前回(第5弾)でAgentに「計画を立てて実行する」能力を持たせた。Plan-and-Executeパターンによって、大きなPRも4ステップの固定計画に落とし込んで処理できるようになった。
ただし、計画を実行するツール群(security_check・performance_checkなど)は planning_agent.py の中に全部書いてある。第5弾のファイルはすでに300行を超えていた。このまま機能を追加し続けると「どこに何があるかわからない」状態になるのは時間の問題だ。
今回はこの問題を Agent Skills という概念で解決する。
なぜSkillという概念が必要か
第1〜5弾で作ってきたものを振り返ると、ツールは常に「何かを実行する手段」として定義してきた。read_code()はファイルを読む。security_check()はコードを検査する。
これらは確かに「ツール」だが、役割が違う。
read_code() はファイルシステムへのアクセス操作だ。MCPが扱うような「外部リソースへの接続」に近い。一方 security_check() は「セキュリティの観点でコードを評価する専門的な判断」だ。操作ではなく、知識の適用だ。
この違いを整理すると:
| 種類 | 役割 | 例 |
|---|---|---|
| Tool | 外部リソースへの操作・アクセス |
read_code()・get_github_diff()
|
| Skill | 専門的な評価・判断の実行 |
SecurityReviewSkill・PerformanceSkill
|
| MCP | ネットワーク越しのツール提供 | GitHub・Slack・社内API |
Skillとは「Agent が呼び出せる専門家の判断モジュール」と理解するといい。
第6弾で作るもの
4つの専門Skillをそれぞれ独立したモジュールとして実装する。
ep06_skills_agent/
├── skills_agent.py # メインAgent(選択 + 統合)
├── review_targets/ # レビュー対象コード(第5弾と同じ5本)
└── skills/
├── __init__.py
├── base.py # BaseSkill 抽象クラス
├── security.py # SecurityReviewSkill
├── performance.py # PerformanceSkill
├── style.py # StyleCheckSkill
└── documentation.py # DocumentationSkill
Agentは3フェーズで動く。
- Skill選択:PR説明をLLMに読ませ、必要なSkillを選ばせる
- Skill実行:選択されたSkillを全ファイルに適用する(静的解析)
-
結果統合:LLMが全Skillの出力をまとめて最終レポートを生成する

実装:BaseSkillと統一インターフェース
まず全Skillの共通規格を決める。
# skills/base.py
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
@dataclass
class SkillResult:
skill_name: str
issues: list[str] = field(default_factory=list)
suggestions: list[str] = field(default_factory=list)
score: int = 100 # 0〜100
duration_sec: float = 0.0
def has_issues(self) -> bool:
return len(self.issues) > 0
def summary(self) -> str:
lines = [f"[{self.skill_name}] score={self.score}"]
for i in self.issues:
lines.append(f" - {i}")
for s in self.suggestions:
lines.append(f" + {s}")
return "\n".join(lines)
class BaseSkill(ABC):
@property
@abstractmethod
def name(self) -> str: ...
@property
@abstractmethod
def description(self) -> str: ...
@abstractmethod
def run(self, code: str, filename: str = "") -> SkillResult: ...
インターフェースはシンプルに「コードを受け取って SkillResult を返す」だけだ。AgentはSkillの中身を知る必要がない。
実装:SecurityReviewSkill(静的解析でCRITICALを確実に拾う)
# skills/security.py(抜粋)
_PATTERNS = [
(
r'f["\'].*SELECT.*\{',
"[CRITICAL] SQLインジェクション:f文字列でSQLを組み立てている",
"プレースホルダ(%s / :param)を使ったパラメータ化クエリに書き換えること",
),
(
r'(?i)password\s*=\s*["\'][^"\']{3,}["\']',
"[CRITICAL] 平文パスワード:ハードコードされた認証情報が存在する",
"環境変数(os.environ)または秘密管理ツールから取得すること",
),
# ... 他3パターン
]
class SecurityReviewSkill(BaseSkill):
@property
def name(self) -> str:
return "SecurityReview"
def run(self, code: str, filename: str = "") -> SkillResult:
issues, suggestions = [], []
for pattern, issue_msg, suggestion_msg in _PATTERNS:
if re.search(pattern, code):
issues.append(issue_msg)
suggestions.append(suggestion_msg)
score = 100
for issue in issues:
if "[CRITICAL]" in issue: score -= 40
elif "[HIGH]" in issue: score -= 25
else: score -= 10
return SkillResult(skill_name=self.name, issues=issues,
suggestions=suggestions, score=max(score, 0))
ここで意識したのは「LLMに頼らない」ことだ。セキュリティのCRITICAL案件(SQLインジェクション・平文パスワード)は正規表現で確実に検出する。LLMに判断させると「見落とし」が起きる。静的解析で検出した事実をLLMに渡すのが正しい分業だ。
PerformanceSkillはN+1クエリパターンと循環的複雑度をast+正規表現で検出する。StyleCheckSkillは未使用変数・型ヒント欠如をastで検出する。DocumentationSkillはdocstring欠如・TODO放置・マジックナンバーを検出する。それぞれ独立しているので、改修しても他のSkillに影響しない。
実装:Agentのメインロジック(3フェーズ)
Phase 1:Skill選択
# skills_agent.py(抜粋)
ALL_SKILLS: dict[str, BaseSkill] = {
"SecurityReview": SecurityReviewSkill(),
"Performance": PerformanceSkill(),
"StyleCheck": StyleCheckSkill(),
"Documentation": DocumentationSkill(),
}
def select_skills(pr_description: str, filenames: list[str]) -> list[str]:
skill_catalog = "\n".join(
f"- {name}: {skill.description}"
for name, skill in ALL_SKILLS.items()
)
prompt = f"""あなたはコードレビューAgentのオーケストレーターだ。
以下のPR説明とファイル一覧を読み、レビューに必要なSkillを選択せよ。
## PR説明
{pr_description}
## 利用可能なSkill
{skill_catalog}
## 出力形式
選択するSkill名をJSON配列で返せ。
例: ["SecurityReview", "Performance"]
"""
response = client.messages.create(model=MODEL, max_tokens=256,
messages=[{"role": "user", "content": prompt}])
raw = response.content[0].text.strip()
selected = json.loads(raw[raw.find("["):raw.rfind("]") + 1])
return [s for s in selected if s in ALL_SKILLS]
PRの説明に「セキュリティ上の懸念が最優先」と書いてあれば SecurityReview が選ばれる。「型ヒントを追加」と書いてあれば StyleCheck が選ばれる。AgentはSkillのカタログをLLMに渡して「何が必要か」を判断させる。
Phase 2:Skill実行
def run_skills(skill_names, filenames):
results = {}
for skill_name in skill_names:
skill = ALL_SKILLS[skill_name]
skill_results = []
for fname in filenames:
code = (REVIEW_DIR / fname).read_text(encoding="utf-8")
result = skill.run(code, filename=fname)
skill_results.append(result)
results[skill_name] = skill_results
return results
各SkillはAPIを呼ばない。静的解析だけなのでミリ秒単位で完了する。ファイル5本×Skill4種類を全部実行しても1秒もかからない。
Phase 3:結果統合
def synthesize_report(pr_description, skill_results):
all_summaries = []
for skill_name, results in skill_results.items():
all_summaries.append(f"=== {skill_name} ===")
for r in results:
all_summaries.append(r.summary())
prompt = f"""シニアエンジニアとして最終レビューレポートを作成せよ。
## 各Skillの検出結果
{"".join(all_summaries)}
重大度の高い順に問題を列挙し、全体スコアと総評を添えること。"""
response = client.messages.create(model=MODEL, max_tokens=1024, ...)
return response.content[0].text.strip()
LLMには「事実の解釈と統合」だけを担わせる。事実の検出は静的解析がやる。役割分担が明確だ。
実行ログ
以下は実際にWindowsで実行したときの出力だ。
============================================================
🤖 AIエージェントシリーズ 第6弾
Agent Skills設計
============================================================
📋 Phase 1: Skillを選択中...
選択されたSkill: ['SecurityReview', 'Performance', 'StyleCheck', 'Documentation']
🔍 Phase 2: 各Skillを実行中...
[SecurityReview] 実行中...
⚠️ sample_01.py score=60 issues=1 (0.00s)
✅ sample_02.py score=100 issues=0 (0.00s)
✅ sample_03.py score=100 issues=0 (0.00s)
⚠️ sample_04.py score=60 issues=1 (0.00s)
✅ sample_05.py score=100 issues=0 (0.00s)
[Performance] 実行中...
✅ sample_01.py score=100 issues=0 (0.00s)
⚠️ sample_02.py score=85 issues=1 (0.00s)
✅ sample_03.py score=100 issues=0 (0.00s)
✅ sample_04.py score=100 issues=0 (0.00s)
⚠️ sample_05.py score=75 issues=1 (0.00s)
[StyleCheck] 実行中...
⚠️ sample_01.py score=84 issues=2 (0.00s)
⚠️ sample_02.py score=76 issues=3 (0.00s)
⚠️ sample_03.py score=76 issues=3 (0.00s)
⚠️ sample_04.py score=92 issues=1 (0.00s)
⚠️ sample_05.py score=76 issues=3 (0.00s)
[Documentation] 実行中...
⚠️ sample_01.py score=80 issues=2 (0.01s)
✅ sample_02.py score=100 issues=0 (0.01s)
⚠️ sample_03.py score=50 issues=5 (0.01s)
⚠️ sample_04.py score=60 issues=4 (0.01s)
⚠️ sample_05.py score=70 issues=3 (0.01s)
📝 Phase 3: 結果を統合してレポートを生成中...
============================================================
📄 最終レビューレポート
============================================================
全体コード品質スコア:80/100
【CRITICAL】セキュリティ上の重大な欠陥
1. SQLインジェクション脆弱性(sample_01.py)
→ f文字列でSQL文を組み立てており、入力値次第でDBを完全に掌握される
→ プレースホルダ(%s)を使ったパラメータ化クエリに書き換えること
2. ハードコードされた認証情報(sample_04.py)
→ 平文パスワード・APIキーがソースコードに埋め込まれている
→ os.environ または Vault・AWS Secrets Manager から取得すること
【HIGH】パフォーマンスの重大な問題
3. N+1クエリ(sample_05.py・26行目)
→ ループ内でDB呼び出しが発生し、レコード数に比例してクエリ数が増加する
→ joinedload を使った eager loading で一括取得すること
【MEDIUM】保守性の問題
4. process_orders 関数の循環的複雑度(sample_02.py・推定CC≈8)
→ 条件分岐の深いネストでテストケースが指数的に増加する
→ 責務ごとに関数を分割し、単一責任原則を適用すること
【LOW】規約・可読性
- 全ファイルで型ヒントが欠如している(mypy 導入を推奨)
- sample_03.py・04.py・05.py で docstring が欠如
- sample_04.py の TODO/FIXME が未対応のまま放置されている
- sample_03.py のマジックナンバー(50・20)を定数化すること
総評:CRITICAL が 2 件あり、このままマージすると本番障害に直結する。
セキュリティ修正を最優先とし、N+1 クエリと CC 超過を次スプリントで対応すること。
型ヒントと docstring は CI(ruff・mypy)で自動検出できる体制を整えること。
============================================================
📊 実行統計
============================================================
総実行時間 : 10.9s
実行Skill数 : 4
レビュー対象ファイル: 5本
検出した問題の総数 : 30件
Skill Files Issues Avg Score
--------------------------------------------------
SecurityReview 5 2 84
Performance 5 2 92
StyleCheck 5 12 81
Documentation 5 14 72
総実行時間10.9sの内訳を見ると、Phase 2(静的解析)の各ファイルは0.00s台で完了している。時間がかかっているのはPhase 1(Skill選択)とPhase 3(レポート生成)のAPI呼び出し2回分だ。第5弾では各ステップでAPIを呼んでいたが、今回はSkillを静的解析に特化させたことでAPI呼び出しを2回に固定できた。ファイル数が10本・20本に増えてもAPI呼び出しは2回のままだ。
第5弾との比較
| 第5弾(Plan-and-Execute) | 第6弾(Skills) | |
|---|---|---|
| ツールの居場所 | planning_agent.py に全部 | skills/ ディレクトリに分散 |
| 新しい観点の追加 | ファイルに関数を追加 | 新しいSkillクラスを追加 |
| API呼び出し | 各ステップで発生 | Skill実行中はゼロ |
| テストのしやすさ | 全体を動かさないと確認できない | Skill単体でテスト可能 |
| LLMの役割 | 実行・検出・統合 | 選択・統合のみ(検出は静的解析) |
特に「テストのしやすさ」は現場で効いてくる。SecurityReviewSkillのパターンを追加したとき、そのSkillだけ単体で動かして確認できる。全体のAgentを起動してAPIを消費する必要がない。
MCPとの役割の違い
第3弾でMCPを実装したとき、「MCPとToolの違い」を説明した。今回はさらに「Skillとは何が違うのか」を整理しておく。
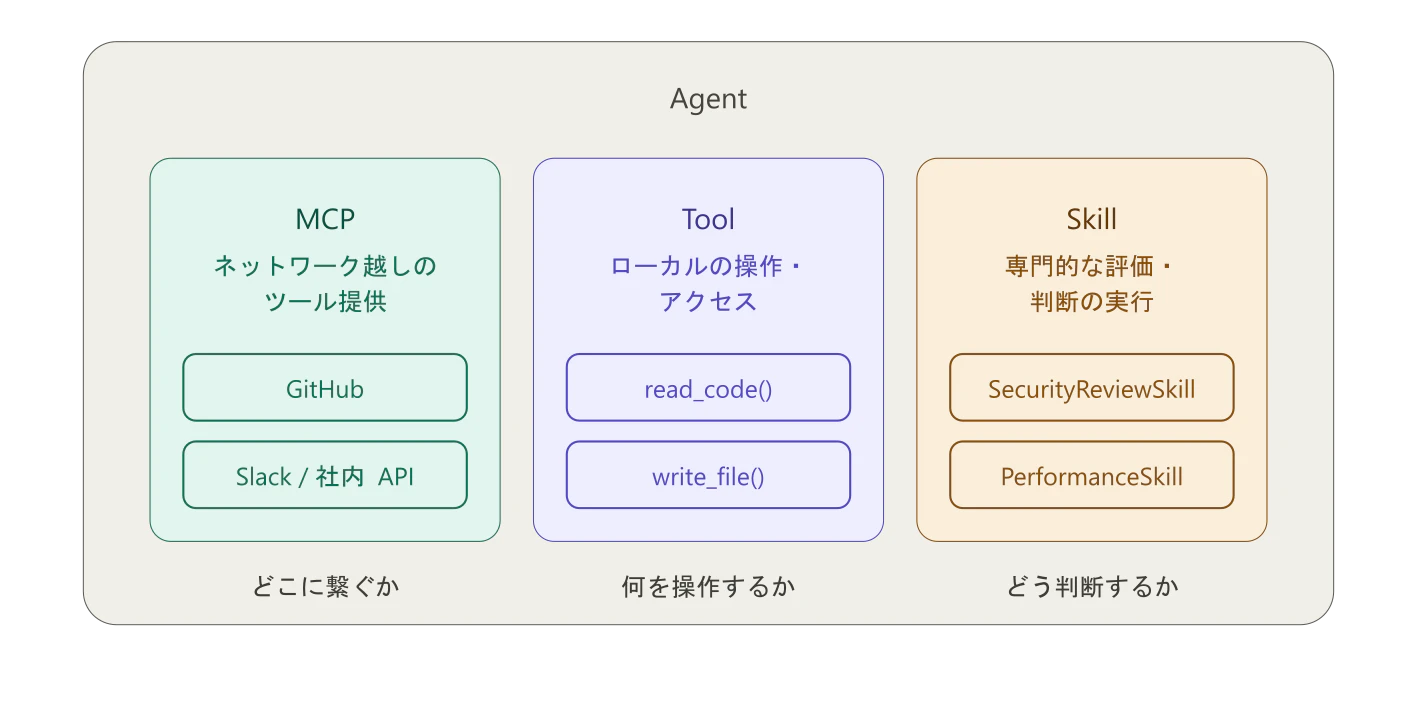
MCP は「どこに繋ぐか」を抽象化する。Tool は「何を操作するか」を定義する。Skill は「どう判断するか」を実装する。レイヤーが違う。
実際のシステムでは、「MCPでGitHubのdiffを取得する → Toolでファイルに書き込む → Skillでセキュリティ評価する → LLMが統合する」という流れになる。それぞれが独立しているから、どのレイヤーも交換可能だ。