はじめに
SENSY株式会社、bitchalです。
普段は主にN.N.を使って色々な類のアイテムレコメンドの研究や、自然言語(主に日本語)をRNN等で処理し、文章の分類タスク、文章生成の研究などをしています。
AIに関わっている身としては、会話できる(したくなる)AIをつくりたい!、という野望があります。
会話できるAI、と一言でいっても難しいです。普段使っている言葉なのに、いざ設計を考えると、(当たり前ですが、)難しいです。深層学習に頼る場合、どういう問題を何の情報からどういうふうに学習するかを設計する必要があり、これを改善していくためには、かなり試行錯誤が必要です。さらに、自然言語の(正しい)データセットの収集、学習後に出力されるテキストなどの結果の正当性の確認には、かなりの人力を要し、輪をかけて改善作業が難しくなります。
設計が難しいなら、、、
そうだ、強化学習してみよう
前々から興味があった強化学習を勉強して、自然言語の分野でどんな応用ができるかを検討してみたいと思い立ちましたので、早速やってみます。
モデルについて
今回取り組むのは、DQN(Deep Q-Learning)というモデルです。
強化学習では、各時点の状況下で取り得る行動から何かを選択し、最終的に得られた結果に対して報酬を得ます。その報酬をもとに各時点の状況下でとった行動を評価し、取るべき行動を学習していく、という半教師学習になります。
DQNは以下のような特徴があります。
- MDP(Markov Decision Process)モデルから改善され、各時点の状況下で取り得る次の状況を全て把握する必要がない
- Q-Learningモデルを踏襲し、各時点の状況でとり得る行動を、(とりあえず)試して、環境を自ら知る
- ある時点の状況でどういう行動をしたらどんな報酬が得られるかを、得られた報酬を教師データとして、N.N.により近似する
- さらに、学習を進めるために、以下のような工夫がある
- 一度経験した、報酬、行動、遷移先、報酬をメモリに保存し、学習時にそれをランダムサンプリングすることで、時系列をバラバラにして、時系列間の相関をなくす
- N.N.の学習によって、教師データである報酬が変化することを防ぐ
- 報酬を固定することで、学習を進みやすくする(結果にたいして重みをつけない)
実践
強化学習は今や新しいものではないので、多くのコードがあります。今回は、理論と実装をみながら、理解を深めることを目的に、その一つを参考にさせていただきました。
ただ、コピペして動かしても面白くないので、N.N.の学習部分を、(こちらも勉強中の)XGBoostに置き換えてみます。
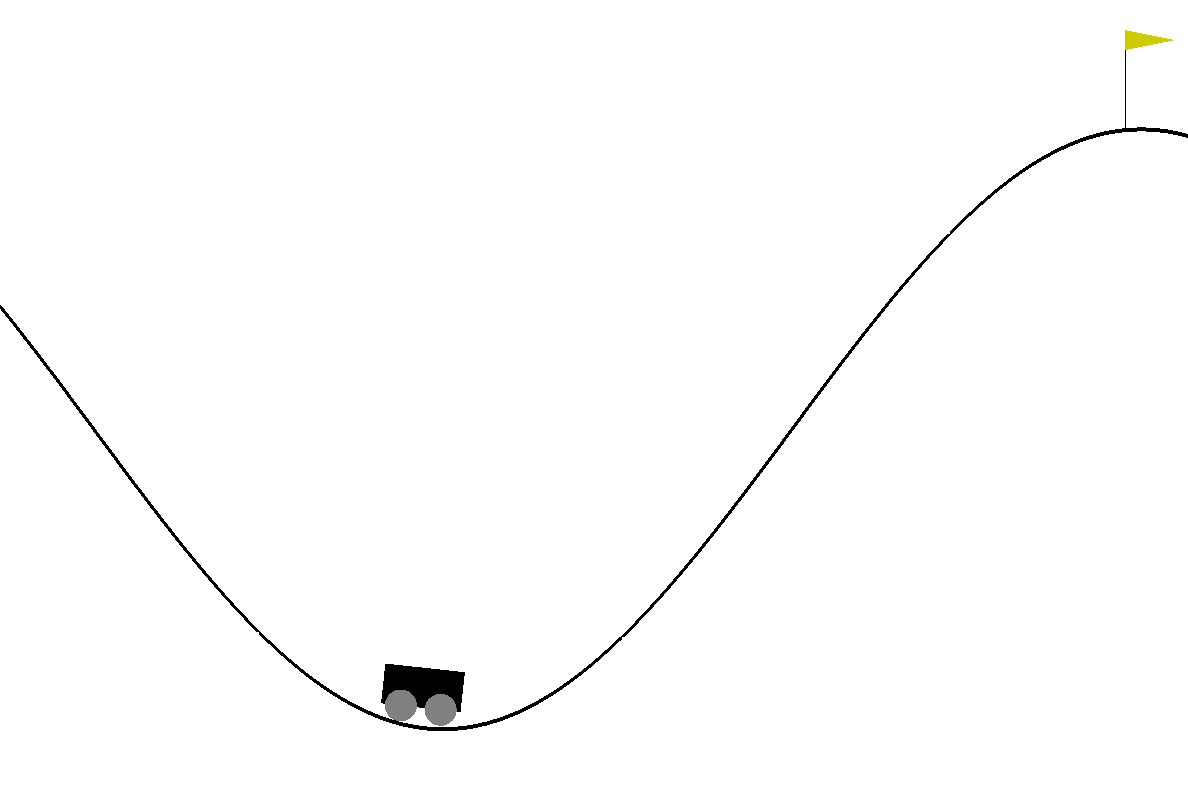
- タスク
今回はOpen AIというシミュレーションプラットフォームで公開されている、MountainCar-v0というタスクを行います。
コード
import time
import gym
import numpy as np
import random
import xgboost as xgb
from collections import deque
class DQN:
def __init__(self, env):
self.env = env
self.memory = deque(maxlen=2000)
self.gamma = 0.85
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.005
self.tau = .125
self.model = self.create_model_xgb()
self.target_model = self.create_model_xgb()
def create_model_xgb(self):
dtrain = xgb.DMatrix(np.random.rand(3,2), label=np.array([0,1,2]))
param = {'nthread': 3, 'silent': 1,
'eta': 0.05, 'gamma':5, 'lambda': 10,
'num_class': 3, 'max_depth':2, 'num_boost_round': 1, 'objective': 'multi:softprob',
'verbose': False, 'num_feature': dtrain.num_col(), 'updater': 'refresh','refresh_leaf': True}
booster = xgb.train(param, dtrain, 1, verbose_eval=False)
return booster
def act(self, state):
self.epsilon *= self.epsilon_decay
self.epsilon = max(self.epsilon_min, self.epsilon)
if np.random.random() < self.epsilon:
return self.env.action_space.sample()
predicted_action = self.model.predict(xgb.DMatrix(state))[0]
return random.choice(np.where(predicted_action == predicted_action.max())[0]) # 複数ありえる
def remember(self, state, action, reward, new_state, done):
self.memory.append([state, action, reward, new_state, done])
def replay(self):
timelog = time.time()
batch_size = 32
if len(self.memory) < batch_size:
return
samples = random.sample(self.memory, batch_size) # 過去のいずれかの状態を取得
for sample in samples:
state, action, reward, new_state, done = sample
target = self.target_model.predict(xgb.DMatrix(state))
if done:
target[0][action] = reward
else:
Q_future = max(self.target_model.predict(xgb.DMatrix(new_state))[0])
target[0][action] = reward + Q_future * self.gamma
dtrain = xgb.DMatrix(state, label=np.array([random.choice(np.where(target[0] == target[0].max())[0])]))
self.model.update(dtrain, 1)
def copy_target(self):
self.target_model = self.model.copy()
def save_model(self, fn):
self.model.save(fn)
if __name__ == "__main__":
env = gym.make("MountainCar-v0")
gamma = 0.9
epsilon = .95
trials = 1000
trial_len = 500
dqn_agent = DQN(env=env)
steps = []
timelog = time.time()
for trial in range(trials):
cur_state = env.reset().reshape(1,2)
for step in range(trial_len):
action = dqn_agent.act(cur_state)
env.render() # シミュレータ動かす
new_state, reward, done, _ = env.step(action)
new_state = new_state.reshape(1,2)
dqn_agent.remember(cur_state, action, reward, new_state, done)
dqn_agent.replay() # internally iterates default (prediction) model
dqn_agent.copy_target() # copy target
cur_state = new_state
if done:
print("success")
break
env.render(close=True) #シミュレータを閉じる
if step >= 199: # 終了条件
print("trial: {}, step: {} failed. duration: {}".format(trial, step, time.time() - timelog)); timelog = time.time()
continue
実行結果
今回は会社に沢山あるGPUマシンを使わずにMacBookのCPUで行いました。単純なタスクのわりに実行に時間がかかり、クリアはできませんでした。。。
主な原因としては、XGBのモデルが再学習毎に所要時間が増えているためですが、現在調査中になります。
また、そもそもxgbで解くことに理論的な問題がないかも検証する必要はありそうです。
強化学習への感想
- 面白い、シミュレーションをずっと見ていられる、が時間の無駄
- デバッグが難しい。そもそも学習できているのかいないのか分からないので、ちゃんと理論を理解して実装していくのがいい
まとめ
自然言語処理との関係で、ざっくりしていますが、こんなことができないかなと思いました。
文章生成のモデルに強化学習の仕組みを組み込むと同時に、(高い精度で)日本語として意味がとおる文章かどうかを判定する判定器を通して、意味の通じない文章が生成されないように学習する。
もっと理解を深めて、どんな分野で使えるかを考えていきたいと思います。
参考記事
強化学習を勉強をさせていただきました。
ゼロからDeepまで学ぶ強化学習
強化学習のコードを参考にさせていただきました。
[Reinforcement Learning w/ Keras + OpenAI: DQNs]
(https://https://towardsdatascience.com/reinforcement-learning-w-keras-openai-dqns-1eed3a5338c)