)を整形
if 'Lyrics' in df.columns:
df['Lyrics'] = df['Lyrics'].apply(clean_lyrics)
else:
print("⚠ CSVに 'Lyrics' カラムが見つかりません。")
# 整形後のファイルを書き出し
df.to_csv("lyrics_〇_clean.csv", index=False, encoding="utf-8-sig")
print("✅ 不要なふりがな・ローマ字・空白を削除しました → lyrics_〇_clean.csv")
と出してきて宝物と書いてほんものと読む奈々語並に難しいぜ。(最近はそういうのない)
昔小屋をロッジと読んでました。ロッジじゃん。今もある奈々語の方が珍しいのでは…歌ってる人違うしなこれは。
import pandas as pd
# CSVファイルを読み込み
df = pd.read_csv("lyrics_〇_clean.csv")
# Lyrics列を基準に重複削除(最初の1件だけ残す)
df_unique = df.drop_duplicates(subset=["Lyrics"], keep="first")
# 新しいCSVとして保存
df_unique.to_csv("〇_clean_unique.csv", index=False)
print("✅ 重複を削除しました。新しいファイル: lyrics_〇_clean_unique.csv")
とっとと終われと君ばかり抱いてる??ってこんな感じ??
あーそうですか。課金しろですか資金ないです。
で、アルバムごとに分けてもいいのですが、10枚以上あるのでオタクはもう眠いのです。
これを後、TNNKとabhingdonboysschoolまでやらないといけない。(二回目)
次に出てきた歌詞をデータ化にしていきます。
から
import csv
import os
from os import path
from wordcloud import WordCloud
# get data directory (using getcwd() is needed to support running example in generated IPython notebook)
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# Read the whole text.
file_path = path.join(d, r"C:csvの場所)
with open(file_path, encoding='utf-8') as f:
text = f.read()
wordcloud = WordCloud(
width=800,
height=600,
background_color='white',
font_path='C:\\Windows\\Fonts\\meiryo.ttc' # 日本語フォント
).generate(text)
# Display the generated image:
# the matplotlib way:
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
# lower max_font_size
wordcloud = WordCloud(max_font_size=40).generate(text)
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# The pil way (if you don't have matplotlib)
# image = wordcloud.to_image()
# image.show()

???
失敗か??とおもったら、出ました。

でもなんかうたてんとかhttpsとか入ってるの消したいですね。と思ったので。
少し調べましたがでてこなかったので、AIに聞きました。
#!/usr/bin/env python
import os
import re
from os import path
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
# 現在のスクリプトのディレクトリ
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# CSVファイルのパス
file_path = path.join(d, '')
# --- 📂 ファイル読み込み ---
with open(file_path, encoding='utf-8') as f:
text = f.read()
# --- 🧹 前処理 ---
# URL(https://やhttp://)を削除
text = re.sub(r'https?://\S+', '', text)
# 不要な英単語なども削除(UtaTenやlyricなど)
remove_words = ["utaten", "lyric", "lyrics", "https", "http"]
for word in remove_words:
text = text.replace(word, "")
# --- 🔍 Janomeで形態素解析(名詞だけ抽出) ---
t = Tokenizer()
words = [
token.base_form for token in t.tokenize(text)
if token.part_of_speech.startswith('名詞')
]
# --- 🧩 名詞をスペース区切りで結合 ---
filtered_text = " ".join(words)
# --- ☁️ WordCloud生成 ---
wordcloud = WordCloud(
font_path='C:\\Windows\\Fonts\\meiryo.ttc', # 日本語フォント指定
background_color='white',
width=800,
height=600,
colormap='viridis' # カラーマップ変更可
).generate(filtered_text)
# --- 🖼 表示 ---
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
で完全なコード(ドヤァ)としてきますがエラーコードを見ると、やはり開けないので、
AIは間違うこともありますッ!ってドジっ子設定にしておくと脳内が平和でよいです。
(まぁ間違いを認めないんですけど)
# CSVファイルのパス
file_path = path.join(d, “ファイルの場所”)
# --- 📂 ファイル読み込み ---
with open(file_path, encoding='utf-8') as f:
text = f.read()
ファイルの場所を変えます。
すると開けました。
ではこれの形を替えてみましょう。
T.M.Revolution

これは私が書いたマイクなのですが元画像

この汚れみたいなんなんだろうと思っております。なんだこれ。
画像加工でわかった事実、まぁいいでしょう。後はIDを書き換えて同じ作業です。
と思ったんですが、データを見ると、なぜか、ni mo yume woなどが出てくるため、なぜだろうと思い、そもそもの元データからして、ローマ字が出ているのですね。そこで空白して整形するようにお願いします。
がcsvのデータで見ても問題ないようなのですが…。今回曲名は弾くことにして曲のURLの列も消して、一番上のlyricの欄だけ残します。
import pandas as pd
import re
# 読み込むテキストファイル
input_file = r"ファイルの場所。"
# 保存するテキストファイル
output_file = "つけたい名前.拡張子"
# ファイル読み込み
with open(input_file, "r", encoding="utf-8") as f:
lines = f.readlines()
cleaned_lines = []
for line in lines:
line = line.strip() # 前後の空白を削除
if not line: # 空行はスキップ
continue
if re.fullmatch(r"[A-Za-z\s]+", line): # 英字だけの行(ローマ字)をスキップ
continue
cleaned_lines.append(line)
# 改行を整えて保存
with open(output_file, "w", encoding="utf-8") as f:
f.write("\n".join(cleaned_lines) + "\n")
print(f"✅ ローマ字と余分な空行を削除して整形したファイルを作成しました: {output_file}")
これを処理すると
# 不要な英単語なども削除(UtaTenやlyricなど)
remove_words = ["utaten", "lyric", "lyrics", "https", "http"]
for word in remove_words:
text = text.replace(word, "")
の部分が必要なくなります。
最初のコードの
data = []
for s in songs:
print("Getting:", s["title"])
lyric = get_lyrics(s["url"])
data.append({"Title": s["title"], "URL": s["url"], "Lyrics": lyric})
sleep(1)
titleとURLがいらなかったですね。まぁ全部やってから気づきましたが、まぁ合った方が処理する上でわかりやすかったかもしれないので、まぁあってもいいことにしましょう。
・文字のYO!SAY!の部分は歌詞なので残さないとなりません。確信的なSTYLEも歌詞なので残さないといけません。
・データを見ると、ni、mo、wo、gaなどのふりがなが邪魔です。
import re
input_file = "lyrics.txt"
output_file = "lyrics_cleaned.txt"
# 削除したい短いローマ字のリスト
delete_words = {"ni", "wo", "ga", "mo"}
with open(input_file, "r", encoding="utf-8") as f:
lines = f.readlines()
cleaned_lines = []
for line in lines:
line = line.strip()
if not line:
continue
# 小文字だけの短いローマ字行で削除対象かチェック
if line.lower() in delete_words:
continue
# 長い英字だけの行(ふりがな)を削除
if re.fullmatch(r"[A-Za-z\s]{3,}", line):
continue
# それ以外は残す
cleaned_lines.append(line)
with open(output_file, "w", encoding="utf-8") as f:
f.write("\n".join(cleaned_lines) + "\n")
print(f"✅ 指定ローマ字とふりがなだけ削除したファイルを作成しました: {output_file}")
そして、メモ帳で一応確認ざーーーっと確認して、ないな、geruとかwoとかだなとか確認して該当は消します。

いい感じです。これはわかりやすくするためにクリスタのハートの絵を使っています。

クリスタでいじって消しても出てくる謎の汚れなんだこれ。まぁいいですわ。(めんどくなってきた。)
T.M.Revolution



abingdonboysschool
同じ作業だーと思ったら、なんか英語が消されて日本語の音だけ残ってますね。これではデータとして不完全です。
消す:英語に被ってるカタカナ、ローマ字
残す:英単語、漢字とひらがな。カタカナ
なのですが、abingdonboysschoolの作詞は全部vocalである西川貴教さんなので、極論として、全部のデータから作りたい感がありますので、日本語とひらがな、カタカナ、英単語の3つを作って後で足すという形式をとることにしました。
TMRの場合は、そこまで目立たたないし英単語もabsより少な目なイメージで進めております。
(全ては私の独断と偏見で行われております。)
何回かしたうちに改行を日本語はやめ、英語は名詞・形容詞・動詞のみにしました。
最終的にこうなります。
import numpy as np
from PIL import Image
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import re
from janome.tokenizer import Tokenizer
import os
from os import path
# --- スクリプトのパス ---
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
# --- 📂 歌詞ファイル ---
file_path = path.join(d, r"ファイルの場所")
with open(file_path, encoding='utf-8') as f:
text = f.read()
# --- 🧹 URL・不要語削除 ---
text = re.sub(r'https?://\S+', '', text)
remove_words = ["utaten", "lyric", "lyrics", "https", "http"]
for word in remove_words:
text = text.replace(word, "")
# --- 🇯🇵 日本語名詞抽出 ---
t = Tokenizer()
English_words = [
token.base_form for token in t.tokenize(text)
if token.part_of_speech.startswith('名詞') and len(token.base_form) > 1
]
# --- 日本語ストップワード削除 ---
English_stopwords = {"は", "に", "を", "が", "で", "と", "も", "へ", "や", "から", "まで", "より"}
English_words = [w for w in English_words if w not in English_stopwords]
# --- 🔠 英単語(3文字以上)抽出 ---
english_words = re.findall(r'\b[a-zA-Z]{3}\b', text)
# --- 不要なローマ字・助詞的英単語を除外 ---
romaji_stopwords = {
"ha", "ni", "wo", "ga", "de", "to", "mo", "no", "he", "yo", "ne",
"ka", "sa", "shi", "ko", "so", "ra", "re", "ta", "tte", "nai",
"kedo", "demo", "nara", "kana", "dake", "dare", "kimi", "boku"
}
english_words = [
w.lower() for w in english_words
if w.lower() not in romaji_stopwords and (len(w) >= 4 or w.lower() in {"love", "life", "time", "dream", "light", "heart"})
]
# --- 🧩 日本語+英単語を結合 ---
all_words = English_words + english_words
filtered_text = " ".join(all_words)
# --- 🎭 マスク画像 ---
mask_path = path.join(d, r"ファイルの場所")
mask = np.array(Image.open(mask_path))
# --- ☁️ WordCloud生成 ---
wordcloud = WordCloud(
font_path='C:\\Windows\\Fonts\\meiryo.ttc',
background_color='white',
width=800,
height=600,
mask=mask,
contour_width=5,
contour_color='black'
).generate(filtered_text)
# --- 🖼 表示 ---
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()


いい感じです。これを別の画像で、表現すると。

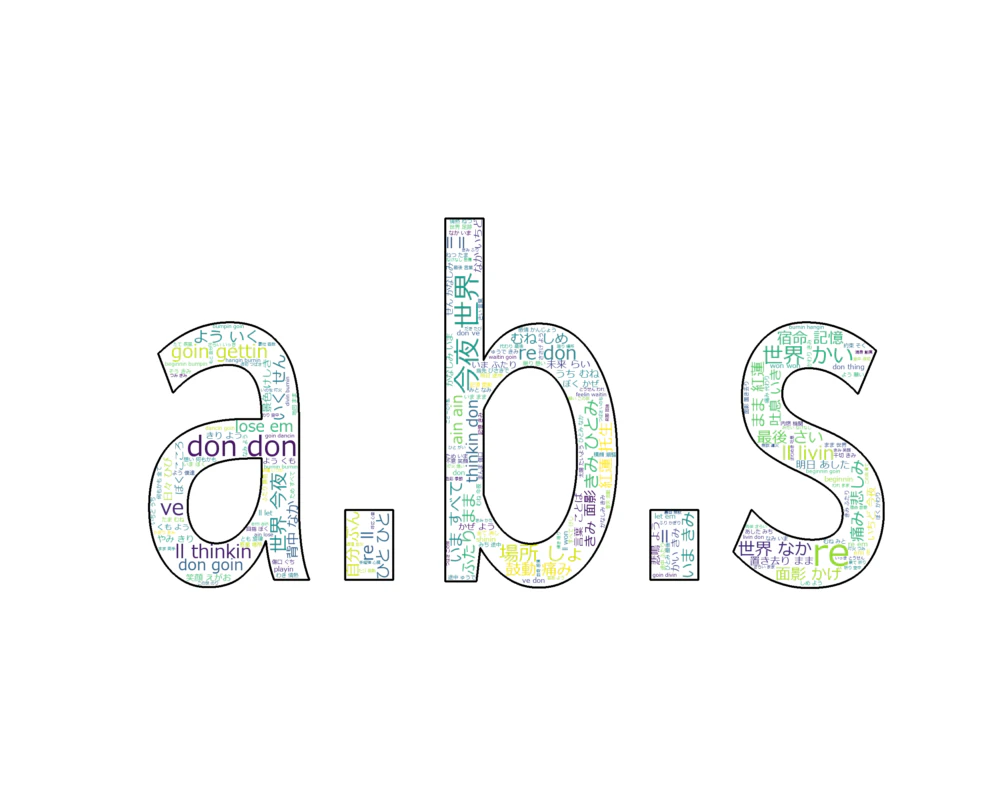

では、次はTNNKですね。


英単語が多すぎたりしてバランスが取れなかったので、
# --- 🔠 英単語(3文字以上)抽出 ---
English_words = re.findall(r'\b[a-zA-Z]{4}\b', text)
# --- 🧩 日本語+英単語を結合 ---
filtered_text = " ".join(japanese_words) + " " + " ".join(English_words)
数字を弄ってみたり、空白をいじってみたりしました。


FREEDOMは別のIDになってましたのでこちらになります。

※なお-eは入ってるか確認しておりません。なぜなら曲が多すぎるからです。ほぼ30年の重みを感じます。
アルバムごとにわけるのもいいですがオリジナルアルバムだけで10枚あり、Rebootも混ざったりアレンジが混ざってることもあります。なので、歌詞はあまり変わりませんが、どの曲をどこのアルバムに持って行くかを考えるだけで一日が終わってしまいます。
※そんなこといっても全部歌ってる人同じなのに、何が違うの思ってらっしゃる方に簡単に説明します。
T.M.Revolution
西川貴教のソロプロジェクトです。皆さんご存じの
【身体が夏になったり凍えそうな季節に愛をどうこういうの】
はここに入ります。
作曲家と作詞家が固定されております。
abingdonboysschool
西川貴教さんがフロントマンを務め、バンドやろうぜ。の形で始まっております。
作詞が西川貴教さん。作曲が他のメンバー(柴崎浩、SUNAO、岸利至)が担当しています。サポメンとして、
IKUO長谷川浩二(以上敬称略)で私は活動を待ち侘びております。
TNNK
西川貴教の歌声でいろいろやってみようがコンセプトです。
作曲家と作詞をしている人が違います。
そのうちのHEROESという曲は西川貴教さんが作詞をされてますが、他はいろんな方々がされています。
FREEDOMが小室哲哉さんが作られた曲として、話題を集め今や大人気の曲となっております。
全て聞いてる時間はなくていいので、段々と沼に入ってください。
以上です。
全て2025年11月の話です。