はじめに
一般の方は耳にしたことがないだろうが、「Numerai(ヌメライ)」というヘッジファンドがある。2016年後半から2017年前半くらいにWiredやForbes等のメディアに取り上げられ、界隈で少し名が知られるようになったヘッジファンドだ。このヘッジファンドはいわゆるクラウドソーシング型ファンドと呼ばれる、不特定多数の人間による株価の予測結果をもとに運用するヘッジファンドである。
筆者も2017年頃、Numeraiに参加したことがある。Numeraiの方式は予測結果に基づいてランキングされるトーナメント方式であり、つまりKaggleのようなものだ。トーナメントは毎週開催され、ランキング上位には暗号通貨で報酬が支払われる。しかし当時のトーナメントは、ランキングの基準が不明瞭であり、その順位変動がとてつもなく激しく(TOP10に入っていたのに翌週は100位以下に落ちる等)、いわゆる運ゲーだったためすぐに辞めてしまった。
最近、とある事情があり、およそ3年振りにNumeraiを覗いてみた。そうすると2017年当時よりもトーナメントの仕様が随分と洗練されているではないか。データセットをダウンロードして特徴量を観察すると、なかなか面白い。これはファイナンスM/Lに携わるものとして絶好の腕試し案件だと思い、1週間ほど缶詰になってデータセットと格闘していた。
Numeraiのデータセットおよびトーナメントは、ファイナンスM/Lに興味を持っている方にとって非常に有意義な教材であると考えている。この場を借りて読者の方へ紹介させて頂こうと思う。
Numeraiについて
Numeraiについてもう少し説明を加えておく。Numeraiの概要については、筆者が2017年に執筆した過去ブログをまず参照して頂きたい。その上でNumeraiの特徴をまとめると、
- Numeraiは参加者から集めた予測結果をもとにメタ学習を行い、その結果に基づいて運用する。
- Numeraiのデータセットは秘匿化されており、参加者はその特徴量や予測対象の銘柄が何なのか全く知ることはできない。
- Numeraiへ提出するのは予測結果だけであり、予測モデルは提出する必要はない。参加者の知的財産は保護されており、それゆえNumeraiは大量の予測結果を集めることができる。
- ファイナンス機械学習の著者でありAQRのML部門でヘッドを務めていたMarcos Prado氏がアドバイザーに就任している。
- Numeraiは著名なヘッジファンドであるルネッサンステクノロジーからも出資を受けている。
- Numerai自身の運用資産や利回りは非開示であり全く不明であるが、これまでに参加者に支払われた賞金総額は25億円を超えており、その運用状況は良好なものと推測される。
トーナメントの仕様
さて、次にトーナメントの仕様を見てみよう。Numeraiのトーナメントは毎週開催され、週末に新規のデータセットがダウンロード可能となる。アップロードの期限は翌月曜日の23:30(日本時刻)となっている。アップロードする予測の作成手順は以下の通りだ。
データセットのダウンロード
ログインすると画面左にダウンロードボタンがある。これを押すだけだ。ダウンロードされたZipファイルには、以下のデータセットが含まれている。
- numerai_training_data.csv
- numerai_tournament_data.csv
training_dataは学習用のデータセット、tournament_dataは予測作成用のデータセットだ。これらはCSVで提供されているが、容量が大きいためExcelで開くことは困難である。参考までにtrainig_dataの次元は(310特徴量+α)×約50万サンプルでありその容量は770MB、tournament_dataの次元は(310特徴量+α)×約170万サンプルでありその容量は2.6GBに及ぶ。データセットの内容については、後述の章にてもう少し詳しく触れることにする。
モデルの作成~予測結果の提出
モデルの作成はPythonかRが適当だろう。この両者についてサンプルコードが提供されている。データセットをダウンロードするとサンプルコードも梱包されている。参考までにNumeraiのHPにて提供されているコードを下に載せておく(Python ver.)。
以下の手順で作成したCSVをNumeraiのHPでアップロードするだけだ。簡単である。
import pandas as pd
from xgboost import XGBRegressor
# Read the csv file into a pandas Dataframe
training_data = pd.read_csv("numerai_training_data.csv").set_index("id")
tournament_data = pd.read_csv("numerai_tournament_data.csv").set_index("id")
feature_names = [f for f in training_data.columns if "feature" in f]
# train a model to make predictions on tournament data
model = XGBRegressor(max_depth=5, learning_rate=0.01, \
n_estimators=2000, colsample_bytree=0.1)
model.fit(training_data[feature_names], training_data["target"])
# submit predictions to numer.ai
predictions = model.predict(tournament_data[feature_names])
predictions.to_csv("predictions.csv")
モデルの評価
一般的な機械学習モデルの評価にはAccuracyやLoglossが使われるが、Numeraiのトーナメントモデルの評価にはRank Correlationが使われる。これは非常に好ましいことだ。なぜならトレーディングにおけるスキルとは情報係数(Information Coefficient)であり、すなわちこれは予測ターゲットと予測に使った投資指標との相関係数であるからだ。この辺りの考え方は伝統的なアクティブ運用理論に基づいており、興味のある方は筆者の過去ブログを参照して頂きたい。Rank Correlationは以下のコードにて計算可能である。こちらのコードもNumerai提供だ。
ranked_prediction = training_data["prediction"].rank(pct=True, method="first")
correlation = np.corrcoef(training_data["target"], ranked_prediction)[0, 1]
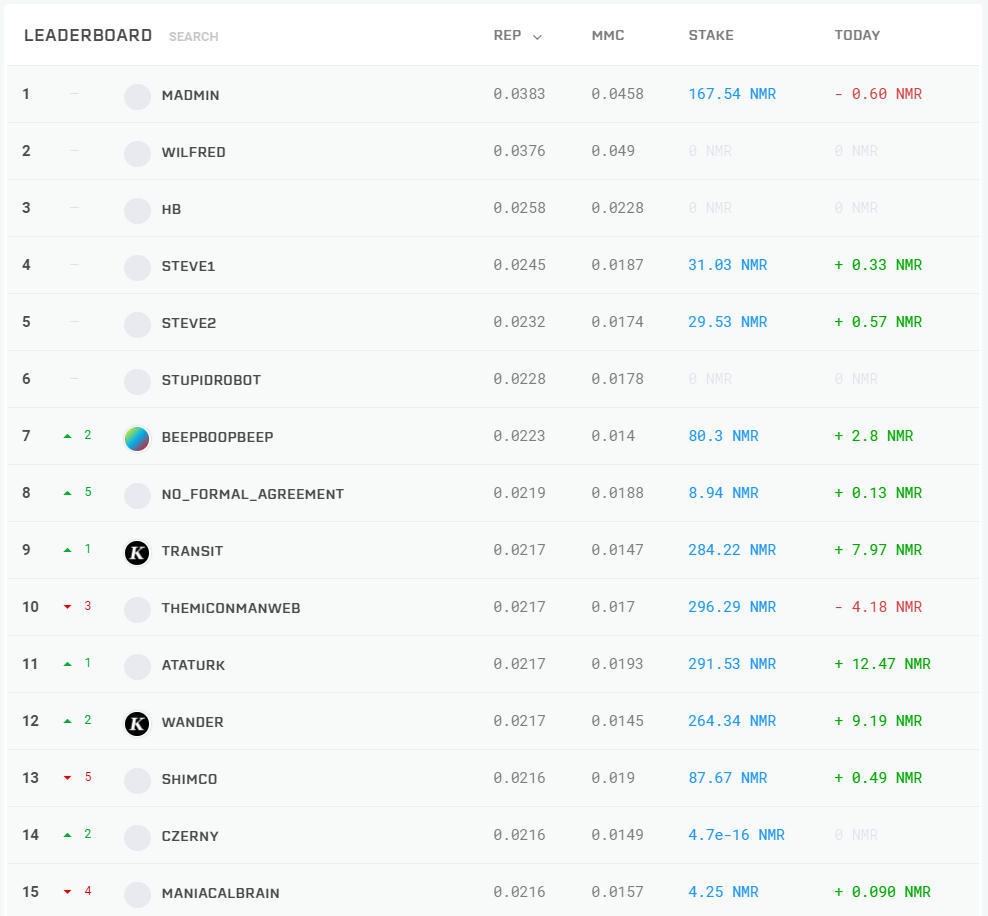
リーダーボードランキング
リーダーボードはreputationによってランキングされる。reputationとは、フォワード予測におけるRank Correlationの直近100日の平均値だ(※直近でトーナメント仕様がアップデートされている。旧仕様は直近20トーナメントの平均値であった。これに関するドキュメントはまだ更新されていないようだ)。
リーダーボードにはもう1つMMC(Meta Model Contribution)という指標がある。こちらはNumeraiが実際に運用するメタモデルとの相関値である。こちらの指標は直近のアップデートで実装されたばかりであり、表示されているだけで記事公開の時点ではまだ機能していないようだ。
報酬体系
では読者の方の一番の興味対象であるNumeraiの報酬体系について説明する。まず、大前提として「Numeraiの報酬はNMR(Numeraire)というNumerai独自の暗号通貨で支払われる」ということだ。この時点で「暗号通貨ってよく分からないし面倒くさいな」と思った方は、この章は読み飛ばして頂いて構わない。
もう1つの大前提は、報酬を受け取るためには「手持ちのNMRをステイクする必要がある」ということだ。これについて少し詳しく説明する。
ステイクについて
NMRで話を進めると拒絶反応を起こす方もいるかもしれないので、ここでは円建てで話を進める。
ある参加者の一人が自信のある予測結果が作れたとする。これで報酬を得たい。そう思ったら、自身の予測結果に対して例えば1万円をベットするのだ。その結果、予測が良好であればベットした1万円に応じた報酬を得る。反対に予測が悪ければベットした1万円の一部は運営に徴収される。
これは面倒くさい仕様であるが、よくよく考えれば仕方のないことである。ユーザー自身が何らかのリスクを負う形でなければ、例えば1000個くらいアカウントを作って適当な予測結果を提出し続ければいつか偶然良い結果が得られて報酬が貰えるかもしれない。それを防ぐことが目的だ。またベット額から参加者の自信の多寡が伺えることから、Numeraiがメタモデルを構築する上でもステイク量は非常に重視されている。
ステイクに対する報酬は以下の仕様となっている。そのトーナメントラウンドにおけるRank Correlationに応じて、報酬が付与されるかそれとも徴収されるかが決まる。付与および徴収はベットした額の25%が上限となっている。
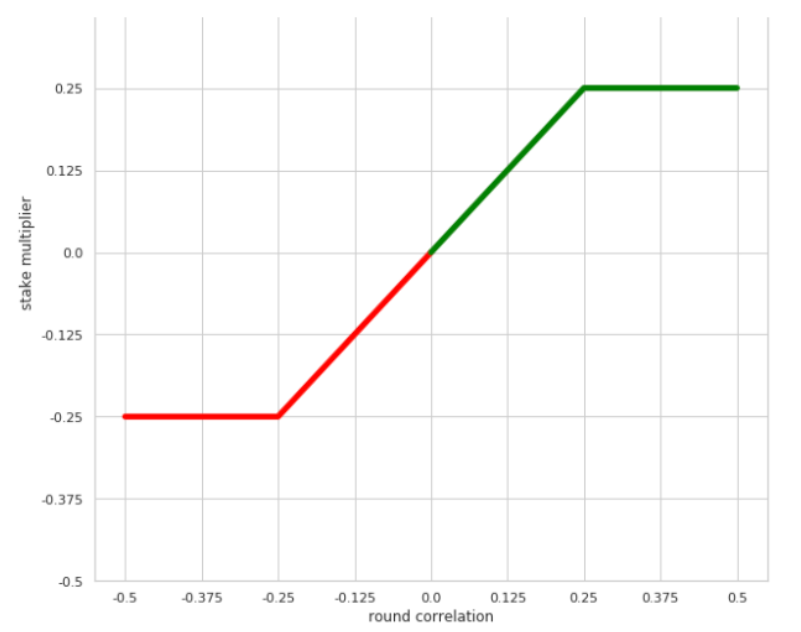
もう少し具体的な話をすると、各トーナメントラウンドにおけるRank Correlationの値はだいたい-0.15~+0.15の間に収まる(つまり徴収/付与はベットした額の-15%~+15%程度に収まる)。各ラウンドを隔てたバラツキはそれなりに大きいが、熟練した参加者であれば平均して0.03程度に落ち着く。つまり長く参加しているとラウンド毎に+3%程度の報酬が期待できるというわけだ。
デイリーボーナス
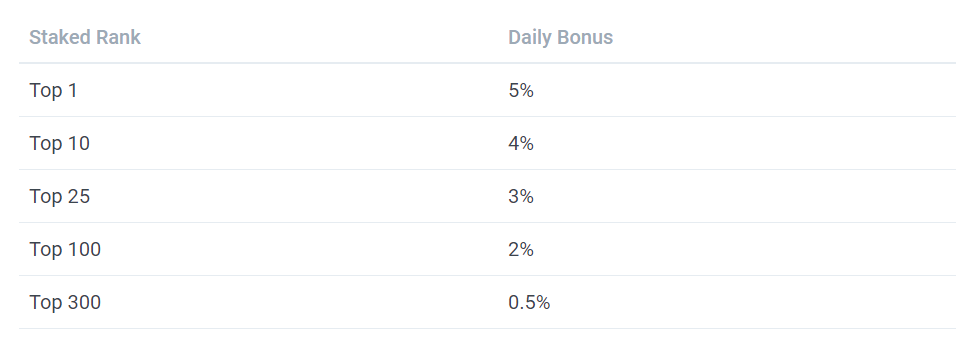
「たった3%か」。そう思った方が多いと思う。Numeraiで大きく報酬を得る手段は別にある。それがランキングだ。
リーダーボードで高ランクに位置すると、ステイク量に応じたデイリーボーナスが付与される。ランキングトップには5%、TOP10であれば4%だ。仮にランキングTOP10を維持できれば、日利4%という莫大な利回りを享受することができる。ただし、以下のような条件は存在する。
- ペイアウトは週5日
- 獲得した額は毎週木曜日に複利積み増しができる
- ステイクした100日後からペイアウトが適用される(100日のフォワード予測を行った後、ということである)
また、当然ながらNumeraiが参加者全体に支払う額には上限があり、日当たり250NMR(現在の時価で45万円)までだ。これを超えると、支払総額が上限額に収まるよう報酬は参加者が貰うべき値に均等割りされる。ガッツリステイクしてランキング上位に君臨すれば、日当たり数万円を得ることは十分に可能である。目指すべき報酬は月あたりおよそ100万円。データサイエンティストとしての副収入には十分だろう。
ただ注意しておきたいことは、NMRはいわゆる草コインと呼ばれる信用の低い暗号通貨である。価格の変動は激しく、いつゴミになるか分からない。暗号通貨の取引所に上場しているが、流動性も少なく決まった量を決まった額で換金することができない可能性もある。暗号通貨は税制の取り扱いも不利であるし、送金の取り扱い方を間違えると紛失してしまい手元には戻らなくなる。あくまでも「余剰資金」を「自己責任」の範囲内で楽しむことが大事である。間違ってもNMRの取引差益で稼ごうなどとは思わないことだ。
データセット
次にデータセットの内容について説明しよう。データセットは、2019年からMarcos Prado氏が監修している。2019年12月に発売されたPrado氏の著書(邦訳版)「ファイナンス機械学習」は、Amazonでバカ売れしていたので目にした方も多いはずだ。Prado氏の監修により、特徴量の総数はそれまでの40程度から300程度まで拡張されている。Prado氏はNumeraiのデータセットについて論文まで出している。興味のある方は読むべきだろう。
項目について
データセットの項目は下記のようになっている。サンプル数はtraining_dataがおよそ50万、tournament_dataがおよそ170万である。
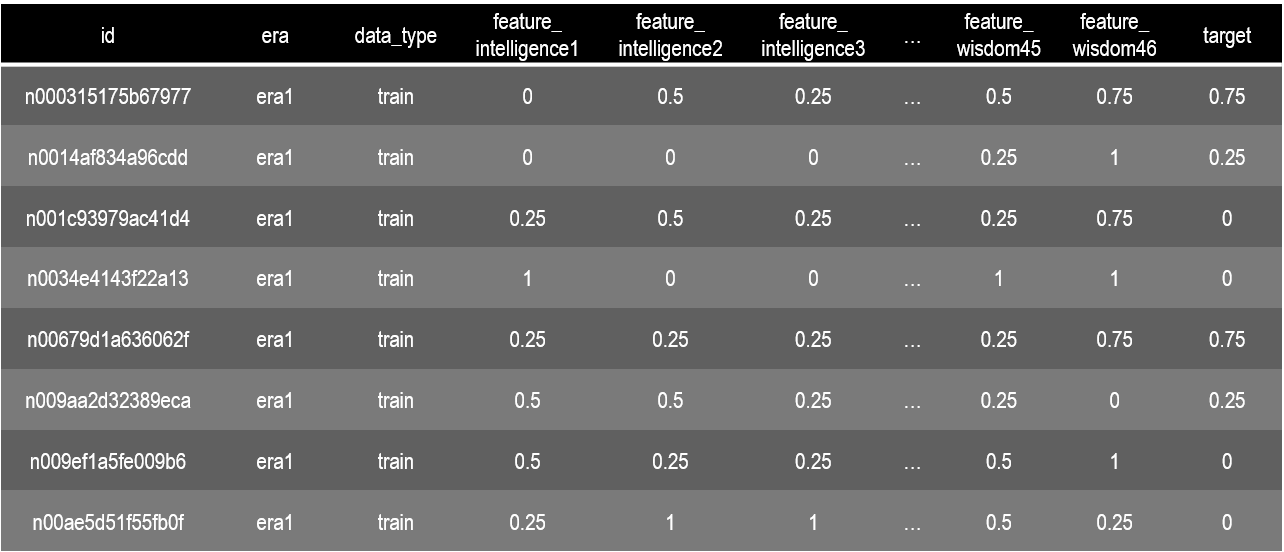
- idは各サンプルに個別に振られた数値であり、全てのサンプルにおいて重複しているものはない。idの数値は日時と銘柄名を暗号化したものだと考えられる。
- eraはデータの期間を示している。training_dataにはera1~era120までの120の期間が含まれている。株式市場は時系列で変化が生じるため、データセットの期間構造を考慮してEDAを行う必要がある。なお、era1~era120が時系列順であるかどうか説明はない。また各eraにおいてサンプル数が異なるため注意が必要である。
- data_typeはtraining_dataではtrainだけである。tournament_dataではvalidation、test、liveの3種類が存在する。validationはモデル検証用のデータでありtargetが付与されている。testはNumeraiが成績判定のために使うセットでありtargetはnan値である。liveは現在進行形の市場データである。当然targetはnan値である。それぞれ特徴量の数は異なる。
- featureの総数は310である。各featureにはサブネームが付与されている。intelligence(知力)、charisma(魅力)、strength(筋力)、dexterity(敏捷力)、constitution(耐久力)、wisdom(判断力)である。これはダンジョンズ&ドラゴンズというRPGのステータス名にちなんでいる。
- targetは教師データである。
featureおよびtargetの数値について
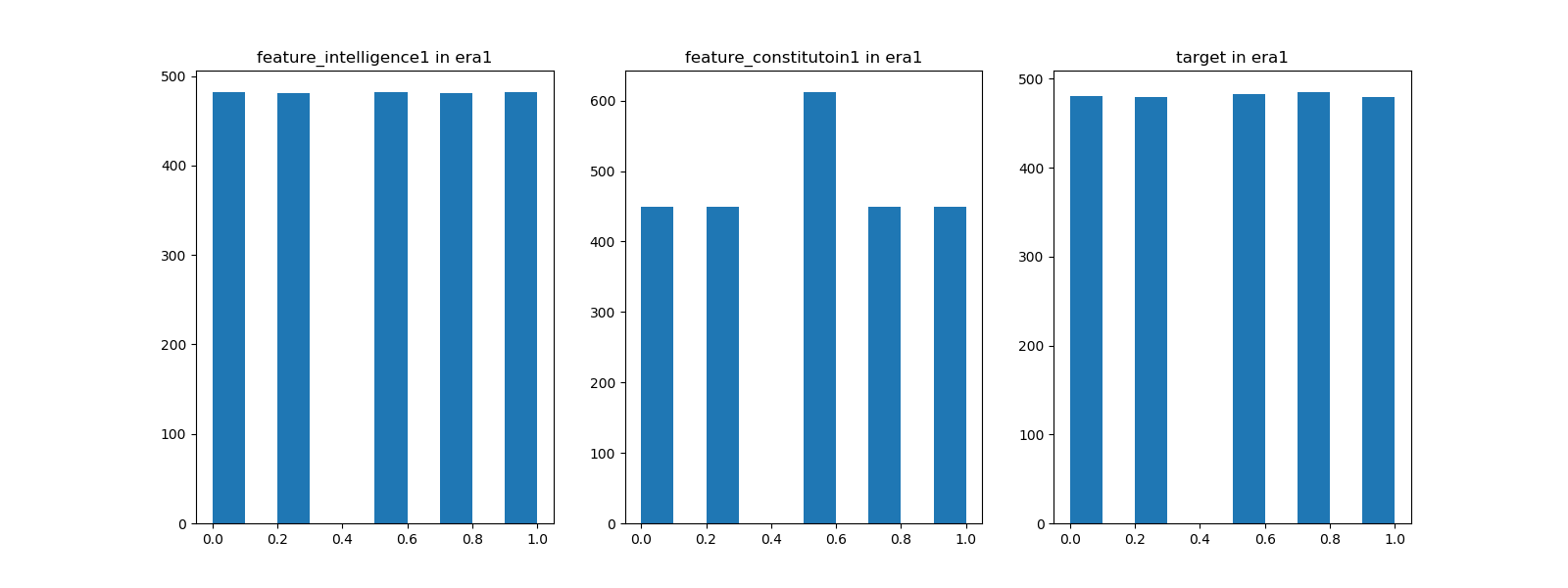
上記のデータを眺めてみてお気付きになっただろうが、featureおよびtargetの値は離散値である。その数値は、0、0.25、0.5、0.75、1の5種類であり、要するにこれはクオンツ運用にありがちな5分位のデータになっている。era毎にヒストグラムを観察すると以下のようになる。各分位のサンプル数が揃っているものとそうでないものがある。下図のfeature_constitution1のような特徴量の原系列はファットテールな分布であるか、もしくはカテゴリ変数のように該当が極端に少ない場合だろう。そのように思索しながらEDAを進めていく。
期間構造について
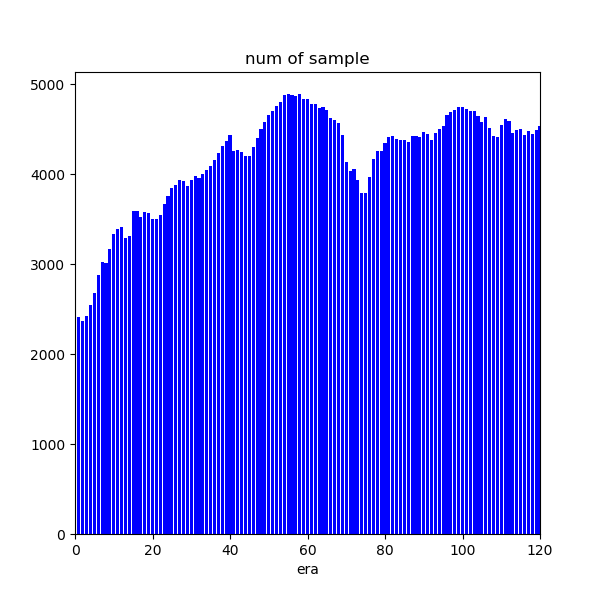
次にera毎のサンプル数の推移を見ていこう。以下のように各eraにおいてサンプル数はかなり異なる。相関なり何なりはやはり時系列で追っていく必要がある。サンプル数の推移は概ね連続に見えることから、era1~era120は時系列順に並んでいる可能性が高いと考えられる。
さらなるEDA
上記までは基本であり、さらにEDAを進めていくと色々なことが分かってくる。2017年当時と比べるとデータセットは非常に洗練されており面白みがある。「なるほど、Prado氏監修だけのことはある。このトーナメントは運ゲーにはならないはずだ」。筆者の中には確信がある。
トーナメント参加結果
筆者は次回のROUND208からNumeraiに参戦する。既にモデルはできておりvalidationの結果は良好であった。ランキングに使われるreputationは直近100日のフォワード予測の結果であり、データのない日は一律で-0.1が適用される。よって新規参加者は-0.1のreputationから始まり、フォワード予測の結果が溜まっていくに連れて徐々に順位を上げていくことになる。
この章は逐一更新していく予定である。
(2020/4/19追記)
予定通りROUND208のpredictionを提出した。Validation Correlationは0.034でありまずまずの値である。ついでに手持ちのNMRを全てステイクしておいた。26NMR(4/19時点の時価でおよそ6万円)であり、これは2017年に参加した時に手にした報酬である。なお繰り返しになるがペイアウトの適用は100日後からである。
(2020/4/24追記)
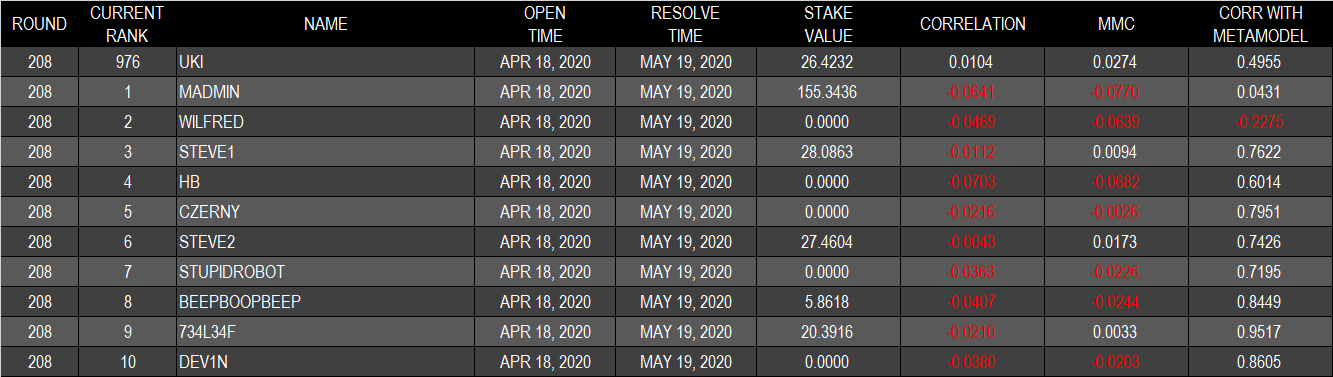
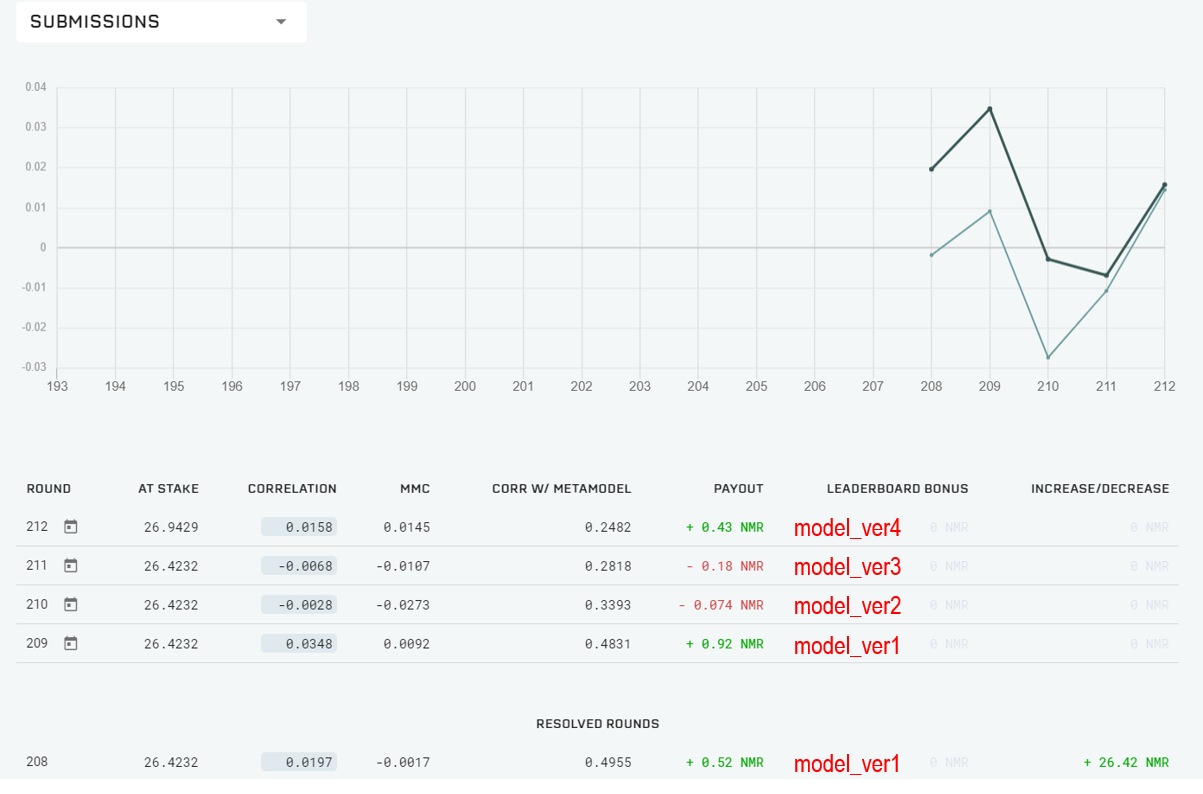
ファーストサブミッションとなったROUND208の結果は良好であった。ランキングTOP10がいずれもマイナスのROUND CORRELATIONとなった中、筆者のモデルはプラスで終えることができた(下表は筆者集計)。
(2020/4/30追記)
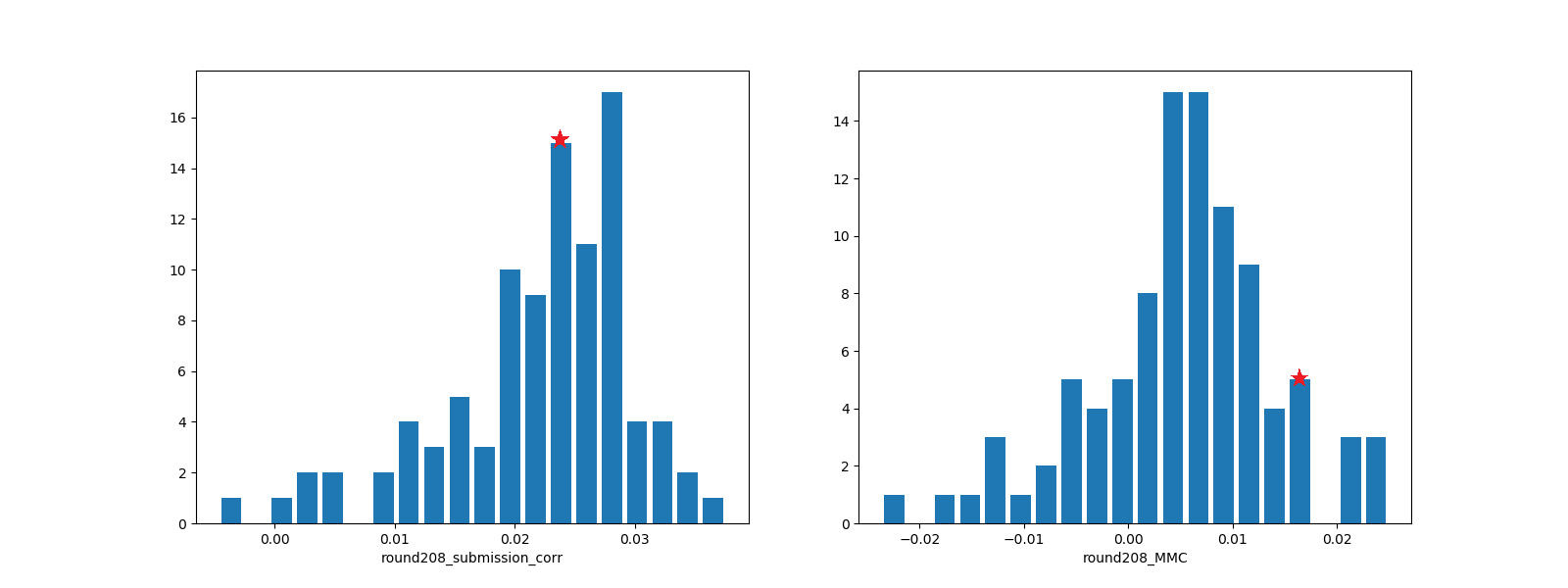
上記の結果は、ROUND208の初日のみの集計であった(ROUNDが終わった確定値だと勘違いしていた。失礼)。実際のROUNDは20日間であり、期間中は毎日correlationの値が変化する。本日、ROUND208の5日経過時点での、ランキングTOP100ユーザーのcorrelationとMMCの分布、および筆者の位置を示す。今のところ順調である。MMCについては下の章に追記しておいたのでそちらも確認してほしい。
(2020/5/22追記)
何回かモデルのverをアップデートして、ROUND212からほぼ最終モデルに落ち着いた。これで暫く様子を見る予定である。
追加情報(2020/4/25制定)
実際にROUND208に参加してみて色々と分かったことがあるので本章を制定する。今後も何か分かったことがあれば本章に追記していく予定である。
(2020/4/25追記)
-
ペイアウトは100日後から適用と書いたが、これはデイリーボーナスに関する条件でありCorrelationに応じた報酬の付与/徴収はステイクしたラウンドから即時行われることが分かった(下図)。
-
Correlationによるペイアウト量は各トーナメントラウンドにおけるRank Correlationに応じて発生すると書いたがこれは正確ではなかった。そのラウンドが終了してそのラウンドを通じたCorrelationが確定した際に一度のみ報酬/付与が行われると考えていたが、実際はそのラウンドの開催中においてデイリーのCorrelationに応じて毎日付与/徴収が発生することが分かった(下図)。 -
ラウンドの具体的なタイムスケジュールが把握できたので記載しておく(以下全て日本時刻)。日曜日未明にデータセットが更新される。predictionの提出期限は月曜日23:30だと考えていたが、ROUND208における提出期限は火曜日0:30であった。また、そのラウンドの開始日は木曜日となるようである。ROUND208を例に取ると、データセットがDLできたのは4/19(日)の早朝、predictionの提出期限は4/21(火)0:30、ラウンドが開始されたのが4/23(木)であった(下図)。

-
training_dataは基本的に変更されない。このためデータセットをダウンロードする度にモデルを作り直す必要はない。前回ラウンドの提出結果をもとに改善を加えてもよいが、ラウンドの結果はバラツキを伴うため短期間の結果をもとにモデルの変更を判断すべきではない。
-
チート行為について。Numeraiのフォーラムで議論されているが、3つのアカウントを使ってトータルのCorrelationの平均を0近傍にしつつ(つまりステイクで徴収されるリスクを0にしつつ)、運よく上位に入ったアカウントでデイリーボーナスを狙う、という行為が確認されている(そもそもこのような攻撃を抑止するためにデイリーボーナスのペイアウト適用を100日後にしているらしい)。このため今後の報酬体系に変化が生じる可能性がある。
(2020/4/30追記)
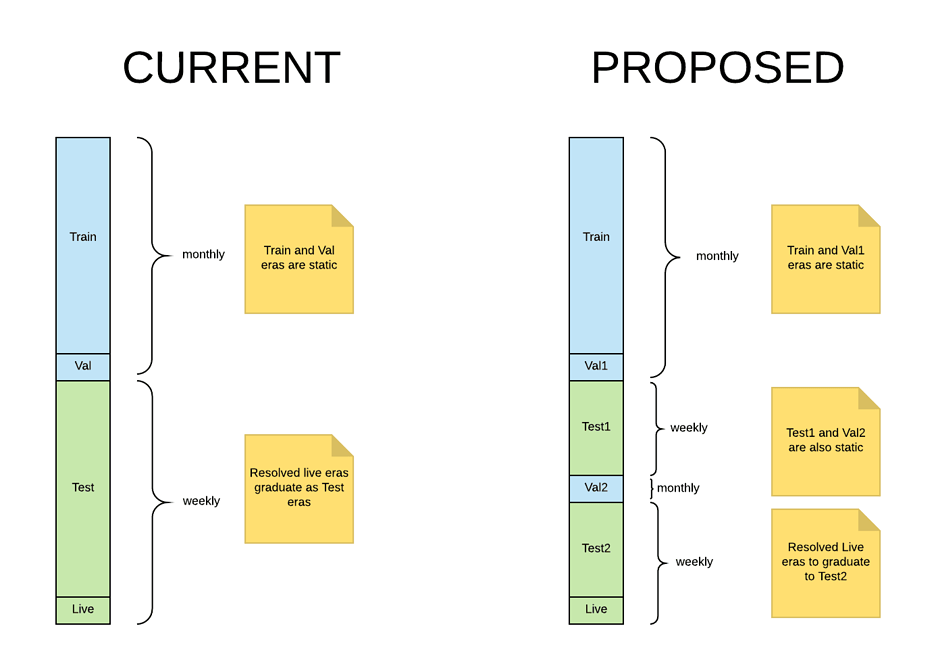
- ROUND210よりValidationのデータ構造が変更となる。これに伴うtournamnet_dataの変更はない。具体的には以下の図のように期間を隔てて2つの期間のValidationが用意されることになる。詳細なアナウンスはこちら。いずれかにコロナショック期間のデータも含まれるとのこと。testデータおよびliveデータはweeklyであるが、実際のROUNDは4week(=1month)で開催されているため訓練データとの差異は生じないような仕組みになっている。
-
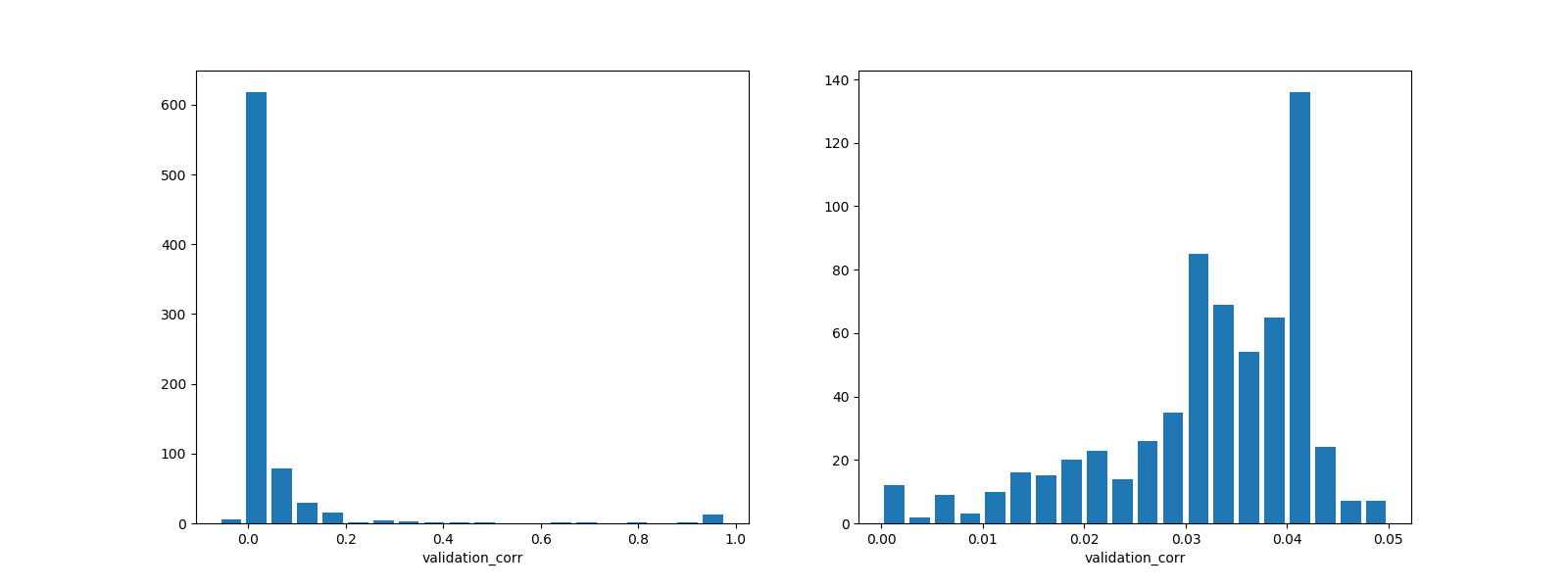
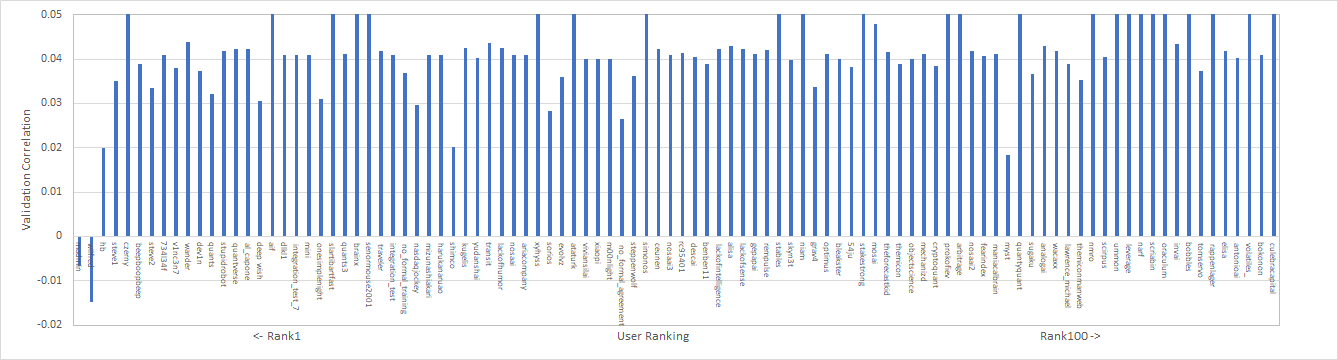
参考までにROUND208の参加者全体のValidation Correlationを集計したので記載しておく。全体(左図)を俯瞰すると極端にcorrelationが高いユーザーがいるが、これはtournament_dataに含まれているvalidationデータも訓練データに含んでモデル構築しているためである。アウトオブサンプルの予測性能に自身があるのであれば、このようなやり方も良いのではないかと思う。現実的な範囲(右図)で確認すると0.03台が多いことが分かる。Validation Correlationが極端に低いユーザーは、チートなどの別の意図を含んでいる可能性がある。
-
2020年5月末よりMMCによるペイアウトがスタートする。ユーザはペイアウトをcorrelation基準とするかMMC基準とするか選択できるようになる(MMCによるペイアウトはMMCに対して2倍を乗じる)。これに伴い、ランキングボーナスは2020年9月までに廃止となる。報酬体系の変化について、その背景を以下に述べておく。
-
チート行為防止のためにランキングボーナスを廃止すると、ユーザーへのペイアウトはcorrelationのみとなる。予測の良し悪しのみでペイアウトが付与/徴収されるとすると、ユーザーがトーナメントに参加するインセンティブはなくなる(予測性能の高いユーザーは自身で株式投資を行えばよい。correlationは運営側が任意に設定できる可能性が存在するため、わざわざ不透明な賭けを行う必要はなくなる)。ペイアウトをMMC(メタモデルへの寄与度)基準とすると、仮に予測性能が低かった場合でも、モデルへの寄与に応じて報酬を得られることになる。correlation基準に対してMMC基準とすると、現状のTOP100ユーザーのうち86人が報酬が増えるとのこと。詳細はこちら。
-
MMCの詳細な計算方法はこちら。簡単に言うと、自身のモデルからメタモデルとの相関を取り除いた残りの部分(レジデュアル部分)とリターンとの相関である。モデルのオリジナリティの部分がリターンの予測にどれだけ結びついているかを示す指標である。
(2020/5/1追記)
- 直近でNumeraiのトーナメントページおよび各ユーザのプロファイルページのフォーマットが変更となり、これによりトーナメント仕様や報酬体系の理解を深めることができた。Numeraiのドキュメントは情報が不足している部分が多く、実際のトーナメント仕様や報酬体系は実機で確認しながら把握するようにしている。このため記事の内容に不備あったり二転三転することがあったりするが、ご容赦いただきたい。またもしお気付きの点があればコメントを頂けると非常に有難い。
- Numeraiでは、4つのROUNDが並行して開催される仕組みとなっているようだ。1つのROUNDは4Weekであり毎週新規ROUNDが始まるためである。進行中のROUND(Resolving Round)におけるペイアウトの記載は、あくまでも暫定(Pending)のものであり、実際にペイアウトされるのはそのROUNDが完全に終了してから(つまりROUND開始から4week経過後、Resolvedとなってから)となる。
(2020/5/5追記)
- ROUND210からvalidationの期間が二つとなった。これらは全て"validation"という同一のラベルが付いているが、本記事では便宜上、従来まで使われていた期間のデータをvalidation1、新規追加になった期間のデータをvalidation2と呼ぶことにする。validation1よりもvalidation2のほうが圧倒的にパフォーマンスが悪くなる。validation2は真の意味でのアウトオブサンプルデータなのだ。これは正直なところ運営ミスだと思っている。validation2の追加によって、validation1は検証用データに全く値しないことが露呈したからだ。筆者もこの変更を受けて、今後どうするか思案中である。
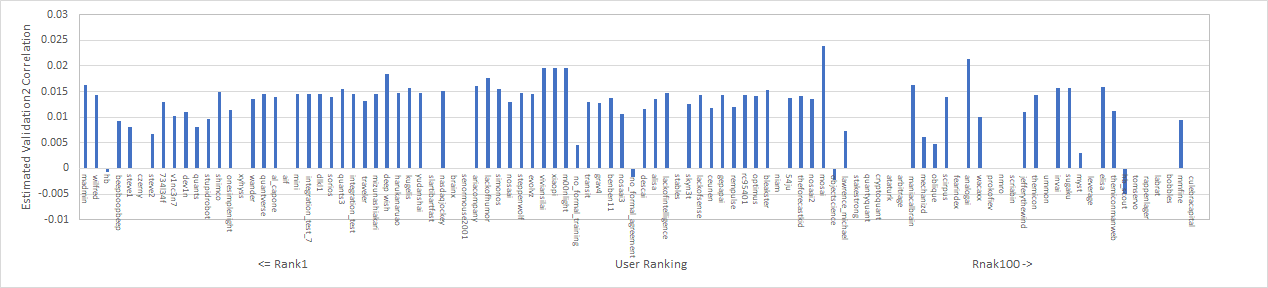
ひとまず、TOP100ユーザーのvalidation2のValidatoin Correlationを推定したので記載しておく。データが抜けている部分は推定できなかった箇所である。少なくともValidation2期間におけるValidation Correlationは0.01~0.015が妥当だと考えている。結局筆者が提出したROUND210のvalidation2期間のValidation Correlationは0.013程度とした。
(2020/5/22追記)
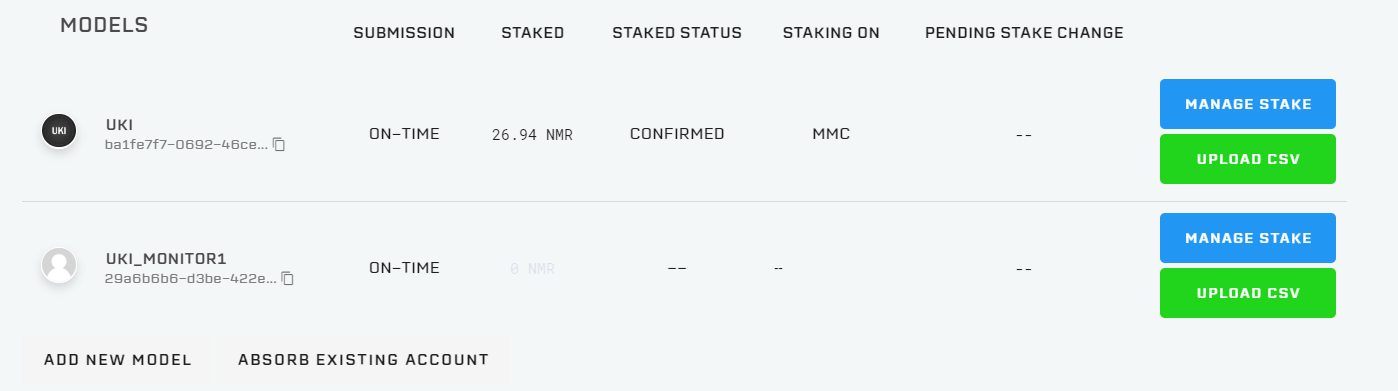
Numeraiでは複数のモデルの提出を認めているが、これまでは独立したメールアドレスでそれぞれのアカウント登録が必要であった。今回、1アカウントについて10モデルまで提出できるように変更された。各モデルでステイク量も割り振って管理できるようになっている。設定方法はこちら。
なお、筆者は2モデルを提出している。サブのモデルはモニタ用であり、数ラウンド様子を見て良好なパフォーマンスであればメインモデルに結合する予定である。
Numerai API(2020/5/1制定)
NumeraiのAPIがあるので紹介しておく。このAPIを使ってデータセットのDLやpredictionの提出ができる。しかしそれよりも有用なのは、ユーザー情報を集計できることだろう。以下、各Roundの最終日におけるTOP100ユーザーのRound CorrelationおよびMMCを取得するためのサンプルコードを載せておく。APIリミットがよく分からないので叩きすぎに注意すること。他にも便利な使い方があれば紹介していく予定である。
import time
import numerapi
import matplotlib.pyplot as plt
round = 208
api = numerapi.NumerAPI()
LB = api.get_leaderboard(limit=100) # TOP100ユーザー
users = [LB[i]["username"] for i in range(len(LB))]
submission_corr = []
mmc = []
for user in users:
sub = api.daily_submissions_performances(username=user)
sub_round = [sub[i] for i in range(len(sub)) if sub[i]["roundNumber"]==round]
submission_corr.append(sub_round[0]["correlation"])
mmc.append(sub_round[0]["mmc"])
time.sleep(0.5)
plt.hist(submission_corr)
plt.hist(mmc)
Numeraiコミュニティ(2020/5/22制定)
NumeraiはRocket.chatというプラットホームでオープンチャットコミュニティを設けている。Rocket.chatはディスコードのようなものである。トーナメントの重要な変更に関する議論や、モデルのデータサイエンスに関する議論が行われている。何か有用な情報があればピックアップして本章にて紹介するが、特に本気で取り組んでいる方は是非ともコミュニティに参加すべきだろう。コミュニティにおける筆者のIDはuki1である。
(2020/5/23追記)
MMCによるペイアウトが開始され、コミュニティでは自身の予測結果をneutralize(直交化)する手法が流行っているようである。MMCはメタモデルに対してneutralizeするのだが、メタモデルは当然ながら未知であるため、Exampleモデル等の予測結果を代表的な予測結果と考え、それに対して自身の予測結果をneutralizeするのである。この所作を行うと代表的なモデルとの相関を低く抑えることができる(ただし予測性能が残るかどうかは話は別である)。以下はneutralizeのコードである。proportion=0.5程度でneutralizeを行って、それでもなお予測性能を維持できる事例が報告されている。次のROUND213ではとりあえずneutralizeしてみて、予測性能が残るようであればneutralize後の予測結果を1つ提出してみるのも悪くないだろう。
import pandas as pd
import numpy as np
# seriesは自身の予測結果、byはneutralizeの基準となる予測結果(MMCではメタモデルの予測結果)
def neutralize_series(series, by, proportion=1.0):
scores = series.values.reshape(-1, 1)
exposures = by.values.reshape(-1, 1)
exposures = np.hstack((exposures, np.array([np.mean(series)] * len(exposures)).reshape(-1, 1)))
correction = proportion * (exposures.dot(np.linalg.lstsq(exposures, scores)[0]))
corrected_scores = scores - correction
neutralized = pd.Series(corrected_scores.ravel(), index=series.index)
return neutralized
トーナメントにおける優位戦略(2020/5/2制定)
上記までにランキングボーナスが廃止予定でありペイアウトがCorrelation基準もしくはMMC基準の選択制に移行することを述べた。Correlation基準によるペイアウトは、完全に参加者個人の予測スキル依存であり収益の非対称性はなく、腕試し以外の参加者がこれを選択するインセンティブはない。ここでMMC基準を選択した場合、参加者は本当に収益の非対称性を得ることができるのだろうか?本章ではMMCに関する分析を行い、報酬を第一目的とした参加者の優位戦略について考察する。
TOP100の分析
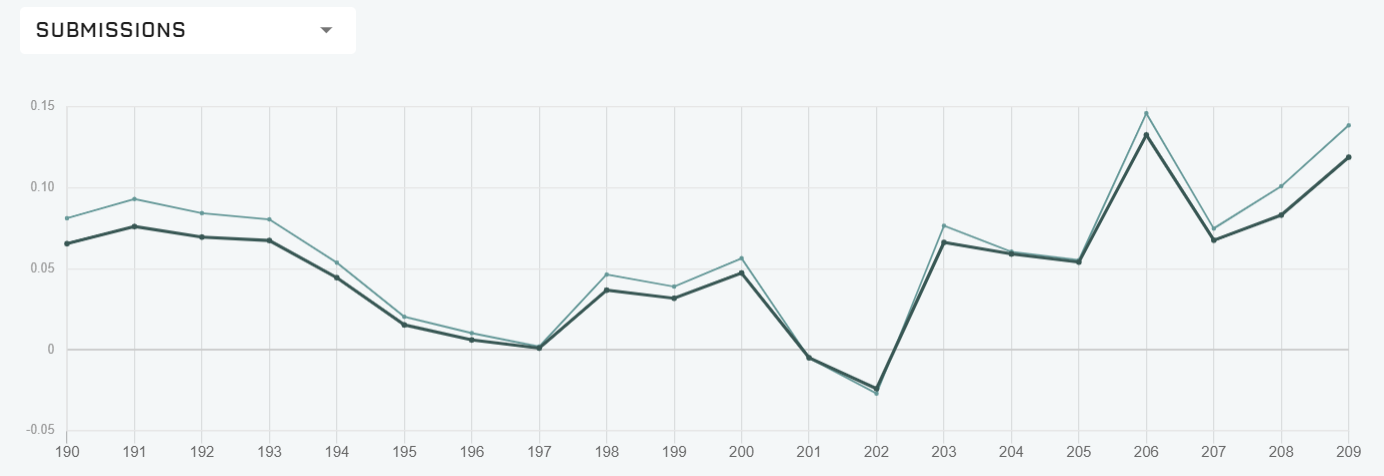
MMCに関する分析を行う前に、まず現在(2020/5/2時点)のTOP100ユーザーが構築したモデルについて分析を行う。まずTOP100ユーザについて、直近20RoundのSubmission Correlationの推移(下図)を元に彼らの作った予測モデルのクラスタリングを行う。明らかに似通った推移のユーザーが多いためである。
クラスタリングの手法はSOMを用いた。またプロットの差異にそれぞれの領域の特徴が分かるよう、予測スキル(reputation)およびメタモデルとの相関(corr w/ metamodel)でプロットにグラデーションを付けた。
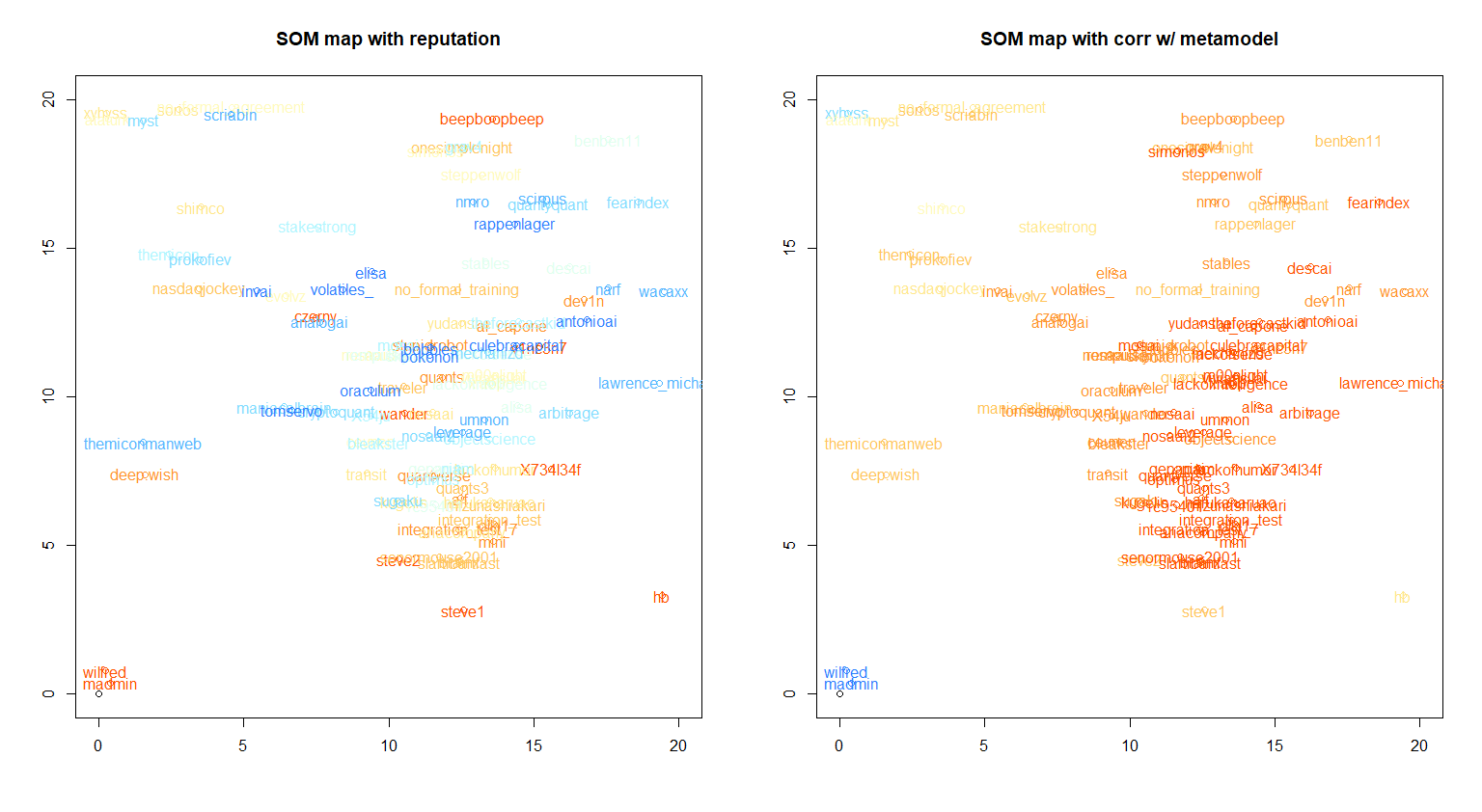
さて、これを見ると明らかに異質なユーザーがいる。SOMマップの左下に位置するmadmin氏とwilfred氏の二人、つまりランキング1位と2位の二人だ。現在ランク1位のmadmin氏はチートの疑いがもたれている(参考サイト)。残念だが2位のwilfred氏も同様であろう。それは彼らのValidation Correlationが明らかに低いことからも推察可能である(下図)。なお参考までに筆者のモデルはマップに左上のグループに位置するものと考えている(データ不足のため、あくまで現在までの挙動からの推測)。
問題は、この2人を除外した後、マップのどの部分に位置することが最も効果的に報酬を得ることができるか、である。単純に予測スキルを高めても良いが、メタモデルとの相関が大きくなってしまうとMMCが低くなって報酬が減ってしまう可能性がある。MMCの仕様を元に、報酬を最大化するための優位戦略がどうなるか検討する(次回報告予定)。
(2020/5/19追記)
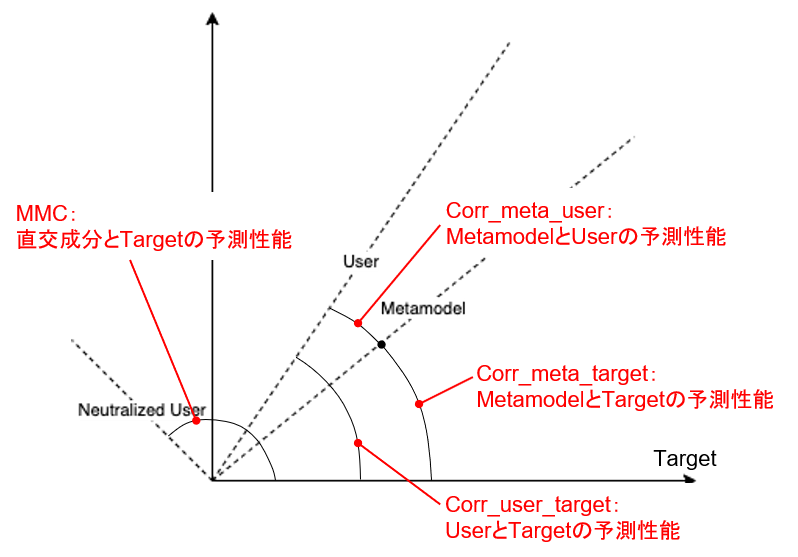
MMCによるペイアウトにおける所見をまとめたので報告する。まずMMCの定義はこちら。簡単に説明すると、予測をN次元のベクトルと考えたとき、MMCとは「メタモデルのベクトルとユーザーの予測モデルのベクトルとの直交成分」とターゲットベクトルとの相関である。以下は2次元(N=2)の場合の模式図である。このとき、予測性能である相関係数は、各々のベクトルがターゲットとなす角度を示す(正確にはcosθ)。この図ではターゲットベクトルは(1,0)成分に固定しているので、予測ベクトルが第一象限にあれば予測性能はプラスとなる。逆に予測ベクトルが第二象限にあれば予測性能はマイナスとなる。下図ではユーザーモデルの予測性能はプラスであるが、メタモデルとの直行成分はマイナスとなっており、MMCであればペイアウトはマイナスになることを意味する。この関係はターゲット、メタモデル、ユーザーのベクトルの位置関係によって大きく左右される。
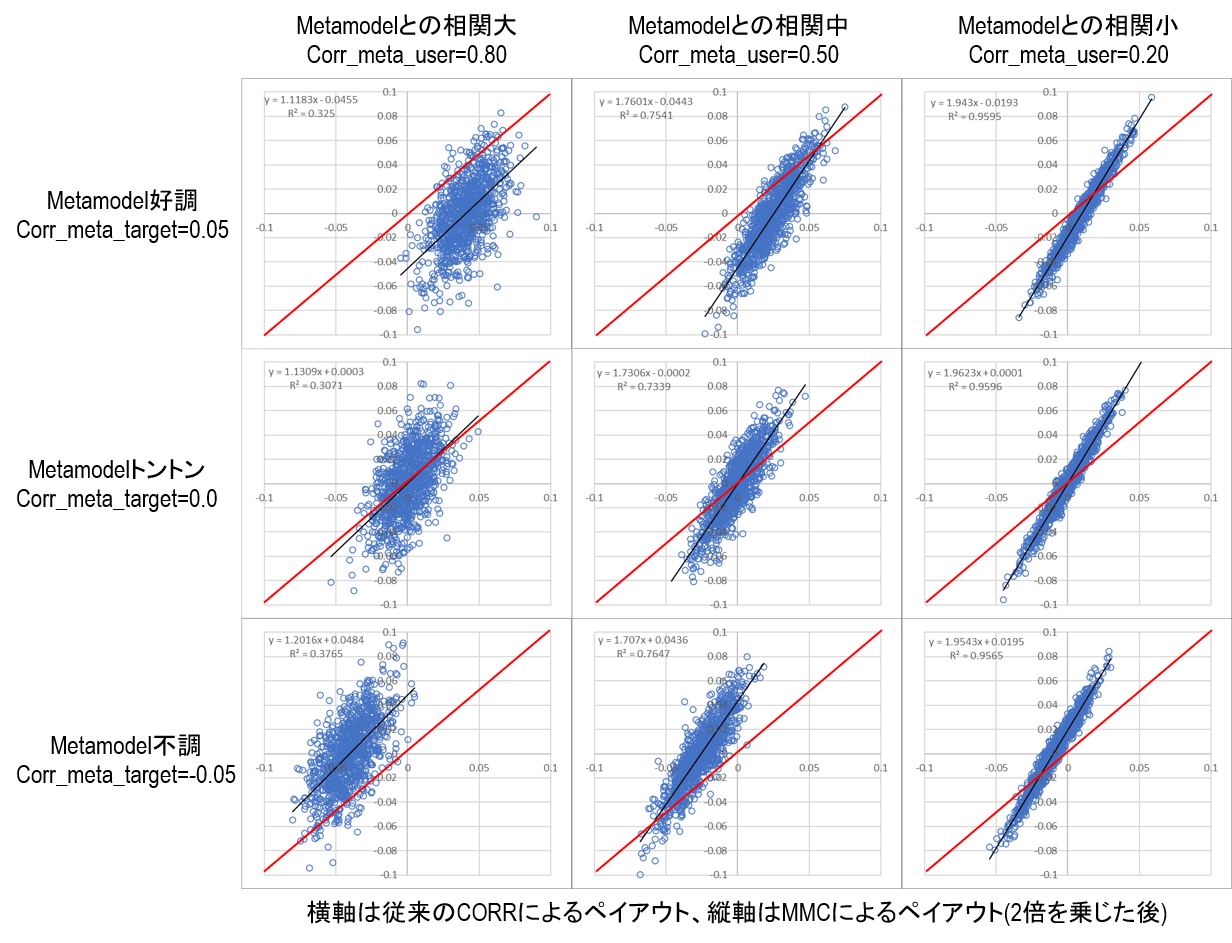
上図のように2次元では極端すぎるので、ここではN=5000次元について乱数を発生させてモンテカルロ的に各パラメータとペイアウトの関係を観察してみた。下図は旧ペイアウトと新ペイアウトを比較した図である。パラメータとして、メタモデルの予測性能およびメタモデルとユーザーモデルの相関を振っている。グラフに斜めに引っ張っている赤線は旧ペイアウト:新ペイアウト=1:1を示す線であり、この赤線よりも左上に位置するプロットは新ペイアウトで報酬が増え、逆に右下に位置するプロットは新ペイアウトで報酬が減るサンプルとなる。
まず分かることは、メタモデルが好調なとき(上列)、MMCによるペイアウトは従来のペイアウト(つまり単純な予測性能)よりも減額される傾向にある、ということだ。逆にメタモデルが不調なとき(下列)、MMCによるペイアウトは従来のペイアウトよりも増額される傾向にある。つまり、全体として予測が好調な期間(予測が簡単な期間)および不調な期間(予測が難しい期間)に対してユーザーへのペイアウトを平滑する効果がある。
次に、メタモデルとの相関別に観察してみると、相関が低くなるにつれて(右列に進むにつれて)回帰係数が増加することが分かる。相関が低い場合は従来のペイアウト(つまり単純な予測性能)に対してMMCによるペイアウトが大きく振れることが分かる。これはすなわち、メタモデルとの相関が低くなると自らの予測性能に対してペイアウトにレバレッジが掛かるということだ。
最後に収益の非対称性であるが、これはグラフからも分かるように旧ペイアウト(つまり単純な予測性能)に対してMMCによるペイアウトは線形の関係であり、フリーランチは存在しないことが分かる。
以上をまとめると、
- MMCによるペイアウトは予測の簡単な期間/難しい期間に対してペイアウトを安定させる
- メタモデルとの相関を下げるとレバレッジを掛けることができる(当然、制約を受けるため難しくなる)
- 非対称の収益機会は存在せず、トーナメントにおける優位戦略は存在しないと考えられる。
つまり、Numeraiに参加するインセンティブとは、予測が難しい期間においてペイアウトが水増しされることになるだろう。定量的な比較は難しいが、投資ポートフォリオの1つと考えれば悪くない選択肢なのかもしれない(ただしNMRリスクを許容できれば、の話である)。
最もスタイリッシュなのは、メタモデルとの相関が低いモデルでガンガンに予測を的中させることだろう。腕に覚えのある参加者は是非ともチャレンジして頂きたい。
(2020/5/22追記)
MMCによるペイアウトがスタートした。CorrによるペイアウトかMMCによるペイアウトか選択できる。設定方法はこちら。
(2020/6/4追記)
筆者が参戦してからおよそ1ヶ月半が経過した。この期間中、筆者は様々な視点から大量の検証を行った。その結果と筆者の知見からNumeraiに参加するインセンティブをまとめたので報告する。
インセンティブ1.大きなレバレッジ
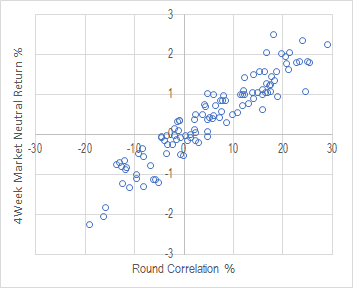
NumeraiのペイアウトはCORRに比例する。CORR=0.1の場合、ペイアウトは10%である(MMCの場合はさらに2倍を乗じる)。この仕様がそもそもハイレバレッジである。Numeraiのモデルはマーケットニュートラルであり、実際にこのような戦略を取ると市場リスクを排除できる反面、利回りは当然低くなる。筆者の経験上、実際の株式市場の大型銘柄のロングショートリターンは、大きく見積もってもCORR=0.1当たり1%である(下図)。つまり、ペイアウトがCORRとなっている時点で既に実際の株式の値動きに対して10倍のレバレッジが掛かっていることになる。MMCの場合はこれに対して最大で2倍のレバレッジが掛かるため、実質的なレバレッジはおよそ20倍となる。さらにこれを証拠金不足に陥ることなく4週連続でベットできるため、実質的なレバレッジはおよそ80倍である。ハイレバレッジは諸刃の剣ではあるが、マーケットニュートラル戦略の資金効率の劇的に改善できるという観点から非常にありがたい仕様となっている。
インセンティブ2.コスト0によるポートフォリオ構築
ユーザーは実際に株式を購入するわけでなく、ただ予測結果に基づいて報酬を受け取ることができる。これは取引手数料やマーケットインパクトの影響が皆無であることを意味する。言い換えると、バックテストからの劣化を全く気にする必要がないわけだ。これはシステムトレーダーにとって唯一無二の恩恵であり、特に大きなステイクをしているユーザーがこの恩恵を顕著に受け取ることができる。
インセンティブ3.MMCによるP/Lの安定化
ハイレバレッジ戦略の場合、P/Lのバラツキが大きいとすぐに退場となってしまう。これは積み上げた報酬をわずか数回の損失で一気に放出してしまうためだ。MMCにベットすると、予測が好調な期間/不調な期間を通じて報酬を平滑化する効果がある。これにより期待値を損なうことなく、ハイレバ複利の運用戦略に持続性を供給することができるようになる。
インセンティブ4.優秀なFeature
一般的に運用戦略の構築において大きな関門となるのは投資指標の探索である。これは特にマーケットの初級者が直面する課題である。どのような指標が説明力を持つのか分からない、そしてそれをどうやって探せばよいか分からない。Numeraiのデータに含まれているFeatureの予測力はとても優秀である。筆者は多角的な検証を行ったが、これらのFeatureを用いればまず間違いなく長期的に見て損益をプラスで推移させることができる。
ここまでをまとめると、Numeraiに参加するインセンティブとは、
- マーケットニュートラル戦略の資金効率を劇的に改善するレバレッジ
- ゼロコストで理想リターンを享受できる
- MMCによる損益平滑効果でハイレバ複利戦略に持続性を供給
- 優秀なFeatureを無償利用可能
システムトレーダーにとって、まさしく夢のようなプラットホームとなっているわけである。
さて、インセンティブだけを説明するとフェアでないので、デメリットについてもう一度確認しておく。トーナメントに参加する上で最も大きいリスクは、運営リスク、NMRの価格変動リスク、NMRの流動性リスクである。
運営リスクは、トーナメントが突如廃止となったり、仕様変更が入って思うようなリターンが得られなくなるリスクである。これは仕方ない。そうなればNMRを引き上げるだけだ(まさか没収されることはないとは思う)。
次にNMRの価格変動リスクであるが、これは受け入れるしかない。そもそも世の中にフリーランチは存在せず、ハイリターンを得るためには必ずリスクが付きまとう。ただしTOPプレイヤーはおよそ30週でステイクした資金を5倍にできていることから、NMRの価格が1/5程度になるリスクは許容できるわけだ。逆に言うとNMRの価格が急上昇する可能性もあるわけで、これであればNMRにベットする価値はあると考えている。
最後に流動性リスクであるが、NMRが上場している取引所は少なく板が薄いため、極端な量のNMRは短期間で換金することが難しい。これが一番のネックだと考えている。大きめの手数料を設定してもらっても構わないので、Numerai運営にはOTCでNMRをBTCやUSDTにスワップできるようにしてもらえると非常にありがたい。
予測のためのTips
無事ランキング上位に君臨できたときは、この章も更新していく予定である。
(2020/5/11追記)
まだまだランキング上位はほど遠いが、ここで筆者の行っているEDAの1つについて紹介する。基本的なことであるが、feature同士の相関の時系列推移を観察することだ(読者の方でもこれを確認済みの方は多いかもしれない)。このEDAで筆者が工夫した点は、training_dataではなくtournament_dataのtestデータを観察したことである。Numeraiのフォーラムを読み込んだ人はご存知かと思うが、tournament_dataのtestデータであるERA854~899(週次)はValidation2のERA197~206(月次)にほぼほぼ対応している。さらにこのデータは実際のトーナメントのROUND168~ROUND204にほぼほぼ対応している。これは即ち2020年4月以前の40週でありコロナショックの期間を含んでいる。
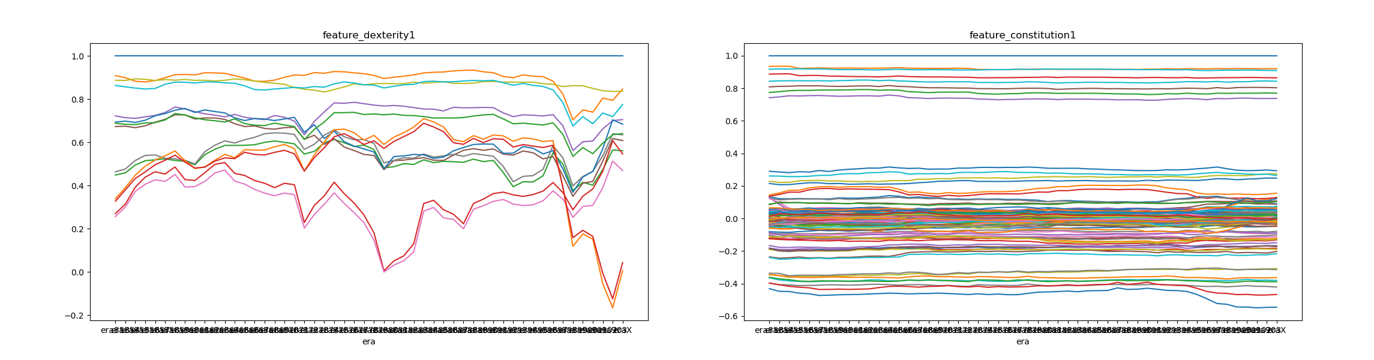
以下のグラフは、ERA853~ERA904(週次)におけるdexterity1とその他のdexterityの相関推移(左図)、およびconstitution1とその他のconstitutionの相関推移(右図)である。
お分かりになるだろうが、dexterity相関の右端部分で相関係数が大きく下落する。この部分がコロナショックである。後述するが、dexterityはつまり価格の騰落系の指標であり、計算期間(1W、4W、52W等)と計算方法(単純な騰落率や移動平均乖離率等)の組み合わせで14個の指標が構成されている。
また互いの相関が大きく変動するdexterityとは異なり、constitutionは殆ど一定の相関推移となっている。constitutionはほぼ間違いなく銘柄の属性を表す指標である(財務諸表やセクター、リージョンなど)。コロナショックの部分でわずかに上下にドリフトする指標があるが、これはPERやPBRなど価格が織り込まれる財務指標である。
これらのデータを受けて、説明力が大きくcorrelationを伸ばす上でカギとなるdexterityについて、実際の市場データで再現ができないか試みた。世界中の銘柄を考慮するのは手間が掛かるので、ここではS&P500銘柄を対象とした。下図が騰落系の指標の互いの相関推移である。feature1~4はそれぞれ1W、4W、12W、52Wの騰落率である。局所的に上図のdexterity相関と類似形状が現れることが分かる。
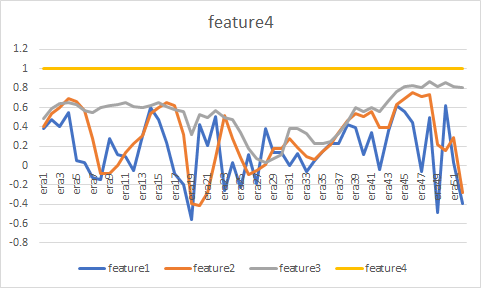
次にこれらの再現指標とdexterityについて、リターンのバランスカーブを比較した。結論としてバランスカーブが酷似していることから、特に説明力の大きいdexterity4およびdexterity7はほぼ間違いなく52W(もしくはそれに準ずる期間)の騰落系指標だと考えている。
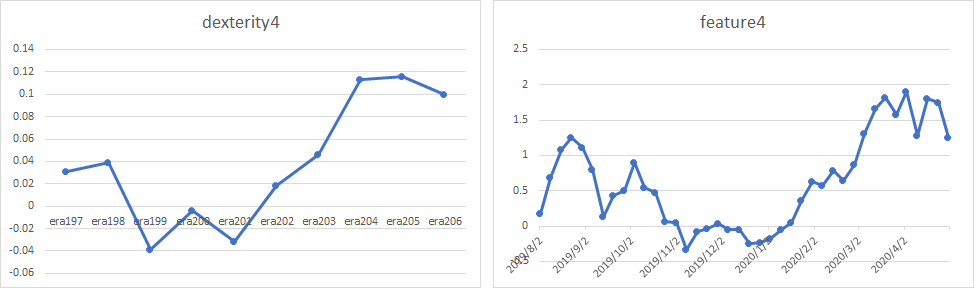
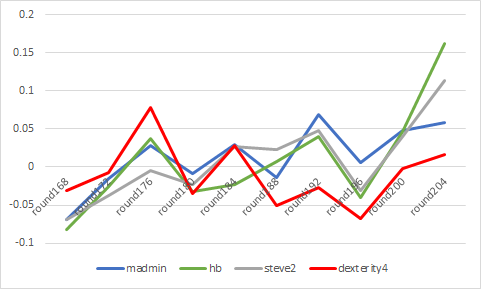
さらに、ランク上位のユーザーはdexterity4の恩恵を大きく受けている。以下は、ランク上位のmadmin氏、hb氏、steve2氏のRound Correlation推移とdexterity4のCorrelation推移の比較である。
さて、問題はこのdexterityが通年で本当にロバストな指標かどうかである。今回の検証の最後に、S&P500銘柄について騰落率の指標を用いて銘柄選定した場合にどのような挙動となるか、2010年以降の期間について確認した。結論として(当然ではあるが)長期の騰落率にベットするだけでは、十分なパフォーマンスを得ることは難しい。dexterity4は非常に優秀な指標に見えるが、validation2の期間は実は下図の赤枠部分だけなのである。
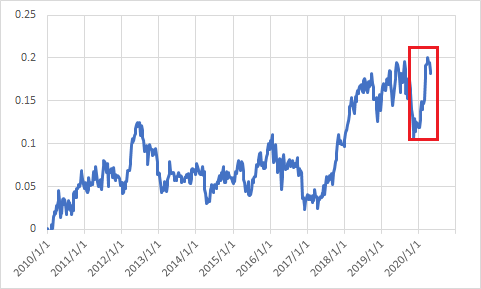
この検証から、やはり週次で安定したモデルを作ることは非常に難しい課題だと考えている。これをブレイクスルーするために試験的なモデルをROUND211で投入してみた。挙動確認用のモデルであり結果はあまり期待していない。
(2020/5/29追記)
ROUND212から投入したモニター用のモデルがやたらと強いというコメントを頂いたので説明しておく。UKI_MONITOR1はモデルを提出してからまだまだ日が浅いのだが、確かに直近のパフォーマンスは優れているようだ(下図)。
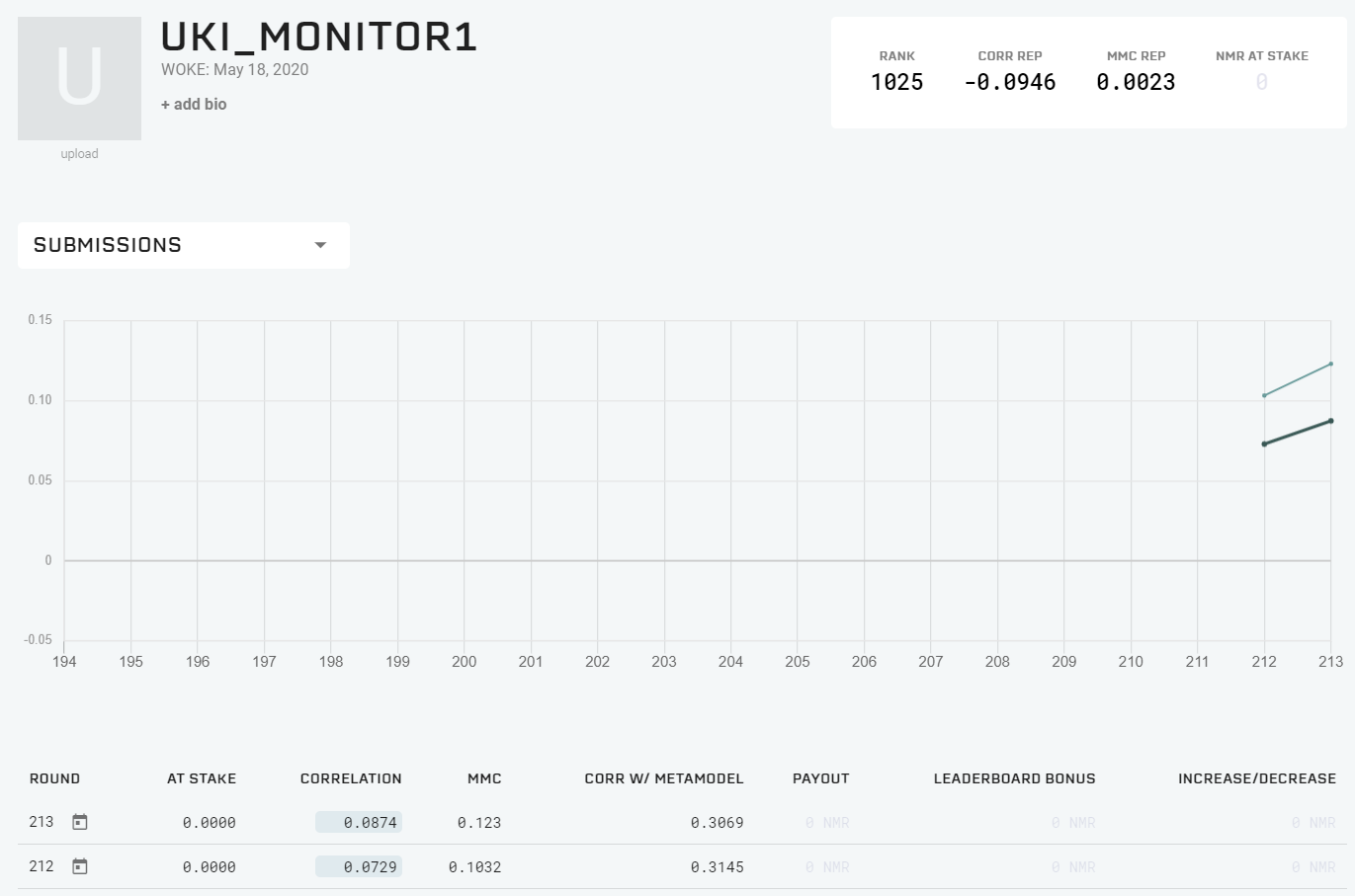
結論から言うと、UKI_MONITOR1は単なるdexterity7である(ただしマイナスを乗じている)。コードは以下の通り。これを値が0.4~0.6になるようにスケーリングしているだけである。
tournament_data["prediction"] = -tournament_data["feature_dexterity7"]
何故このようなことをしたかというと、dexterity7(もしくはdexterity4)は全ての特徴量の中で最もhigh-varianceであり、モデルの予測性能(つまりCorrelation)をブーストするために必要不可欠だからである。ただしこの指標はtime-dependencyが大きく、単純にモデルに取り込むことはリスクが高いため、ひとまず挙動をウォッチすることに決めた。直近で高い予測性能を実現しているユーザーはdexterity7の恩恵を受けているが、いずれその性能を大きく損なう可能性が高いと考えている。そんな時、要因切り分けのためにこのモニターが役に立つはずだ。
本音を言うと310の特徴量全てについてこのモニターを作ろうかと思ったが、さすがにそれは運営にも迷惑が掛かるし大人気がないので思い留まった。読者の皆様も常識の範囲内の数量でモニターを作ってみることをお勧めする。
おわりに
いかがだろうか。
本記事ではNumeraiの概要、トーナメント、報酬体系、そしてデータセットについて説明した。NumeraiのデータセットはファイナンスM/L専門のアドバイザーに監修されており、ファイナンスM/Lを実践的に学ぶ上でKaggleを超える絶好の題材となっている。さらに十分な報酬も用意されている。ファイナンスM/Lに携わる者のバトルフィールドはここにある。
さあ、君もはじめようNumerai。