はじめに
AWS DMSの継続レプリケーションするタスクのインスタンスのスペックの調整をするのに、コンソール上でポチポチするのが面倒になったので、必要に応じてレプリケーションインスタンスを自動的にスケールして、より高い負荷 (スケールアップ) を処理し、負荷が低いときにコストを削減 (スケールダウン) する方法を模索しました。
やりたいこと
対象のレプリケーションインスタンスのCPU使用率が閾値を超えた際は、スケールアップし、Eメール通知をもってトリガーを確認できるようにします。閾値を下回った際は、スケールダウンし、Eメール通知を行う。
セットアップ
構成図
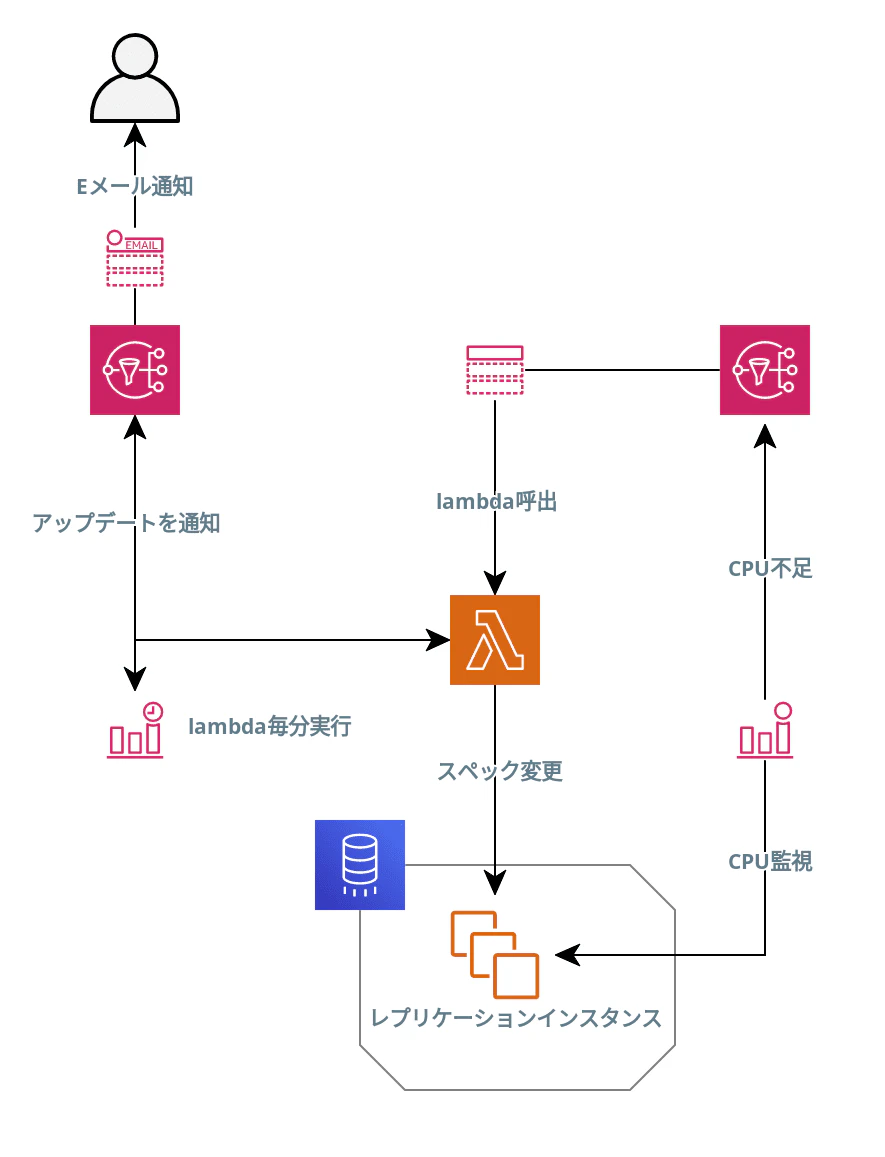
必要リソース
- インスタンスタイプの変更通知(SNS)
- Lambda関数を呼び出す通知(SNS)
- CPU監視用のアラーム(Cloudwatch)
- IAMロールの作成(IAM)
- Autoスケールスクリプト(Lambda)
- 毎分Lambdaを呼び出すスケジューリング(Cloudwatch)
インスタンスタイプの変更通知
レプリケーションインスタンスのスケールアップした際に、Eメール通知します。
(トピック名: Replication_Instance_Update)
- SNSトピックを作成
- サブスクリプションでEメールでの通知設定
Lambda関数を呼び出す通知
CPU使用率が閾値を跨いだ際に、Lambda関数を呼び出します。
トピックの作成(トピック名: dmsautoscaler)
- SNSトピックを作成
- サブスクリプションでlambda関数を設定
CPU監視用のアラーム
レプリケーションインスタンスのCPU使用率を監視するようにアラームを作成します。
CPU使用率の閾値は、下記の参照ください。
CPU使用率が閾値より超えた場合
(アラーム名:dms_cpu_high)
CPU 使用率 CPUUtilization が次の場合は常に : >= 80: 5 データポイント 期間 = 1 MinuteStatistic = 平均
CPU使用率が閾値より下回った場合
(アラーム名:dms_cpu_low)
CPU 使用率 CPUUtilization が次の場合は常に: <= 40: 5 データポイント 期間 = 1 MinuteStatistic = 平均
IAMロールの作成
Lambda関数に付与するロールを作成します。
(ロール名:dms-autoscaler)
権限一覧
- DMS レプリケーションインスタンスを変更する
- CloudWatch Logs に入力する
- CloudWatch イベントルールを作成して使用する
- SNS トピックに公開する
※下記のポリシーを使用
lambda_policy.json
Lambda関数の作成
レプリケーションインスタンスのCPU使用率が閾値を跨いだ時に、Cloudwatchアラームにより、Lambdaに登録されるSNS通知がトリガーとなり、この関数で、レプリケーションインスタンスのスケールがされます。
自動スケーリングの設定は、S3バケットにjsonファイルを格納し、jsonファイルを介して管理しています。
(lambda関数:AutoscaleDMSReplicationInstance)
(S3バケット名:dms-autoscaleinstances)
自動スケーリング設定ファイル
instance_types.json
スケーリングlambda関数
dms.py