はじめまして、Newspicksでエンジニアしています、Hoàngです。
新卒で入社し、現在はNewspicksを支えるデータ分析基盤を作っています。そのノウハウをシェアできればと思い、この記事を書きました。
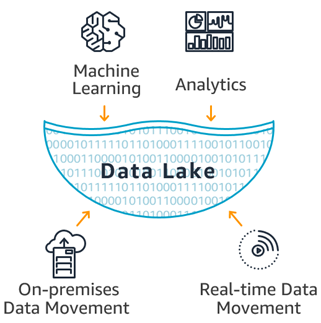
なぜData lakeが必要なのか?
(AWSより引用)
サービスに機械学習、AIを導入したい思ったことがありますでしょうか。あるいは、ユーザーがどのようにサービスを利用しているかを分析したいと思ったことがありますか。
ユーザ分析や機械学習をするために本番のデータベースにアクセスしたり、クエリを投げたりしてはいけません。分析、機械学習の用途で本番サービスに負荷を与えると、最悪の場合本番サービスを停止させてしまうこともあります。本番データと完全に同期されたデータ基盤があれば、このような問題にも対処できます。
また、データ分析はSQLを使うのですが、SQLではDynamoDB, MongoDBといったNoSQL系にクエリを発行することができません。NoSQLのデータもSQLから分析できるようにするためには、CSV や Parquet等のフォーマットに変換する必要があります。Data lake を導入することで、こういった変換済みのデータが蓄積され、SQLでNoSQLのデータの分析もできるようになります。
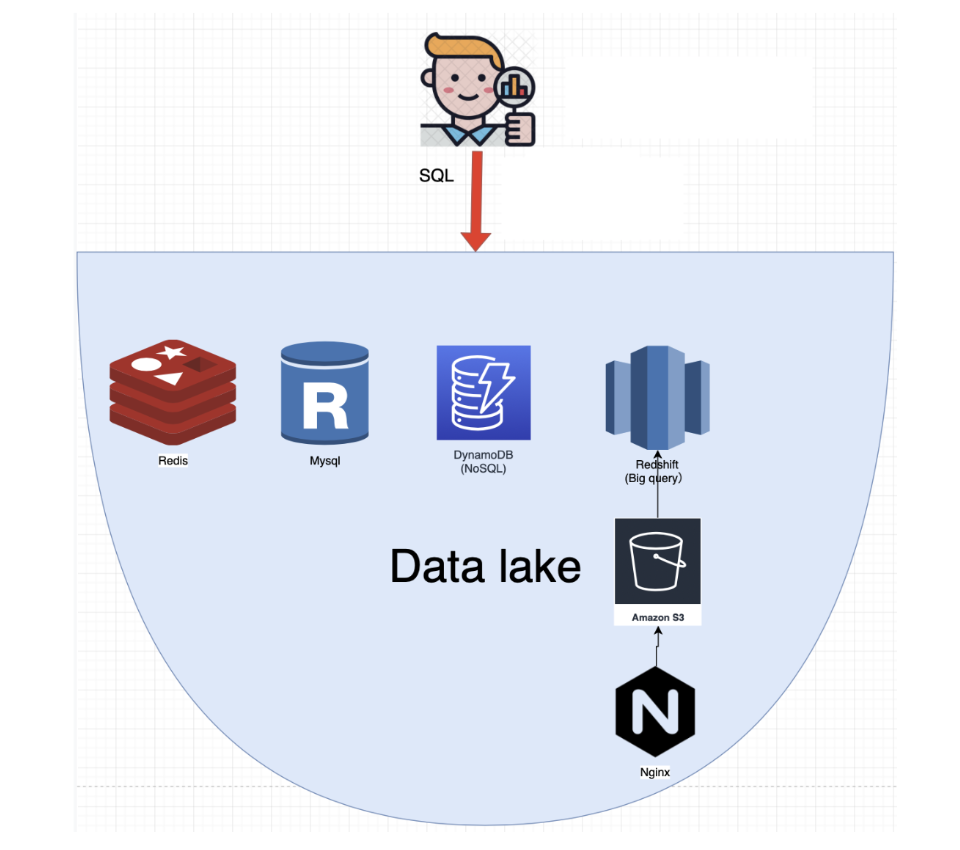
1. データレイク(Datalake)とは何か?
データレイクとは「データの湖」の意味で、ありとあらゆるデータを格納する場所です。従来のデータ格納場所といえば、DatawareHouseがありますが、データレイクは、データウェアハウスに無いくつかの利点があります。
データレイクでは、RDMSからのデータだけではなく、MongoDb, DynamoDBなどのNoSQLデータベースのデータも格納できます。それだけでなく、インメモリデータベース、Redisもデータレイクに格納することができます。
サービスを運用する上でユーザーを分析し、サービスの質を上げなければユーザーを増やせません。ユーザー情報、操作ログ等は、様々なデータソースに分散されている場合が多いです。データを一箇所に集約することで、非常に分析しやすくなり、かつ、分析の精度も上がります。
こういった背景から、データレイクの存在がますます重要になります。
2. データソース
データレイクに取り込まれるデータの種類が様々あります。様々なデータソースをData lakeに取り込むことで分析が充実しますので、それぞれのデータソースの取り込む方法を書いていきます。
1. リレーショナルデータベース(RDMS)
ユーザ情報などが格納されるデータベーです。RDMSのデータをCSVかParquetに変換して、データウェアハウスに格納するのが一般的です。
2. NoSQL
NoSQLは非常に扱いにくく、分析に向いていないデータベースです。例えば、MongoDB、DynamoDB、Redisです。NoSQLにデータウェアハウスで分析するには、NoSQLのデータをJsonで書き出しCSV、Parquetに変換してデータウェアハウスに入れて初めて分析できます。
3. Access log
Accessログは、ユーザの操作を記録するためのもので、Fluentdのアクセスログはテキストでできており、データウェアハウスにCopyするときに、スキーマを指定する必要があります。
3. データレイクのデータ保存場所
データレイクには膨大なデータを格納するため、安全で安価なデータ保存場所が必要です。データストレージを自社サーバで運用するサービスがあまり見られません。ほとんどのサービスがAWSのS3を使ってデータの保存を行なっています。例えば、NetflixもデータレイクのデータをS3においてデータ基盤を構築しています。ZOZO TechnologyもデータをS3においてBigqueryから分析を行っています。
今の段階では、AWS S3がデータレイクの保存場所としては一番最適なのではないかと考えています。
4. データ集計処理の基盤環境
従来のデータ基盤は、あるホストサーバでCronでバッチの実行を管理していると思いますが、この方法で様々課題があり、オススメしません。例えば、依存関係が担保されることがデータ基盤の命なのですが、Cronは依存関係を担保できません。前のJobが失敗すると、後続のJobが実行させないでエラーを通知することが必要ですが、Cronではこの操作ができません。
現在、モダーンなデータ基盤管理ツールといえば、Fluentdを開発しているTreasure Data社のDigdagが有名です。DigDagを使うとJobの依存関係を担保できますが、自サーバを管理する必要があります。
筆者としては、サーバ運用コストを減らしたいので、サーバレスなサービスがないかを調査しました。ちょうどサーバレスでデータ基盤を構築するサービスが、AWSにありました。AWS Glueです。AWS Glue作成する上でのコツ、ハマりポイントなどを後日の記事にて説明したいと思います。
AWS Glueとは?
AWS Glueは、サーバレスでデータ基盤を構築できるAWS サービスです。自サーバを管理する必要なく、ETL処理のスクリプトのみ作成すればいいのです。Cronでできなかった、Jobの前後依存関係も簡単に担保できます。
5. データレイクの分析基盤
データレイクにデータを集める方法を述べてきましたが、データを分析しなければ意味がありません。
データを分析するツールとして有名なのは、AWSのRedshiftと、Google Cloud Platfrom(GCP)のBigqueryがあります。それぞれの比較を行いますが、オススメはRedshiftとRedshift Spectrumの組み合わせです。
なぜRedshift & Redshift Spectrumを組み合わせるのか
Redshiftはデータウェアハウスとして分析結果を非常に早く返せます。おそらく、Bigqueryより速いです。定常分析、例えば、DAUのように毎時、毎日実行される分析がある場合は、Redshiftを持っておいたほうがいいかと思います。しかし、Redshiftに格納できるデータ量がノード数に依存するので、Redshiftのデータが溢れるとノードを増やさないといけないというデメリットがあります。ノード数が10個で毎月約80万円かかり、非常に高価です。そこにRedshift Spectrumを組み合わせるとコスト削減できます。Redshift spectrumはS3上にあるデータを直接アクセスできてRedshift上のデータとジョインして分析できます。