AIエージェントシリーズ 第5弾|プランニングAgent——大きなPRを自動分解して実行する
はじめに
第1弾でReActループを作り、第2弾でToolを使い分け、第3弾でMCPを通じてGitHubと繋いだ。Agentはだいぶ「動けるもの」になってきた。
しかし、現実のPRは5ファイル・500行を超えることも珍しくない。ReActのように「コードを読む→コメントする」を1ファイルずつ繰り返す方式では、ファイルが増えるほど同じような思考ループが積み重なる。無駄が多いし、全体を見渡した一貫したレビューができない。
第5弾では Plan-and-Execute パターンを実装する。PRを受け取ったAgentはまず「どの順番で何を調べるか」の計画を立て、その計画に従って粛々と実行する。計画フェーズと実行フェーズを分離するこのアーキテクチャは、大きなタスクを扱うときのAgentの定番パターンだ。
ReActの課題:ファイルが増えると破綻する
第1弾のReActエージェントは、ファイルを1つ渡すと非常によく機能した。しかしファイルが5つになると何が起きるか。
[ファイル1]
Thought: このコードを読んでみよう
Action: read_code("sample_01.py")
Observation: コードを読んだ
Thought: SQLインジェクションがある
Action: comment("SQLインジェクション脆弱性を修正してください")
[ファイル2]
Thought: このコードを読んでみよう
Action: read_code("sample_02.py")
Observation: コードを読んだ
Thought: ネストが深い
Action: comment("複雑度が高いです")
... × 5ファイル分繰り返し
5ファイルなら10ステップ。10ファイルなら20ステップ。ファイル数に比例してステップ数が増えていく。
さらに問題なのが「一貫性の欠如」だ。ファイル1でSQLインジェクションを見つけ、ファイル4でも同じパターンを見つけたとき、ReActは「これはプロジェクト全体の設計上の問題だ」という判断ができない。各ファイルの処理は独立していて、横断的な知見が活きない。
Plan-and-Execute とは
Plan-and-Execute は名前のとおり「計画→実行」の2フェーズ構成だ。
Phase 1: Planner(計画立案)
└─ PRの内容を把握し、最適な実行計画をJSON形式で生成する
Phase 2: Executor(計画実行)
├─ Step 1: security_check(全ファイル対象)
├─ Step 2: performance_check(全ファイル対象)
├─ Step 3: complexity_check(全ファイル対象)
└─ Step 4: generate_report(結果を統合してレポート生成)
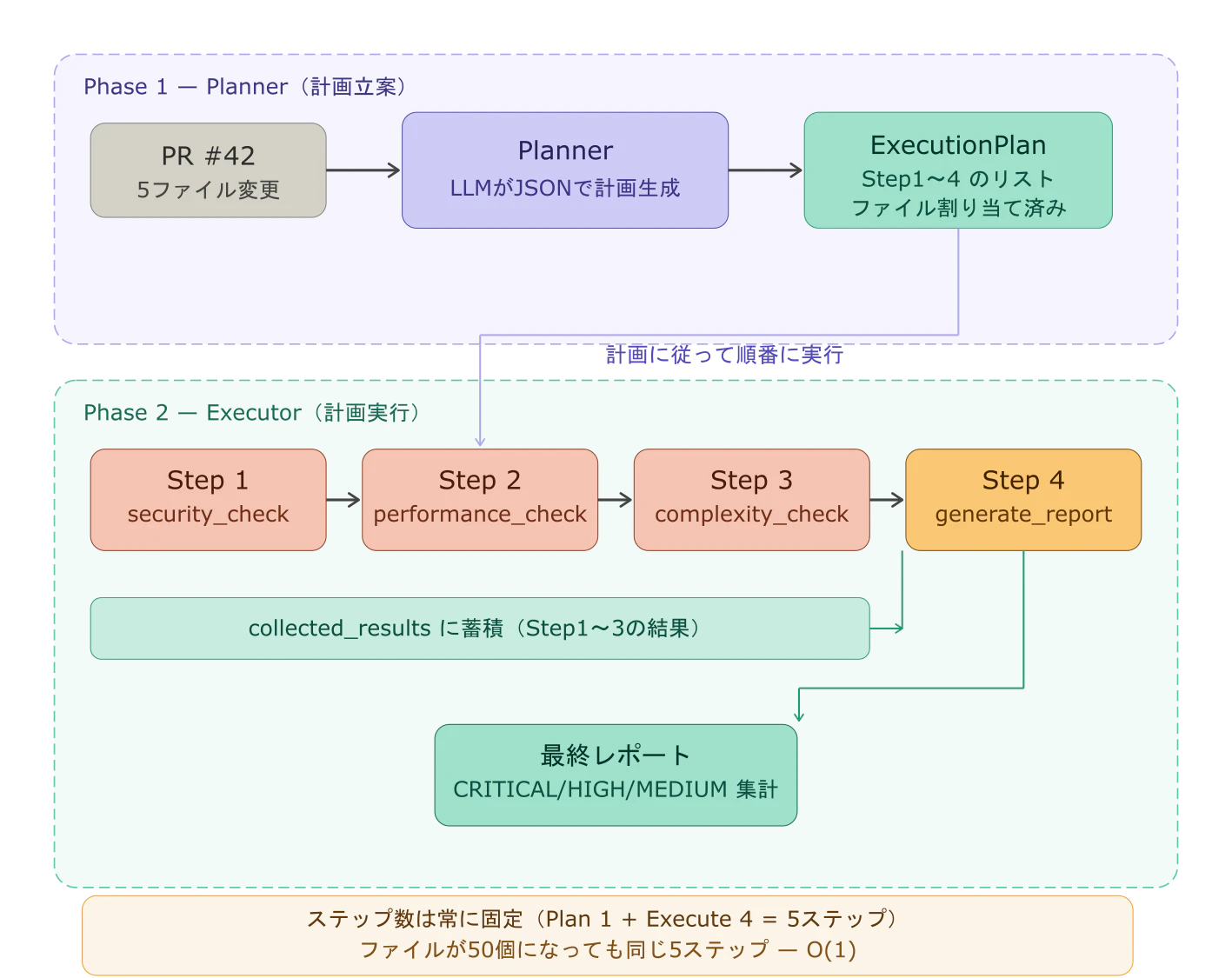
大きな違いは「ファイル数に関係なくステップ数が固定になる」ことだ。セキュリティチェックは全ファイルをまとめて処理する1ステップ。ファイルが50個になっても、ステップ数は変わらない。
そしてもう一つの利点が「全体を見渡した計画」だ。Plannerは最初にPR全体を把握してから計画を立てるため、「このPRはセキュリティとパフォーマンスを重点的に見るべきだ」という判断を最初にできる。
全体アーキテクチャ
planning_agent.py
├── plan() ← Phase 1: LLMがJSONで計画を生成
├── execute() ← Phase 2: 計画に従ってToolを順番に実行
│ ├── security_check()
│ ├── performance_check()
│ ├── complexity_check()
│ └── generate_report()
└── main() ← PR情報を渡してplan→executeを呼ぶ
フレームワークは使わない。Anthropic Python SDK だけで実装する。
実装:データ構造から始める
まずPlanを表すデータクラスを定義する。計画は「ステップのリスト」であり、各ステップは「どのツールを・どのファイルに使うか」を持つ。
@dataclass
class ReviewStep:
step_id: int
name: str
description: str
tool_name: str
target_files: list[str]
status: str = "pending" # pending / running / done / failed
result: str = ""
duration_sec: float = 0.0
@dataclass
class ExecutionPlan:
pr_summary: str
steps: list[ReviewStep] = field(default_factory=list)
total_steps: int = 0
status フィールドがあることで「このステップは今どの状態か」が常に明確になる。実行ログや障害追跡に役立つ。
実装:Phase 1 — Planner
Plannerの役割はシンプルだ。PRの概要とファイル一覧をLLMに渡し、JSONで実行計画を返させる。
def plan(pr_description: str, files: list[str]) -> ExecutionPlan:
prompt = f"""あなたはコードレビューの専門家です。
以下のPRを4ステップでレビューする実行計画をJSONで作成してください。
## PR概要
{pr_description}
## 変更ファイル
{chr(10).join(f" - {f}" for f in files)}
## 出力形式(JSONのみ)
{{
"pr_summary": "PRの1行サマリー",
"steps": [
{{
"step_id": 1,
"name": "ステップ名",
"tool_name": "使用するツール名",
"target_files": ["対象ファイル名"]
}}
]
}}"""
response = client.messages.create(
model=MODEL,
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
plan_data = json.loads(response.content[0].text.strip())
# ... ExecutionPlanに変換して返す
ポイントは「JSONのみを返せ」と明示することだ。LLMは説明文を添えたがる傾向があるため、プロンプトで明確に禁止する。それでも ```json フェンスが含まれることがあるので、正規表現で除去する処理も忘れずに入れる。
if "```" in raw:
raw = re.sub(r"```(?:json)?", "", raw).strip().rstrip("```").strip()
実装:Phase 2 — Executor
Executorは計画に従ってツールを順番に呼ぶ。単純に見えるが「結果の受け渡し」が重要なポイントだ。
def execute(plan: ExecutionPlan) -> dict:
collected_results: dict[str, str] = {}
for step in plan.steps:
if step.tool_name == "generate_report":
# 最終ステップ:これまでの全結果をまとめて渡す
result = execute_tool("generate_report", {
"review_results": json.dumps(collected_results, ensure_ascii=False)
})
else:
# 通常ステップ:ファイルごとにツールを実行し、LLMで解釈
file_results = []
for fname in step.target_files:
code = read_code(fname)
tool_result = execute_tool(step.tool_name, {"filepath": fname})
# LLMに結果を解釈させて改善提案を生成
interp = client.messages.create(...)
file_results.append(...)
collected_results[step.name] = "\n\n".join(file_results)
step.status = "done"
各ステップの結果を collected_results に蓄積し、最後の generate_report ステップにすべて渡す。これがPlan-and-Executeの「全体を見渡したレポート」を実現する仕掛けだ。
ツール実装:静的解析で確実に検出する
ツールは正規表現とASTを使った静的解析で実装する。LLMだけに頼らず、コードを決定論的に解析することで見逃しを防ぐ。
セキュリティチェック(抜粋):
def security_check(filepath: str) -> str:
code = Path(filepath).read_text(encoding="utf-8")
issues = []
# SQLインジェクション:f文字列でSQLを組み立てているパターン
if re.search(r'f["\'].*SELECT.*{', code):
issues.append("🔴 [CRITICAL] SQLインジェクション")
# 平文パスワード:password = "..." のパターン
if re.search(r'password\s*=\s*["\'][^"\']+["\']', code, re.IGNORECASE):
issues.append("🔴 [CRITICAL] 平文パスワード")
return "\n".join(issues) if issues else "✅ 問題なし"
複雑度チェック(AST解析):
def complexity_check(filepath: str) -> str:
tree = ast.parse(code)
# 未使用変数の検出
assigned = {n.id for n in ast.walk(tree)
if isinstance(n, ast.Assign)
for t in n.targets if isinstance(t, ast.Name)}
used = {n.id for n in ast.walk(tree)
if isinstance(n, ast.Name) and not isinstance(n.ctx, ast.Store)}
unused = assigned - used
# ネスト深さの計測
depth = max_depth(tree)
if depth >= 4:
issues.append(f"🟠 [HIGH] ネスト深さ {depth}: 早期リターンを検討")
ASTを使うことで「変数が代入されたが使われていない」という関係を正確に把握できる。文字列マッチングでは難しい分析だ。
実行フロー:シーケンス図
実際のメッセージのやり取りをシーケンス図で示す。
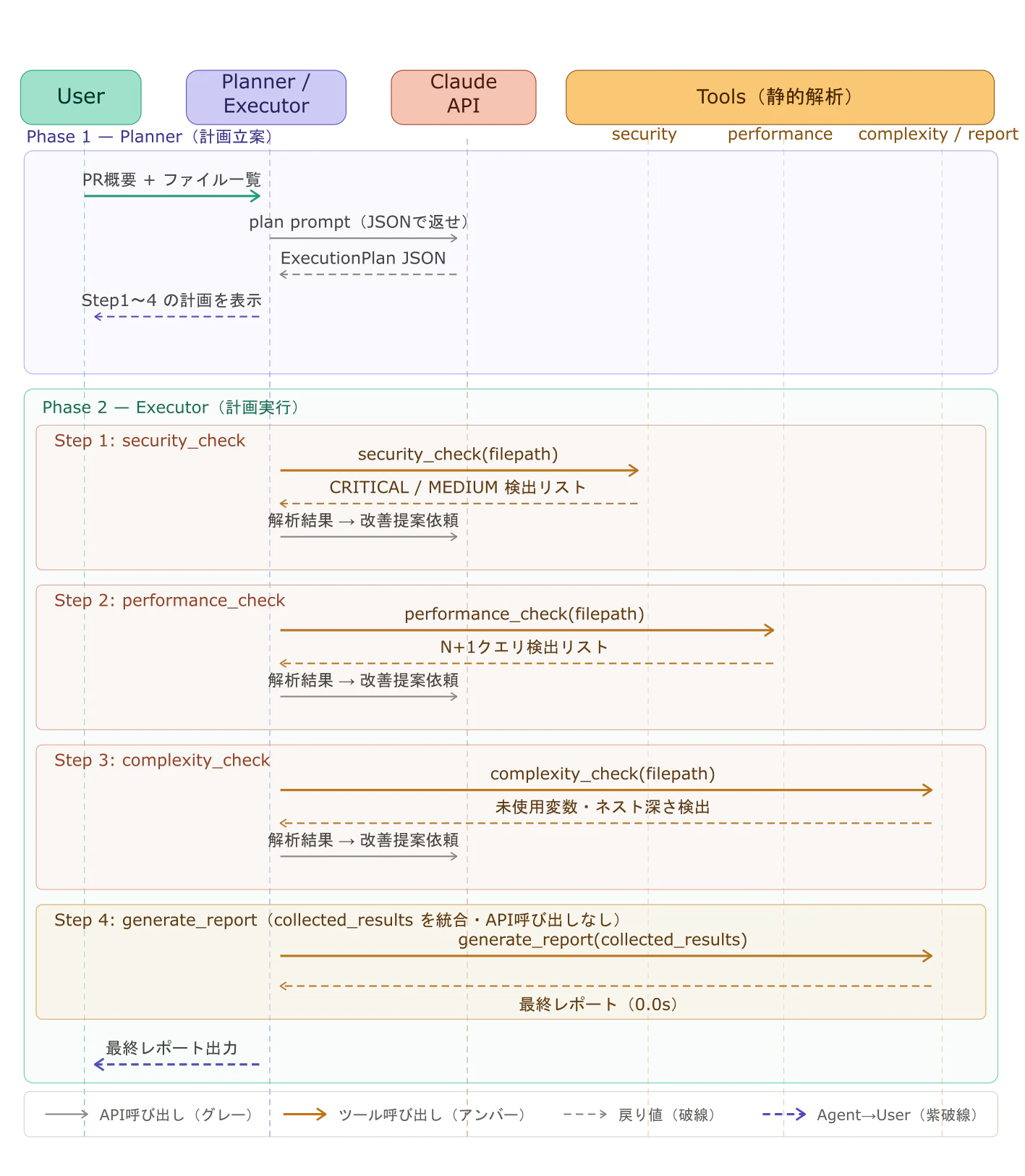
Phase 1では1回のAPI呼び出しで計画全体を生成する。Phase 2ではステップごとに「ツール呼び出し(静的解析)→API呼び出し(改善提案生成)」を繰り返す。最後のgenerate_reportはAPIを呼ばず静的処理のみで完結するため、実行時間が0.0sになる。
実行結果
実際に動かしてみる。
Phase 1:Plannerが計画を生成
============================================================
📋 Phase 1: プランニング
============================================================
PR概要: ユーザー認証・注文管理システムの実装に伴うセキュリティ・パフォーマンス・コード品質の包括的レビュー
生成されたステップ数: 4
Step 1: [security_check] セキュリティ脆弱性検査
Step 2: [performance_check] パフォーマンス問題検査
Step 3: [complexity_check] コード品質・複雑度分析
Step 4: [generate_report] 最終レビューレポート生成
PR概要の文面もLLMが生成している。5ファイル・3つのモジュールを横断するPRを1行でまとめ、4ステップの計画を自動的に立てた。注目すべきはStep 1とStep 2でAgentが対象ファイルを振り分けていることだ。セキュリティ系は sample_01.py と sample_04.py を優先し、パフォーマンス系は sample_05.py を対象に含めている。
Phase 2:Executorが順番に実行
--- Step 1/4: セキュリティ脆弱性検査 ---
ツール: security_check | 対象: ['sample_01.py', 'sample_02.py', 'sample_04.py']
✅ 完了 (12.4s)
--- Step 2/4: パフォーマンス問題検査 ---
ツール: performance_check | 対象: ['sample_02.py', 'sample_03.py', 'sample_05.py']
✅ 完了 (13.5s)
--- Step 3/4: コード品質・複雑度分析 ---
ツール: complexity_check | 対象: ['sample_01.py', 'sample_02.py', 'sample_03.py', 'sample_04.py', 'sample_05.py']
✅ 完了 (20.4s)
--- Step 4/4: 最終レビューレポート生成 ---
✅ 完了 (0.0s)
最終レポート(抜粋)
============================================================
📊 検出サマリー
🔴 CRITICAL : 3 件(即時対応が必要)
🟠 HIGH : 4 件(次スプリントで対応)
🟡 MEDIUM : 5 件(バックログに追加)
============================================================
⚠️ CRITICAL問題があるためこのPRはマージ不可です。
検出内容の一例を示す。sample_01.py に対するセキュリティチェック結果:
🔴 [CRITICAL] SQLインジェクション: f文字列でSQLを動的生成しています
🟡 [MEDIUM] タイミング攻撃: == 演算子でのパスワード比較は脆弱です
💡 改善提案:
# ❌ 危険
query = f"SELECT * FROM users WHERE username = '{username}'"
# ✅ 安全(パラメータ化クエリを使用)
query = "SELECT * FROM users WHERE username = ?"
cursor.execute(query, (username,))
静的解析で問題を確実に検出し、LLMが改善コードを添えて出力する。静的解析だけでは「どう直すか」が弱く、LLMだけでは「見逃し」が発生する。両者を組み合わせることで補完している。
実行統計
総実行時間: 51.0s
実行ステップ数: 4
Step ツール 時間 状態
--------------------------------------------------
1 security_check 12.4s done
2 performance_check 13.5s done
3 complexity_check 20.4s done
4 generate_report 0.0s done
generate_reportが0.0sなのは、静的ツールだけで完結していてAPI呼び出しが不要だからだ。
ReAct vs Plan-and-Execute:定量比較
compare_react_vs_plan.py を実行して実測した。
対象ファイル数: 5 件
📊 ステップ数比較
手法 ステップ数
----------------------------------------
ReAct (第1弾) 10 ステップ
Plan-and-Execute (第5弾) 5 ステップ
----------------------------------------
削減: 5 ステップ (50% 削減)
※ Plan-and-Executeは全ファイルをまとめて処理するため
ファイル数が増えるほど効果が大きくなります
| 指標 | ReAct(第1弾) | Plan-and-Execute(第5弾) |
|---|---|---|
| 実行ステップ数(5ファイル) | 10ステップ | 5ステップ(50%削減) |
| ファイル数依存 | O(n) | O(1)(計画ステップは固定) |
| 横断的分析 | ❌ | ✅(全結果を統合してレポート) |
| 計画の透明性 | ❌(暗黙のループ) | ✅(JSONで可視化) |
| 途中経過の把握 | 難しい | ✅(step.statusで常に把握可能) |
5ファイルで50%削減、10ファイルなら75%削減になる。ファイルが増えるほど効果が大きくなる構造だ。
ただし、短所もある。計画が固定されるため「計画立案時に予測できなかった問題」に動的に対応しにくい。たとえば「security_checkで問題が見つかったから、このファイルをさらに詳しくfuzz_testしよう」という適応的な行動は、純粋なPlan-and-Executeでは難しい。ReActの柔軟性とPlan-and-Executeの効率性はトレードオフの関係にある。
なぜPlan-and-Executeか:設計の背景
ReActが「問いかけながら進む探偵」なら、Plan-and-Executeは「プロジェクト計画を立ててから施工する建築家」だ。
探偵スタイルは未知の問題を解くときに強い。手がかりが見つかるたびに次の行動を変えられる。しかし「今日中にビルを建てる」という決まったゴールがあるときは、計画を立ててから動いた方が圧倒的に効率がいい。
コードレビューは後者に近い。「セキュリティ→パフォーマンス→可読性→レポート」というレビューの型は、どのPRに対しても変わらない。型が決まっているタスクには、計画ベースのアーキテクチャが向いている。
第6弾の予告:Agent Skills設計
第5弾でAgentは「計画を立てて実行する」能力を手に入れた。しかし現在のツール実装は planning_agent.py の中に全部書いてある。ファイルが大きくなるにつれて管理が難しくなる。
第6弾では Agent Skills の設計を扱う。SecurityReviewSkill・PerformanceSkill・StyleCheckSkill を独立したモジュールとして実装し、Agentがその場に応じてSkillを選んで組み合わせる。モジュール設計とMCPとの役割の違いも対比する。
まとめ
- ReActの課題:ファイル数に比例してステップが増え、横断的な分析ができない
- Plan-and-Execute:計画フェーズと実行フェーズを分離し、ファイル数に依存しない固定ステップで全体を処理
-
実装のポイント:LLMにJSONで計画を生成させ、各ステップの結果を
collected_resultsに蓄積して最終レポートに渡す - 静的解析の活用:正規表現・ASTを使い、LLMだけに頼らず確実に問題を検出する