久しぶりの投稿になります!
来年から新横浜で仕事をすることになったので、横浜エリアの賃貸情報を効率よく比較できたらなーと思い、スクレイピングにてデータを取得することにしました。
参考にしたサイトは、こちらです。
機械学習を使って東京23区のお買い得賃貸物件を探してみた 〜スクレイピング編〜
やりたいこと
Suumoさんのデータから、新横浜近くである港北区および神奈川区にある物件を以下のようなデータ構造で取得したい。
* 写真をいれる
SUMMOさんの利用規約を確認したところ、以下のようになっています。
ユーザーは、本サイトを通じて提供されるすべてのコンテンツについて、当社の事前の承諾なく著作権法で定めるユーザー個人の私的利用の範囲を超える使用をしてはならないものとします。
今回の場合は、あくまで個人的に参照するためにデータを集めるということなので、大丈夫でしょう。
環境
OS:Windows 10
使用する言語:Python
ライブラリ:BeautifulSoup
自分はwindows10上でAnacondaを使っているので、以下のコマンドで仮想環境の構築を行いました。
conda create -n scraping python=3.6.0
pip install beautifulsoup4
とくに仮想環境にこだわらないのであれば、そのまま「pip install beautifulsoup4」として頂いても問題ないと思います。
コードの説明
完成したコード全体は以下のようになりました。
順番に説明したいと思います。
from bs4 import BeautifulSoup
import urllib3
import re
import time
import pandas as pd
from pandas import Series, DataFrame
## ステップ1
http = urllib3.PoolManager()
url = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&pc=30&smk=&po1=25&po2=99&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sc=14102&sc=14109&ta=14&cb=0.0&ct=7.5&md=02&md=03&md=04&md=05&et=9999999&mb=0&mt=35&cn=9999999&fw2="
response = http.request('GET', url)
soup = BeautifulSoup(response.data, "html.parser")
## ステップ2
pages = soup.find_all('ol', class_='pagination-parts')
pages = str(pages)[::-1]
m = re.search(r'\<\d\d\d\>',pages)
max_page_number = int(m.group(0).replace("<", "").replace(">", "")[::-1])
urls = []
urls.append(url)
## ステップ3
for i in range(max_page_number - 1):
page_num = str(i + 2)
url_page = url + '&pn=' + page_num
urls.append(url_page)
names = [] #マンション名
addresses = [] #住所
locations0 = [] #立地1つ目(最寄駅/徒歩~分)
locations1 = [] #立地2つ目(最寄駅/徒歩~分)
locations2 = [] #立地3つ目(最寄駅/徒歩~分)
ages = [] #築年数
heights = [] #建物高さ
floors = [] #階
rent = [] #賃料
admin = [] #管理費
others = [] #敷/礼/保証/敷引,償却
floor_plans = [] #間取り
areas = [] #専有面積
detail_urls = [] # 詳細URL
## ステップ4
for url in urls:
response = http.request('GET', url)
soup = BeautifulSoup(response.data, "html.parser")
apartments = soup.find_all('div', class_='cassetteitem')
## ステップ5
for apartment in apartments:
room_number = len(apartment.find_all('tbody'))
name = apartment.find('div', class_='cassetteitem_content-title').text
address = apartment.find('li', class_='cassetteitem_detail-col1').text
for i in range(room_number):
names.append(name)
addresses.append(address)
## ステップ6
sublocation = apartment.find('li', class_='cassetteitem_detail-col2')
cols = sublocation.find_all('div')
for i in range(len(cols)):
text = cols[i].find(text=True)
for j in range(room_number):
if i == 0:
locations0.append(text)
elif i == 1:
locations1.append(text)
elif i == 2:
locations2.append(text)
## ステップ7
age_and_height = apartment.find('li', class_='cassetteitem_detail-col3')
age = age_and_height('div')[0].text
height = age_and_height('div')[1].text
for i in range(room_number):
ages.append(age)
heights.append(height)
## ステップ8
table = apartment.find('table')
rows = []
rows.append(table.find_all('tr'))
data = []
for row in rows:
for tr in row:
cols = tr.find_all('td')
if len(cols) != 0:
_floor = cols[2].text
_floor = re.sub('[\r\n\t]', '', _floor)
_rent_cell = cols[3].find('ul').find_all('li')
_rent = _rent_cell[0].find('span').text
_admin = _rent_cell[1].find('span').text
_deposit_cell = cols[4].find('ul').find_all('li')
_deposit = _deposit_cell[0].find('span').text
_reikin = _deposit_cell[1].find('span').text
_others = _deposit + '/' + _reikin
_floor_cell = cols[5].find('ul').find_all('li')
_floor_plan = _floor_cell[0].find('span').text
_area = _floor_cell[1].find('span').text
_detail_url = cols[8].find('a')['href']
_detail_url = 'https://suumo.jp' + _detail_url
text = [_floor, _rent, _admin, _others, _floor_plan, _area, _detail_url]
data.append(text)
for row in data:
floors.append(row[0])
rent.append(row[1])
admin.append(row[2])
others.append(row[3])
floor_plans.append(row[4])
areas.append(row[5])
detail_urls.append(row[6])
time.sleep(10)
## ステップ9
# 各リストをシリーズ化
names = Series(names)
addresses = Series(addresses)
locations0 = Series(locations0)
locations1 = Series(locations1)
locations2 = Series(locations2)
ages = Series(ages)
heights = Series(heights)
floors = Series(floors)
rent = Series(rent)
admin = Series(admin)
others = Series(others)
floor_plans = Series(floor_plans)
areas = Series(areas)
detail_urls = Series(detail_urls)
suumo_df = pd.concat([names, addresses, locations0, locations1, locations2, ages, heights, floors, rent, admin, others, floor_plans, areas, detail_urls], axis=1)
suumo_df.columns=['マンション名','住所','立地1','立地2','立地3','築年数','建物の高さ','階層','賃料料','管理費', '敷/礼/保証/敷引,償却','間取り','専有面積', '詳細URL']
suumo_df.to_csv('suumo_shinyoko.csv', sep = '\t',encoding='utf-16')
ステップ1
BeautifulSoupにGETしたデータを格納してパースしています。
リクエストを送るために利用するurllib3ですが、
以前のurllib2にあったopenurl関数が使えなくなっているので、
以下のようにPoolManager()を呼び出したあと、request('GET', url)としています。
## ステップ1
http = urllib3.PoolManager()
url = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&pc=30&smk=&po1=25&po2=99&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sc=14102&sc=14109&ta=14&cb=0.0&ct=7.5&md=02&md=03&md=04&md=05&et=9999999&mb=0&mt=35&cn=9999999&fw2="
response = http.request('GET', url)
soup = BeautifulSoup(response.data, "html.parser")
ステップ2
こっちは少し強引ですが、ページネーションの最終ページを取得している部分です。
- ページネーションHTMLの文字列を取得
- 1で取得した文字列を[::-1]で反転させる
- re.searchとm.groupにて、ページ数の最大値を取得。同時にreplaceで<>を削除
- 最後に反転した文字列を復元
あまり良いやり方ではないと思っているので、もう少しスマートにできるやり方が見つかり次第修正するつもりです。
## ステップ2
pages = soup.find_all('ol', class_='pagination-parts')
pages = str(pages)[::-1]
m = re.search(r'\<\d\d\d\>',pages)
max_page_number = int(m.group(0).replace("<", "").replace(">", "")[::-1])
urls = []
urls.append(url)
ステップ3
ここでは、取得したい情報があるページのURLリストを作成しています。
調べたところ、URLには以下のような法則性がありました。
1ページ目:ttps://suumo.jp/jj/...&fw=2
2ページ目以降:ttps://suumo.jp/jj/...&fw=2&pn=ページ数
ですので、1ページ目は初期設定に使ったURLをそのまま使用。
2ページ目以降は「1ページ目のURL + &pn=ページ数」としたものを順にリストurlsへ追加しています。
## ステップ3
for i in range(max_page_number - 1):
page_num = str(i + 2)
url_page = url + '&pn=' + page_num
urls.append(url_page)
ステップ3の直後に、空リストの集団が出てきますが、ここに取得したデータをどんどん入れていきます。
このリストを最後にpandasで結合して、一つのcsvにして出力します。
names = [] #マンション名
addresses = [] #住所
locations0 = [] #立地1つ目(最寄駅/徒歩~分)
locations1 = [] #立地2つ目(最寄駅/徒歩~分)
locations2 = [] #立地3つ目(最寄駅/徒歩~分)
ages = [] #築年数
heights = [] #建物高さ
floors = [] #階
rent = [] #賃料
admin = [] #管理費
others = [] #敷/礼/保証/敷引,償却
floor_plans = [] #間取り
areas = [] #専有面積
detail_urls = [] # 詳細URL
ステップ4
ここでは、ステップ3で作成したURLを順に処理するようにしています。
また、apartmentsという、マンションの情報がまとまったブロックを30個分取得しています。
このあと、1ブロックずつデータを取り出す必要があるので、あらかじめマンション単位で分割したデータを用意しています。
↓このブロックが1ページあたり30個分あるので、これを取得
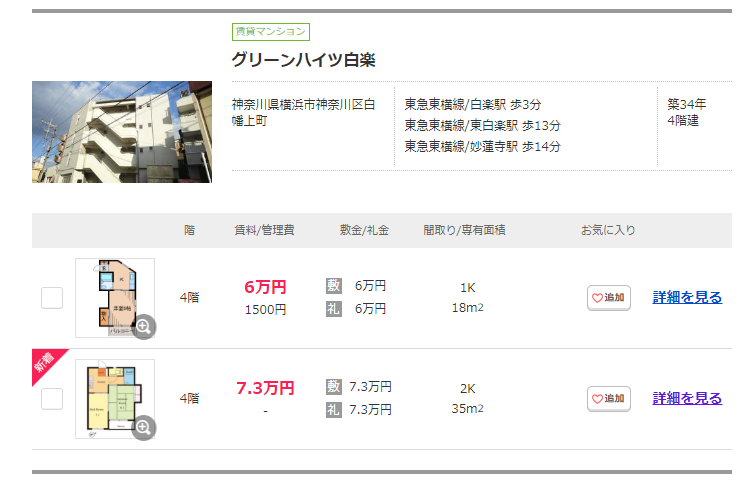
## ステップ4
for url in urls:
response = http.request('GET', url)
soup = BeautifulSoup(response.data, "html.parser")
apartments = soup.find_all('div', class_='cassetteitem')
ステップ5
ここから、マンション1つに対してのデータ取得処理になります。
マンション1つに対して複数の部屋の貸し出し情報が掲載されているため、あからじめroom_number = len(apartment.find_all('tbody'))で部屋の情報を掲載しているテーブルから部屋の数を取得しています。
nameとaddressは、いったんデータを取得したのち、部屋数の分だけデータをコピーして下に挙げたリストに追加しています。
- names = [] #マンション名
- addresses = [] #住所
## ステップ5
for apartment in apartments:
room_number = len(apartment.find_all('tbody'))
name = apartment.find('div', class_='cassetteitem_content-title').text
address = apartment.find('li', class_='cassetteitem_detail-col1').text
for i in range(room_number):
names.append(name)
addresses.append(address)
ステップ6
ステップ6では、立地のデータを取得しています。
- locations0 = [] #立地1つ目(最寄駅/徒歩~分)
- locations1 = [] #立地2つ目(最寄駅/徒歩~分)
- locations2 = [] #立地3つ目(最寄駅/徒歩~分)
今回は、HTMLの構造が下に挙げたようにliの下にdivの子が3つある状態になっています。
<li cassetteitem_detail-col2>
<div>text1</div>
<div>text2</div>
</li>
ですので、まずはfind_all('div')で子要素のdivをすべて取得してcolsに代入します。
その後、for i in range(len(cols))の中にて
cols[i]からcols[0].find(text=True)、cols[1]find(text=True)、cols[2]・・・
といった形で要素を取得して、上で挙げたlocations0~2のリストに追加しています。
## ステップ6
sublocation = apartment.find('li', class_='cassetteitem_detail-col2')
cols = sublocation.find_all('div')
for i in range(len(cols)):
text = cols[i].find(text=True)
for j in range(room_number):
if i == 0:
locations0.append(text)
elif i == 1:
locations1.append(text)
elif i == 2:
locations2.append(text)
ステップ7
以下のリストにデータを追加する個所です。
- ages = [] #築年数
- heights = [] #建物高さ
ここもステップ6で説明したHTMLと同じ構造をしているのですが、すこし違う手法でデータを取得しています。
age_and_height('div')[0].textとありますが、以下のようなイメージになります。
<li cassetteitem_detail-col3>
<!-- age_and_height('div')[0]に該当 -->
<div>text1</div>
<!-- age_and_height('div')[1]に該当 -->
<div>text2</div>
</li>
## ステップ7
age_and_height = apartment.find('li', class_='cassetteitem_detail-col3')
age = age_and_height('div')[0].text
height = age_and_height('div')[1].text
for i in range(room_number):
ages.append(age)
heights.append(height)
ステップ8
ステップ8では、以下のリストを取得しています。
- floors = [] #階
- rent = [] #賃料
- admin = [] #管理費
- others = [] #敷/礼/保証/敷引,償却
- floor_plans = [] #間取り
- areas = [] #専有面積
- detail_urls = [] # 詳細URL
自分はここで結構ハマりました。
tableをパースしてtr、tdタグ以下の構造を取得したまでは良かったのですが、td以降のタグ構造がカラムごとにバラバラだったので。
最終的に、各々のtd以下のliタグをfind_allで取得して、そこから各spanに保持しているテキストを取得することにしました。
ここでのHTMLの構造はこんな感じです。
<ul>
<li><span>text1</span></li>
<li><span>text2</span></li>
</ul>
上で挙げたHTMLの例に対応したpythonのコードはこちら。
# ここでul > li以下のHTMLをリストで取得
_rent_cell = cols[3].find('ul').find_all('li')
# 1つ目のspanが保持するテキストを取得
_rent = _rent_cell[0].find('span').text
# 2つ目のspanが保持するテキストを取得
_admin = _rent_cell[1].find('span').text
## ステップ8
table = apartment.find('table')
rows = []
rows.append(table.find_all('tr'))
data = []
for row in rows:
for tr in row:
cols = tr.find_all('td')
if len(cols) != 0:
_floor = cols[2].text
_floor = re.sub('[\r\n\t]', '', _floor)
_rent_cell = cols[3].find('ul').find_all('li')
_rent = _rent_cell[0].find('span').text
_admin = _rent_cell[1].find('span').text
_deposit_cell = cols[4].find('ul').find_all('li')
_deposit = _deposit_cell[0].find('span').text
_reikin = _deposit_cell[1].find('span').text
_others = _deposit + '/' + _reikin
_floor_cell = cols[5].find('ul').find_all('li')
_floor_plan = _floor_cell[0].find('span').text
_area = _floor_cell[1].find('span').text
_detail_url = cols[8].find('a')['href']
_detail_url = 'https://suumo.jp' + _detail_url
text = [_floor, _rent, _admin, _others, _floor_plan, _area, _detail_url]
data.append(text)
for row in data:
floors.append(row[0])
rent.append(row[1])
admin.append(row[2])
others.append(row[3])
floor_plans.append(row[4])
areas.append(row[5])
detail_urls.append(row[6])
time.sleep(10)
取得したデータは、textにリスト形式で代入し、最後にリストのdataに追加しています。
最後にできるdataの構造は以下のようになります。
[
[_floor1, _rent1, _admin1, _others1, _floor_plan1, _area1, _detail_url1],
[_floor2, _rent2, _admin2, _others2, _floor_plan2, _area2, _detail_url2],
...
]
ステップ9
最後は、いままで取得してきたデータをpandasを使って結合しています。
- Seriesでシリーズ化
- 1のデータをpandas.concatで結合
- suumo_df.columnsで、各カラムにタイトルを追加
- suumo_df.to_csvで、結合したデータをCSV形式にして出力
## ステップ9
# Seriesでシリーズ化
names = Series(names)
addresses = Series(addresses)
locations0 = Series(locations0)
locations1 = Series(locations1)
locations2 = Series(locations2)
ages = Series(ages)
heights = Series(heights)
floors = Series(floors)
rent = Series(rent)
admin = Series(admin)
others = Series(others)
floor_plans = Series(floor_plans)
areas = Series(areas)
detail_urls = Series(detail_urls)
# 1のデータをpandas.concatで結合
suumo_df = pd.concat([names, addresses, locations0, locations1, locations2, ages, heights, floors, rent, admin, others, floor_plans, areas, detail_urls], axis=1)
# 各カラムにタイトルを追加
suumo_df.columns=['マンション名','住所','立地1','立地2','立地3','築年数','建物の高さ','階層','賃料料','管理費', '敷/礼/保証/敷引,償却','間取り','専有面積', '詳細URL']
# 結合したデータをCSV形式にして出力
suumo_df.to_csv('suumo_shinyoko.csv', sep = '\t',encoding='utf-16')
長い説明となりましたが、以上になります!