統計的因果探索の手法である LiNGAM、そのバリエーションの1つである Direct LiNGAMについて勉強したので、その根本的な原理についてメモしておきます。
主に以下の2冊がネタ元です。
因果関係を統計的にモデル化する手法には、SEM(構想方程式モデリング)、傾向スコア、ベイジアンネットワークなどがありますが、LiNGAMが目的とするのは因果関係の真の方向を探ることです。
つまり、xがyに影響しているのか、YがXに影響しているのか、お互いに影響はないのか、を明らかにしたいということです。
Direct LiNGAM は因果の方向を探るのに回帰分析と独立性の評価を用います。
「正しい因果的順序で回帰分析を行うと、説明変数と残差は独立になります。一方、正しくない因果的順序で回帰分析を行うと残差は従属になります。したがって、独立になる場合の説明変数が因果的順序の最初の変数であると推定できます。」(『統計的因果探索』p113)
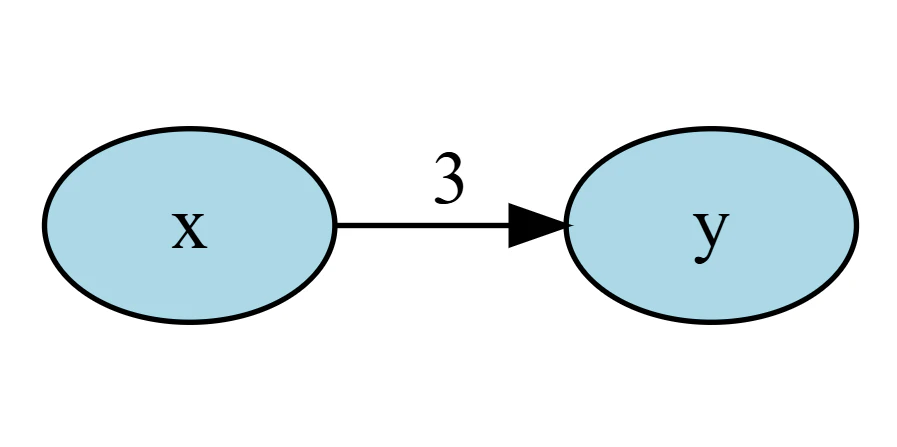
R言語で簡単なデモデータを使って試してみましょう。xがyに影響する以下のモデルを真の因果関係とします。
y = x \times 3 + e
まずは必要なパッケージを呼びだしておきましょう。
library(conflicted)
library(tidyverse)
library(DiagrammeR) # パス図描画
library(patchwork) # グラフ配置
xとeはそれぞれ独立した一様分布の乱数とします。
#R言語
n <- 1000 #サンプルサイズ
set.seed(1)
x <- runif(n)
set.seed(2)
e <- runif(n)
y <- x*3 + e
因果ダイアグラム(パス図)で描くとこんな感じです。
# パス図
DiagrammeR::grViz("
digraph {
graph[layout = dot, rankdir = LR]
x, y [style='filled', fillcolor = 'lightblue']
x -> y [label = 3]
}
")
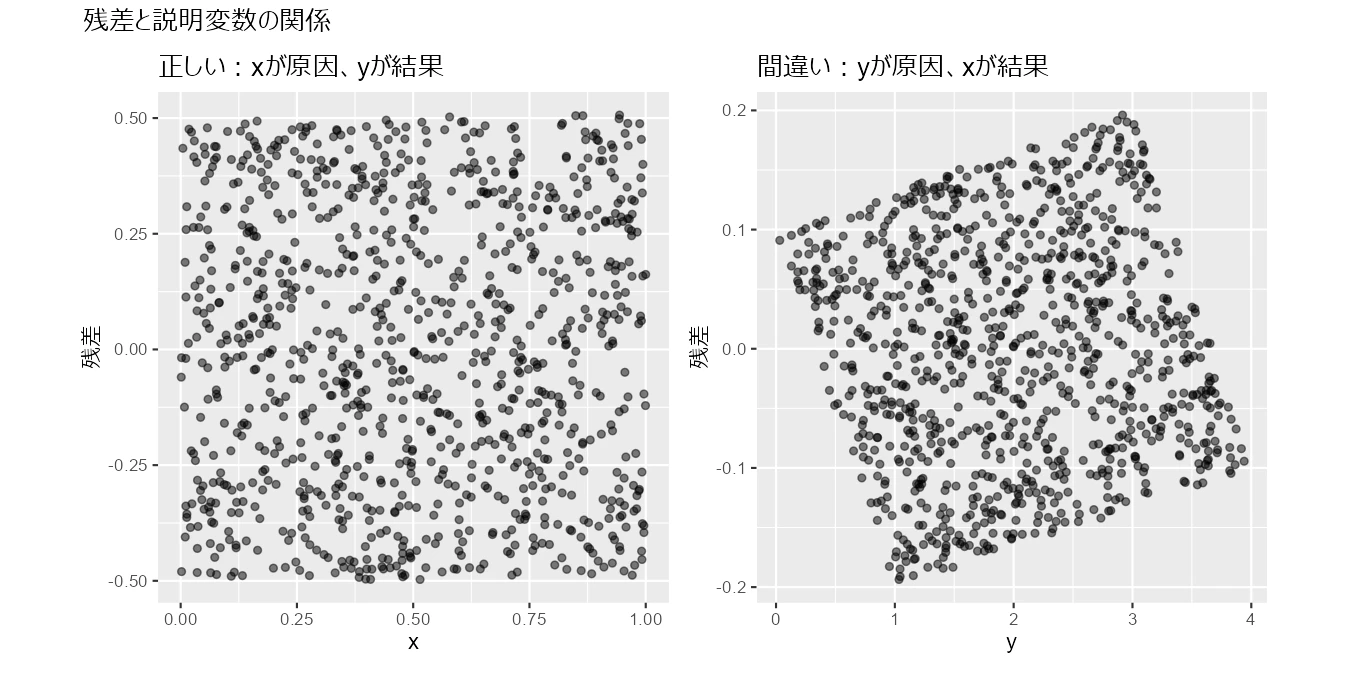
このデータを使って、正しい順序と間違った順序、それぞれで回帰分析を行います。
# 正しいモデル
true_model <- lm(y ~ x)
# 間違ったモデル
false_model <- lm(x ~ y)
それぞれの説明変数と残差の関係を可視化して確認します。
df <- data.frame(
x = x,
y = y,
true_model = true_model$residuals,
false_model = false_model$residuals
)
p_true <- df |>
ggplot(aes(x = x, y = true_model)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "正しい:xが原因、yが結果", x = "x", y = "残差")
p_false <- df |>
ggplot(aes(x = y, y = false_model)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "間違い:yが原因、xが結果", x = "x", y = "残差")
p_true + p_false + plot_annotation(title = "残差と説明変数の関係")
一目瞭然、正しい因果順序のモデルでは説明変数と残差がどちらも一様分布で独立した状態ですが、間違った因果順序のモデルでは説明変数と残差が一様分布ではなく偏りが生まれています。
この説明変数と残差の関係から、因果的順序の方向を推定するわけです。
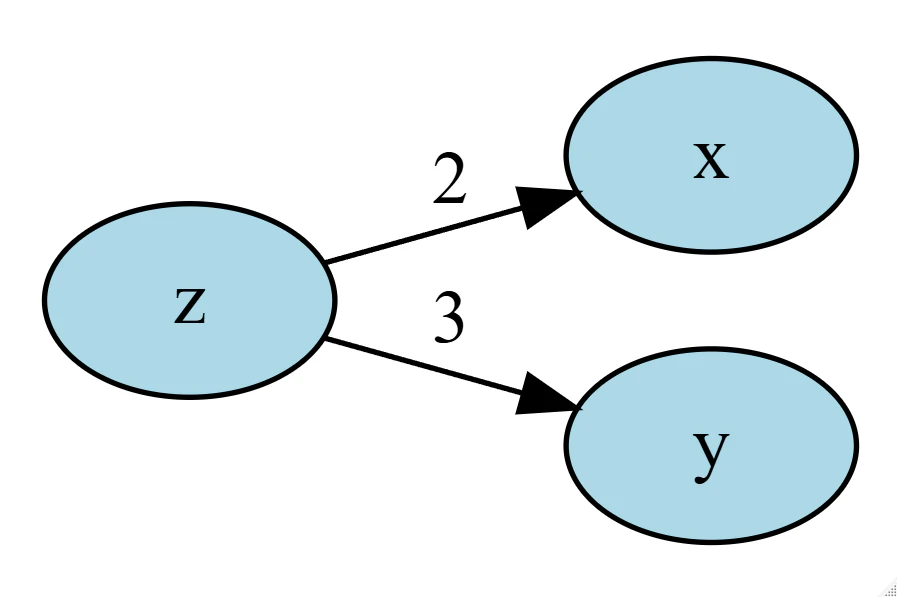
次に、ZがXとYの両方に影響するモデルを試してみましょう。
# パス図
DiagrammeR::grViz("
digraph {
graph[layout = dot, rankdir = LR]
x, y, z [style='filled', fillcolor = 'lightblue']
z -> x [label = 2]
z -> y [label = 3]
}
")
set.seed(12)
z <- runif(n)
set.seed(34)
ex <- runif(n)
set.seed(56)
ey <- runif(n)
x <- z * 2 + ex
y <- z * 3 + ey
考えられるすべてのパスについて、正順と逆順の回帰分析を行い、説明変数と残差の関係を可視化します。
model_xz <- lm(x ~ z) # 正解
model_zx <- lm(z ~ x)
model_yx <- lm(y ~ x)
model_xy <- lm(x ~ y)
model_zy <- lm(z ~ y)
model_yz <- lm(y ~ z) # 正解
df <- data.frame(
x = x,
y = y,
z = z,
model_xy = model_xy$residuals,
model_yx = model_yx$residuals,
model_xz = model_xz$residuals,
model_zx = model_zx$residuals,
model_yz = model_yz$residuals,
model_zy = model_zy$residuals
)
p_xy <- df |>
ggplot(aes(x = y, y = model_xy)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "x ~ y", y = "residuals")
p_yx <- df |>
ggplot(aes(x = x, y = model_yx)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "y ~ x", y = "residuals")
p_xz <- df |>
ggplot(aes(x = z, y = model_xz)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "x ~ z: 正しい因果順序", y = "residuals")
p_zx <- df |>
ggplot(aes(x = x, y = model_zx)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "z ~ x", y = "residuals")
p_yz <- df |>
ggplot(aes(x = z, y = model_yz)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "y ~ z: 正しい因果順序", y = "residuals")
p_zy <- df |>
ggplot(aes(x = y, y = model_zy)) +
geom_point(alpha = 0.5) +
theme(aspect.ratio = 1) +
labs(title = "z ~ y", y = "residuals")
p_xy + p_xz + p_zy + p_yx + p_zx + p_yz +
plot_annotation(title = "残差と説明変数の関係")
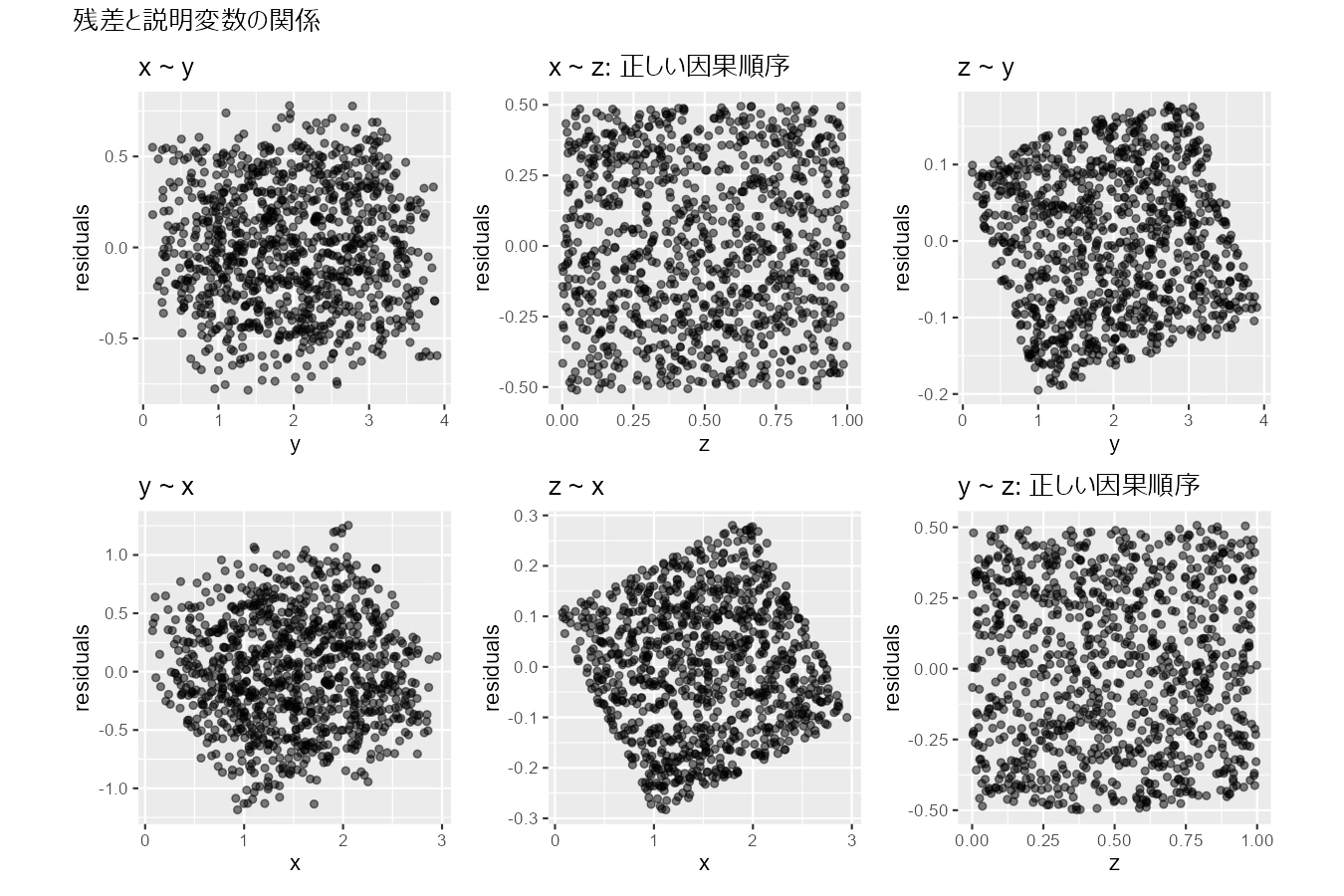
正解のx~zとy~zの残差はきれいな一様分布になっています。
正しくない因果順序は分布が歪んでいます。
x ~ yとy ~ xは両方とも正しくないと判断できるので、疑似相関を判別できていることも分かります。
実際のDirect LiNGAMではこの独立性の評価に相互情報量やHSICを使って評価していきます。
そして、因果グラフの構造が定まったら、最小二乗法やLASSO回帰を用いて影響の程度を推定したり、冗長なパスを刈り取るといった処理を行います。
以上です!