はじめに
高校卒業後、特にやりたい事もなく職を転々としていました。
ある時アプリやソフトを自分で作れるようになりたい、今までと違った職に就きたいと思いaidemyを受講するに至りました。
本記事の概要
・この記事では犬と猫の識別アプリができるまでの過程を記事にしています。どのような流れで開発できるのかこの記事をご覧していただけると理解できると思います。
・何か作りたいけどどうしたらいいかわからない方や、プログラミングは難しいとイメージし、敬遠してしまっている方がプログラミングに触れるきっかけになればいいと思い記事を書いています。
・この記事ではpythonでの開発になりますのでpython関連以外の言語等は扱いませんのでご了承ください。
アイデミーで学習した内容
・環境構築
・Python入門
・Numpy
・Pandas
・Matplotlib
・データクレンジング
・機械学習概論
・教師あり学習(分類)
・スクレイピング
・ディープラーニング基礎
・CNN
・男女認識
・HTML/CSS
・Flask入門
・MNISTを用いた手書き文字認識アプリ作成
・アプリ作成
・コマンドライン入門
・Git入門
・デプロイ
有名なディープラーニングや機械学習はかなりむずかしく学習において山場でしたがslackやカウンセリングなどを使い乗り切ることができました!
犬と猫識別アプリの開発
アプリをご覧いただきたい方はこちらから!
モデル作成の詳細
ここでは、Python・Deep Learningの実行環境に、Google Colab(GPU)を利用します。
データ収集から、予測まで行いますが、データ収集のプログラムを実行する前に、必ずGPUに設定してください。
GPUに設定せず、CPUの状態で学習させてしまうと多くの時間を費やしてしまうので、注意です。
(※途中GPUなどに変更した場合、その前までにインストールしていたライブラリなどは全て初期化されますので注意です。)
また、手元の環境で動作させる場合、KerasやTensorFlowなどのインストールは必要になります。
このテキストでは解説しておりませんのでご注意ください。
さらに、画像ファイルやその他cnn.h5などの読み込みはお使いのPCの場合、ファイルのパス(PATH)を適切にする必要があります。そのためテキストのままのコードだと動作しない場合がございますのでご注意ください。
モデルの作成時はGoodle Colaboratoryを使用します。
全体の流れ
機械学習ではざっくりと次のような流れを行います!
1 データを収集する
2 セータを整形(前処理)
3 学習データを作成する
4 学習フェーズ(機械学習)
5 推論フェーズ(予測)
Google Colabによる環境構築の準備
1 Google Colabの初期設定
2 学習させるデータ集め
3 学習データの作成
4 学習フェーズ(機械学習)
5 推論フェーズ(予測)
ここでは、Google Colabの初期設定としてGPUの設定をします。
Googleアカウントでログインして後に、下記リンクにアクセスしてください。
「最近のノートブック」の画面が表示されますので、画面の左下から「PYTHON3の新しいノートブック」を選びクリックしてください。
または、左上メニューの『Python3 のノートブックを新規作成』でも同じです。
・左上メニューの『Python3 のノートブックを新規作成』の場合
Colaboratoryの画面が表示されましたか?
それでは、黒丸の三角の実行ボタンの右横にある薄い青色のテキストエディタがありますので、
そこにプログラムを記述しましょう。
1 print("hello Python")
始めは少し時間がかかりますが、少し待つと結果が表示されます。
ちなみに作成したノートブックは、自動的にGoogle Driveに保存されます。
GPUに設定する
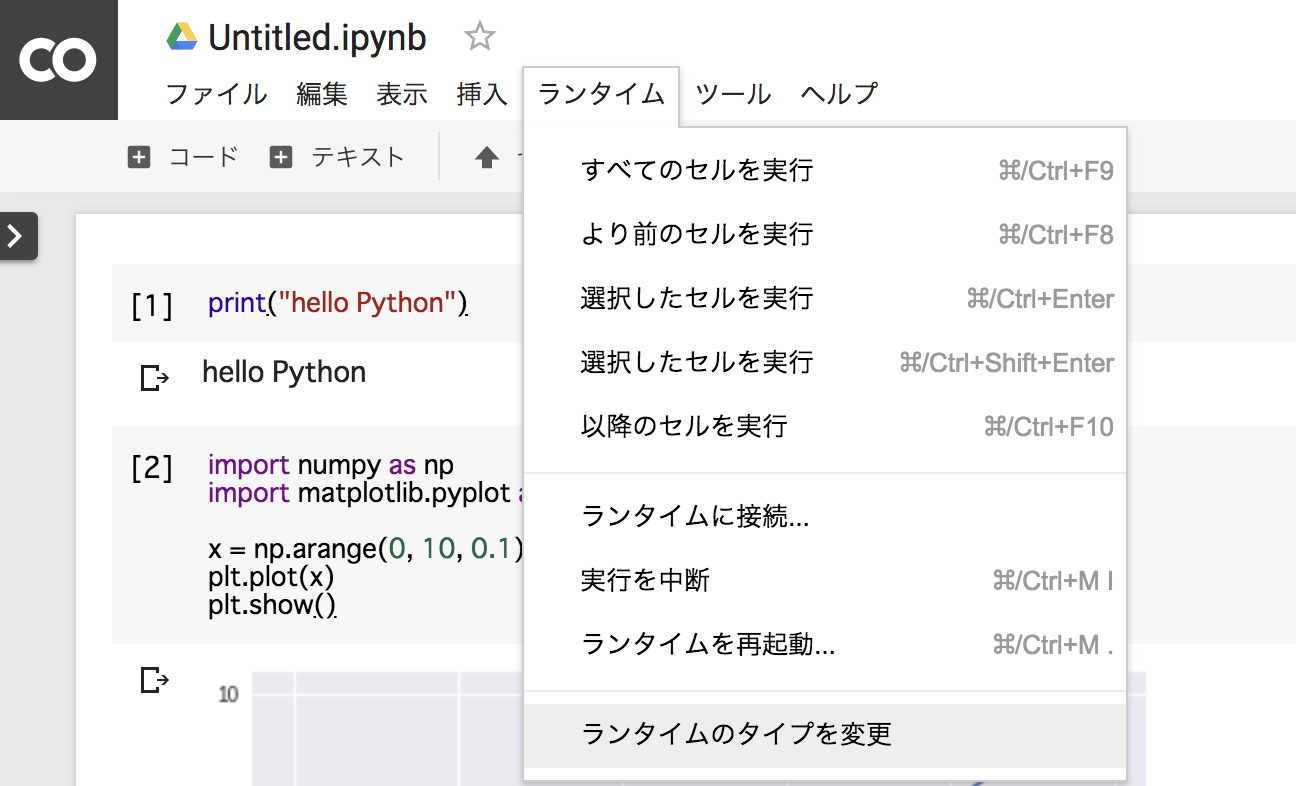
ノートブック作成時には、GPUではないため、下記操作にてGPUを使えるようにします。
上部メニューの ランタイム > ランタイムのタイプを変更を選択。
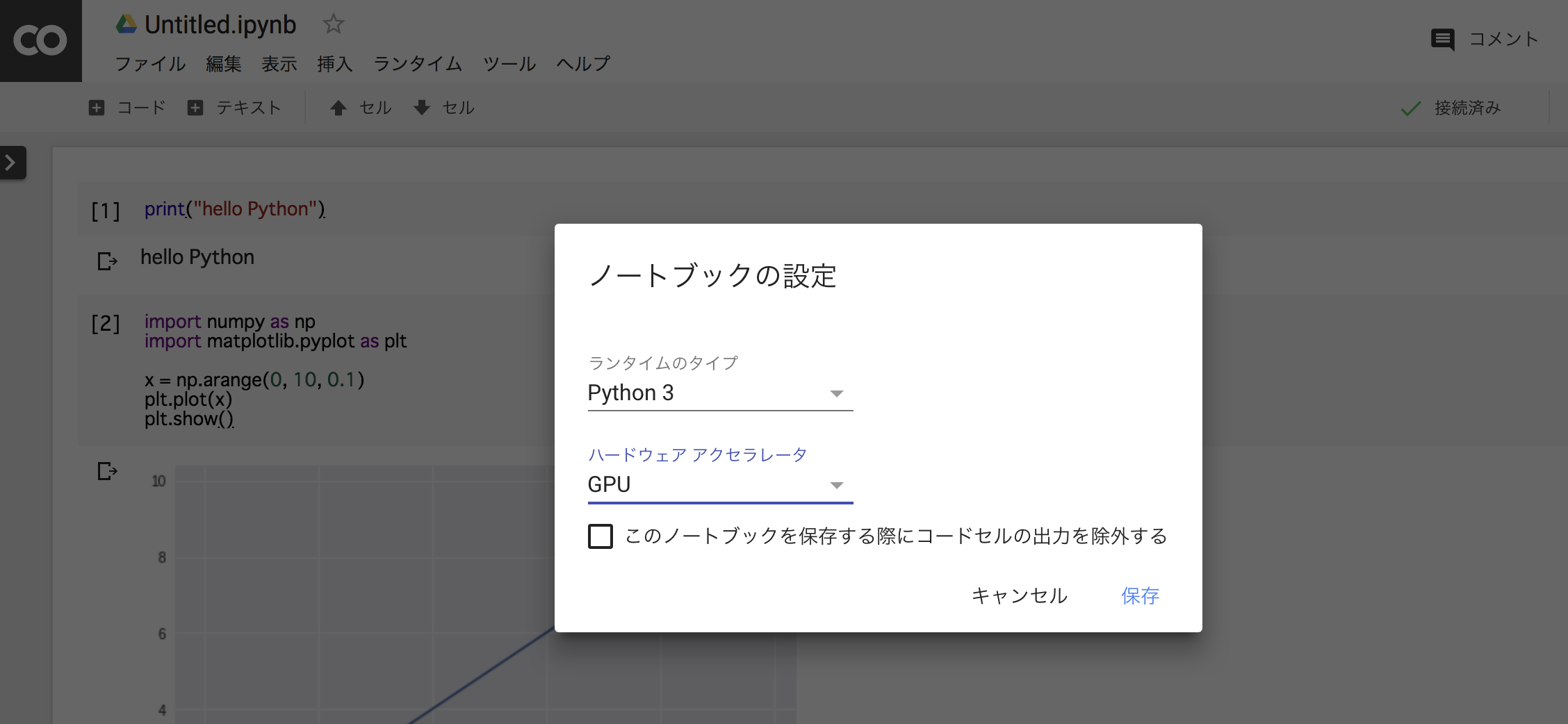
ハードウェアアクセラレータ を None から GPU に変更して保存します。
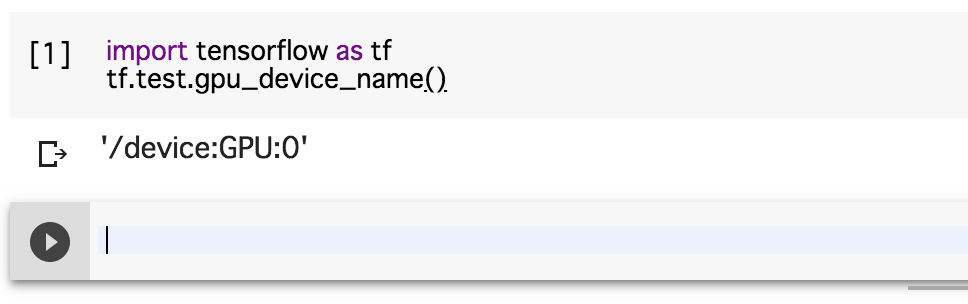
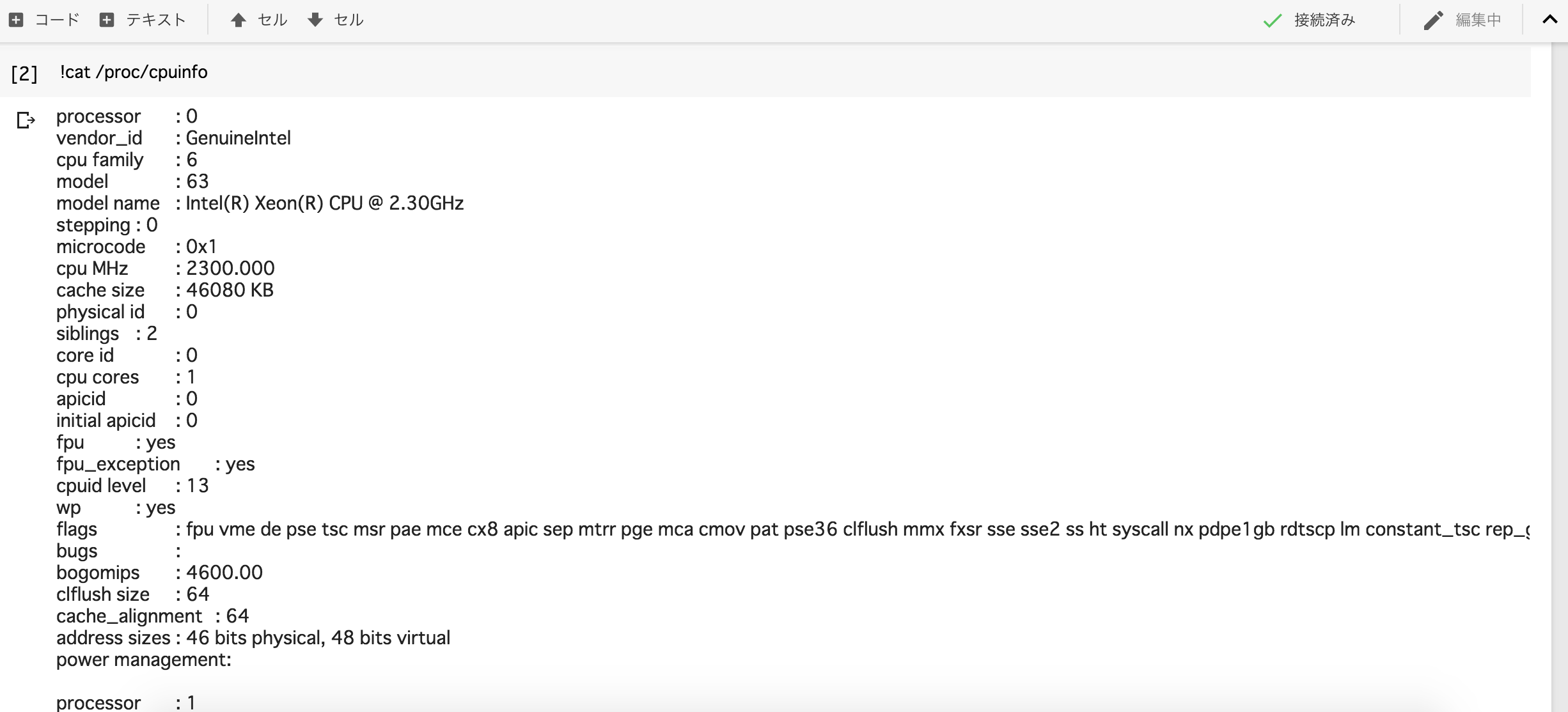
下記を実行し__'/device:GPU:0'__と出力されていればGPUが利用できます。
また、
!cat /proc/cpuinfo
及び
!cat /proc/meminfo
を実行すると、Colaboratoryのマシンスペックを調べることが出来ます!
犬と猫の画像を集める
画像をネットから集めるプログラムをインストールするために、Pythonの画像収集ライブラリをGoogle Colabにインストールします。
Google Colabのセルで下記コマンドを入力&実行すると、インストールが開始されます。
!pip install icrawler
次に画像収集を行うプログラムを記述しましょう。
下記を実行することによりcatフォルダが作成され100枚のが収集できます。
from icrawler.builtin import BingImageCrawler
# 猫の画像を100枚取得
crawler = BingImageCrawler(storage={"root_dir": "cat"})
crawler.crawl(keyword="猫", max_num=100)
そして先ほどと同じように犬の画像を100枚収集しましょう!
先ほどと同じように実行。
from icrawler.builtin import BingImageCrawler
# 犬の画像を100枚取得
crawler = BingImageCrawler(storage={"root_dir": "dog"})
crawler.crawl(keyword="犬", max_num=100)
これで犬と猫の画像をダウンロードすることができました!
それでは、そのうち1枚の猫の画像を表示してみましょう。
# 猫の画像を表示
from IPython.display import Image,display_jpeg
display_jpeg(Image("./cat/000001.jpg"))

データの整形と学習データの作成
画像がダウンロードできたので、次に入力データ(画像)の前処理とデータの分割を行なっていきます。
from PIL import Image
import os, glob
import numpy as np
from PIL import ImageFile
# IOError: image file is truncated (0 bytes not processed)回避のため
ImageFile.LOAD_TRUNCATED_IMAGES = True
classes = ["dog", "cat"]
num_classes = len(classes)
image_size = 64
num_testdata = 25
X_train = []
X_test = []
y_train = []
y_test = []
for index, classlabel in enumerate(classes):
photos_dir = "./" + classlabel
files = glob.glob(photos_dir + "/*.jpg")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
if i < num_testdata:
X_test.append(data)
y_test.append(index)
else:
# angleに代入される値
# 画像を5度ずつ回転
for angle in range(-20, 20, 5):
img_r = image.rotate(angle)
data = np.asarray(img_r)
X_train.append(data)
y_train.append(index)
# FLIP_LEFT_RIGHT は 左右反転
img_trains = img_r.transpose(Image.FLIP_LEFT_RIGHT)
data = np.asarray(img_trains)
X_train.append(data)
y_train.append(index)
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
xy = (X_train, X_test, y_train, y_test)
np.save("./dog_cat.npy", xy)```
numpyのsave()によって、dog_cat.npyというファイル名で、データセットが作成出来ました。
1行目のPILはPython Imaging Librarという画像処理のためのライブラリになります。
**学習**
ここでは認識モデルを作るためのメインプログラムになります。
実行することで機械学習を行います。
(機械学習では学習と推論の2つの工程があり、ここでは学習にあたります。)
<font color="Red">**Goodle Colaboratoryのランタイム設定でノーマルからGPUに変更しましょう、1分かからない程で学習が終わります!**</font>
```python
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.optimizers import RMSprop
from keras.utils import np_utils
import keras
import numpy as np
classes = ["dog", "cat"]
num_classes = len(classes)
image_size = 64
# データを読み込む関数
def load_data():
X_train, X_test, y_train, y_test = np.load("./dog_cat.npy", allow_pickle=True)
# 入力データの各画素値を0-1の範囲で正規化(学習コストを下げるため)
X_train = X_train.astype("float") / 255
X_test = X_test.astype("float") / 255
# to_categorical()にてラベルをone hot vector化
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
return X_train, y_train, X_test, y_test
# モデルを学習する関数
def train(X, y, X_test, y_test):
model = Sequential()
# Xは(1200, 64, 64, 3)
# X.shape[1:]とすることで、(64, 64, 3)となり、入力にすることが可能です。
model.add(Conv2D(32,(3,3), padding='same',input_shape=X.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.1))
model.add(Conv2D(64,(3,3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.45))
model.add(Dense(2))
model.add(Activation('softmax'))
# https://keras.io/ja/optimizers/
# 今回は、最適化アルゴリズムにRMSpropを利用
opt = RMSprop(lr=0.00005, decay=1e-6)
# https://keras.io/ja/models/sequential/
model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['accuracy'])
model.fit(X, y, batch_size=28, epochs=40)
# HDF5ファイルにKerasのモデルを保存
model.save('./cnn.h5')
return model
# メイン関数データの読み込みとモデルの学習を行います。
def main():
# データの読み込み
X_train, y_train, X_test, y_test = load_data()
# モデルの学習
model = train(X_train, y_train, X_test, y_test)
main()
上記プログラムはグーグルコラボラトリーのGPU環境の場合数分で処理が終わりcnn.h5がcolab上に生成されます。
推論
予測させたい犬や猫の画像をダウンロード&アップロードしましょう。
次のプログラムを貼り付けて、実行しダウンロードした画像をアップロードしましょう。
ダウンロードしてきた画像をアップロードします!
ファイルタブのアップロードから下記画像をアップロードします。
今回は、ダウンロードした犬の画像をdog1.jpgというファイル名でアップロードし、変数testpic に代入します。
画像はこちらからダウンロード可能です。
import keras
import sys, os
import numpy as np
from keras.models import load_model
imsize = (64, 64)
testpic = "./dog1.jpg"
keras_param = "./cnn.h5"
def load_image(path):
img = Image.open(path)
img = img.convert('RGB')
# 学習時に、(64, 64, 3)で学習したので、画像の縦・横は今回 変数imsizeの(64, 64)にリサイズします。
img = img.resize(imsize)
# 画像データをnumpy配列の形式に変更
img = np.asarray(img)
img = img / 255.0
return img
model = load_model(keras_param)
img = load_image(testpic)
prd = model.predict(np.array([img]))
print(prd) # 精度の表示
prelabel = np.argmax(prd, axis=1)
if prelabel == 0:
print(">>> 犬")
elif prelabel == 1:
print(">>> 猫")
先ほどの犬の画像を上記のコードで予測させてみると...
>>> 犬
正しく認識しました!
念のために猫の画像でも検証してみましょう!
犬の画像と同様の方法で変数testpicを「./dog1.jpg」から「./cat1.jpg」に変更し、先ほどのコードを再度実行します 。
猫の画像は、インターネットからダウンロードしてアップロードしてください!
自作したアプリでもしっかりと動作するのか試してみます!
こちらはHTMLとCSSで作成した自作アプリのUIです!

まずファイルを選択して先ほどダウンロードした犬の画像(dog1)をアップロード用に選択します!
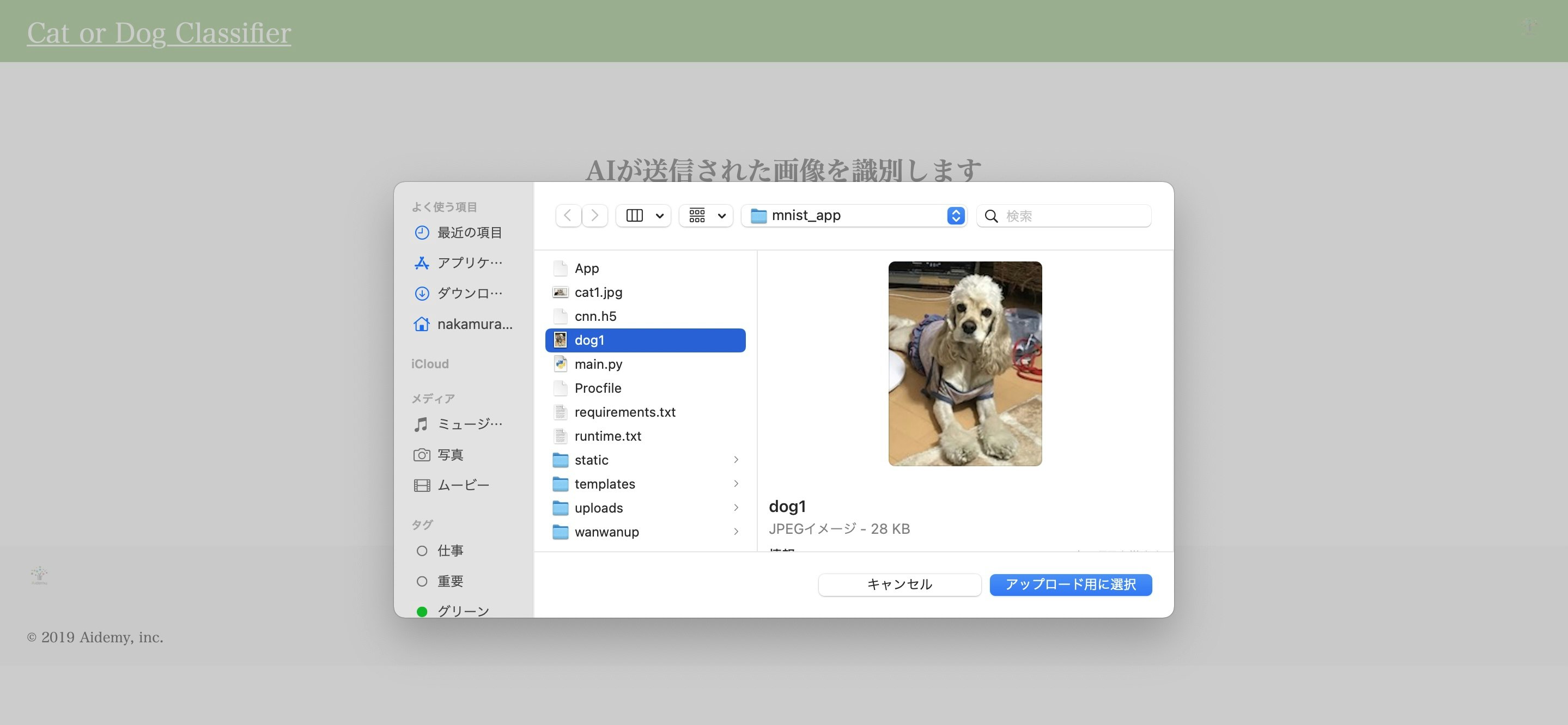
そしてsubmit!をクリックすると...

見事識別できていますね!
今回はデータ収集の都合上で100枚以下のデータ数で学習を行なったため精度はあまり高くありません(ディープラーニングでは通常数千から数万のデータ数で学習を行うのが一般的なため)より精度を向上させる場合は画像収集時に引数max_numを増やすことで学習に使うデータ数を増やし再学習させましょう!
アプリを作成して
今回はこちらのサイトを参考にしました!参考文献
今回は犬と猫の識別でしたが学習した内容を活かして他のアプリも作成してみたいという意欲が湧いてきました。
見た目の部分ではまだまだですしプログラミングにはこれといった正解はないのでステップバイステップでまずは取り組んでみるということを大事にしていきたいと思います。
最後に
Aidemyを受講して独学では学べない深い内容の教材がありもちろん挫折しそうになりましたがslackでの質問でしたりカウンセリングで理解できなかった部分がすぐに解決した事と、受講が全てe-ラーニングだったので適度に息抜きできる環境であったのが最後まで続けられたのだと思います。
最後までご覧いただきありがとうございました!