Note: この記事の情報は 2026年4月時点のものです。
出典: この記事は @Ronycoder がXに投稿した約15分の動画をもとにまとめたものです。登壇者はAnthropicのBarry Zhang氏。「Agents at Work」イベントでの講演内容です。
はじめに
AnthropicのBarry Zhang氏はEric氏とともに、ブログ記事「Building Effective Agents」を執筆した人物だ。この講演ではそのブログ記事の核心にある3つのアイデアをさらに深掘りし、エージェント開発における実践的な知見を共有している。

3つの原則:
- すべてにエージェントを使うな
- シンプルに保て
- エージェントの視点で考えろ
AIシステムの進化
まずBarry氏は、AIシステムがどう発展してきたかを整理した。
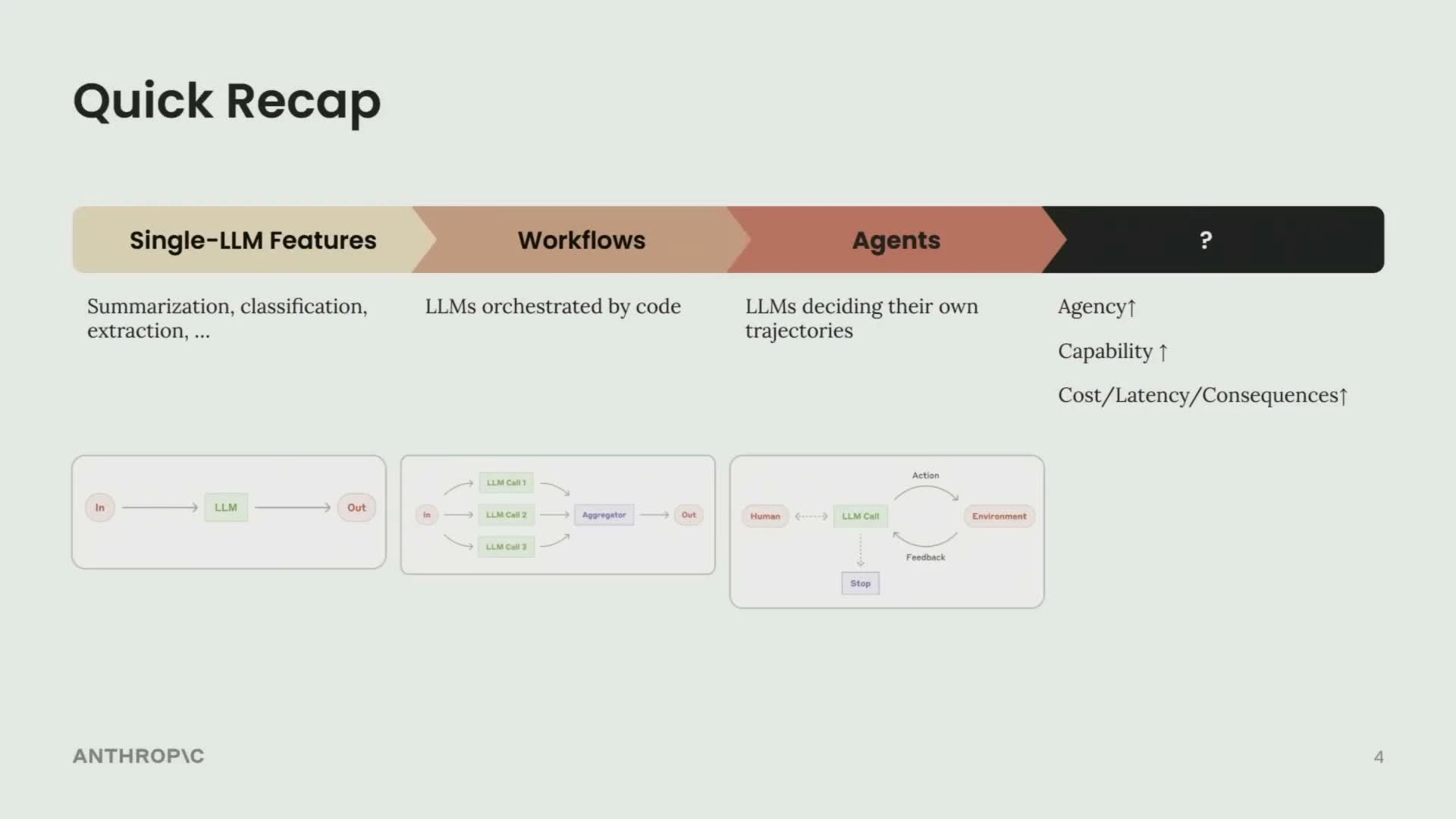
| フェーズ | 概要 |
|---|---|
| Single-LLM Features | 要約・分類・抽出など、1回のLLM呼び出しで完結するシンプルな機能 |
| Workflows | 複数のLLM呼び出しをコードで制御する事前定義フロー。コストと精度のトレードオフを管理できる |
| Agents | LLM自身が軌跡を決定し、環境からのフィードバックをもとにほぼ自律的に動作するシステム |
| 次のフェーズ(?) | より汎用的な単体エージェント、またはマルチエージェント協調 — どちらに向かうかはまだ未知数 |
方向性は明確だ。エージェントにより多くの自律性を与えるほど、有用性と能力は上がる。しかし同時に、コスト・レイテンシ・エラーの影響も大きくなる。この緊張関係こそが、以降の3原則の根拠になっている。
原則1: すべてにエージェントを使うな
エージェントは「複雑で価値の高いタスクをスケールさせるための手段」であり、あらゆるユースケースへのドロップイン置き換えではない。ではいつ使うべきか? Barry氏は4項目のチェックリストを示した。

チェック1: タスクの複雑さ
エージェントが真価を発揮するのは、曖昧で複雑な問題空間だ。デシジョンツリーを自分で書き出せるなら、その通りに明示的に実装してしまった方がよい。コスト効率が高く、制御もしやすい。
チェック2: タスクの価値
エージェントはトークンを大量に消費する。「1タスク10セント以内に収めたい」という制約があるなら、使えるのは30〜50トークン相当に過ぎない。そういったケースでは、最頻出シナリオをワークフローで処理するだけで大半の価値を回収できる。
逆に「何トークン使ってもいいからとにかくタスクを完遂したい」と思うなら、エージェントの出番だ。
チェック3: 重要機能のボトルネック確認
エージェントを走らせる前に、軌跡上の重大なボトルネックがないか確認する。コーディングエージェントなら、コードを書けるか・デバッグできるか・エラーから回復できるかが問われる。ボトルネックがあっても致命的ではないが、コストとレイテンシが倍増する。その場合はスコープを絞って出直す。
チェック4: エラーのコストと発見しやすさ
エラーが高リスクで発見しにくい場合、エージェントに自律的な行動を委ねるのは難しい。読み取り専用アクセスやHuman-in-the-Loopで軽減はできるが、それはスケーラビリティとのトレードオフになる。
なぜコーディングは良いユースケースなのか
Barry氏はコーディングエージェントを例に、このチェックリストを適用してみせた。
- 複雑さ: 設計ドキュメントからPRまでは、明らかに曖昧で複雑
- 価値: 開発者にとってコードの価値は言うまでもない
- 能力: モデルはすでにコーディングの多くの工程が得意
- 検証のしやすさ: ユニットテストとCIで出力を機械的に検証できる
この「出力が自動検証可能」という性質が、コーディングエージェントの成功例が多い理由の一つだとBarry氏は指摘する。
原則2: シンプルに保て
「エージェントとは、ツールをループで使うモデルのことだ」
Barry氏はエージェントをこの一文で定義し、構成要素を3つに絞り込んだ。

env = Environment()
tools = Tools(env)
system_prompt = "Goals, constraints, and how to act"
while True:
action = llm.run(system_prompt + env.state)
env.state = tools.run(action)
| コンポーネント | 役割 |
|---|---|
| Environment | エージェントが動作するシステム(ファイルシステム、ブラウザ、APIなど) |
| Tools | エージェントがアクションを取り、フィードバックを得るためのインターフェース |
| System Prompt | エージェントのゴール・制約・振る舞いの定義 |
コーディングエージェント・サーチエージェント・Computer Useエージェント——見た目は全く異なるが、Anthropic社内ではこれらがほぼ同じコードのバックボーンで実装されているという。Environmentに依存する部分と、ToolsとSystem Promptの設計だけが変わる。
複雑さは反復速度を殺す
Barry氏が「シンプルに」と強調するのは経験則による。序盤の余計な複雑さは反復速度を大幅に落とす。まずこの3つのコンポーネントを作り、動作が安定してから最適化に移る。
具体的な最適化の例:
- コーディング/Computer Use: ディレクトリをキャッシュしてコスト削減
- サーチ(多数ツール): ツール呼び出しを並列化してレイテンシ削減
- 全般: エージェントの進捗をユーザーに見せてトラストを獲得
原則3: エージェントの視点で考えろ
「Put yourself in their shoes context window(エージェントの靴ではなくコンテキストウィンドウに入れ)」
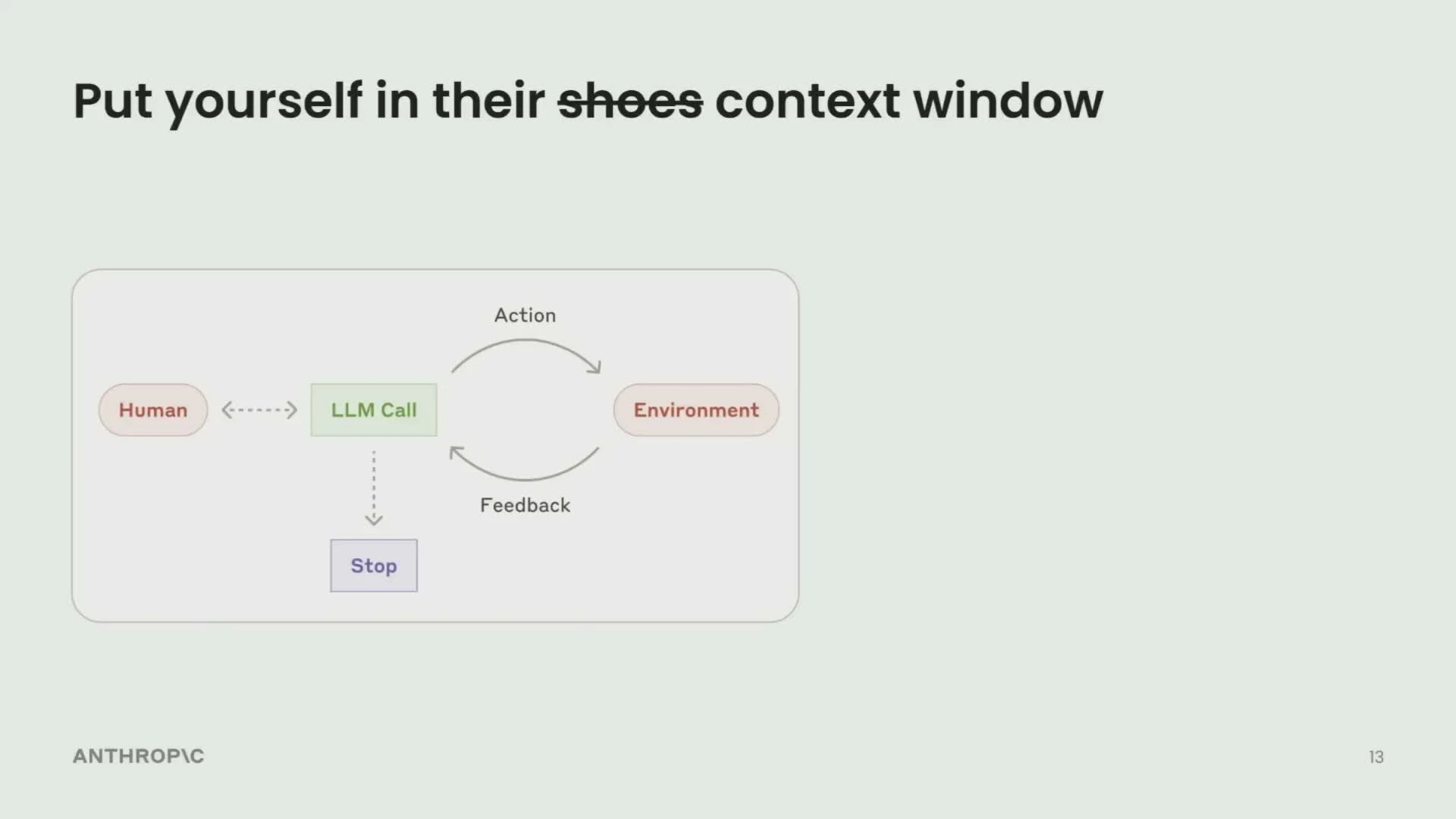
モデルは一見、非常に高度な推論をしているように見える。だが各ステップで実際にやっていることは、10〜20Kトークンの限られたコンテキストに対して推論を走らせているだけだ。モデルが世界について知っていることは、すべてそのコンテキストウィンドウに収まっている。
Barry氏はエージェントの視点を体感する実験として、Computer Useの例を挙げた。
「あなたは今、Computer Useエージェントです」
渡されるのは静止画スクリーンショットと、ひどく説明不足なテキスト説明だけ。ツールを使うことでしか環境に影響を与えられない。クリックを試みても、推論とツール実行が走っている間は何も見えない。それは3〜5秒間、目を閉じたままコンピュータを操作するに等しい。
目を開けたとき、新しいスクリーンショットが渡される。あなたのクリックが成功したのか、誤ってコンピュータをシャットダウンしたのかも分からない。
この実験をやると、エージェントが本当に必要としているものが自然と見えてくるとBarry氏は言う。
- スクリーン解像度(どこをクリックすべきかを知るために)
- 推奨アクションと制約(不必要な探索を防ぐガードレール)
ClaudeにClaudeを評価させる
実用的なテクニックとして、エージェントの軌跡全体をClaudeに投げて尋ねるという方法が紹介された。
「なぜここでこの判断をしたと思うか? より良い判断をするために何を提供できるか?」
System Promptをそのままモデルに渡して「どこか曖昧な点があるか? 従えるか?」と確認することも有効だ。自分自身の理解を代替するものではないが、エージェントの視点に近づくための強力な補助線になる。
今後の3つのオープンクエスチョン
講演の最後にBarry氏は、AIエンジニアとして常に頭の中にある未解決問題を3つ挙げた。
1. エージェントへの予算意識の付与
ワークフローと異なり、エージェントのコストとレイテンシは把握しにくい。時間・金額・トークン数で「予算」を定義・適用する仕組みが整えば、本番投入できるユースケースが大幅に広がる。
2. セルフエボルビングツール
すでにモデルを使ってツールの説明文を改善することはできている。これを一般化して、エージェント自身が各ユースケースに必要なツールを設計・改善するメタツールに発展させる——そうすればエージェントの汎用性は飛躍的に高まる。
3. マルチエージェント協調
Barry氏は「2026年末までに、本番でのマルチエージェント協調事例が大幅に増える」と確信している。並列化・関心の分離・サブエージェントによるメインエージェントのコンテキストウィンドウ保護——いずれも魅力的だ。ただし、エージェント同士の通信をどう設計するかは大きな課題として残る。現在の同期型ユーザー・アシスタントターンから、非同期通信やエージェント間の相互認識へとどう拡張するかが次の問いだ。
まとめ
| 原則 | ポイント |
|---|---|
| すべてにエージェントを使うな | 複雑さ・価値・能力・エラーコストの4項目でユースケースを評価する |
| シンプルに保て | Environment・Tools・System Promptの3コンポーネントだけで作り始める |
| エージェントの視点で考えろ | コンテキストウィンドウに入り込み、エージェントが見ている世界を体感する |
エージェントを正しく機能させるのは、まだ簡単ではない。しかしその難しさの多くは、エージェントが何を見ていて何を知らないかを開発者が理解できていないことから来ている。この3つの原則は、その理解を深めるための実用的な出発点だ。
全文書き起こし
以下は動画の音声書き起こしを日本語訳したものです。一部意訳・補足を含みます。
[0:00〜5:00] Part 1: エージェントの進化と「使うな」の判断基準
Barry です。今日は「効果的なエージェントをどう作るか」についてお話しします。約2ヶ月前、Eric と私は「Building Effective Agents」というブログ記事を書きました。そこではエージェントとは何か・何でないかについての見解と、実践から得た学びを共有しています。今日はそのブログの核心にある3つのアイデアをさらに深掘りし、最後に個人的な考察もお伝えします。
3つのアイデアはこちらです。第一に、すべてにエージェントを使うな。第二に、シンプルに保て。第三に、エージェントのように考えろ。
まず、ここに至るまでの振り返りから始めましょう。私たちのほとんどは、最初は非常にシンプルな機能を作っていました。要約・分類・抽出——2〜3年前は魔法のように感じたものが、今や当たり前になっています。そしてより高度になるにつれ、1回のモデル呼び出しでは不十分になってきました。そこで複数のモデル呼び出しを事前定義のフローで組み合わせるようになりました。これがコストと精度のトレードオフを管理する手段となり、「ワークフロー」と呼ばれるようになりました。これがエージェントシステムの始まりだと私たちは考えています。
今やモデルはさらに高性能になり、本番でドメイン固有のエージェントが増えてきています。ワークフローと違い、エージェントは自分自身の軌跡を決定し、環境フィードバックをもとにほぼ自律的に動作します。これが今日のテーマです。次のフェーズが何になるかはまだ早すぎて断言できませんが、単体エージェントがより汎用的になるか、マルチエージェントの協調・委任が進むか、そのどちらかでしょう。いずれにせよ、エージェントに与える自律性が増すほど、有用性と能力も上がる。しかし同時に、コスト・レイテンシ・エラーの影響も増大します。
それが最初のポイント——「すべてにエージェントを使うな」——につながります。なぜか? エージェントは複雑で価値の高いタスクをスケールさせるためのものであり、あらゆるユースケースへのドロップイン置き換えではないからです。
ワークフローについてブログで多く語ったのは、本当に好きだからです。今日の価値を届ける具体的な手段として優秀です。ではいつエージェントを作るべきか? チェックリストを紹介します。
まず考えるのはタスクの複雑さです。エージェントは曖昧な問題空間で真価を発揮します。デシジョンツリーを自分で書き出せるなら、それをそのまま実装して各ノードを最適化した方が、コスト効率も制御性も高いです。
次はタスクの価値です。エージェントはトークンをたくさん消費します。1タスクの予算が10セントなら、30〜50トークン程度しか使えません。そういう場合は、ワークフローで最頻出シナリオをカバーするだけで大半の価値を得られます。逆に「トークンをいくら使っても構わないからタスクを完遂したい」という場合は、ぜひ講演後に声をかけてください——そのユースケース、私たちのセールスチームが大好きです(笑)。
次は重要な機能のボトルネック確認です。エージェントの軌跡上に重大なボトルネックがないか確認します。コーディングエージェントなら、コードを書けるか・デバッグできるか・エラーから回復できるかが問われます。ボトルネックがあっても致命的ではありませんが、コストとレイテンシが倍増します。その場合はスコープを絞って再挑戦します。
最後に、エラーのコストと発見しやすさです。エラーが高リスクで発見しにくい場合、エージェントに自律的な行動を委ねるのは難しい。読み取り専用アクセスやHuman-in-the-Loopで軽減できますが、スケーラビリティとのトレードオフになります。
このチェックリストを実際に当てはめてみましょう。なぜコーディングが優れたユースケースなのか? 設計ドキュメントからPRまでは明らかに曖昧で複雑なタスクです。良いコードは非常に価値が高い。多くの方がすでにコーディングにClaudeを使っており、コーディングワークフローの多くの工程が得意だと知っています。
[5:00〜10:00] Part 2: シンプルに保つ — 3コンポーネントの設計
そして最後に、コーディングはユニットテストとCIによって出力が機械的に検証できるという素晴らしい性質があります。これが今、コーディングエージェントの成功例が多い理由の一つでしょう。
良いユースケースを見つけたら、第二のアイデア——できる限りシンプルに保つ——に移ります。私たちにとってエージェントとは、ツールをループで使うモデルのことです。このフレームでは3つのコンポーネントがエージェントを定義します。
まず環境。エージェントが動作するシステムです。次にツール群。エージェントがアクションを取り、フィードバックを得るためのインターフェースです。そしてシステムプロンプト。エージェントがこの環境でどう動くべきかのゴール・制約・理想的な振る舞いを定義します。モデルがループで呼び出される——それがエージェントです。
複雑さを省くことは、反復速度を守るために必要だと痛い目を見て学びました。この3つの基本コンポーネントだけに集中することが、最も高いROIをもたらします。最適化はあとからでも十分です。
私たちが自社または顧客向けに作った3つのエージェントのユースケースを具体例として挙げると、プロダクトの見た目もスコープも機能も全く異なります。しかしバックボーンはほぼ同じ、実際にはほぼ同じコードを共有しています。
環境はユースケースに依存するため、実質的な設計上の決断は2つだけです——エージェントに提供するツールの種類と、指示するプロンプトの内容です。
ちなみにツールについてもっと知りたい方には、私の友人 Mahesh が今朝 MCP(モデルコンテキストプロトコル)のワークショップを開催しています。ぜひ参加してみてください。
話を戻します。3つのコンポーネントを作ったら、そこから最適化をたくさんできます。コーディング・Computer Useではディレクトリをキャッシュしてコスト削減。多数のツールを使うサーチでは並列化してレイテンシ削減。そしてほぼすべてのケースで、エージェントの進捗をユーザーに見せてトラストを獲得することが重要です。それだけです。シンプルに、まず3コンポーネントを作り、動作が安定してから最適化に入ってください。
[10:00〜14:46] Part 3: エージェントの視点で考える & 未来への問い
最後のアイデアです——エージェントのように考えること。多くのビルダー(私自身も含めて)が自分の視点でエージェントを開発して、エージェントがミスをすると混乱します。直感に反するように見えるからです。そのため私たちは常に、エージェントのコンテキストウィンドウに入り込んで考えることを勧めています。
エージェントは非常に高度な振る舞いをしているように見えます。しかし各ステップで実際にやっていることは、10〜20Kトークンという非常に限られたコンテキストに対して推論を走らせているだけです。モデルが現在の世界の状態について知っていることは、すべてそのトークンに収まっています。自分をその制限の中に置いて、コンテキストが十分かつ整合的かを確認することが非常に有効です。それによってエージェントが世界をどう見ているかを理解でき、私たちの認識とエージェントの認識のギャップを埋められます。
ちょっと想像してみてください——今あなたはComputer Useエージェントです。渡されるのは静止画のスクリーンショットと、非常に貧弱なテキスト説明だけ。ツールを使うことでしか環境に影響を与えられません。クリックを試みても、推論とツール実行が走っている間は何も見えない——それは3〜5秒間、目を閉じたままコンピュータを操作するようなものです。目を開けると新しいスクリーンショットが渡されます。あなたのクリックが成功したのか、誤ってシャットダウンしたのかも分かりません。これは大きな信頼の跳躍であり、サイクルが再び始まります。
ぜひ一度、エージェントの視点でタスクを最初から最後までやってみることをお勧めします。不思議で、少し不快な体験です。でもその少し不快な体験を経ると、エージェントが実際に何を必要としていたかが明確に見えてきます。
スクリーン解像度を知ることがどれほど重要か、どこをクリックすべきかが分かります。推奨アクションと制約があると、不必要な探索を防ぐガードレールになることも分かります。
これらは一例に過ぎません。自分のエージェントユースケースでこの実験をして、エージェントに提供すべきコンテキストを探ってみてください。
幸い、私たちが作っているシステムは私たちの言語を話します。だから ClaudeにClaudeを理解させることができます。システムプロンプトを投げて「曖昧な点はあるか? 従えるか?」と確認できます。ツールの説明を投げて「このツールの使い方が分かるか? パラメータは多すぎないか少なすぎないか?」とも確認できます。
私たちが頻繁にやるのは、エージェントの軌跡全体をClaudeに投げて「なぜここでこの判断をしたと思うか? より良い判断をするために何を提供できるか?」と尋ねることです。これは自分自身の理解を代替するものではありませんが、エージェントが世界をどう見ているかに、はるかに近い視点を得られます。繰り返します——エージェントのように考えながら反復してください。
実践的な話をたくさんしてきましたが、最後に個人的な考察を一枚スライドで話させてください。これからどう進化するか、そしてAIエンジニアとして共に答えを出すべきオープンクエスチョンです。常に頭の中にある上位3つを挙げます。
まず、エージェントに予算意識を持たせることが必要だと思います。ワークフローと異なり、エージェントのコストとレイテンシは把握しにくい。これを解決できれば、本番投入に必要なコントロールが得られ、多くのユースケースが開かれます。
次は「セルフエボルビングツール」というコンセプトです。すでにモデルを使ってツールの説明文を改善できています。これを一般化して、エージェント自身が各ユースケースに必要なツールを設計・改善するメタツールへ発展させることができるはずです。エージェントの汎用性が飛躍的に高まるでしょう。
最後に——もはや過激な意見でもないと思いますが——私は「2026年末までに本番でのマルチエージェント協調が大幅に増える」と確信しています。並列化・関心の分離・サブエージェントによるメインエージェントのコンテキストウィンドウ保護——魅力的な利点がたくさんあります。ただし、エージェント同士の通信をどう設計するかは大きな問いです。現在の同期型ユーザー・アシスタントターンから、非同期通信やエージェント間の相互認識へどう拡張するか——これがマルチエージェントの未来を探る上での重要なオープンクエスチョンです。
今日忘れてしまっても、この3つだけ覚えて帰ってください。すべてにエージェントを使うな。良いユースケースを見つけたら、できる限りシンプルに保て。そして反復する中で、エージェントのように考え、彼らの視点を得て、仕事を助けてあげてください。