はじめに
皆様初めまして。今回はプログラミングスクールAidemyでデータ分析を学んだ初心者がカリフォルニアの住宅価格の予測を行いました。
住宅価格を題材にしたのは、気になった物件の家賃や値段を調べるのが好きで海外の住宅の値段に興味を持ったからです。
環境
Windows10
Python 3.10.12
Google Colaboratory
データの準備
まず初めにライブラリとデータセットをダウンロードします。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
次にデータを変数に格納し、データの中身を確認します。その後データフレームへ変換します。
#データを変数に格納
data_housing = fetch_california_housing()
#データの中身を確認
print(data_housing.DESCR)
#データフレームに変換
real_estate = pd.DataFrame(data_housing.data, columns=data_housing.feature_names)
データの中身を確認出来ましたが長文のため要約します。
・インスタンスの数 20640
・属性の数 属性(特微量)は8つ。ターゲット(目的変数)は1つ。
・それぞれの属性とターゲットの説明
MedInc ブロックグループの収入の中央値
HouseAge ブロックグループの築年数の中央値
AveRooms 世帯ごとの平均部屋数
AveBedrms 世帯ごとの平均ベッドルーム数
Population ブロックグループの人口
AveOccup 世帯ごとの平均世帯人数
Latitude ブロックグループの緯度
Longitude ブロックグループの経度
このデータセットは1990年のものになっています。1つの行が1つのブロックグループに対応しています。ブロックグループはサンプルデータを公開する最小の地理単位であり、600から3,000人の人口を持っています。
目的変数は住宅の中央価格になります。単位は100,000ドル。例えば目的変数の数字が2だった場合、価格は200,000ドルになります。
欠損値はなし。
次に目的変数を取得し、確認。データフレームに追加し特微量の列名を確認します。
# 目的変数(住宅価格の中央値)を取得
target = data_housing.target
# 目的変数を表示
print("目的変数",target)
#目的変数をPriceとしてデータフレームに追加
real_estate["Price"] = data_housing.target
#特微量の列名の表示
print("列名",real_estate.columns.values)
#先頭の5つを表示
print(real_estate.head())
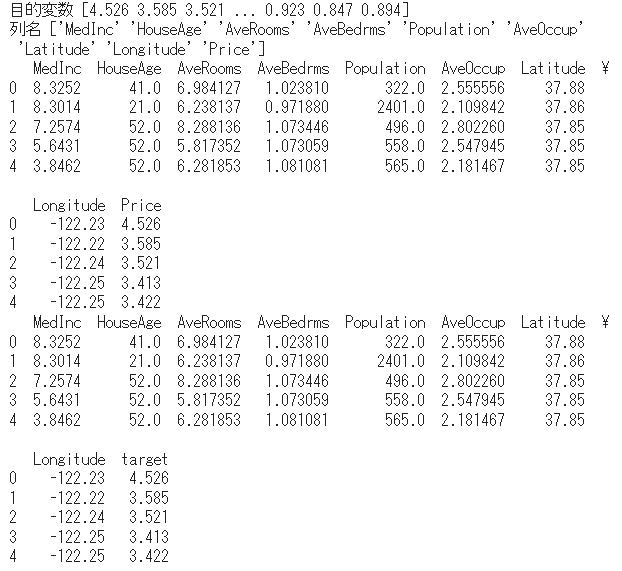
目的変数が追加されている事が確認できました。
次にこのデータセットには欠損値はないとなっていましたが間違いがないように改めて確認します。
real_estate.isnull().sum()

欠損値はありませんでした。
データの基本情報の確認と平均値や標準偏差などの統計的な概要を確認します。
#基本情報の確認
print(real_estate.info())
#データの統計的な概要を確認
print(real_estate.describe())

データの特徴の確認
それぞれの特微量をヒストグラムで確認します。ヒストグラムのビン数はスタージェスの公式を使用。計算式は1+Log(2n)を使用。底が2を使用したのはデータ数が多い時は2を使用した方が良い結果が出やすいため。ビン数は16。
plt.figure(figsize=(15, 10))
for i, column in enumerate(real_estate.columns):
plt.subplot(3, 3, i+1) # 3x3のサブプロット
sns.histplot(real_estate[column], bins=16, kde=False, color='skyblue')
plt.title(f"{column}")
plt.tight_layout() # レイアウトの調整
plt.show()

MedInc(中央収入)は2~4の間(収入の単位は10,000ドル)が多いが一部10を超えるブロックがあり最大だと14を超えています。。予想ですが、カリフォルニア州にはハリウッドスターやミリオネア(資産を100万ドル以上持っている人)が住んでいる高級住宅地ビバリーヒルズがあります。他にもあの映画で有名なハリウッドもカリフォルニア州にあります。その一部の地域の人たちが中央収入の10以上になっているものと思われます。数値が10以上の数を出して見ます。
# MedIncが10以上の行だけを抽出
count = real_estate[real_estate['MedInc'] >= 10]
# 10以上の数値の出現回数の合計を計算
count10over = count['MedInc'].value_counts().sum()
print("10以上の数値の出現回数の合計:", count10over)

20640に対して309と非常に少ない数になっています。今回はこのまま価格予測のデータとして使用していきます。余談ですが、ビバリーヒルズにはビバリーウィルシャーという映画「プリティーウーマン」で登場した1泊10万円以上する5つ星ホテルがあります!いつか泊まってみたいですね(^^)
次に相関関係を確認するためにヒートマップを確認します。
sns.heatmap(
real_estate.corr(),
vmax=1,vmin=-1,annot=True
)

ヒートマップは色が明るいもしくは暗くなれば相関が強くなります。明るい色は正の相関、暗い色は負の相関になります。ヒートマップ上にわかりやすく相関の数字を付け加えています。これをみると
・MedInc(収入の中央値)とPrice(住宅価格の中央値)
・AveRooms(世帯ごとの平均部屋数)とAveBedrms(世帯ごとの平均ベッドルーム数)
・Latitude(ブロックグループの緯度)とLongitude(ブロックグループの経度)
この3つが相関が強くなっています。このうち
・MedIncとPrice
・LatitudeとLongitude
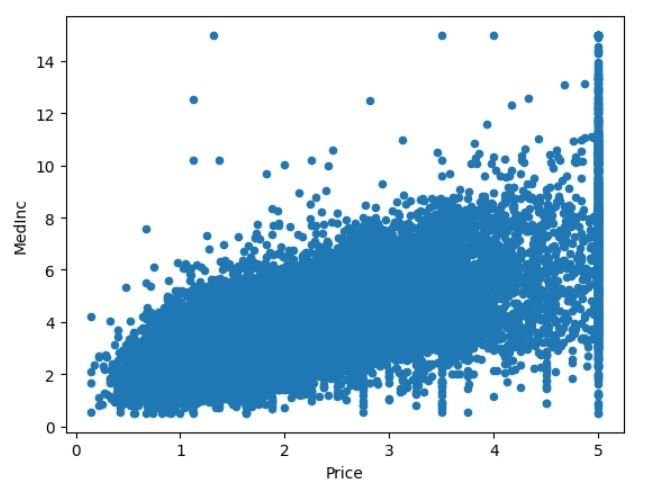
上記2つの相関を散布図で確認します。
#相関関係の強いLatitudeとLongitudeの散布図を作成。
real_estate.plot.scatter(x='Latitude',y='Longitude')
#相関関係の強いMedlncとPriceの散布図を作成
real_estate.plot.scatter(x='Price',y='MedInc')

他に相関は弱かったが個人的に気になった
・HouseAg(ブロックグループの築年数の中央値)とMedInc
・HouseAgeとPrice
この2つも散布図で確認してみます。
#相関関係は弱いが個人的に相関すると考えたHouseAgとMedIncの散布図を作成
real_estate.plot.scatter(x='HouseAge',y='MedInc')
#相関関係は弱いが個人的に相関すると考えたHouseAgeとPriceの散布図を作成
real_estate.plot.scatter(x='Price',y='HouseAge')
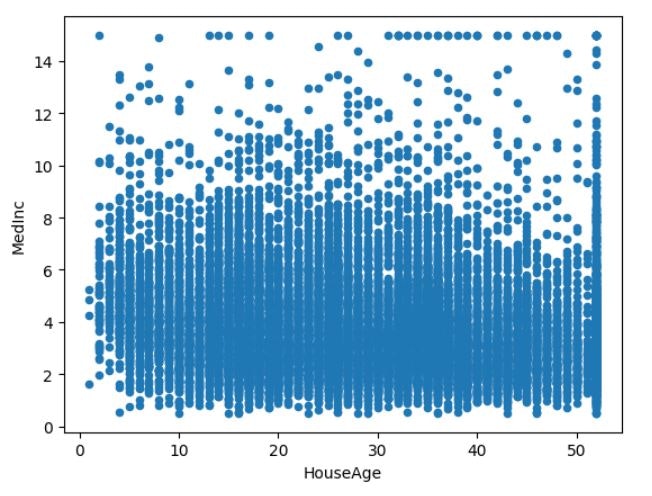
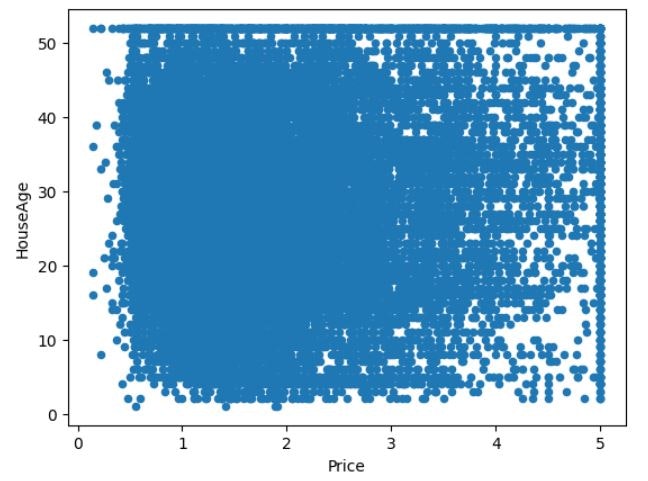
それぞれの相関図を見ると相関関係が強いものは点が寄っていますが相関関係が弱いと点はバラける事がわかりました。今後散布図を見る時に一目で相関関係があるかわかるようになりました。
散布図を見るとMedInc(中央収入)が高いとPrice(住宅価格の中央値)も高くなります。これは販売するターゲット層が富裕層になっているので当然の結果だと考えられます。ただ、築年数が新しい、古いに関わらずPriceの値段はバラけています。これは築年数が古くても家の価値は下がらない事になります。これについて調べた所、アメリカは土地の利用や建築の法律が厳しく新しい住宅が増えにくく、地震がほとんどないため豊富な木材を使用して耐久性の高い木造住宅が建てられます。長く(80年~100年)住めると考えられており、さらにそこから住んでいる住宅を自分でリノベーションやメンテナンスをして資産としての価値を高めていき売買の値段を上げていこうと考える文化でした。日本では築年数が古くなると安くなるイメージだったのでとても面白い情報でした。今後データ分析を活かしていく際にその国や土地の文化を調べる事が大事だと学ぶことが出来ました。
機械学習での価格予測とスコアの算出
ここから機械学習を始めます。今回は
・線形重回帰
・ラッソ回帰
・リッジ回帰
・ElasticNet回帰
・ランダムフォレスト
・LightGBM
上記6つで予測を行います。
#線形重回帰
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X, y = data_housing.data, data_housing.target
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=100)
model = LinearRegression()
model.fit(train_X, train_y)
pred_y = model.predict(test_X)
# 線形重回帰で予測結果を出力します
print("線形重回帰の価格予測",pred_y[:10])
#モデルの評価
score = model.score(test_X ,test_y)
print("スコア",score)
#ラッソ回帰
from sklearn.linear_model import Lasso
model = Lasso()
model.fit(train_X,train_y)
pred_y = model.predict(test_X)
# ラッソ回帰で予測結果を出力します
print("ラッソ回帰",pred_y)
#モデルの評価
score = model.score(test_X ,test_y)
print("スコア",score)
#リッジ回帰で機械学習
from sklearn.linear_model import Ridge
model = Ridge()
model.fit(train_X, train_y)
pred_y = model.predict(test_X)
# リッジ回帰で予測結果の出力
print("リッジ回帰",pred_y)
#モデルの評価
score = model.score(test_X ,test_y)
print("スコア",score)
#ElasticNet回帰
from sklearn.linear_model import ElasticNet
model = ElasticNet()
model.fit(train_X, train_y)
pred_y = model.predict(test_X)
# ElasticNet回帰で予測結果を出力します
print("ElasticNet回帰",pred_y)
#モデルの評価
score = model.score(test_X ,test_y)
print("スコア",score)
#ランダムフォレスト
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state = 42)
model.fit(train_X, train_y)
pred_y = model.predict(test_X)
# ランダムフォレストで予測結果を出力します
print("ランダムフォレスト",pred_y)
#モデルの評価
score = model.score(test_X ,test_y)
print("スコア",score)
#LightGBM
import lightgbm as lgb
model = lgb.LGBMRegressor(n_estimators=100, random_state=42)
model.fit(train_X, train_y)
pred_y = model.predict(test_X)
# LightGBMで予測結果を出力します
print("LightGBM",pred_y)
#モデルの評価
score = model.score(test_X ,test_y)
print("スコア",score)
それぞれの結果を載せます。

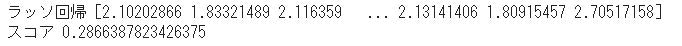
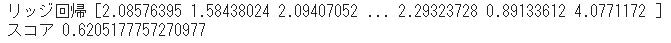
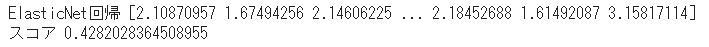


今回はLightGBMの予測結果が一番良いという結果になりました。ランダムフォレストも良い結果が出ましたがLightGBMの結果の出るスピードがかなり速くLightGBMが優秀な学習方法だと考えています。
まとめ
カリフォルニアの住宅価格を予測しました。初めて自分で分析まで行いました。エラーが頻発しどうれば良いかわからない事も多かったですが、エラーが解決し結果が見えてくる作業が楽しかったです。今回はデータのクレンジング等の前処理がほぼないデータだったので次は前処理を行うデータを使用して分析を行ってみたいと思います。
長くなりましたが最後までご覧頂きありがとうございました。
※「このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています」