はじめに
本稿はこちらの参考書の3.7節、Robust Principal Component Analysis (RPCA) の備忘。
概要
$\ell_2$-最適化や最小二乗法は外れ値や破損、ノイズに影響されやすいことが知られている。主成分分析も同様に外れ値に関して脆くなってしまう。この敏感さを改善するために、CandesらはロバストなPCAを開発した。ここではその具体的な手法について紹介およびデモコードを作成してみる。
Principal Component Analysis
先ず、通常のPCAについて再喝しておく。
PCA(Principal Component Analysis)は、データ行列$\boldsymbol{X}\in\mathbb{R}^{m\times n}$を低次元の空間に射影することで、データの主な構造を捉える手法である。次のようにデータ行列を近似する低ランク行列$\boldsymbol{L}$を求める。
\begin{align}
\min_{\boldsymbol{L}}{
\|
\boldsymbol{X}-\boldsymbol{L}
\|_F^2
}
\end{align}
ここで、$|\cdot|_F$はフロベニウスノルムである。そして、これを満足する最適な$\boldsymbol{L}$は$\boldsymbol{X}$の特異値分解から得られる、というのがEckert-Youngの定理であった。参考はこちら。
Rubust Principal Component Analysis (RPCA)
RPCAの目的はデータ行列$\boldsymbol{X}$を低ランク行列$\boldsymbol{L}$と外れ値やノイズを含む正方行列$\boldsymbol{S}$に分解することである。
\begin{align}
\boldsymbol{X}=\boldsymbol{L}+\boldsymbol{S}
\end{align}
この行列$\boldsymbol{L}$の主成分は$\boldsymbol{S}$に含まれる外れ値やノイズに対して頑健となる。例えば、顔認識などであれば$\boldsymbol{L}$に固有顔、$\boldsymbol{S}$に影、遮蔽などを含ませる、といった要領である。
数学的に、以下を満足する$\boldsymbol{L}$と$\boldsymbol{S}$を見つければ良い。
\begin{align}
\begin{cases}
{\rm 目的関数:}\quad&
\mathop{\rm min~rank}
\limits_{\boldsymbol{L},\boldsymbol{S}}
\left(
\boldsymbol{L}
\right)
+\|\boldsymbol{S}\|_0 \\
{\rm 制約条件:}\quad&
\boldsymbol{L}+\boldsymbol{S}=\boldsymbol{X}
\end{cases}
\end{align}
上記目的関数において、${\rm rank}(\boldsymbol{L})$の項と$|\boldsymbol{S}|_0$の項はどちらも非凸なので、最適化問題としては難しい問題となる。
非凸最適化問題の緩和
以前圧縮センシングについて記述した記事(こちら)では、特定の制約下で$\ell_0$-最適化を$\ell_1$-最適化へと緩和できることを紹介した。今回もこれと同様に統計的に高い確率で解が$\ell_0$-最適化となるように問題を緩和する。
\begin{align}
\begin{cases}
{\rm 目的関数:}\quad&
\mathop{\rm min}
\limits_{\boldsymbol{L},\boldsymbol{S}} \|\boldsymbol{L}\|_*
+
\lambda\|\boldsymbol{S}\|_1 \\
{\rm 制約条件:}\quad&
\boldsymbol{L}+\boldsymbol{S}=\boldsymbol{X}
\end{cases}
\end{align}
$|\cdot|_*$は核ノルム(nuclear norm)であり、以下のような定義で与えられる。行列$\boldsymbol{A}$に関して、その特異値を$\lbrace \sigma_i\rbrace_{i=1}^{\min{\left(m,n\right)}}$と置いて、
\begin{align}
\|\boldsymbol{A}\|_*=
\sum_{i=i}^{\min{\left(m,n\right)}}
\sigma_i
\end{align}
このように、全ての特異値の総和として計算される。
ランク最小化は非凸であり、最適化問題として扱い難い。ランクが低い行列では、非ゼロの特異値が少なく、それらの合計である核ノルムも比較的小さくなるので、核ノルム最小化がランク最小化問題の凸緩和として用いられる。
式$(4)$の解は、$\boldsymbol{L}$と$\boldsymbol{S}$が以下の条件を満たすとき、$\lambda=1/\sqrt{\max{(n,m)}}$ならば、高い確率で式$(3)$の解に収束する。
(a) $\boldsymbol{L}$ がスパースでない
(b) $\boldsymbol{S}$が低ランク行列でない。(この行列$\boldsymbol{S}$は低次元な列空間を持たないために、ランダムに分布していると想定される。)
拡張ラグランジュ乗数法による求解
主成分追跡
式$(4)$は主成分追跡(PCP: Principal Component Pursuit)として知られる制約付き最適化問題であり、本節では簡潔に記述するために以下のように記述し改める。
\begin{align}
\begin{cases}
{\rm 目的関数:}\quad&
\mathop{\rm min}
\limits_{\boldsymbol{L},\boldsymbol{S}}
f(\boldsymbol{L},\boldsymbol{S})
=
\mathop{\rm min}
\limits_{\boldsymbol{L},\boldsymbol{S}}
\left(
\|\boldsymbol{L}\|_*
+
\lambda\|\boldsymbol{S}\|_1
\right)
\\
{\rm 制約条件:}\quad&
\boldsymbol{C}(\boldsymbol{L},\boldsymbol{S})=
\boldsymbol{X}-\boldsymbol{L}-\boldsymbol{S}=\boldsymbol{O}
\end{cases}
\end{align}
ペナルティ関数法
一般的な制約付き最適化問題に言えることだが、無制約最適化問題として扱うことが出来る。
例えば、ペナルティ関数法などがあるが、これの$k$ステップ計算した式は次のようになる。
\begin{align}
\min_{\boldsymbol{L},\boldsymbol{S}}{\Phi_k(\boldsymbol{L},\boldsymbol{S})}
=f(\boldsymbol{L},\boldsymbol{S})
+\mu_k\sum_i
\boldsymbol{r}_i^2
\end{align}
ここで、$\lbrace\boldsymbol{r}_i\rbrace$は行列$\boldsymbol{C}$の行ベクトルを示す。
ペナルティ関数法は、係数$\mu_k$を増加させてそのイテレーションでの無制約問題を解き、その解を次のイテレーションの初期値として用いる。が、これは数値的に不安定となる。($\mu$が制限なく増大するため。)
拡張ラグランジュ乗数法
主成分追跡は拡張ラグランジュ乗数法(ALM: Augumented Lagrange Multiplier)を用いて解かれる。
これは、通常のラグランジュ未定乗数法にペナルティ関数法のペナルティ項に類似した項を追加したもので、係数$\mu\rightarrow\infty$とする必要がなく、数値的不安定性を回避でき理論的な収束へ繋がる。
\begin{align}
\min_{\boldsymbol{L},\boldsymbol{S}}
\mathcal{\mathcal{L}}_A
\left(
\boldsymbol{L},
\boldsymbol{S},
\boldsymbol{\upsilon}
\right)
=f(\boldsymbol{L},\boldsymbol{S})
+\frac{\mu}{2}
\sum_i\boldsymbol{r}_i^2
+\sum_i\upsilon_i\boldsymbol{r}_i
\end{align}
或いは、ラグランジュ乗数$\lbrace\upsilon_i\rbrace$を制約式全体ではなく、ラグランジュ乗数行列$\boldsymbol{Y}=\lbrace\upsilon_{i,j}\rbrace$を用いて各要素個別に拡張すれば、エルミート内積を用いて以下のように記述される。
\begin{align}
\min_{\boldsymbol{L},\boldsymbol{S}}
\mathcal{\mathcal{L}}_A
\left(
\boldsymbol{L},
\boldsymbol{S},
\boldsymbol{Y}
\right)
=&f(\boldsymbol{L},\boldsymbol{S})
+\frac{\mu}{2}
\langle
\boldsymbol{C},\boldsymbol{C}
\rangle
+
\langle
\boldsymbol{Y},\boldsymbol{C}
\rangle \\
=&\|\boldsymbol{L}\|_*
+\lambda\|\boldsymbol{S}\|_1
+\frac{\mu}{2}
\|\boldsymbol{C}\|_F^2
+
\mathrm{Tr}
\left(
\boldsymbol{Y}^\dagger
\boldsymbol{C}
\right)
\end{align}
各イテレーション後に以下のようにラグランジュ乗数行列$\boldsymbol{Y}$を更新する。
\begin{align}
\boldsymbol{Y}_{k+1}
\leftarrow
\boldsymbol{Y}_k+\mu\boldsymbol{C}_k
\end{align}
ペナルティ係数$\mu$については、ペナルティ法同様に$\mu\leftarrow\alpha\mu,\ \alpha>1$とする方法もあるが、計算安定性や収束性、計算の単純化のために今回は固定としておく。
交互乗数法
交互乗数法(ADMM: Alternating Directions Method of Multipliers)は各変数の部分更新を行うことで最適解を探索するALMの派生である。
今回の問題に特化して言えば、先ず、スパース行列$\boldsymbol{S}$とラグランジュ乗数行列$\boldsymbol{Y}$を固定して、低ランク行列$\boldsymbol{L}$に関して部分最適化を行う。
\begin{align}
\hat{\boldsymbol{L}}
\leftarrow
\mathop{\rm arg~min}
\limits_{\boldsymbol{L}}
{\mathcal{L}}_A
\left(
\boldsymbol{L},
\boldsymbol{S},
\boldsymbol{Y}
\right)
\end{align}
次に、この$\hat{\boldsymbol{L}}$を用いて$\boldsymbol{S}$の更新を行う。
\begin{align}
\hat{\boldsymbol{S}}
\leftarrow
\mathop{\rm arg~min}
\limits_{\boldsymbol{S}}
{\mathcal{L}}_A
\left(
\hat{\boldsymbol{L}},
\boldsymbol{S},
\boldsymbol{Y}
\right)
\end{align}
これらの$\hat{\boldsymbol{L}}$と$\hat{\boldsymbol{S}}$を使って、$\boldsymbol{Y}$を更新する。
\begin{align}
\boldsymbol{Y}
\leftarrow
\boldsymbol{Y}+\mu\boldsymbol{C}(\hat{\boldsymbol{L}}, \hat{\boldsymbol{S}})
\end{align}
デモコード
先ずは、通常のPCAに綺麗な学習データだけで低ランク行列を求めてみる。使うデータはExtended Yale Face Database B。
先ずはライブラリのインポートから。
# Import libraries
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.image import imread
import scipy.io
from tqdm import tqdm
plt.rcParams['figure.figsize'] = [7, 7]
plt.rcParams.update({'font.size': 18})
続いてデータの読み込み
# Read data
contents = scipy.io.loadmat('../../data/allFaces.mat')
X = contents['faces']
nfaces = contents['nfaces'].reshape(-1)
m = int(contents['m'][0, 0])
n = int(contents['n'][0, 0])
PCAの実装
ライブラリを使っても良いのだが、ここではスクラッチする。
class PCA:
def __init__(self, X):
self.X = X
self.col_ave = np.mean(self.X, axis=1)
self._SVD()
def _SVD(self):
X = self.X - np.tile(self.col_ave, (self.X.shape[1], 1)).T
self.U, self.S, self.Vh = np.linalg.svd(X, full_matrices=False)
def transform(self, data, rank=2):
Xt = data - self.col_ave
Xh = self.U[:, :rank] @ self.U[:, :rank].T @ Xt
return Xh + self.col_ave
オリジナルのデータに対して、固有顔を計算し、適当なサンプル画像の低ランク表示をすると次のようになる。
後述のRPCAで得られた低ランク行列の階数が1218だったため、ここでも同じ階数を指定して計算してみる。
pca = PCA(X)
sample = X[:,np.sum(nfaces[:37])] # 38人目の最初の画像
Xh = pca.transform(sample, rank=1218) # RPCAと比較

RPCAの実装
続いて、RPCAを計算するクラスを同様に作成する。
式$(12),(13)$の部分最適化問題は、ラグランジュ関数$\mathcal{L}_A$の偏微分を計算し、それがゼロとなるようにする。
\begin{align}
&&
\mathcal{\mathcal{L}}_A
\left(
\boldsymbol{L},
\boldsymbol{S},
\boldsymbol{Y}
\right)
&=
\|\boldsymbol{L}\|_*
+\lambda\|\boldsymbol{S}\|_1
+\frac{\mu}{2}
\|\boldsymbol{C}\|_F^2
+
\mathrm{Tr}
\left(
\boldsymbol{Y}^\dagger
\boldsymbol{C}
\right) \\
&\Rightarrow&
\frac{
\partial
\mathcal{L}_A
}{
\partial
\boldsymbol{L}
}
&=
\frac{
\partial
\|\boldsymbol{L}\|_*
}{
\partial
\boldsymbol{L}
}
+
\frac{
\partial
\boldsymbol{L}
}{
\partial
\boldsymbol{C}
}
\left(
\mu\boldsymbol{C}
+\boldsymbol{Y}^\dagger
\right)=\boldsymbol{O}
\end{align}
ここで、核ノルム$|\boldsymbol{L}|_* $の$\boldsymbol{L}$に関する偏微分は、特異値分解$\boldsymbol{L}=\boldsymbol{U\Sigma V}^*$を用いて、
\begin{align}
\frac{
\partial
\|\boldsymbol{L}\|_*
}{
\partial
\boldsymbol{L}
}
=\boldsymbol{UV}^*
\end{align}
したがって、式$(16)$は
\begin{align}
&&
\frac{
\partial
\mathcal{L}_A
}{
\partial
\boldsymbol{L}
}
&=
\boldsymbol{UV}^*
-\mu\boldsymbol{C}
-\boldsymbol{Y}^\dagger \\
&&&=
\boldsymbol{UV}^*
-\mu
\left(
\boldsymbol{X}
-\boldsymbol{L}
-\boldsymbol{S}
\right)
-\boldsymbol{Y}^\dagger \\
&\Rightarrow&
\hat{\boldsymbol{L}}
&=
-\frac{1}{\mu}
\boldsymbol{UV}^*
+\boldsymbol{X}
-\boldsymbol{S}
+\frac{1}{\mu}
\boldsymbol{Y}^\dagger \\
&&&={\rm Shrinkage}
\left(
\boldsymbol{X}
-\boldsymbol{S}
+\frac{1}{\mu}
\boldsymbol{Y}^\dagger,~
\frac{1}{\mu}
\right)
\end{align}
ここで${\rm Shrinkage}$はソフトしきい値処理(Soft Thresholding)という操作であり、行列の各要素に対してしきい値処理を行う。
同様にして、$\mathcal{L}_A$を部分最小化するような$\boldsymbol{S}$は
\begin{align}
\hat{\boldsymbol{S}}=
\min_{\boldsymbol{S}}{\mathcal{L}_A}
&=
\min_{\boldsymbol{S}}{
\left(
f(\boldsymbol{L},\boldsymbol{S})
+\frac{\mu}{2}
\langle
\boldsymbol{C},\boldsymbol{C}
\rangle
+
\langle
\boldsymbol{Y},\boldsymbol{C}
\rangle
\right)
} \\
&=
\min_{\boldsymbol{S}}{
\left(
\lambda\|\boldsymbol{S}\|_1
+\frac{\mu}{2}
\|
\boldsymbol{X}
-\hat{\boldsymbol{L}}
-\boldsymbol{S}
+\frac{1}{\mu}
\boldsymbol{Y}^\dagger
\|_F^2
-\frac{1}{2\mu}
\|\boldsymbol{Y}\|_F^2
\right)
} \\
&=
\min_{\boldsymbol{S}}{
\left(
\lambda\|\boldsymbol{S}\|_1
+\frac{\mu}{2}
\|
\boldsymbol{S}
-\boldsymbol{X}
+\hat{\boldsymbol{L}}
-\frac{1}{\mu}
\boldsymbol{Y}^\dagger
\|_F^2
\right)
} \\
&={\rm Shrinkage}
\left(
\boldsymbol{X}
-\hat{\boldsymbol{L}}
+\frac{1}{\mu}
\boldsymbol{Y}^\dagger,~
\frac{1}{\mu}
\right)
\end{align}
これに基づいてRPCAクラスを作成する。
class RPCA:
def __init__(self, X, threshold=10**-7):
self.X = X
self.m = self.X.shape[0]
self.n = self.X.shape[1]
self.mu = self.m * self.n / (4 * np.sum(np.abs(X.reshape(-1))))
self._lambda = 1 / np.sqrt(np.maximum(self.m, self.n))
self.threshold = threshold * np.linalg.norm(X)
print(f'threshold = {self.threshold:.2f}')
self.loss_list = list()
self._ALM(X)
def _ALM(self, X, max_iter=1000):
S = np.zeros_like(X)
Y = np.zeros_like(X)
L = np.zeros_like(X)
with tqdm(total=max_iter) as pbar:
for _ in range(max_iter):
if self.is_saturated(X, L, S, pbar):
break
L = self._SVT(X - S + (1 / self.mu) * Y, 1 / self.mu)
S = self.shrink(X - L + (1 / self.mu) * Y, self._lambda / self.mu)
Y = Y + self.mu * (X - L - S)
self.L = L
self.S = S
def is_saturated(self, X, L, S, pbar):
loss = np.linalg.norm(X - L - S)
self.loss_list.append(loss)
pbar.set_postfix(loss=loss)
pbar.update(1)
return loss <= self.threshold
def shrink(self, X, tau):
Y = np.abs(X) - tau
return np.sign(X) * np.maximum(Y, np.zeros_like(Y))
def _SVT(self, X, tau):
U, S, Vh = np.linalg.svd(X, full_matrices=False)
return U @ np.diag(self.shrink(S, tau)) @ Vh
これも同様に全オリジナルデータに対して実行し、PCAと同じ人物の行列分解結果を描画する。ただし、この処理には5時間、約850epochを要したので、実行する際はこれに留意。
因みに制約条件の誤差$|\boldsymbol{X}-\boldsymbol{L}-\boldsymbol{S}|_F^2$の推移は次のようになった。

低ランク行列$\boldsymbol{L}$の結果は以下の通り。ちなみに、今回得られた行列$\boldsymbol{L}$の階数は1,218であった。

通常のPCAで得られた結果と見比べてみると、オリジナルデータに対してはRPCAの方がぼやけて見える。
これは、PCAが主成分に基づく低ランク行列を得る(=特異値が急激に減少し、データ行列をよく説明する上位の特異値を採用)一方で、RPCAはノイズや外れ値をスパース行列$\boldsymbol{S}$に分離するため、主成分が平滑化されてぼやけて見える。鮮明さと頑健さの間にトレードオフがあることが観察できる。
次に、スパース行列$\boldsymbol{S}$を描画

顔の中でも、エッジや細部が目立つ目や鼻などが外れ値として判定されていることがわかる。
スパイクノイズを加えた場合
RPCAの強みが観察できるケースとして、各画像の一部にランダムに高い値を持つ「スパイクノイズ」を加えたデータセットを考える。
# Add sparse noise to the data
X_sparse_noise = np.copy(X)
num_pixels_to_corrupt = int(0.2 * X_sparse_noise.size) # Corrupt 20% of pixels
corrupt_indices = np.unravel_index(np.random.choice(X_sparse_noise.size, num_pixels_to_corrupt, replace=False), X_sparse_noise.shape)
X_sparse_noise[corrupt_indices] = 255
実際に出力してみるとこのような感じ。
plt.imshow(np.reshape(X_sparse_noise[:, np.sum(nfaces[:37])], (m, n)).T, cmap="gray")
plt.axis("off")
plt.show()

画像全体のランダムに選択された20%(厳密にはデータ行列$\boldsymbol{X}$の20%だが)のピクセルが白に置換されていることがわかる。このように汚れや破損した画像データは現実世界で多くの分野で発生する。
では、先ほど同様にPCAから実行する。
pca = PCA(X_sparse_noise)
sample = X[:, np.sum(nfaces[:37])]
Xh = pca.transform(sample, rank=1246)
plt.imshow(np.reshape(Xh, (m, n)).T, cmap="gray")
plt.axis("off")
plt.show()

スパイクノイズが加わっているため、先ほどのオリジナルケースとはことなり、全体がぼんやりした画像となっている。
次にRPCA
rpca = RPCA(X_sparse_noise)
np.save('L.npy', rpca.L)
np.save('S.npy', rpca.S)
plt.imshow(np.reshape(rpca.L[:,np.sum(nfaces[:37])], (m, n)).T, cmap="gray")
plt.axis("off")
plt.show()
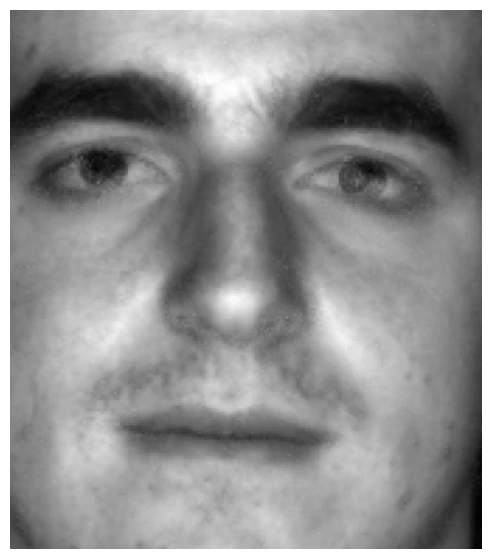
このように上記PCAと同じ行列ランクであるが、画像の鮮度が保たれており、ノイズに対する頑健性が観察できる。行列$\boldsymbol{L}$の階数は1246であった。
スパース行列$\boldsymbol{S}$は次の通り。

因みに、今回の誤差$|\boldsymbol{X}-\boldsymbol{L}-\boldsymbol{S}|_F^2$の推移は以下の通り。
損失が一度上がっているのが目を引くが、これは交互乗数法によるものだと勝手に解釈している。(片方の行列を更新したときに一時的にもう片方の行列との整合性が崩れ、損失が上がった。)

おわりに
拡張ラグラジアン乗数法が反復法でかつ、各epochで毎度特異値分解を実施(ADMMの一環)しているので、高速化技術も適当なタイミングで調査してみたい。